그런 당신을 위해 논문을 준비했습니다! Inception-v4 편. Inception-ResNet and the Impact of Residual Connections on Learning 논문 리뷰
원문 : https://arxiv.org/pdf/1602.07261v2.pdf
Inception-ResNet and the Impact of Residual Connections on Learning 논문을 리뷰해보겠다.
그리고 틀린점이 충분히 있을 수 있다. 발견하신다면 여지없이 댓글달고 혼내주세요. 많이 배우겠습니다.
왜 이 논문이 중요한가?
Inception v1,v2,v3를 거쳐 v4로 마침내 resnet + Inception으로 방점을 찍은 논문이다.
현재 현업에서는 이 모델을 backbone으로 쓰고 있는지 모르겠지만, 빠른 시간과 정확성으로 한때 backbone으로 꽤나 쓰인것으로 알고있다.
다소 복잡하겠지만 열심히 해보자.
1. Inception v4의 구조
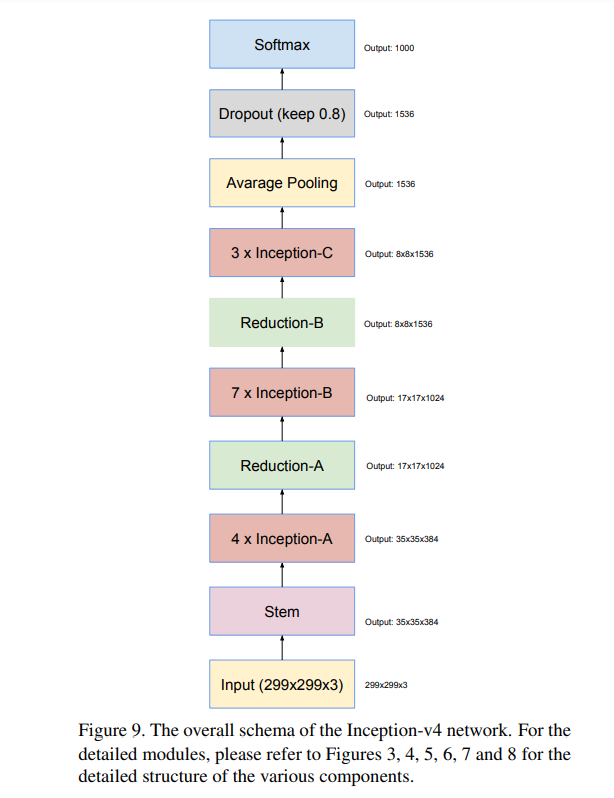
Stem, Inception-A, B, C, Reduction A, B, Average Pooling, Dropout, Softmax로 이루어져 있다.
아니 먼저 왜 이름이 inception인가요?? 영화랑 관련이 있나?
결론만 말하자면 있다.
기존 cnn은 일반적으로 한 층에 1개의 cnn만 사용했으나 밑에 보면 알 수 있듯이 inception 에서는 여러개의 cnn을 때려 넣었다.
영화에서 꿈속의 꿈속의 꿈속의 꿈속의 꿈속의... 처럼 하나에 여러개의 cnn을 때려박고 concat으로 마무리 하는것이다.
