Word2Vec : 단어 벡터 간 유의미한 유사도를 반영할 수 있도록 단어의 의미를 수치화 하는 방법
Word Embedding : 분산표현(Distributed Representation)을 이용해 단어간 의미적 유사성을 벡터화하는 작업
의미가 비슷한 단어("관련성") → 비슷한 벡터값을 갖게 한다 → 분류 테스크 진행 시 잘 부합됨, 머신러닝 task를 할 때 좋은 요건이 된다.
+) 만약 단어가 정 반대의 의미를 가지고 있다고 임베딩 벡터가 반대 방향을 가르키는 뜻이 아니다.
기존 one-hot-vector(= 희소표현 방법 = Sparse Representation, target : 1, 나머지 : 0) 단어벡터간 유사도를 계산할 수 X → Word2Vec(분산표현의 학습방법)을 이용해 단어의 의미를 수치화
Word2Vec 학습방식
- CBOW(Continuous Bag of Words) : 주변에 있는 단어들을 입력으로 중간에 있는 단어를 예측하는 방법.
class CBOWDataset(Dataset):
def __init__(self, train_tokenized, window_size = 2):
self.x = [] #input word
self.y = [] # target word
for tokens in tqdm(train_tokenized):
token_ids = [w2i[token] for token in tokens]
for i, id in enumerate(token_ids):
if i-window_size >=0 and i+window_size < len(token_ids):
self.x.append(token_ids[i-window_size:i] + token_ids[i+1:i+window_size+1])
self.y.append(id)
self.x = torch.LongTensor(self.x)
self.y = torch.LongTensor(self.y)
def __len__(self):
return self.x.shape[0]
def __getitem__(self, idx):
return self.x[idx], self.y[idx]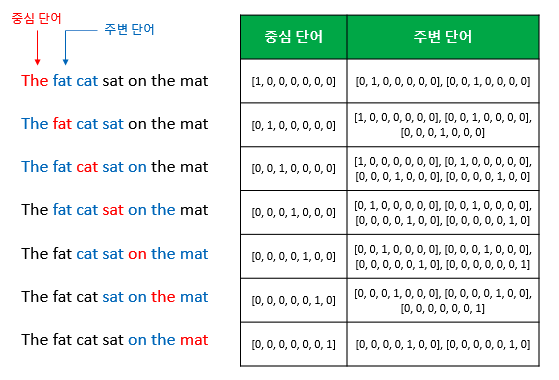
중심 단어를 예측하기 위해 앞, 뒤로 몇 개 단어를 볼지 결정하게 되는데 이를 윈도우 라고 한다.
해당 사진은 윈도우가 2인 예이다. 오른쪽으로 단어를 변경해가며 학습 데이터 셋을 만드는데 이를 슬라이딩 윈도우 라고 한다.
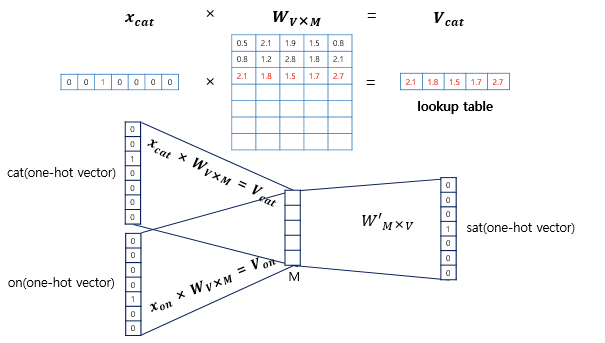
위의 그림은 CBOW의 인공신경망을 도식화 한 것, Word2Vec의 은닉층은 활성화 함수가 존재하지 않으며 주로 투사층(projection layer)이라고 부른다.
투사층의 크기 : M = 5, 이므로 임메딩 벡터의 차원은 5, W(가중치) = V X M 행렬, W’의 벡터는 M X V가 된다.
