
💻 프로젝트 소개
- kaggle의 다양한 버섯의 정보를 이용하여 다중 분류를 통해 식용 버섯 유무를 판단할 수 있는 모델을 만드려고 한다.
[데이터셋 출처]
https://www.kaggle.com/datasets/uciml/mushroom-classification
📁 데이터셋
[데이터셋 구성]
- class: p-독성, e-식용
- cap-shape: 버섯의 모자 모양(bell=b, conical=c, convex=x, flat=f, knobbed=k, sunken=s)
- cap-surface: 버섯의 모자 표면(fibrous=f, grooves=g, scaly=y, smooth=s)
- cap-color: 버섯의 모자 색상
- bruises: 버섯에 멍이 들었는지 여부(bruises=t, no=f)
- odor: 버섯의 냄새
- gill-attachment: 버섯의 주름 부착 방식(attached=a, descending=d, free=f, notched=n).
- gill-spacing: 주름 사이의 간격(close=c, crowded=w, distant=d)
- gill-size: 주름 크기를 나타냅니다 (broad=b, narrow=n).
- gill-color: 주름 색상
- stalk-shape: 줄기 모양(enlarging=e, tapering=t).
- stalk-root: 줄기의 뿌리 부분 모양
- stalk-surface-above-ring: 반지 위의 줄기 표면
