Introduction
NLG Model은 빠른속도로 배포되고 있고, 이러한 오픈소스로 풀린 모델들의 생성해 낸는 단어들의 위험성 또한 존재한다.
본 논문에서는 3가지 관점에서 survey를 진행
1. 최근 text detection에 대한 설명
2. Treat Model에 대한 분석
3. EU AI윤리 지침에 따른 survey
2. Machine Generated Text
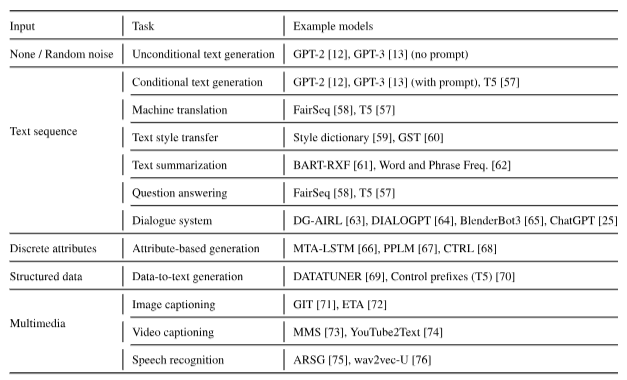
언어 생성접근에는
1. Non-Neural Model
2. Non-Transformer Neural method
- RNN, LSTM GAN, Deep RL, IRL(Inverse RL)등의 방식이 있다.
3. Transformer
- 가장 연구가 활발한 분야로 토큰을 생성할 때 조건부 확률로 가장 높은 확률이 높은 토큰을 선택하는 방식을 사용한다.
- unidirectional transformer 모델에서 디코딩 전략으로 top P, top K, Temperature를 주로 많이 사용하고 최근에는 typical sampling 방식을 사용하기도 한다.
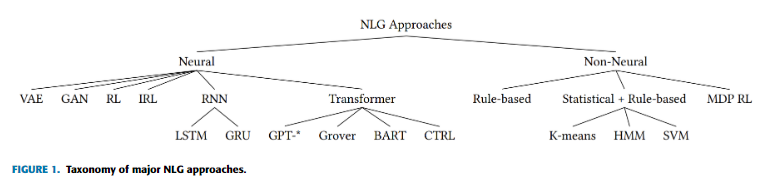
3. Threat Model
용어 : Threat Model - 시스템 보안을 향상시키기 위한 모델.
4. Detextion of Machine Generated Text
detection문제는 binary cls 문제이다.
A. Feature-Based Approaches
SVM, RF(random forest), NN(neural Network) 를 classification문제해결에 사용할 수 있다.
- Feature방식 사용했을 때 sampling이 달라지면 샘플링 바뀐 것으로 학습된 것보다 기존 모델의 성능↓
- 작은 모델 출력에 대해서 훈련 → 큰 모델 출력 detect 가능하지만, 큰 모델에서 작은모델 detect하는 것이 더 효율적이다.
1) Frequency Features
- Zipf's Law : 단어의 빈도, 단어의 빈도는 빈도에 따른 단어의 순위에 반비례한다(?)
- 기계가 생성한 text는 사람이 쓴 텍스트의 토큰 분포를 완벽하게 반영하지 못한다. → 그러므로 토큰의 분포는 분류(식별) 하는데 유용하다. (긴 텍스트를 부분적으로 고려할 때 유용함)
- 방법론 : 1) TF-IDF 2) lemma frequency 3) log-log lemma frequency 4) n-gram 5) pos tagging
2) Fluency Features
- 문장 길이가 길어질 때 기계로 생성한 문장은 일관성이 유지되기 힘들다. (!!!요즘 나온 큰 모델에서 유효할지 잘 모르겠음)
- 방법론 : 1) Gunning-Fog Index 2) Flesch Index : 이 둘의 방법은 가독성 및 텍스트 이해를 측정한다.
- 복잡한 방법으로는 보조목적 모델을 이용해 coreference resolution 으로부터 일관성을 측정함
3) Linguistic Features From Auxiliary Models
- 과거의 research는 일관성을 측정해왔다(coreference resolution)을 통해. 혹은 pos, NE를 통해
- 요즘에는 feature를 뽑은 후 NN을 통과시켜 사용하기도 한다. 하지만 적대적인 방식(!!! GAN 같은 것을 말하는 건가?)에는 취약하다는 단점을 가진다.