순서대로 차근차근 알아보자
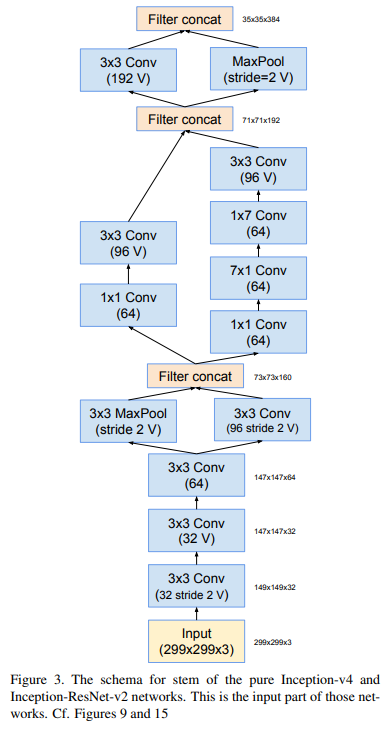
1-1. Stem
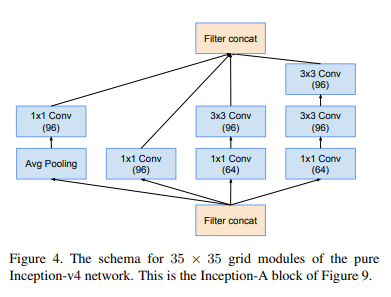
1-2. Inception-A
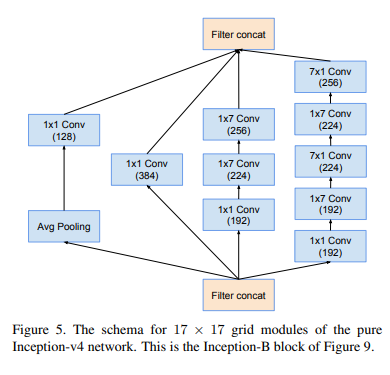
1-3. Inception-B
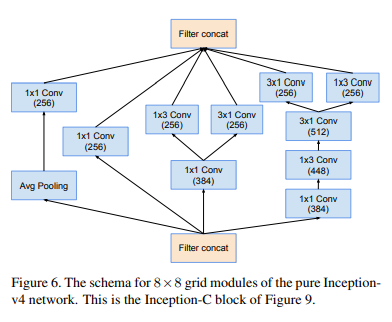
1-4. Inception-C
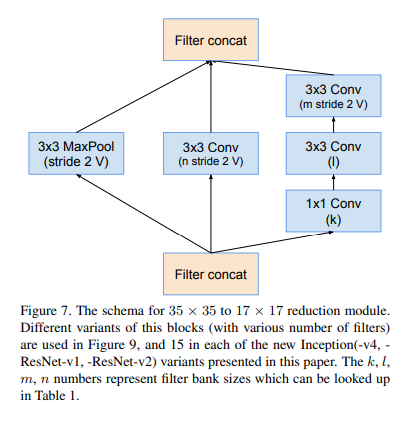
1-5. Reduction-A
1-6. Reduction-B
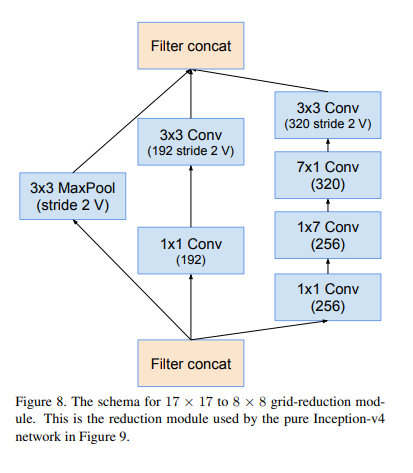
말로 설명하는 것보다 그림으로 설명하는 것이 빠르고 명확할것 같아서 그림으로 설명을 대체한다.
여기 괄호 옆에 V가 있는데 이건 뭔가요?
좋은 질문이다.
Conv, Maxpool 등의 layer이후에는 차원을 맞춰주기 위해 padding이 필요하다.
V 표시가 있는 것은 zero padding을 한 것이고,
V 표시가 없는 것은 zero padding을 안한 것이다.
2. resnet + inception
자 이제 Resnet(잔차) + inception을 해보자!
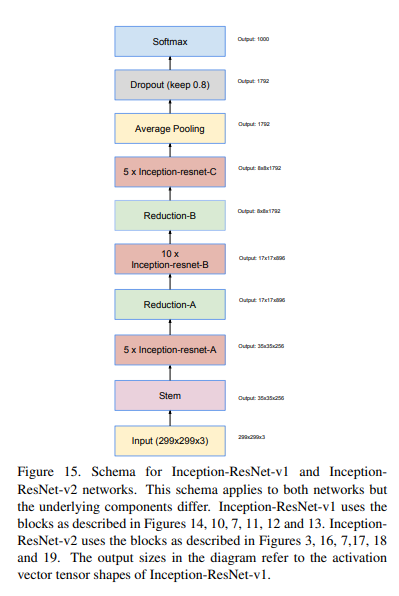
위 그림은 resnet + inception을 한 network에 전체적인 구조이다. inception만한 구조에서 중간중간 inception-resnet으로 바뀐 것을 알 수 있다.