- stalk-surface-below-ring: 반지 아래의 줄기 표면
- stalk-color-above-ring: 반지 위의 줄기 색상
- stalk-color-below-ring: 반지 아래의 줄기 색상
- veil-type: 베일(버섯의 부속물)의 종류
- veil-color: 베일의 색상
- ring-number: 반지의 수(none=n, one=o, two=t).
- ring-type: 반지의 종류
- spore-print-color: 포자 자국의 색상
- population: 개체군의 분포 형태
- habitat: 버섯이 자라는 환경
[EDA]
- 먼저 결측치가 있는지 확인해보았는데 결측치가 있는 칼럼은 없었다.
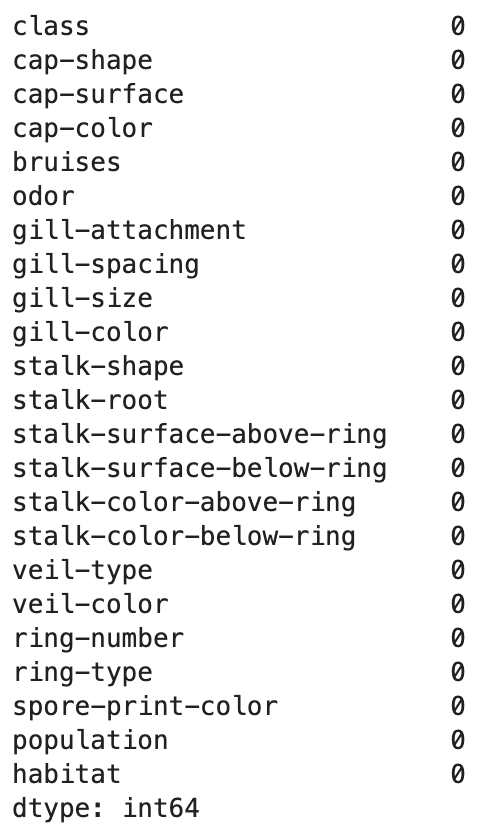
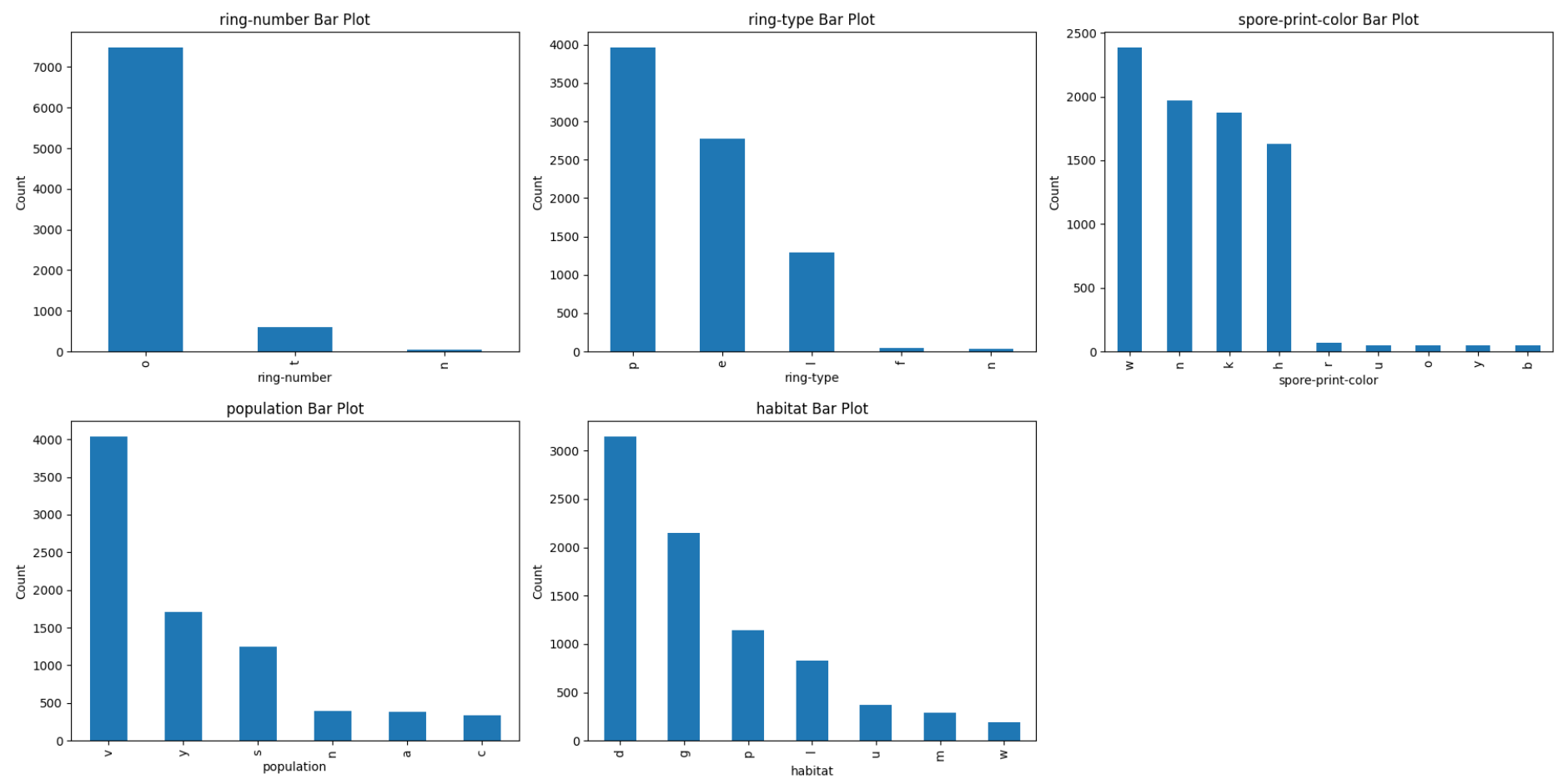
- 모든 칼럼의 바 그래프를 그려보았다.
식용 버섯인것과 아닌것의 비율은 거의 비슷했다.
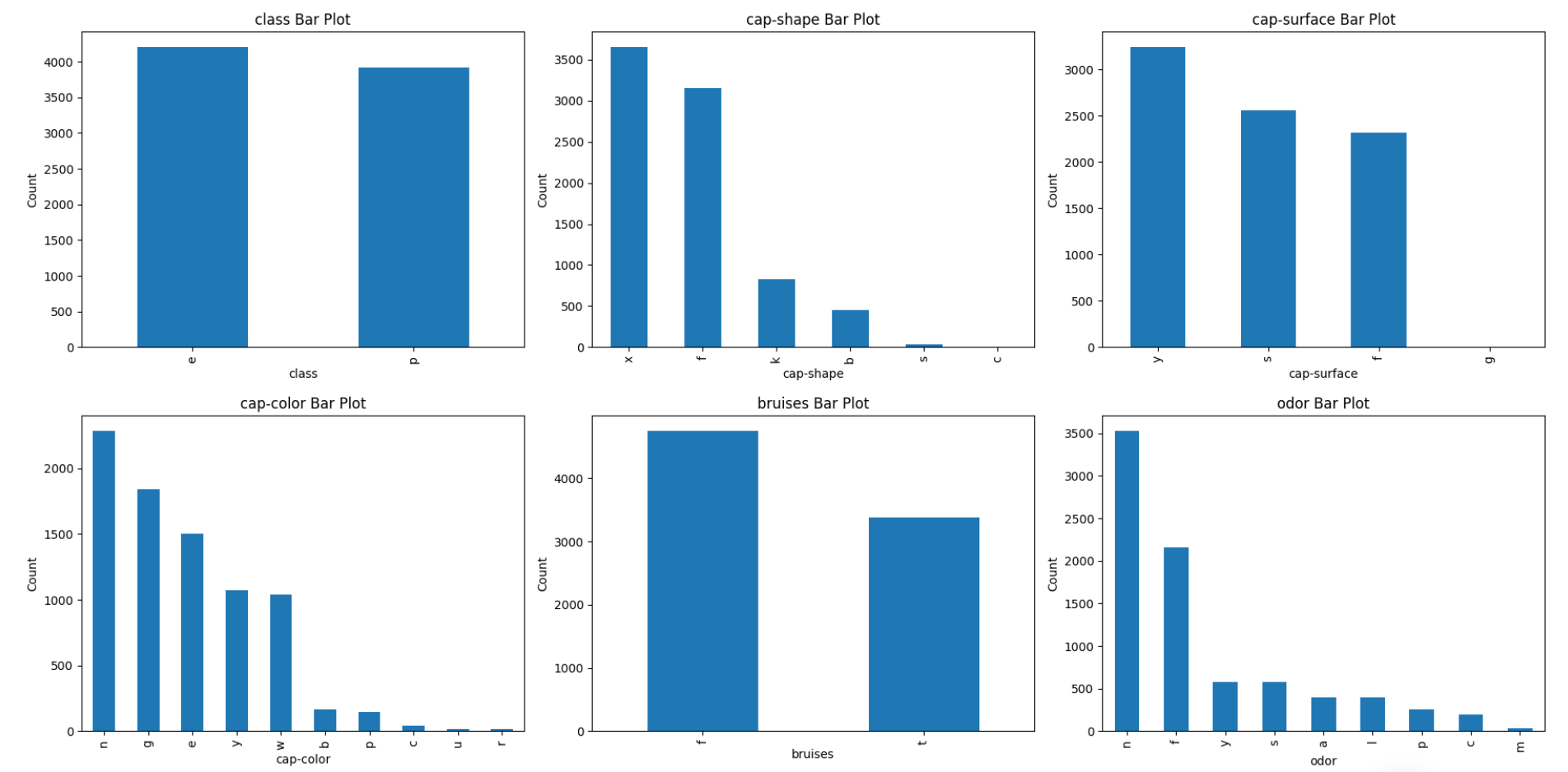
- 주름 부착방식은 대부분 'a' 형태를 띄었으며, 베일 색상은 대부분 'w'었다.
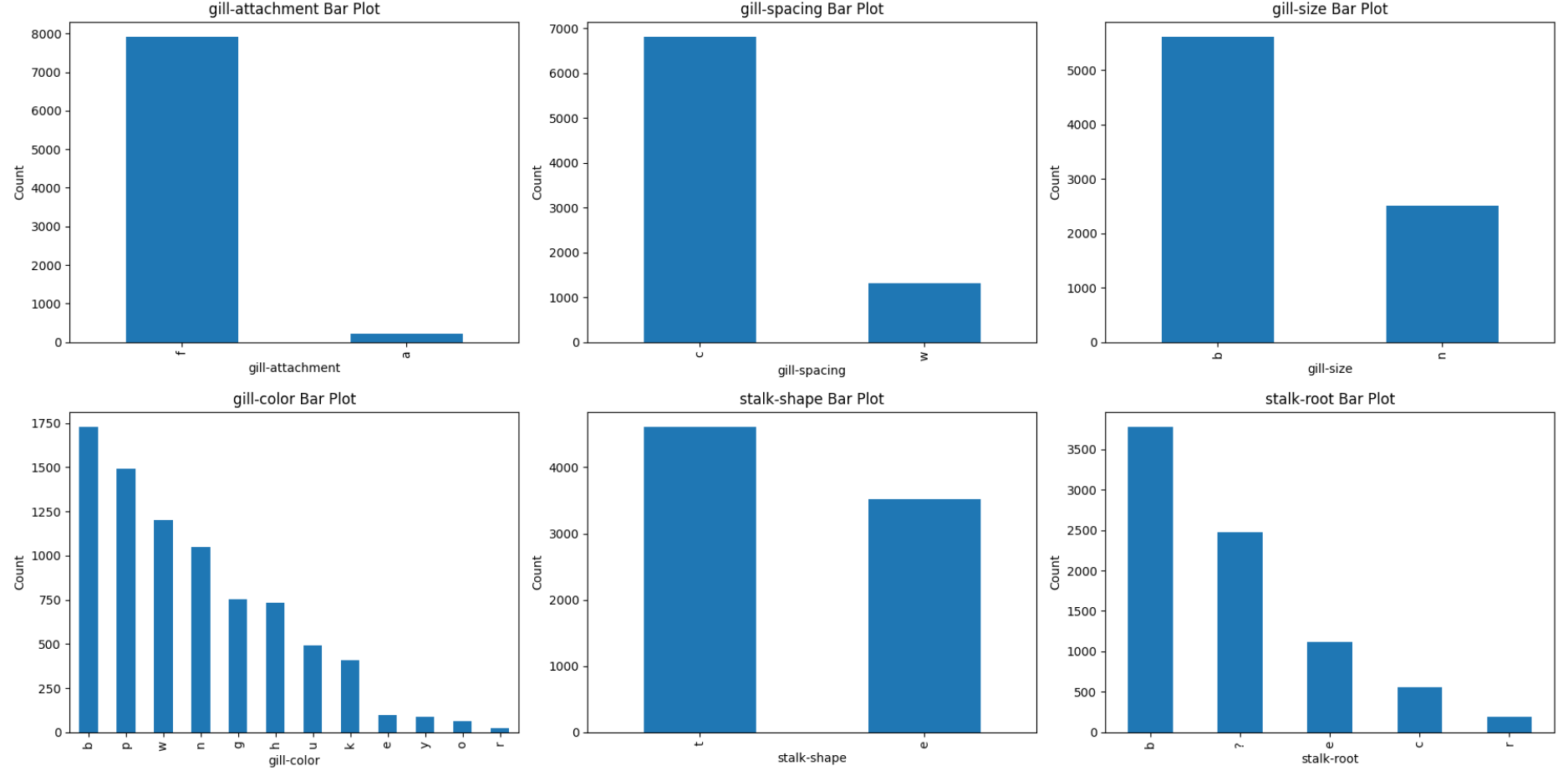
- 베일 종류는 한 종류로 이루어져있었다.
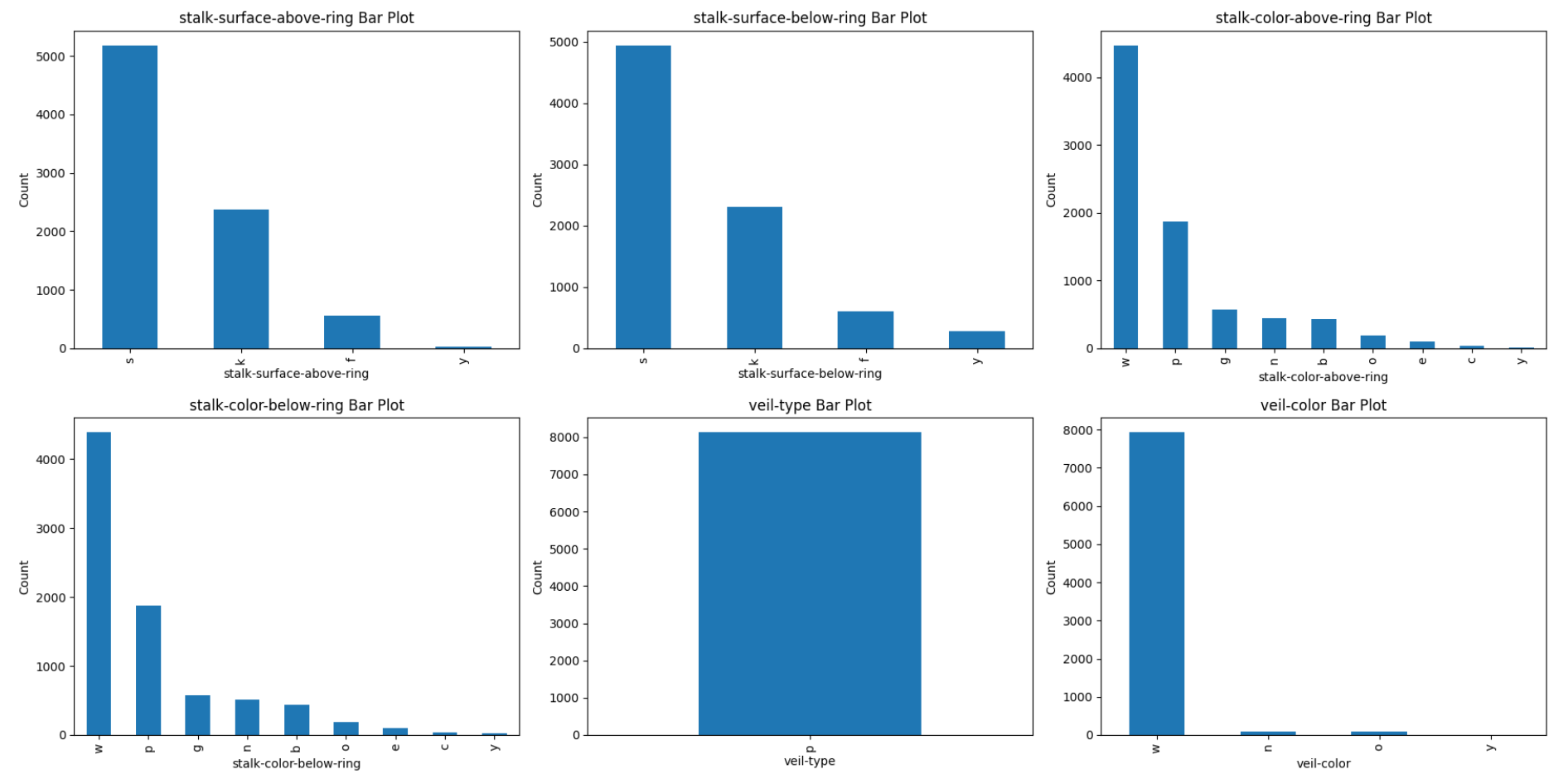
- 한개의 링을 갖고 있는 버섯이 가장 많았다.
