개요
😊참가 경위
😫 AI model 개발 공모전이 하고 싶다...
이전까지 창업 경진대회나 비즈니스 아이디어 경진대회를 위주로 공모전을 수행해오다보니.. 이제 다시 AI model 개발 공모전이 하고 싶어졌다. 이제야 겨우 pretrained model이든, 아예 쌩으로 layer를 쌓든 해서 AI model 개발을 할 수 있다고 말할 수 있는 수준이 됐는데 이대로 그냥 졸업하기에는 아까웠다.
이왕 교내 AI 동아리 회장도 하게 된 거 경험을 더 쌓아보자! 싶어서 평소에 주로 공부해오던 Image deep learning 관련 공모전이 없을까 찾아보았다.
그러다가 마침 공모전 팀 매칭 오픈 카톡방에서 이 대회를 봤고, 지난 번에 의학영상처리 과목도 수강했겠다 바로 같이 하자고 연락을 넣었다.
🟥 대회 설명
-
대회 주제: 주어진 뇌 혈관 조영술 이미지를 기반으로 뇌 동맥류의 유무와 위치를 판별하는 AI 알고리즘을 개발해라
-
참가 자격: 대학(원) 재학/휴학생 (재학 증명서와 휴학 증명서가 발급 가능한 자에 한함.)
- 원래 졸업 유예생 친구도 같이 하자고 하려 했는데 안 된다고 해버려서 어쩔 수 없이 같은 학부생 4명과 팀을 했다.
-
대회 일정: 참가 접수 -> 검증 데이터셋 공개 -> 모델 평가 -> 최종 발표 -> 수상작 발표 -> 시상
참가 접수가 23.06.19~23.07.18 동안 개발한 모델을 제출하는 것으로 이뤄졌다.
접수 기간 만료 후에 검증 데이터 셋을 공개하면, 해당 데이터셋에 대한 AUROC 평가 지표를 직접 입력하고 주최 측에서 상위권 10개 팀에 대해 직접 model 파일을 돌려보고 시상 팀을 정한다고 한다.
🥲Model 개발 과정
Data set이... 이게 맞아...?
처음에 train_set을 받았을 때는 image가 9016개여서 "오~ 의료영상인데 꽤 많은데? 충분하겠다!"라고 생각했다.
아니었다.
자세히 보니 전체 개수는 9016개지만 하나의 환자에 대해서 8장씩 찍은 사진이므로, 실제 우리가 받은 data set은 1127개에 불과했다. 그런데 수행해야하는 task는 2가지 였다.
- 한 환자의 image 8장에 대해서 이 환자가 뇌 동맥류가 있을 확률을 예측
- 한 환자의 image 8장에 대해서 이 환자의 뇌 동맥류가 어디에 있는지 예측
두 task는 엄연히 다른 성격의 task였다. 1번은 regression의 방식으로 존재 유무에 대한 확률 예측을 수행하는 것이고, 2번은 총 21개의 label에 대해서 multi-label classification을 수행하는 것이다.
21개 label에 대해서 multi-label classification을 수행하는데 dataset이 1127장?
너무 적었다. 게다가 그 multi label들도 전혀 균일하지 않았다. (보통 이러면 아예 학습이 안 되거나 아무리 열심히 균일성을 맞춰서 validation set을 뽑아도 한계가 있다.)
3개의 class로 분류하는 task가 주어질 때도 웬만하면 데이터를 각 class에 대해 3000개 이상씩 줬었고, 혹여나 dataset이 적더라도 augmentation을 통해 어떻게든 dataset을 1000개보다는 훨씬 많게 할 수 있었다.
그러고도 validation accuracy가 겨우 90%를 넘길까 말까 하는 상황에 1127개?
게다가 2번의 task는 8장의 image 사이의 관계에 대해서 추출되는 feature이기 때문에 함부로 augmentation을 할 수도 없었다.
