
💻 프로젝트 설명
- 타이타닉 데이터셋을 이용하여 MLP Classification을 통해 생존자 분류 모델을 만들어보고자 한다.
📁 데이터셋
[데이터셋 구성]
- PassengerId: 탑승객 아이디
- Survived: 생존 유무
- Pclass: 등급
- Name: 이름
- Sex: 성별
- Age: 나이
- SibSp: 타이타닉에 탑승한 형제자매/배우자 수
- Parch: 타이타닉에 탑승한 부모/자녀 수
- Ticket: 티켓 번호
- Fare: 요금
- Cabin: 객실 번호
- Embarked: 승선지
[EDA]
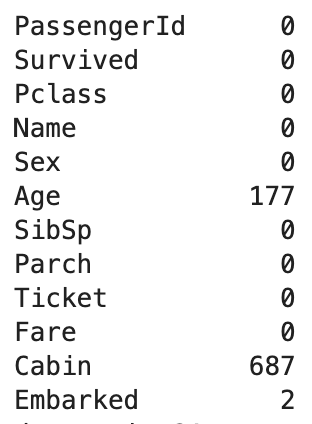
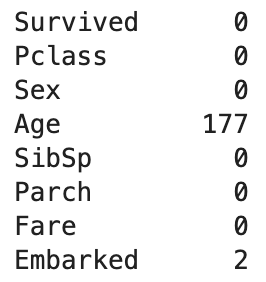
- 먼저 결측치를 조회해보았을 때 나이, 객실 번호, 탑승지 칼럼에 결측치가 존재했다.
-
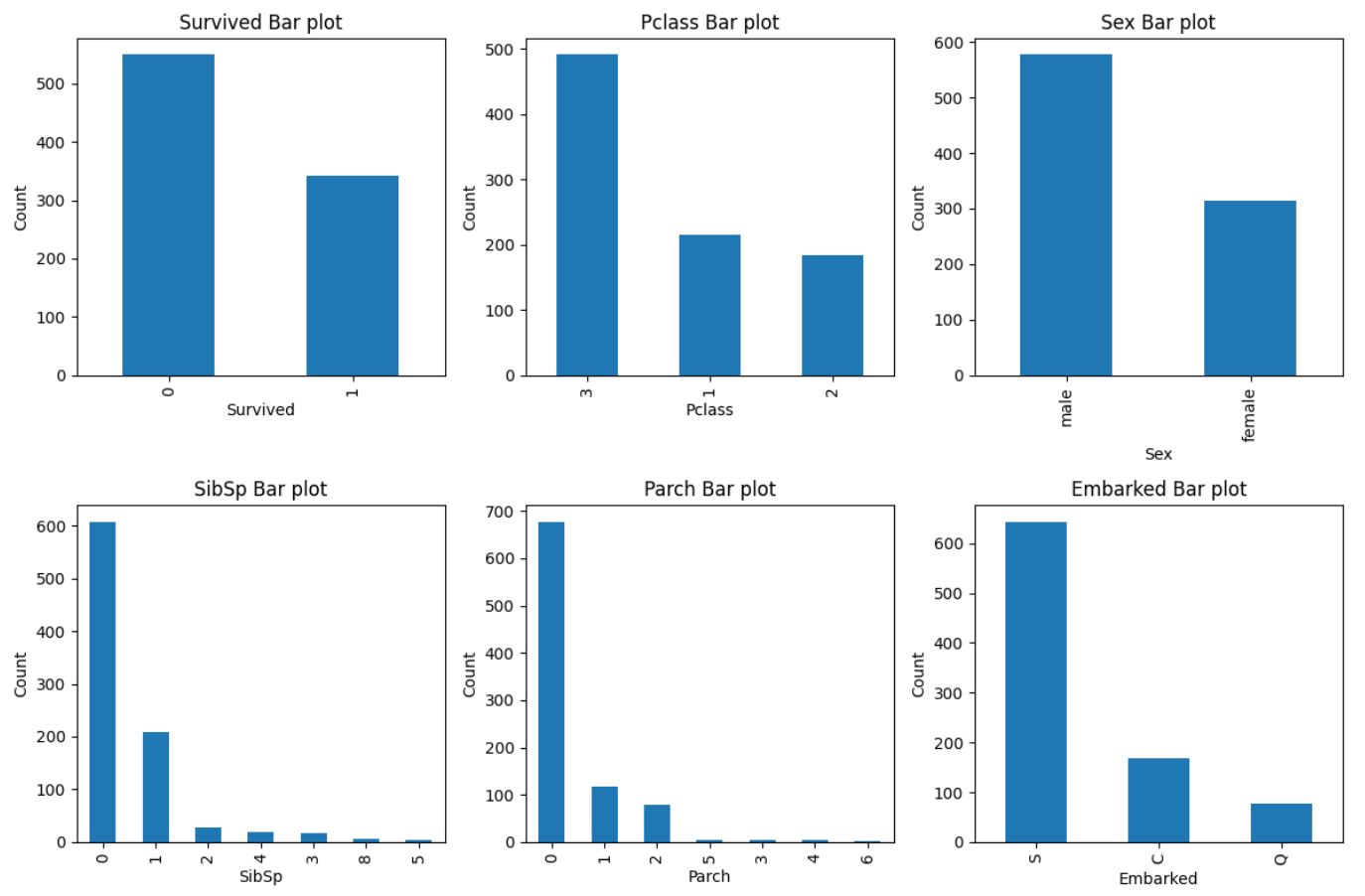
나이, 요금을 제회한 칼럼들의 그래프를 그려보았다.
먼저 Survived에서 0이 사망, 1이 생존을 나타내는데 사망 비율이 더 높았다.
객실 등급은 3등급이 가장 많았고, 성별은 남성이 여성보다 많았다.
