NLP 벤치마크 설명
Natural Language Inference(MNLI, SNLI, XNLI, aNLI) : 자연어 추론
- 입력 : 전제 : 회색 개가 숲에서 쓰러진 나무를 핥고 있다.
- 가설 : 개가 밖에 있다.
- 출력 : 참 거짓 모름
Sentiment Analysis(SST, IMDb, NSMC) : 감정분석
- 입력 : 문장, 신만이 이 영화를 용서할 수 없다.
- 출력 : 긍정 부정
Similiarity Prediction(STS, MRPC, QQP, PAWS-X) : 유사도 예측
- 입력 : 문장1 : 파이썬과 자바 중 뭐부터 배워야 하나요?
- 문장 2 : java나 python 중 하나를 배워야한다면, 뭐부터 시작해야 할까요?
- 출력 : 유사 비유사
Reading Comprehension(SQuAD, RACE, MS MARCO, KorQuAD) : 기계 독해
- 입력 : 지문 (Question)형태
- 출력 : 정답 : 2022년 등
Intent classification(ATIS, SNIPS, AskUbuntu) : 의도분류
- 입력 : 질문 : 현재 위치 주변에 있는 맛집 두 곳만 알려줘
- 출력 : 장소검색(식당, 가까운, 평점 좋은, 2)
NLP 모델
RoBERTa
Transfer learning :
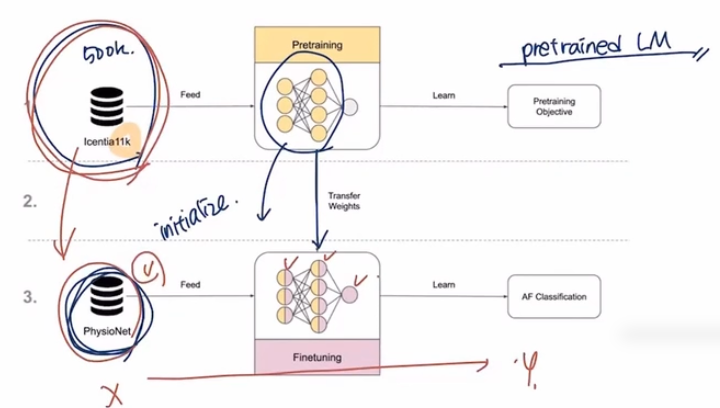
pretraned LM → fineturning LM
RoBERT :
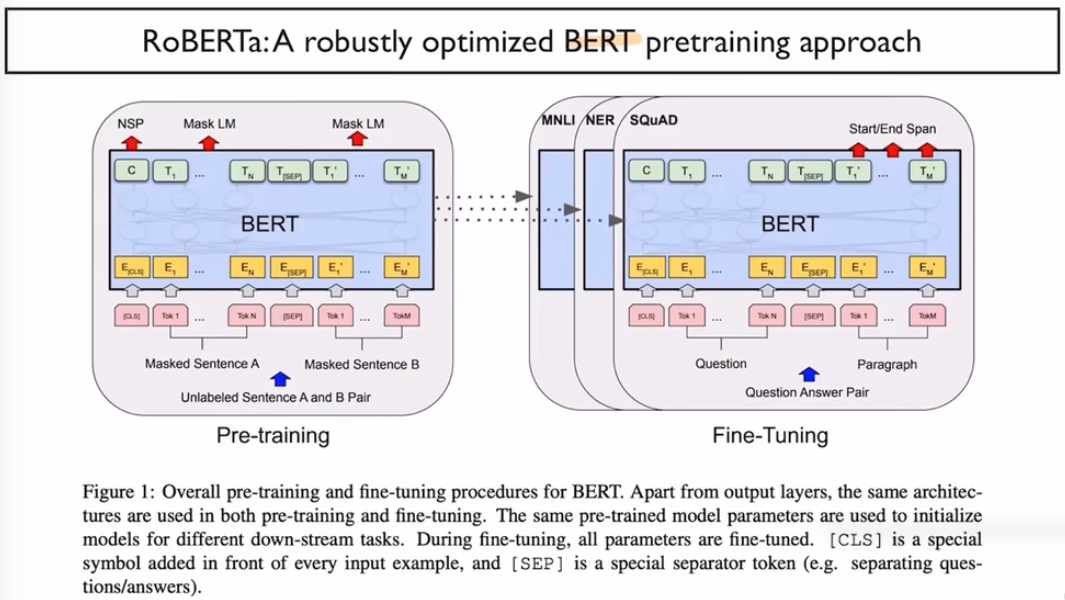
BERT의 크기를 키워본 것.
ROBERTa 는 NSP를 사용하지 않음, 데이터를 160G로 만들고 학습을 500K까지 늘려봄 또한 베치사이즈도 256까지 올리고 BPE보캡을 사용할떄 byte-level BPE를 사용함(50K)
로보타는 Next Sentence Prediction을 수행하지 않음.
