그런 당신을 위해 논문을 준비했습니다! ResNet 편. Deep Residual Learning for Image Recognition 논문 리뷰
원문 : https://arxiv.org/abs/1409.1556
Deep Residual Learning for Image Recognition 논문을 리뷰해보겠다.
그리고 틀린점이 충분히 있을 수 있다. 발견하신다면 여지없이 댓글달고 혼내주세요. 많이 배우겠습니다.
왜 이 논문이 중요한가?
resnet이라는 녀석을 통해 ILSVRC 2015에서 1위를 차지했다.
layer가 깊어지면 깊어질수록 여러문제들이 발생하는데 이를 resnet을 통해 좋은 결과를 보여주었다.
그럼 resnet이란 녀석을 알아보러 떠나보자.
1.Introduction
연구자들은 한 질문에서부터 시작한다.
Is learning better networks as easy as stacking more layers?
더 좋은 모델을 학습하는게 층을 쌓는 것처럼 쉽나??? 라는 질문이다.
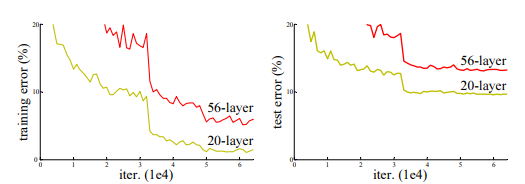
위 표는 56-layer 와 20-layer를 쌓았을 대를 비교한 것이다.
같은 epoch에서 얕은 layer와 깊은 layer를 비교해 보았을 때, 오히려 얕은 layer가 더 error가 낮았다!
이는 overfitting(과적합)문제가 아니라 너무 깊은 층은 오히려 error를 높힌다는 것을 의미한다.
아니 왜 overfitting의 문제가 아니죠? 왜why?
만약 overfitting이 문제였다면 56-layer에서 training error는 적게 나오고, test error는 높게 나왔어야 overfitting(훈련 data에만 높은 accuracy를 보이는 것)이지만, 위의 표를 확인해보면 그렇지 않다!
-> overfitting이 아닌 다른 문제!
연구자들은 이것은 degradation problem문제라고 말한다.
층이 너무 깊기 때문에 너무 많은 값이 곱해져 과도하게 늘어나거나(exploding(기울기 폭발)), 0~1사이의 값이 너무 많이 곱해져 값이 너무 적어지거나(vanishing(기울기 소멸)) 하는 문제가 발생한다는 것이다.
음 .. 그럼 어떡하나요? 너무 얕게 쌓으면 underfitting이 되고, 너무 깊게 쌓으면 degradation problem이 발생하는데???
그런 당신을 위해 준비했습니다! Residual learning!
연구자들은 이런 고민을 하는 당신을 위해서 멋진 그림을 하나 준비했다.
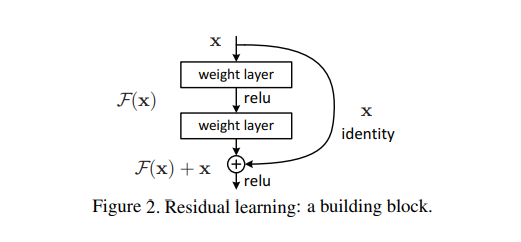
자 너무 겁먹지 말고 천천히 가보자.
F(x)는 우리가 주로 사용하는 일반적인 net 형태이다.
원래 방식 : x -> (layers) -> output
residual learning : x -> (layers) -> output + x (identity)
여기서 달라진건 마지막에 x(identity)를 더해주는 것이다. 쉽다.
??? 이게 뭔.. 왜 갑자기 x를 더하는 거에요
이해한다.
나도 처음에 "?? 좋은 방법이긴한데 왜 하필 x를 더하는거야??" 라는 생각이 들었다.
사실 이 질문의 처음은 조금 다른 생각에서 비롯되었다.
"층이 너무 많으면 optimize하기 힘들다."
".. 그럼 optimize를 더 잘하기 위해서 목표를 바꾸는건 어때?"
라는 생각이다.
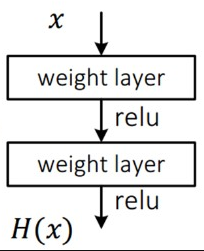
논문에서 원래의 plain net에서의 목표를 H(x) 라고 정하였다.