4) Complex Phrasal Features (복잡한 문구의 특성)
- transformer 모델 나오면서 안 씀
5) Basic Text Features
- 단순 text features만 이용해서 분류하는것이 빈번하게 사용된다.
B. Neural Language Model Approaches
NN을 이용해서 detection을 접근하는 방식이 많이 사용되고 있다. (특히 transformer에서 나온 features를 포함할 때)
1) Zero-shot Approach
- fine-tuning없이 진행, [CLS] token이 인풋 시퀀스 마지막에 들어가며 해당 토큰이 전체 문장의 feature vector 역할을 한다.
- 작은 모델로 큰 모델detect에 사용할 수 있다.
- Grover : 뉴스 도메인에 특화된 detection 모델로 다른 도메인에서는 엄청 성능이 잘나오진 않음(TF-IDF 베이스라인보다 성능이 안나옴)
- 이후 연구에서 bi-directional모델들이 machine generate detection 에 장점이 있다고 함
2) Fine-tuning Approach
- SOTA는 bi-directional모델들이다.(많이 사용하는 방식이다.) ex) RoBERTa large
- 도메인 적응성도 매우 좋음
- TDA(topological data analysis) 방식을 이용하면 fine-tuning 방식에 비해 크게 성능향상되진 않았지만, GPT계열 unseen data에 매우 정확한 탐지를한다. (RoBERTa에 TDA를 적용시켰을 때는 어떻게 될지 모름 !!! 실험결과가 없는 것 같음.)
- Bi-LSTM, bidiredction(roberta), unidirection, linear classification method모두 사용가능 하지만 bidirectional방법이 가장 좋았다.
3) Applied Detection in Specific Domains
- 특징을 잡아서 detect하는 방법또한 하나의 방법이다. (!!! 전체 토큰 갯수 분석??)
- XGBoost, Random forest classification방법은 해석가능한 분류 방식이기때문에 사용자가 잘 데이터를 파악하면 더 성능을 올릴 수 있다.
4) Human-Aided Method
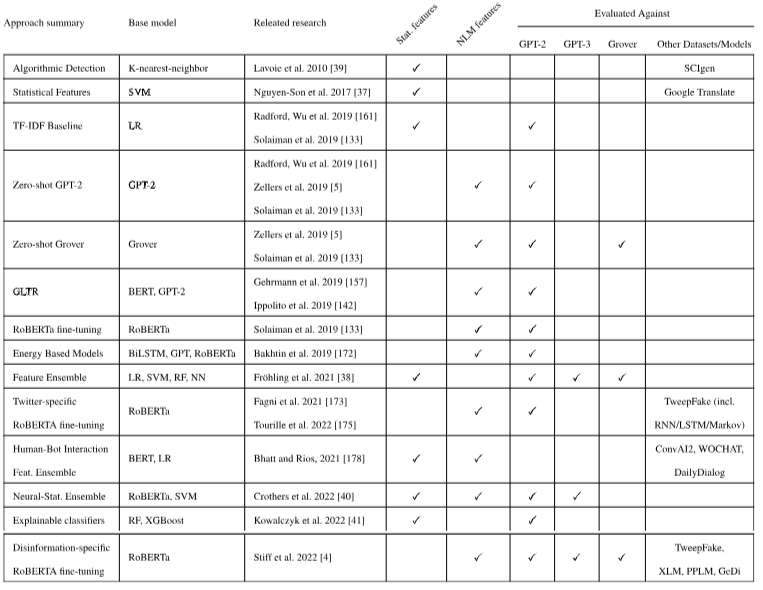
5) Trends in Evaluation Methodology and Datasets
- 트랜스포머 아키택처로 문장을 생성한 후 detection을 수행함.
- detection시 토큰의 길이가 길때 효과가 더 좋음. 토큰의 길이는 일반적으로 2048을 이용함 (!!! 데이터셋 확인할 필요 있는 것같음)
6) Prompt Injection - 최근 NLG에 Prompt Injection되는 경우 모델이 잘 탐지하지 못하는 취약점이 존재한다.
5. Trends and Open Problems
1) Detection Under Realistic Settings
- class imbalance