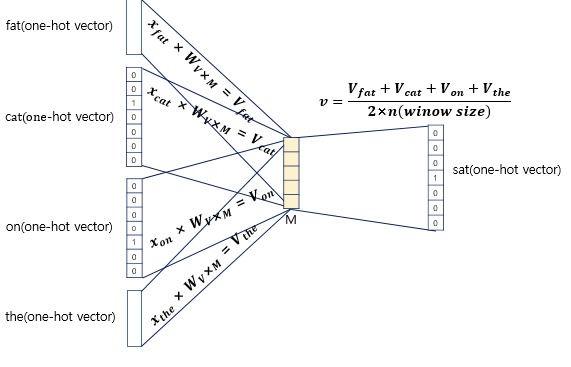
+) 만약 윈도우 사이즈가 2라면 입력 벡터의 총 개수는 2n이 된다. 즉 4개가 입력벡터로 사용된다.
+) 입력벡터의 평균을 구해 W’과 행렬 연산을 진행한다.
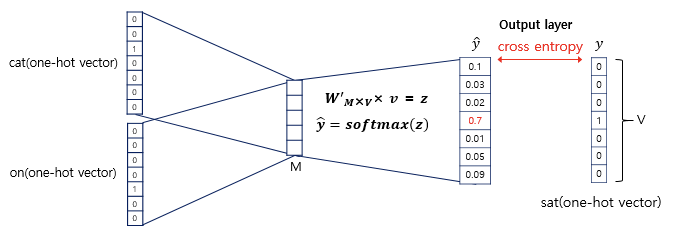
이후 softmax함수를 지나 원소의 합은 1이 되고, 손실함수(loss function)으로 크로스 엔트로피(cross-entropy)함수를 사용한다.
단어간의 조정되는 과정은 아래 링크를 통해 확인할 수 있다.
시각화 : https://ronxin.github.io/wevi/
설명 : https://docs.google.com/document/d/1qUH1LvNcp5msoh2FEwTQAUX8KfMq2faGpNv4s4WXhgg/pub
- Skip-Gram : 중간에 있는 단어들을 입력으로 주변 단어를 예측하는 방법
Reference : https://wikidocs.net/22660
Glove : 카운트 기반과 예측 기반을 모두 사용하는 방법론 - 단어 임베딩 방법론. LSA(Latent Semantic Analysis)-(카운트 기반)와 Word2Vec(예측 기반) 단점 보완하는 목적
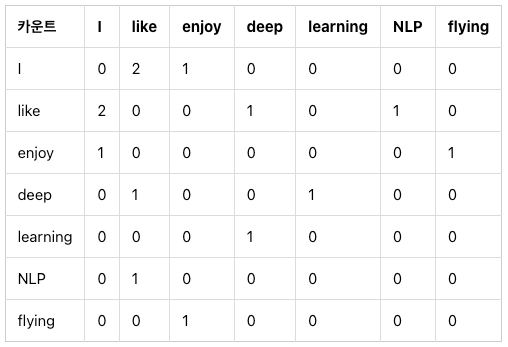
- I like deep learning
- I like NLP
- I enjoy flying
3개의 문장이 있다고 할 때 N X N 행렬을 만들어 준다
동시 등장 확률 (Co-occurrence Probability) : 조건부 확률을 바탕으로 단어간의 관계 비율을 작성해 놓은 것
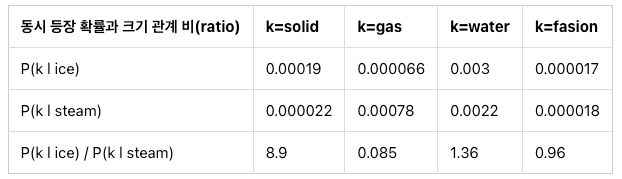
위의 표에서는 solid라는 단어가 나왔을때 ice가 나올 확률이 steam보다 8.9배 크다는 것을 보여줌
Loss Function(손실함수)
log P_{ij}의 경우 값이 커질 때 증가폭이 작아지도록 한다. 예를들어 the와 같은 경우는 co-occurrence값이 매우 높에 나올 가능성이 큰데 이 때 fitting시 neural net이 집중할 가능성이 높기 때문에 변환을 커져 사용한다.
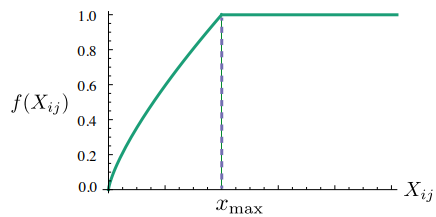
f(P_{i,j}) 의 경우 아래의 그림과 같이 빈도수가 일정 숫가 이상일 때 learning rate를 고정시켜주는 역할을 한다.
Reference : https://wikidocs.net/22885