[전처리]
-
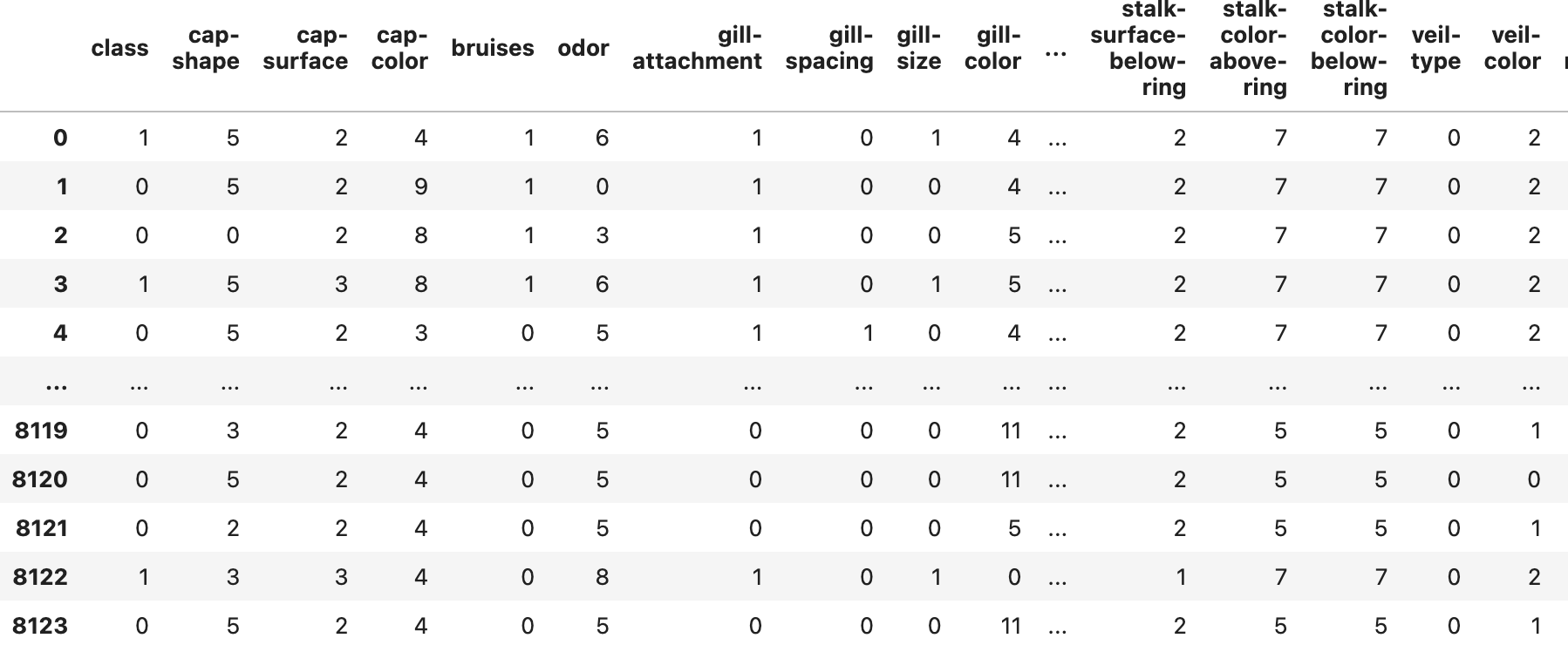
모든 칼럼이 범주형 데이터로 구성되어 있기 때문에 라벨 인코딩을 해주었다.