*) multi-classification은 흔치 않은 task여서 낯선 학부생들이 많을텐데 아래 link를 참고하면 multi-classification model을 만드는데 도움이 될 것이다.
https://sosal.kr/1128
https://dacon.io/competitions/official/235697/codeshare/2354
전처리하는게 더 힘든데?
지금까지 내가 겪어온 image classification task는 정말 깔끔하고 잘 정제된 것들뿐이었다는 것을 깨닫게 되었다. 왜냐?
위에서 언급한 1번의 task는 8장 중 한 장이라도 뇌 동맥류가 있다면, 그 확률을 높게 예측할 수 있어야 한다. 따라서 9016장을 하나씩 labeling해서 학습시키면 당연히 학습 결과가 좋지 않게 나올 수 밖에 없다. 그래서 모든 image들에 대해서 8장을 2열 4행으로 이어 붙이는 기행을 하기로 했다.
이 과정이 마냥 술술 넘어갔으면 이렇게까지 기억에 남지는 않았을 것 같다.
(그래놓고 나중에 가서는 regression model을 만들 때만 image들을 multi input으로 받아 처리하는 식으로 변형했다... 그래야 accuracy가 훨씬 좋았다.)
-
Google drive 중복 문제
Google drive에 9016장의 image를 한 번에 다 업로드하고 있자니... 네트워크가 조금만 불안정해도 중간에 중복 image가 생겼다. 2~3시간이 넘게 업로드가 되고 있길래 밥 먹고 돌아와서도 대기했건만, image path를 가져와서 전체 image 개수를 받아보니 9017개다. 언제 저걸 하나하나 일일이 다 찾아서 중복을 제거하나... 싶어서 그냥 다시 새로 올렸다. 9024개가 나왔다. 하다하다 열불이 나서 아예 압축 파일을 올려서 drive 내에서 압축 해체를 했다. 이제야 겨우 9016개가 나왔다... -
image size 및 형태 문제
9016를 하나하나 다 볼 여유는 없어서 앞 부분과 뒷 부분만 좀 훑어보고 image concatenation code를 돌렸다. 그랬더니 image size가 맞지 않는 오류가 생겼다. 뭔가 싶어서 iamge size를 몇개 random으로 출력해보니 (750,750), (960, 960), (1255, 1255)... 아주 다양했다. 게다가 어떤 image들은 아예 다른 방식으로 수집한 image인지 다른 image들에는 없는 검은색 테두리와 image에 대한 설명문이 같이 있었다.
아니! 의료 데이터 셋의 공유 및 확산을 위한다면서 이렇게 날 것의 날 것을 주면 어떡하자는 건지!
결국 image size도 반복문 이용해서 통일하고, image 테두리도 반복문 이용해서 일일이 검증하고 제거하고 나서 반복문을 이용해서 전처리를 하느라 거의 2시간이 지났다. (심지어 이조차도 네트워크 불안정으로 중복이 일어나거나, 네트워크 오류로 인해 image 한 장이 corrupted 되어있어서 중간에 끊기거나 해서 엄청 애를 먹었다.) -
Colab의 RAM 부족, CUDA memory error
...그렇게 열심히 전처리하고 pretrained model을 돌려보려는 순간...! RAM이 터졌다. 어찌저찌 해서 RAM이 안 터지도록 resizing을 하고 다시 돌리니 CUDA memory가 터졌다. 가난한 학부생은 Colab도 무료 버전으로 이용해서 이런 고난과 수난을 겪는다. 결국 image들을 죄다 100으로 바꿨다.
Accuracy가 왜 이래?
생고생을 다 해서 겨우 전처리가 다 끝나고, 이제야 겨우 model을 좀 돌려보겠거니~ 했는데
어라?
??
????
??????