원래는 H(x)를 가장 적게(최소화)하는 것이 목표 였다. 그러나 x(입력값)이 어떻게 들어올지 모르는 상태에서 H(x)를 가장 적게 만드는 것은 어려운 일이라고 연구자들은 말한다.
그래서 연구자들은 y(output,F(x))값을 x에 연관되게 하면 연산이 쉬워지지 않을까? 라는 생각을 하게 된다.
그래서 H(x)(목표) = (resnet에서의 F(x)) + x 라는 생각을 했다.
따라서 H(x)(목표)를 가장 낮게 하려면, F(x) = -x 여야한다.
이렇게 하면
plain net : 갑자기 모르는 입력값(x)에서 0이 되게 하는것에서
resnet : 입력값(x)을 모르지만 F(x)를 통해 -x가 되게끔 만드는것으로
F(x)의 역할이 변한다.
그래서 더욱 잘 optimize 할 수 있는것이다.
믿지 못하는 사람들을 위해서 연구자들은 실험을 통해 2가지를 증명한다.
1. plain net(residual learning을 쓰지 않은 net을 plain net이라고 한다)보다 resnet이 accuracy가 더 높다.
2. plain net보다 resnet이 더 빠르고 쉽게 결과를 얻는다.
자 그럼 연구자들을 따라서 결과를 구경해보자. let's go.
Implementation
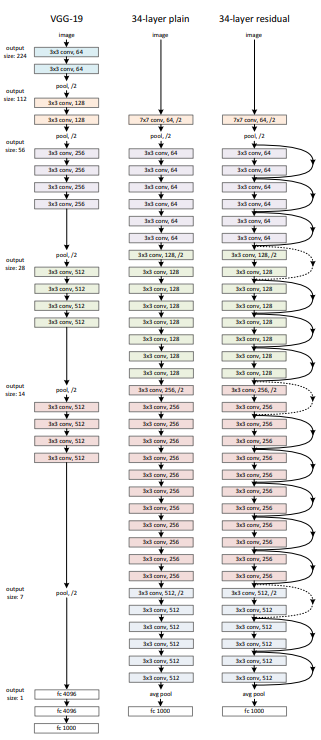
비교를 위해서 VCG-19를 plain net(아무것도 하지 않은 기본 네트워크)으로 설정하였다.
이미지는 짧은 쪽을 기준으로 256,480 으로 resized 하였고, 224 x 224로 randomly 하게 crop하거나 horizontal flip을 하고, per-pixel mean subtracated를 하였다.
(이걸 왜하는지 잘 모르겠다면 전 글을 살짝 참고하고 오자!)
이전글 : 이전글 링크!
BN : convolution 이후, activation 이전에 적용
mini batch : 256
epoch : 60 x 10e5
...
등등 어떤 hyperparameter를 사용했는지 알려주고 있다.
experiment
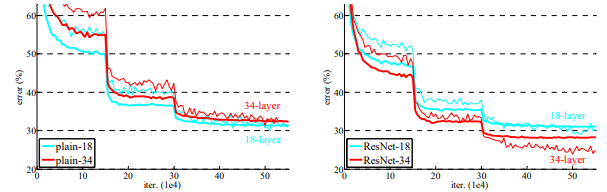
위의 그림은 plain 18,34 layers,ResNet 18,34 총 4개를 비교한 사진이다.
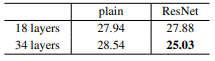
top-1 error를 표로 표시하면 다음과 같다.
plain net
여기 plain net 18 보다 plain net 34 이 top-1 error 가 더 높은데,
여기서 연구자들은 이 optimization difficulty가 vanshing gradients 때문이 아닐것이라고 생각한다고 한다.
forward propagated signals 에서 non-zero variances를 쓰지 않았을 뿐더러,
backword propagated gradients 들을 healthy norms을 BN과 같이 썼기 때문이다.
그럼 forward sign에서도 backward sign에서도 vanish가 일어나지 않았을것이라고 설명한것이다.
-> 따라서 위에서 말한 optimization difficulty(optimization이 어려운것!)이 vanishing gradients때문이 아니다!
Ressidual Net
resnet에서도 똑같이 3x3 filter를 사용했고, identity mapping(x를 더해주는 것)과 zero-padding을 하였다.
zero padding은 뭐고 왜 하나여??