원-핫 인코딩과 고민을 했으나 인코딩 전에도 22개의 칼럼으로 되어있는 데이터셋을 원-핫 인코딩을 하게되면 데이터 용량이 너무 커지는 현상이 발생할 것 같아 라벨 인코딩으로 진행했다.
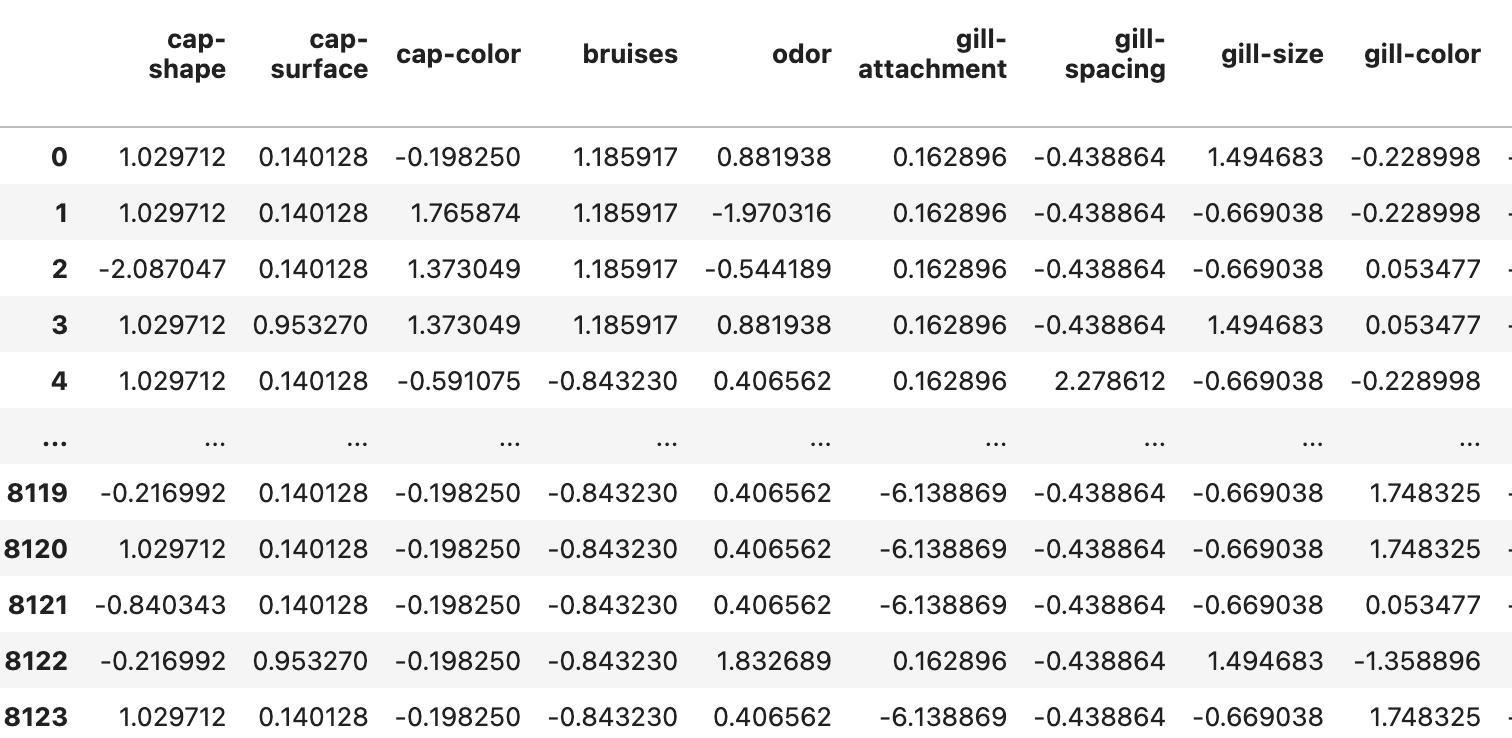
-
standard scaler를 사용하여 정규화를 해주었다.