ELECTRA-Efficiently Learning an Encoder that Classifiers Token Replacements Accurately
GAN이 유행하면서 생성모델과 식별모델을 자연어 처리에 적용한 모델
BERT의 인코더를 더 효율적으로 학습시켜보자는 의미에서 나옴
토큰이 정확하게 inplace되는지 보기위한
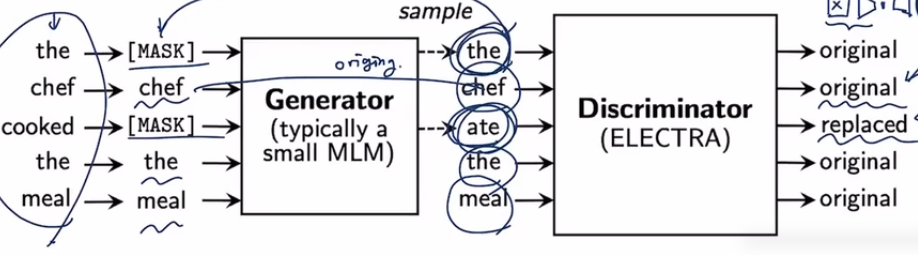
연산량이 적을때 로버타에비해 빠르게 높은 성능에 도달할 수 있다.
ALBERT
항상 NLP모델은 무겁고 사용하기 힘들다라는 생각을 바탕으로 a light BERT가 생겨남

1,2 로 속도와 메모리 문제를 해결하는데 성능이 저하되는 문제가 있어 SOP를 수행해서 성능을 올려보자 라는 접근 방식
2번에서는 FFN(Feed Forward), attention 레이어의 모델 파라미터를 쉐어링 하면서
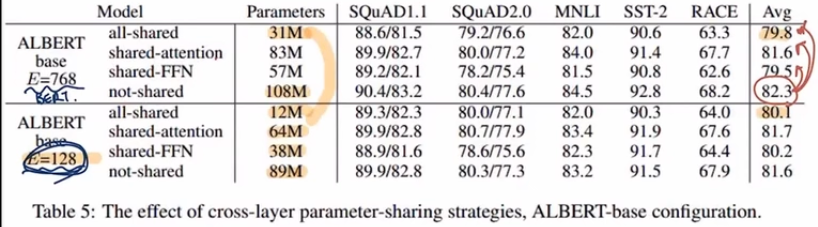
성능의 큰 타격없이 모델파라미터를 효과적으로 줄일 수 있다.
sentesnce order도 고려한 학습을 수행하게 된다. → 학습효과가 좋아짐
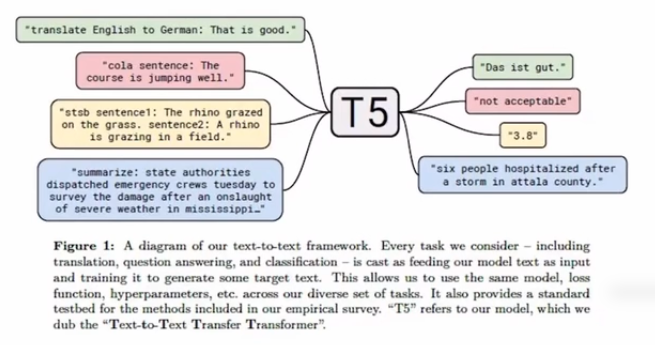
T5 - Text-to Text Transfer Transformer- 11B
인코더디코더가 모두 트랜스포머,
하나의 모델에서 다양한 텍스트를 다룰 수 있다는 특징이 있다.
T5는 트랜스토머에서 할 수 있는 아키택쳐를 다양하게 실험해봄
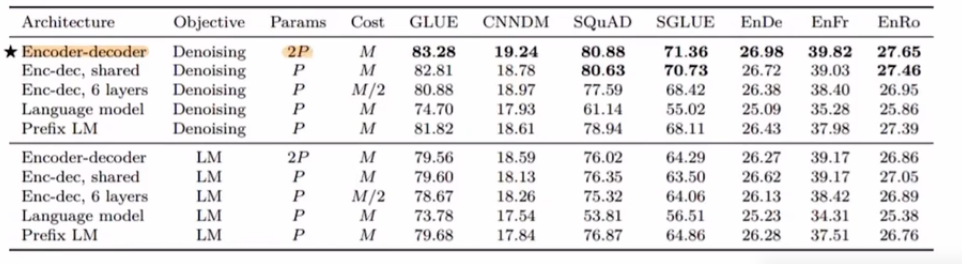
인코더 디코더 구조일때 가장 좋은 결과를 나타냈다 라는 결론.
GPT3 - 175B parameters, Batch_size = 3.2M, 96 Attention layers
모델의 사이즈를 엄처안게 크게 만들면
프롬프트에서 어떤 프롬프트를 설명하고 그거에 대한 예시를 만들어주면 정답을 만들어주는 형태

모델의 파라미터만 키워주면 정확도가 높아진다는 것이 GPT3의 논문 내용
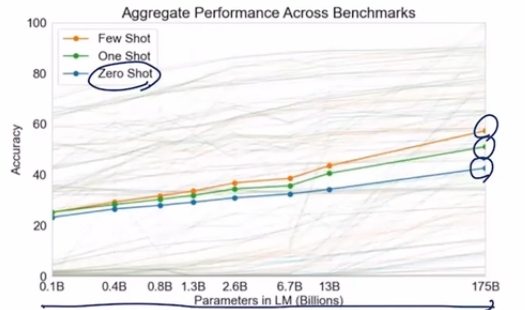
Summary
모델은 계속 커지고 있고 self-supervised learning 기술을 바탕으로 언어 생성 모델이 더 강력해 지고 있다.