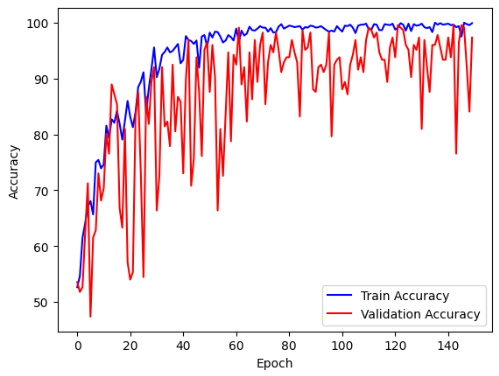
epoch가 100번을 다 돌아도 train accuracy와 validation accuracy가 50%, 45%에서 그대로 유지되었다.
(원본 이미지는 버렸는지 안 보인다. 대충 이렇게 생겼었다. 저 상태로 epoch이 100을 돌았다....)
이런...graph는 처음 본다..... 심지어 이것도 2020년에 나와 최근 Dacon에서도 인기인 ConvNeXt model을 가져와서 사용한 것인데 정말 극심할 정도로 학습이 안 됐다.
RAM 때문에 2열 4행으로 이어 붙인 image를 넣을 때 size를 줄여서 그런지 feature extraction이 제대로 안 되는 것 같았다. regression task든 multi-label classification이든 둘다 완전히 학습 불능 상태였어서... 다른 방법이 필요했다.
그런데 의외로 multi-label classification은 ResNet50의 pretrained model을 가져왔더니 학습이 꽤나 잘 되는 모습을 보였다!
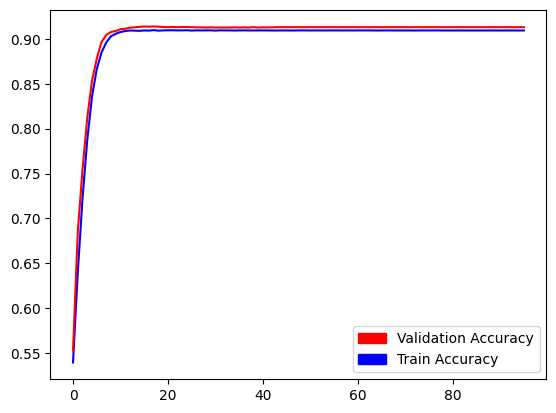
약간 놀라울 수준이었다... 이게 뭔가 싶다. 하지만 대회에서는 regression model을 우선 평가하기 때문에 regression model을 어떻게든 해결해야하는 상황이었다.
이어 붙인 image의 size를 늘리면 RAM이 터져버리고, image가 작아버리면 feature extraction이 안되다보니 아예 다른 방법이 필요한 것은 아닌가 싶었다.
그러다가 팀원이 multi-input 방식으로 학습을 시킬 수 있다고 해서 코드를 바꾸고,
데이터들도 동일한 접미사를 갖는 것들끼리 나눠 1127개의 image가 저장된 8개의 폴더로 나누고,
각각에서 순서대로 하나의 image를 불러와 한 번의 epoch에 8개의 input data를 받는 방식으로 바꿨다.
기적이다!!!!
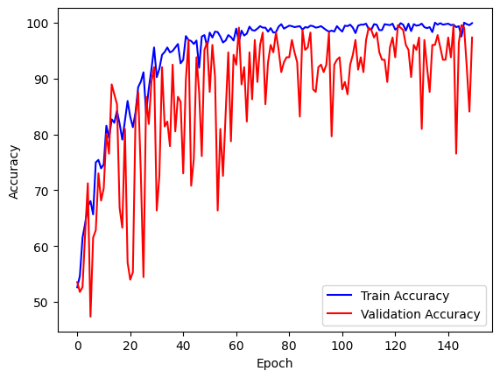
적은 dataset 때문에 oscillation은 어쩔 수 없었지만, 정말 우수한 수준의 train/validation accuracy가 나왔다.