🔨 Multi-class Classification
-
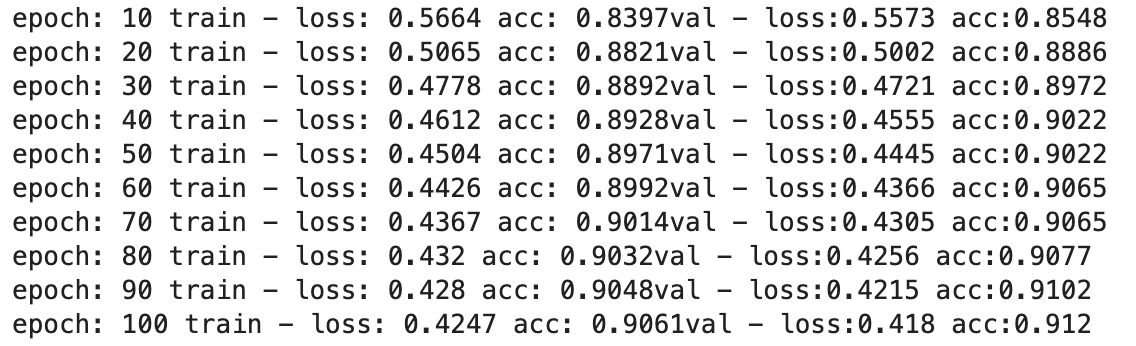
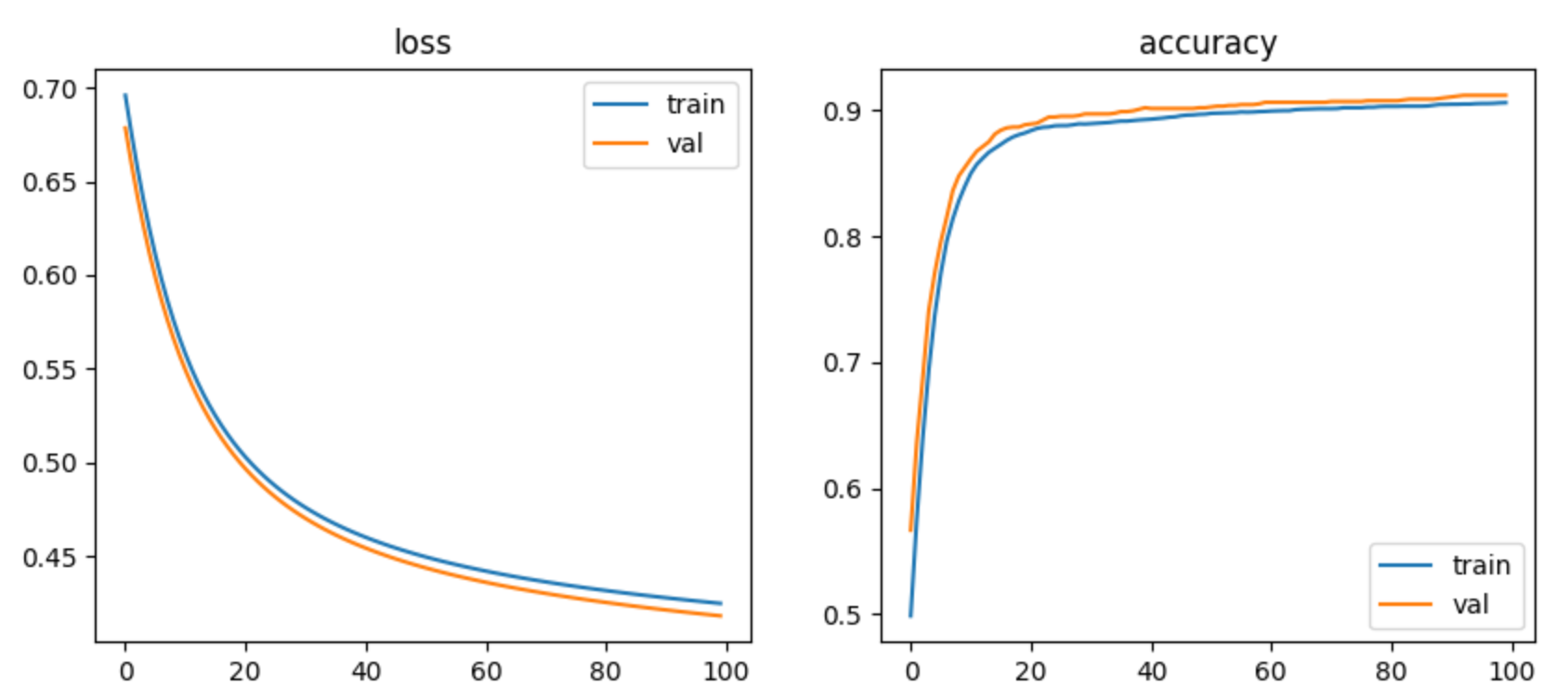
에포크를 100으로 해서 다중 분류를 진행했다.
에포크가 반복될 때마다 오차는 감소하고 정확도는 상승했다.