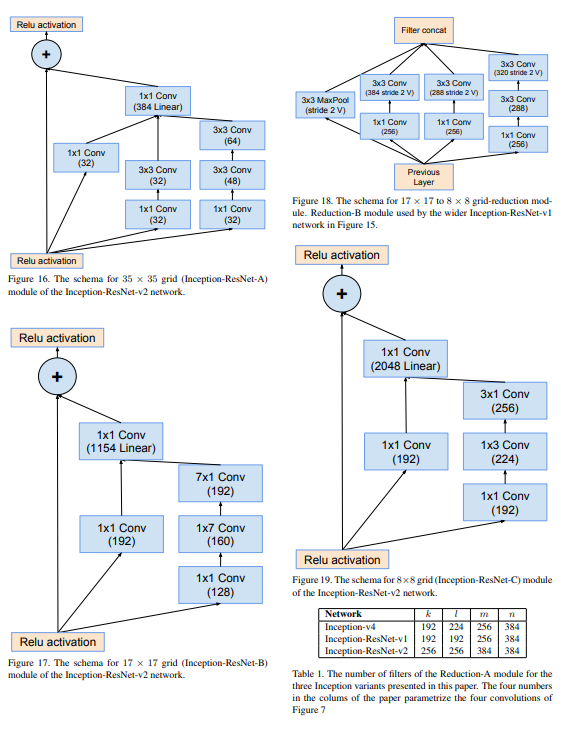
너무 많아질 것 같아서 한번에 가져왔다.
마지막 1x1 conv에서 숫자 뒤에 "Linear"이라는 녀석이 있는데, 이는 활성화 함수를 거치지 않았다는 것을 의미한다.
3. conclusion
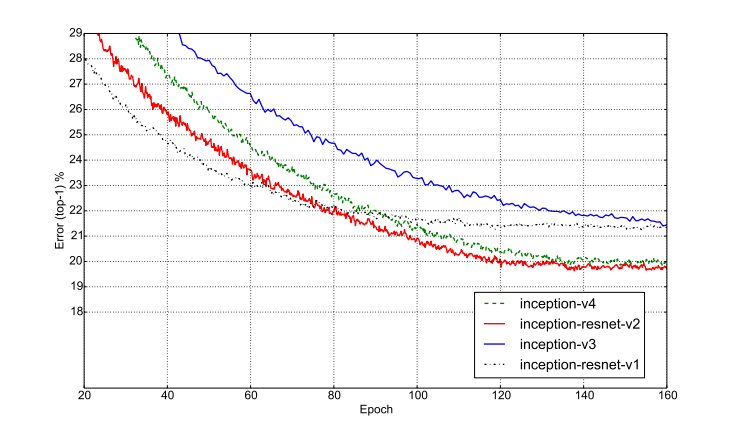
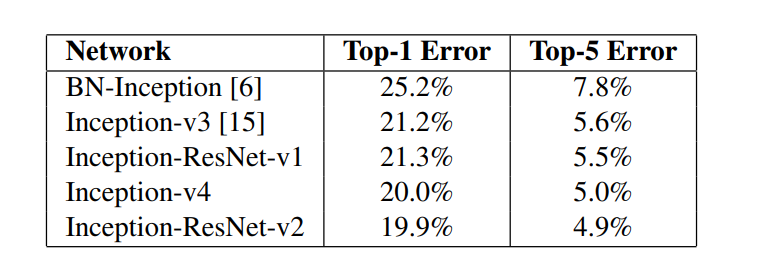
결과는 inception + resnet - v2가 우승을 차지했다.
표에 보면 알겠지만, v3,v4는 잔차학습(resnet)을 하지 않았다.
무려 Top-1 error 19.9%, Top-5 error 4.9%로 top-1 error의 20퍼센트의 벽을 뚫었다.
매우 대단쓰..
결국 많은 논문들의 마지막인 모든 모델들을 조합한 앙상블의 결과는 어떨까?

오우 마이 갓..
144crops를 사용했고, 5만개의 ILSVRC 2012의 데이터를 쓴 결과
무려 top-1 error 16.5%, top-5 error 3.1% 라는 경이적인 기록을 만들었다.