타이타닉에 탑승한 형제자매/배우자 수와 부모/자녀 수는 0명이 가장 많았고, 승선지는 Southampton이 가장 많았다.
-
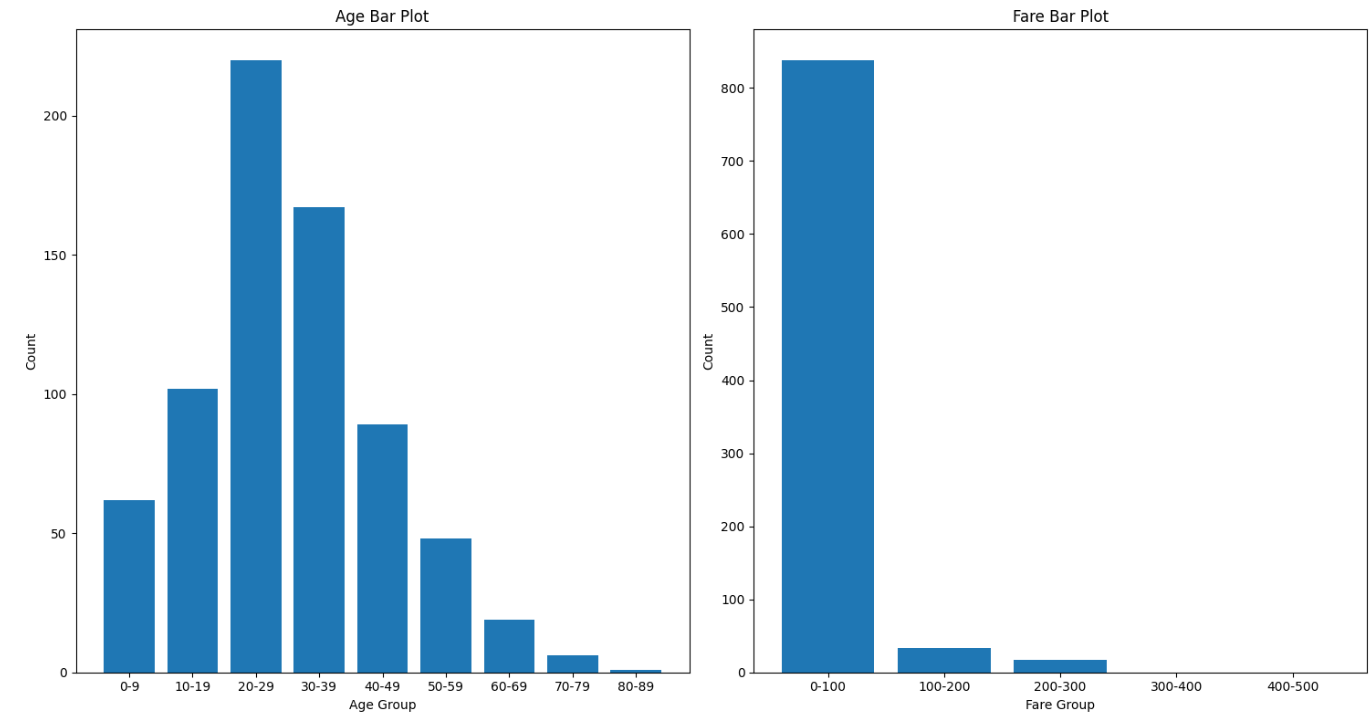
나이, 요금 그래프를 보면 20대 탑승객이 가장 많았으며, 10-100 사이의 요금을 내고 탑승한 승객이 대부분이었다.
-
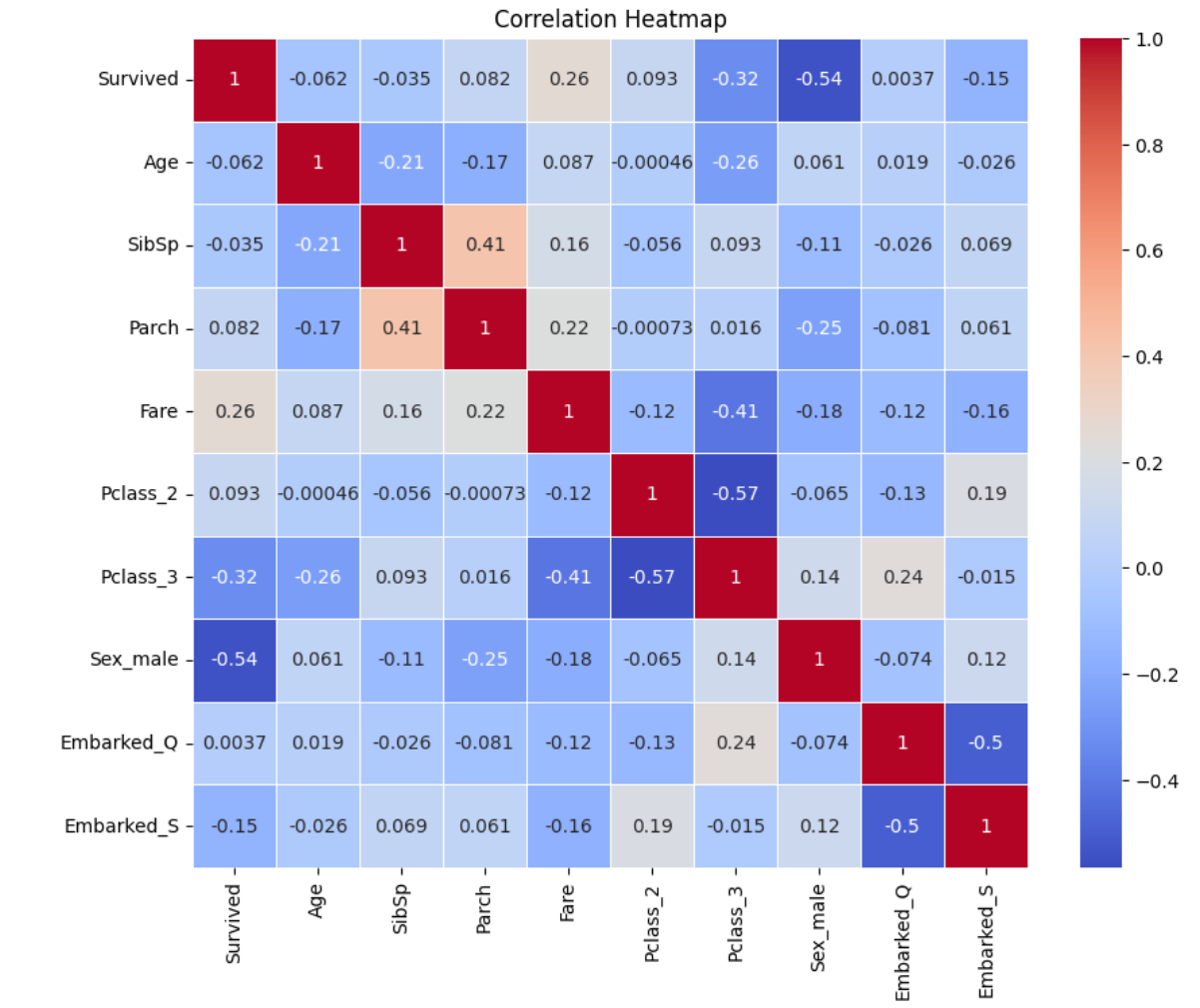
상관관계를 그래프로 나타내었을 때, 의외로 나이는 생존과 크게 연관이 없었다.
