HTML 기초
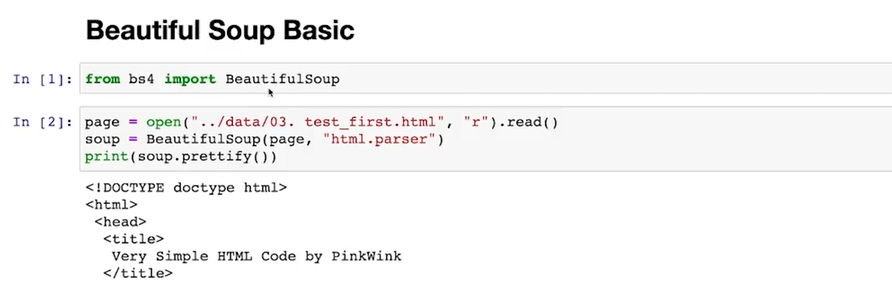
Beautiful Soup 기초
Beautiful Soup Documentation
tag로 되어 있는 문서를 해석하는 모듈
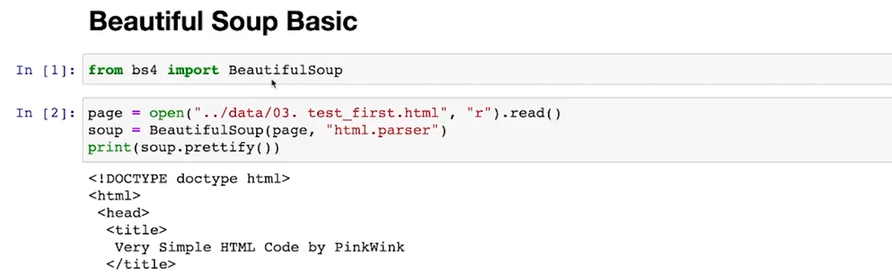
page = open(파일명, 'r').read()
soup = BeautifulSoup(page, 'html.parser')- page 파일을 BeautifulSoup으로 해석, 읽어내는데 필요한 엔진은 html.parser 을 사용하겠다
print (soup.prettify())- soup에 들어간 데이터(들여쓰기)를 잘 읽어주는 기능은 prettify() 이다
soup.body- body tag 만 읽어오고 싶을 때
soup.find('p')
soup.find_all('p') # 모두 찾기 _ list[]로 출력
soup.find_all(class_='특정 단어') #특정 단어만 찾고 싶을 때- p tag 중 '첫번째'를 찾고 싶을 때
- p tag 를 모두 찾고 싶을 때
- '특정 단어'로 클래스가 잡히는 모든 값을 찾고 싶을 때
외부 링크 주고 확인 방법
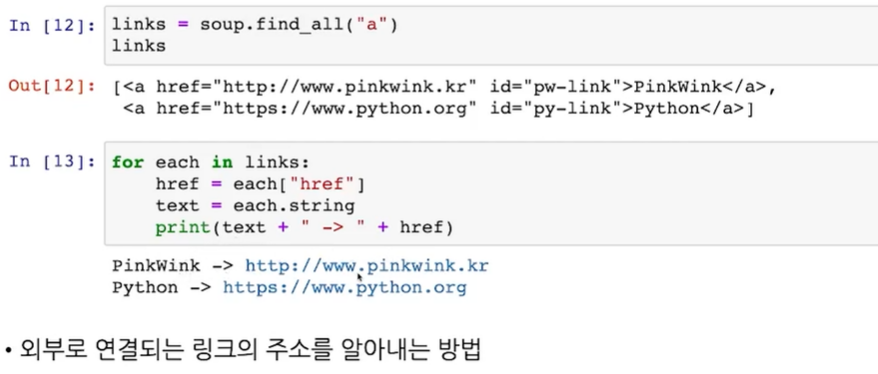
links = soup.find_all('a')
links- 'a' 는 링크 tag
- 'a' tag를 모두 찾아서 links에 저장
for each in links:
href = each['href']
text = each.string
print(text = '->' + href)- links에서 하나씩 가져와서
- 'a' tag의 href 속성을 가져오고 싶다, 가져와서 href라고 한다
- 'a' tag의 글자만 가져와서 text라고 한다

비전공자의 데이터 공부법