NLP
1.Naive Bayes Classifier
Naive Bayes Classifier 소개 및 간단한 예시
2.Word2Vec, Glove
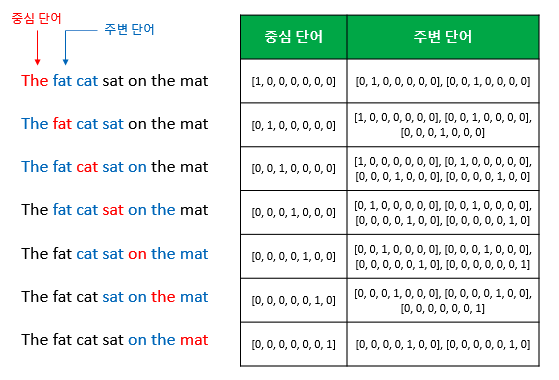
Word Embedding : 분산표현(Distributed Representation)을 이용해 단어간 의미적 유사성을 벡터화하는 작업 의미가 비슷한 단어 → 비슷한 벡터값을 갖게 한다 → 분류 테스크 진행 시 잘 부합됨, 머신러닝 task를 할 때 좋은 요건이 된다
3.Transformer
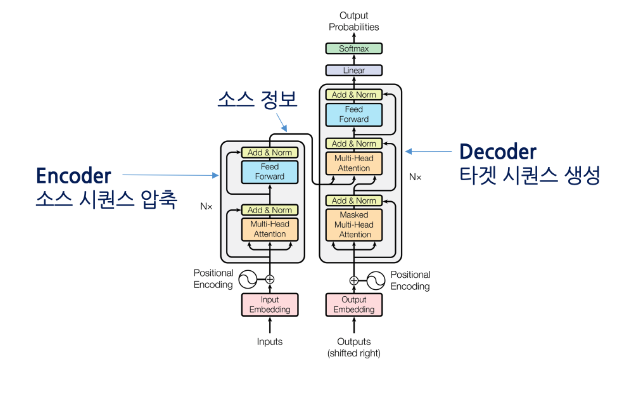
대표적인 기계번역은 어떤 언어(source language)에서 다른 대상 언어(target language)의 단어 시퀀스로 변환하는 과제이다. 여기서 scource language 와 target language의 길이는 다르게 출력되는게 가능하다.transfor
4.NLP - 다양한 모델, 벤치마크
RoBERTa, ELECTRA, ALBERT, GPT3
5.Machine-Generated Text: A Comprehensive Survey of Threat Models and Detection Methods

Introduction NLG Model은 빠른속도로 배포되고 있고, 이러한 오픈소스로 풀린 모델들의 생성해 낸는 단어들의 위험성 또한 존재한다. 본 논문에서는 3가지 관점에서 survey를 진행 최근 text detection에 대한 설명 Treat Model에 대한
6.A Survey on LLM-generated Text Detection: Necessity, Methods, and Future Directions
git : https://github.com/nlp2ct/llm-generated-text-detection watermark in llm : 사람 눈으로 확인하기 어려운 숨겨진 패턴 등을 알고리즘적으로 식별하는 방법 LLM에서 워터마크는 소유권은 물론 콘텐츠의 진위성
7.OUTFOX: LLM-generated Essay Detection through In-context Learning with Adversarially Generated Examples
Abstract ICL(in-context learning)을 이용해 detector와 attacker 둘 다 탐지하고 공격하기 어렵게 한 적대적 학습 형식이다. detector와 attacker gpt 3.5 tubo 사용,,, Introduction OUTFOX
8.DetectLLM: Leveraging Log Rank Information for Zero-Shot Detection of Machine-Generated Text
용어 negative curvature of the log likelihood of the text : 기계가 생성한 probability를 측정한다. curvature of the log likelihood는 이 probability의 곡률(shape)을 의미한다.