가장 생존여부와 관련이 높았던 항목은 성별이었다.
🔨 Multilayer Perception Classification
[Preprocessing]
-
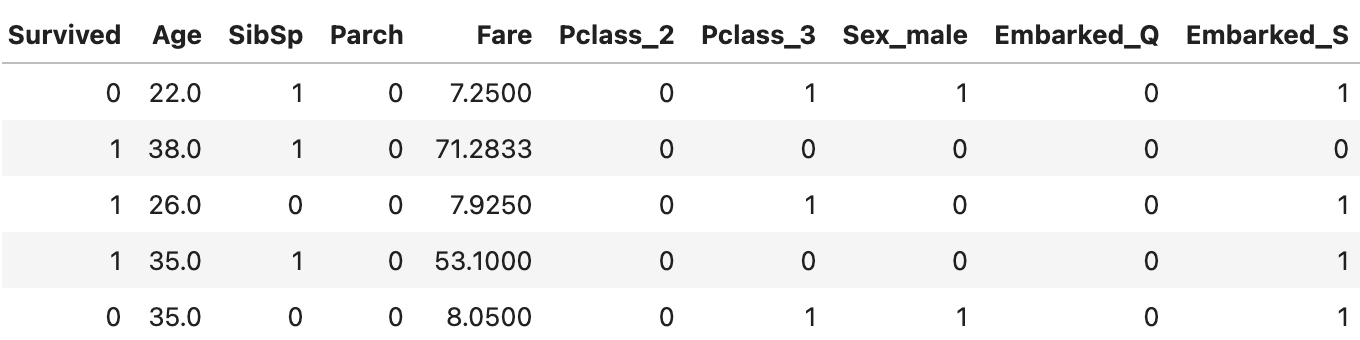
모델 학습에 필요가 없다고 판단되는 "PassengerId", "Ticket", "Name", "Cabin" 칼럼을 drop 해주었다.
그리고 다시 결측치를 조회해보니 Age와 Embarked 칼럼에 여전히 결측치가 존재했다.
따라서 Age는 보간법으로 결측치를 처리하였고, Embarked는 최빈값으로 넣어주었다.
-
범주형 칼럼인 Pclass, Sex, Embarked는 원-핫인코딩을 해주었다.