진짜 없는 dataset 쥐어짜고, 별 짓을 다 하고 learning rate도 0.001, 0.002, 0.005, 0.003, 0.0015 다 넣고 다 돌려보고 하다가 너무너무 좋은 accuracy를 얻게 되었다.
혹시 몰라서 다시 코드를 정리하고 주최 측에서 제공한 evaluate.py를 활용해서 전체 train_set에 대한 AUROC 평가 값을 확인했다.
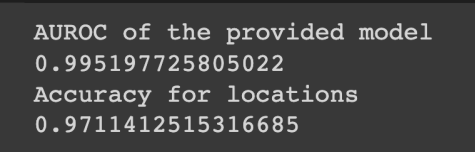
1번의 뇌 동맥류 유무 판별에 대해서 99%, 2번의 뇌 동맥류 위치 판별에서 97%의 정확도를 보였다!
이만하면 됐다 싶어서 제출을 하려고 했다.
그런데...
🤨제출 방식의 문제
주최측에서는 python code를 제출하라고 했을 뿐, 따로 제출 파일의 확장자를 명시하지는 않아서 처음에는 .ipynb 형식으로 파일을 제출하려고 했다.
근데 뭔가 불길한 기분이 들어서 주최 측 홈페이지의 게시판을 뒤져보니..
1. jupyter notebook, Colab에서만 돌아가는 불완전한 코드는 제출 시 불이익이 있을 수 있다는 언급
아니 세상에 누가 .ipynb 파일은 불완전하고, .py로 잘 돌아가야만 완전한 코드라고 하지?
생전 처음 들어보는 언급에 놀라서 잠깐 벙쪘고, 그 다음에는 화가 났다. 다른 게시글에서는 학부생이 GPU가 없어서 Colab을 활용해 개발하는 것을 허용했다고 했으면서 (애초에 이게 금지한다고 금지되는게 아닌데...) 제출하는 것은 무조건 .py로 해달란다.
2. 공지 미흡
공지 사항에는 python 소스 코드라고만 적혀있어서 당연히 .ipynb 확장자도 가능한 줄 알았는데 무슨 이걸 불완전한 코드 취급해버리는 것을 보고 직감이 왔다.
주최측은... 직접 개발을 해본 적이 없는 것 같다...
이게 당연히 해야 하는 수준의 공지이고 (DACON의 최신 대회에서 가져옴)
이건 이 주최측의 공지이다... 있어야할 것이 없는 상황이다.
게다가 아래에는 이렇게 기술되어있다.
권장 프로그래밍 언어에 C와 JAVA가 있는데 제출은 꼭 python script로 해라?ㅎㅎ
그렇다....ㅎㅎ...

3. 기술 문서 및 test.py 실행 방법에 대한 문서는 최대한 자세히 써달라는 언급
말했듯이, 주최측이 말하는 평가진의 전문성은 개발 분야가 아닌 듯 했다.
물론, 다른 개발진들이 주최하는 공모전에서도 가능하면 파일 실행 방법은 자세히 쓸 수록 좋다. 하지만 그런 경우에는 보통 파일 경로라던지, 제출 시에 허용하는 파일의 확장자라던지, 평가 시에 사용하는 기기의 성능이라던지 이런 것들을 충분히 명확하게 공시를 하고 있다.
그렇기 때문에 그 공시된 사항들을 지키기 위해서 파일 실행 방법을 작성하며 검토를 해야하는 것이고, 또 여러 제출 파일들이 뒤섞이면서 python의 경우 여러 library 사이의 version error가 날 수 있음을 고려해 requirements.txt를 함께 제출하여 평가진이 섬세하게 평가에 임하고 있다.
그런데 이 대회에서 내가 느낀 것은... 평가진이 이런 SW를 평가하는 공모전에 경험이 부족하여 공시도 잘 되어있지 않고, 참가자가 주최 측을 배려하여 기술 문서를 작성하는 수고를 하는 것이었다.