또한 100번 진행된 후의 정확도는 0.9로 매우 높은 정확도를 보여주었다.
-
오차와 정확도를 그래프로 그리면 아래와 같다.
💡 Insingt
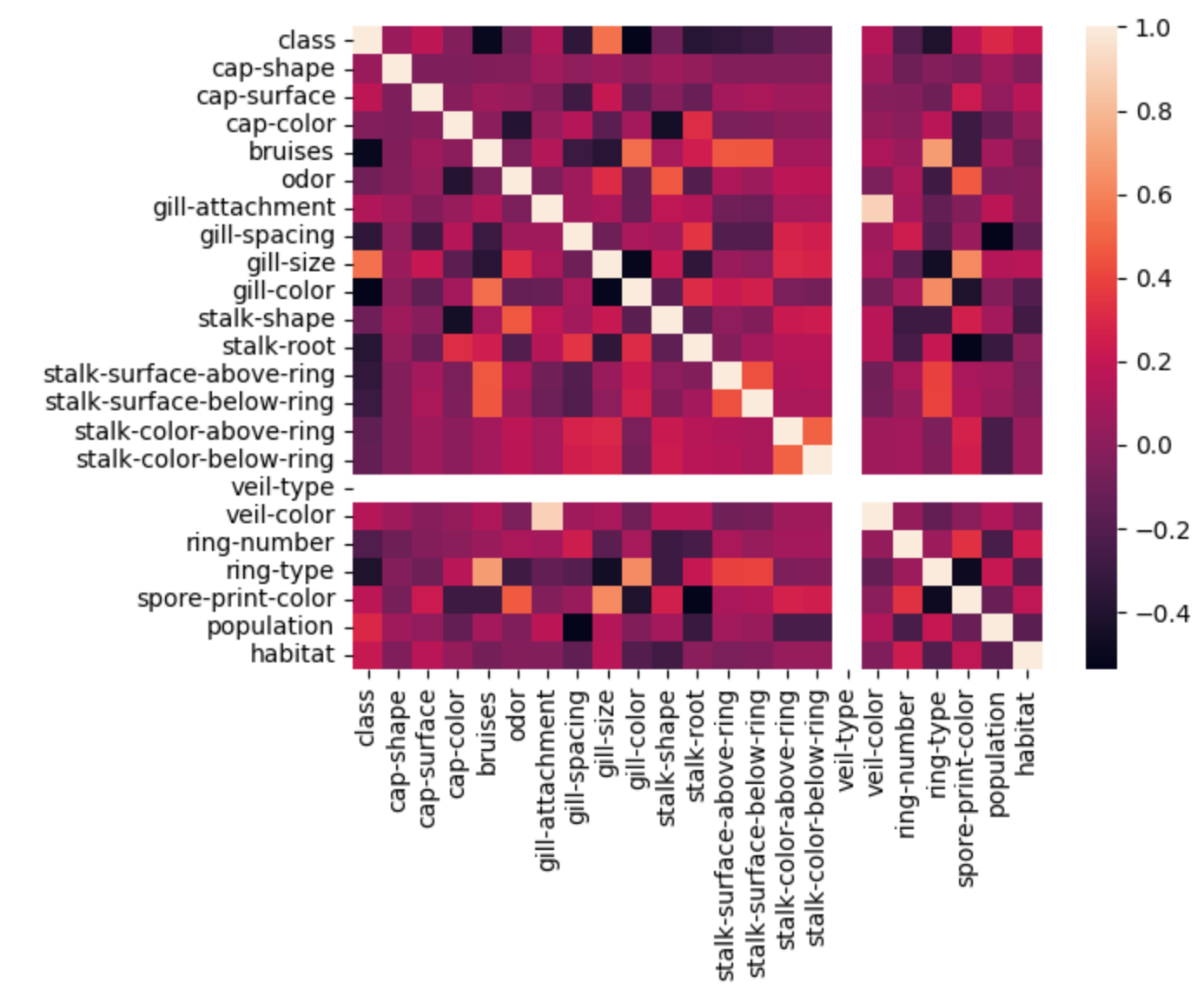
- 칼럼들의 상관성을 히트맵으로 그려보았을 때 class는 bruises(버섯에 멍이 있는지 유무), gill-size(주름 크기), gill-color(주름 색상), ring-type(링 타입)과 높은 상관성을 나타냈다.
정말로 위의 요소들이 독버섯과 아닌 버섯을 구분하는데 사용되는지 찾아본 결과 육안으로 독버섯을 구분하기는 어렵다고 한다.

💻🐜💡