-
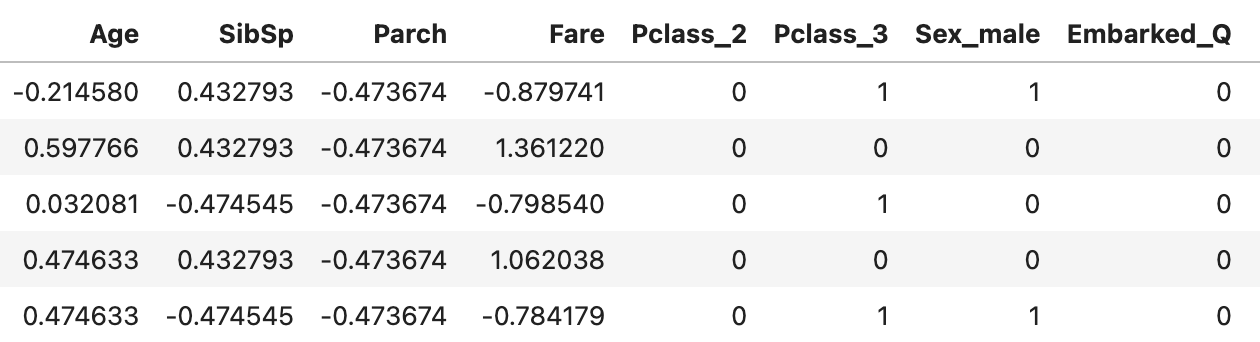
왼쪽으로 치우친 모양을 보인 Fare, Age는 로그를 취해준뒤, Age, Fare, Parch, SibSp는 정규화했다.
[Machine Learning]
-
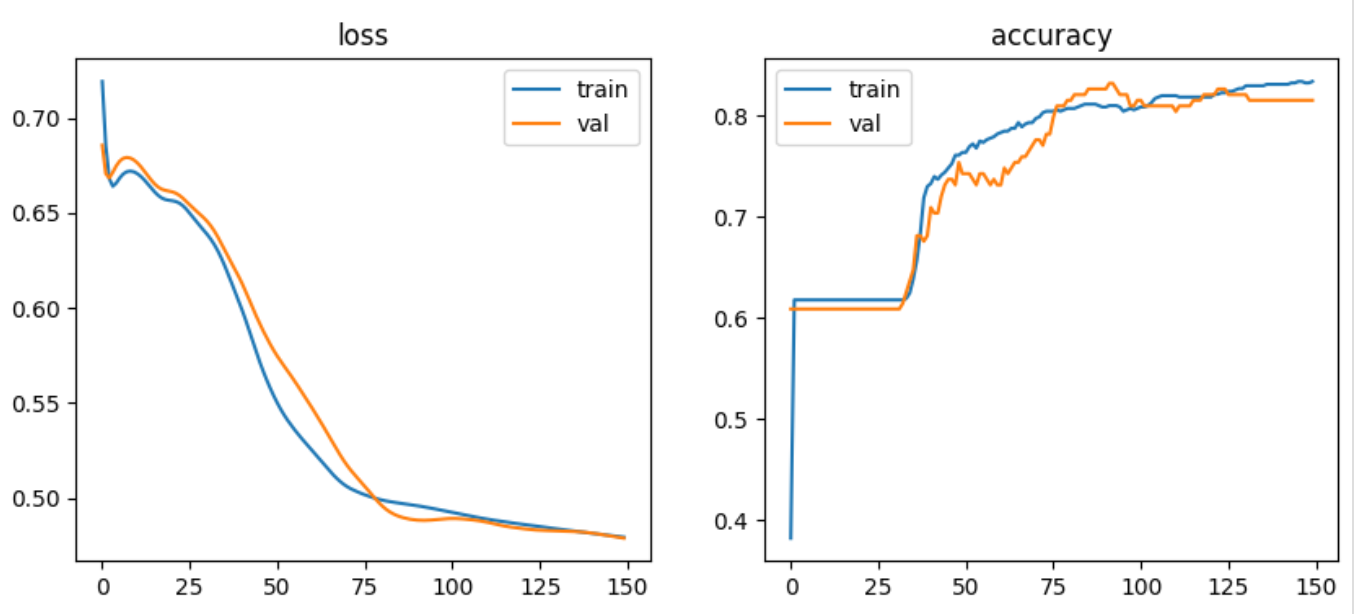
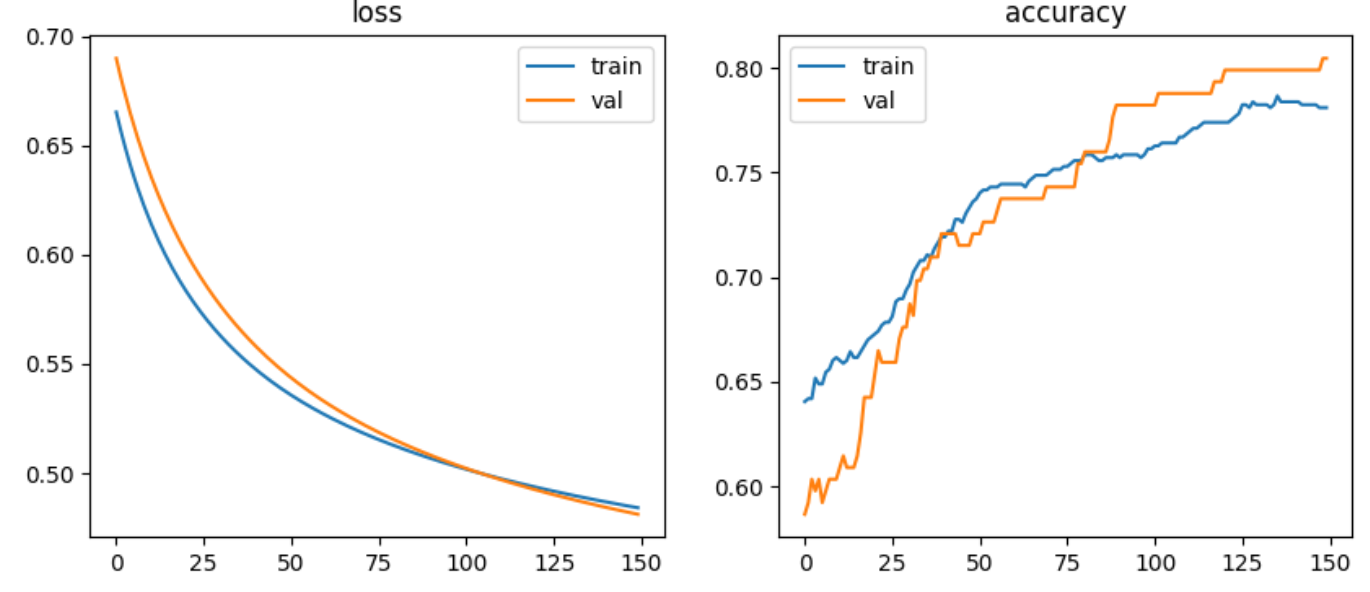
은닉층 뉴런수를 32로 설정하고, learning-rate는 0.01, epoch는 150으로 주었을 때 결과이다.
여기서 뉴런수를 epoch를 줄이고 늘려보았을때, 정확도가 크게 변화가 없거나 오히려 낮아지는 경향을 보였다.

-
오차와 정확도 그래프를 보면 epoch가 진행될수록 오차율은 낮아지고, 정확도는 올라가는 경향을 보이고 있다.
최종 정확도가 약 0.82 나온것을 보면 분류 성능이 괜찮은 모델을 만든것 같다.
💡 Insight
- MLP Classification 모델을 Logistic Regression 모델 결과와 비교해보았다.
로지스틱 회귀 모델에도 동일한 전처리를 해주었고, 동일한 칼럼을 사용했다.
로지스틱 회귀 모델의 정확도는 약 0.80 정도로 MLP 분류 모델이 조금 더 좋은 성능을 보였다.
 |  |
|---|
- loss 그래프에서 로지스틱 회귀 모델은 매끄러운 곡선인 것에 비해 MLP 모델은 매끄럽지 못한 곡선을 보였다.
검색해본 결과 이런 현상이 발생한 이유는 학습률 문제로 보인다. 학습률이 너무 크면 최적의 지점을 지나칠 수 있고, 학습률이 너무 작으면 학습이 느려질 수 있다. 이러한 불안정한 학습률 설정은 loss 그래프를 꼬불거리게 만들 수 있다.
따라서 학습률을 높여도 보고 낮춰도 보았으나 정확도가 형편없이 낮게 나와 원래대로 0.01로 설정하였다.