참... 많은 것을 배웠지만, 그만큼 불필요한 노동을 더 많이 하고 감정 소모도 많이한 기분이었다. 열심히 개발한들, 주최 측은 개발 사항에 대해서 얼마나 알까 싶은 생각이 많이 들었다. (제발 이런 대회를 할 거면 DACON에 올리거나, 컴공 개발진을 자문 위원으로 데려오길 바란다...)
어찌저찌...
급하게 .py로 바꾸고 생각해보니 data를 받는 파일 경로들도 제대로 안 고쳐놔서 전부 수정하고 정리해서 3시 마감 직전에 겨우 제출했다.
마무리
소감
✅ 이 대회를 추천하나요?
⭐⭐⭐--/5
공모전 자체에 임하는 과정에 있어서는 data의 특성을 고려해서 전처리를 하거나, model에 input을 넣는 방식을 달리 하는 등 다양한 노력을 기울이면서 multi-label classification 같은 새로운 task도 다뤄볼 수 있었기 때문에 개인의 실력 향상에는 큰 도움이 되었다.
그러나, 공모전 주최 측의 미흡한 지점들이 참가자를 상당히 괴롭게 하는 점이 없지 않아 있었기 때문에 나중에 주최 측에게 건의할 수만 있다면 대회를 DACON과 협력해서 여는 것을 권하고 싶다. 주최 측이 직접 평가하는 것보다 아예 model을 올리면 accuracy에 대한 leader board가 뜨는 것이 참가자나 주최 측이나 둘다 편한 방식으로 보인다.
그리고 어려운 task와 부족한 data set에 비해 시상 규모도 DACON의 여타 대회들과 비슷한 것을 보면... 굳이 이 대회를 하라고 권하기는 어려울 것 같다.
✅ 그래도 좋았던 것은?
많이 배웠다는 것!
- 의료 영상에 있는 noise들을 제거하기 위해 filtering도 해보고 했는데 전혀 영향이 없었다. 되려 이런 noise들이 convolution 연산을 하면서 무시되는 것 같기도 했다.
- 오히려 너무 depth가 깊고, 큰 규모의 dataset을 학습한 pretrained model들은 작은 규모의 새로운 dataset에 대해 잘 fine tuning 되지 않는 듯 했다.
swin transformer도 써보고, convnext도 tiny부터 large까지 다 써봤지만 ResNet50보다는 못 했다.
ResNet50의 범용성에 감탄하고 있다. - 사실 원래는 regression과 multi-label classification을 동시에 수행하는 multi-task model을 만들려고 했었다. 그러나 학연생으로 랩실에서 연구를 하고 있는 중에 시간이 너무 부족해서 model을 2개 만들어서 사용할 수 밖에 없었다. 이게 참 아쉬웠지만, 그래도 regression과 multi-label classification task를 모두 경험해볼 수 있었던 것이 좋았다.
근데...
그래도 다음에는 좀더 주최 측이 믿을 만한 대회를 나가고 싶다...
주최 측의 그 발언이 좀 상처였다.
"불완전한 코드..."
내가 한 달 고생해서 만든게 불완전한 코드...
Colab에서만 돌아가는 코드는... 불완전한 코드...?ㅋㅋ
하하...........
솔직히 수상은 욕심 없고 (어짜피 급하게 변환한 코드라서 제대로 디버깅도 못 했고)
그냥 나중에 올라올 검증 데이터셋으로 검증했을 때 AUROC 값이 90만 나왔으면 좋겠다.
**) 검증 데이터셋으로 돌렸을 때, 존재 유무 판별은 55%, 존재 위치 판별은 97%로 결국 수상권에는 들지 못 했다. 알고 보니 뇌동맥류를 AI로 탐지하기 위해 만들어진 해외 데이터셋도 있었어서 그걸 사용했다면 이렇게 오버 피팅 결과가 나오지는 않았을까 싶은 생각이 든다.
그래도 많이 배웠다!