위에서 봤듯이 identity mapping(x를 더해주는 것)을 하면,
(기존의 x) 와 (3x3 layer를 통과한 x)를 더해줘야 하는데, 3x3 layer을 통과하면 filter의 수만큼 차원이 늘어나버린다. 그래서 예를들어
(기존의 x) = 1차원
(3x3 layer를 통과한 x) = 9차원
이렇게 차원이 맞지 않아버린다. 그래서 이 차원을 맞추기 위해서 나머지 값들을 0으로 맞춰주는 것을 zero-padding이라고 한다!
본론으로 돌아와서, 표에서 보면 Resnet - 18의 error 보다 Resnet - 34의 error 이 더 낮다!
-> layer가 깊어져도 degradation problem을 잘 해결하고 있다! -> resnet 짱짱!
두번째로!
resnet이 plain net보다 더 error가 낮다!
-> resnet 적용하니 error가 더 낮아졌다! -> resnet 짱짱!
세번째로!
resnet 18이 plain net보다 acc가 높고 빨리 학습됨.
-> not overly deep(너무 깊지 않게 18층만 쌓아도!) 에서도 resnet이 효과적임 -> resnet 짱짱!
결론 -> resnet 쓴게 안쓴것보다 좋아용!
Identity vs Projection Shortcuts
위에서 단순히 zero padding을 이용한다고 했는데, 연구자들은 조금 더 들어가서 zero padding을 쓰지 말고 이것도 x에 맞게 하면 어떨까? 라고 생각했다.
그래서 세개의 군으로 나누어서 실험하였다.
(A) 그대로 x 넣기 +증가하는 차원에 대해서만 zero padding하기(모든 shortcut은 parameter free -> 왜why? 다 0으로 넣어버리기 때문!)
(B) 그대로 x 넣기 + 증가하는 차원에 대해서만 projection shortcut(x에 1x1 conv를 사용한 녀석!)적용 하기
(C) 모든 녀석을 projection shortcut 적용하기
결과는?
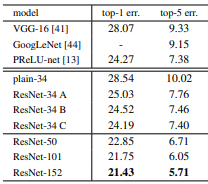
C 우승!
그러나 연구자들은 저렇게 모든 녀석을 다 projection shortcut을 적용하면 메모리가 터져버려서, 결과는 좀 안좋지만 메모리를 적게 사용하는 A를 사용했다고 한다.
결과적으로 A 우승!
자 이제 본격적으로 많이 쌓자보자!

그전에 문제가 조금 있다.
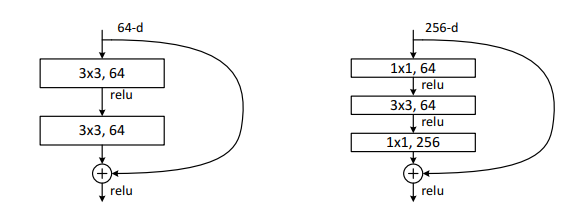
왼쪽 방식은 3x3을 두번 쌓는것이고,
오른쪽 방식은 1x1, 3x3, 1x1으로 3번 쌓는 것이다.
오른쪽 방식을 bottle neck 방식이라고 하는데 오른쪽을 이용하면 차원과 model size를 너무 크게 하지 않으면서 non linear 하게 계산할 수 있다.
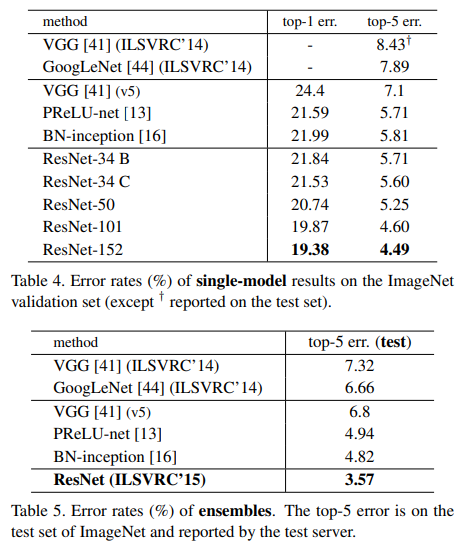
그래서 연구자들은 열심히 층을 쌓아서 34, 50, 101, 152층까지 쌓았다.
이후 앞서 나온 모델들을 앙상블하여 ILSVRC 15 를 나갔고,
결국 King Of the ILSVRC'15가 되었다.
끗~~~
