그런 당신을 위해 논문을 준비했습니다! NCF 편. Neural Collaborative Filtering 논문 리뷰
원문 : https://arxiv.org/abs/1708.05031
이번 시간에는 현재 딥러닝을 이용한 추천 시스템의 기반이 되는 Neural Collaborative Filtering을 살펴보려한다.
아이디어는 상당히 간단하지만 추천 시스템의 기반이 되는 논문이므로 잘 읽어보자!
가즈앗!
1. INTRODUCTION
연구자들은 이전 연구들은 letent vector 를 이용한 MF(Matrix Factorization)를 사용했었고 말한다. 그러나 이런 방법은 유저와 아이템 간의 복잡한 구조를 나타내기에는 부족하다고 말한다. 따라서 본 논문에서는 기존 Collaborative Filtering + neural network 을 하여 비선형성을 추가하고, 시청, 구매, 클릭 등 유저의 행동을 나타내는 feature를 추가해서 implicit feedback 데이터를 이용하여 모델을 구성했다고 말하고 있다.
해당 논문의 기여점 3가지는,
1. 유저와 아이템의 latent features를 모델링 하기 위한 architecture 제시 및 NCF(Neural Collaborative Filtering) 프레임 워크 제시
2. MF는 NCF 중 하나의 경우라는 것을 증명하고, multi layer perceptron을 활용하여 NCF 모델의 비선형성 연산이 가능함을 제시
3. 2가지 실제 데이터(MovieLens와 Pinterest)를 이용한 NCF 효율성 검증
??? letent vector는 뭐고 MF는 뭔가요..몰라도 잇츠 오케이. 밑에 설명이 나오니 걱정 말자.
2. PRELIMINARIES
2-1. Learning from Implicit Data
implitcit feedback이라는 녀석은 무슨 녀석이냐?
유저가 구매하거나, 검색, 클릭 등의 정보를 바탕으로 표현되는 데이터이다.
이를 Matrix로 표현하는데, 유저와 상호작용이 있었다면 1, 없었다면 0 으로 표현한다.
다만, 여기서 1이 무조건적으로 '이 유저가 이 아이템을 좋아해요!'는 아니다.
반대로, 0이 무조건적으로 '이 유저가 이 아이템을 싫어해요!'도 아니다.
그저 '유저와 아이템이 상호작용이 있었다!'정도만 나타내는 것이다.
2-2.Matrix Factorization

Matrix Factorization의 한계점을 보여주기 위해 연구자들은 하나의 예시를 보여준다.
자카드 유사도(Jaccard coefficient (J(X,Y) = |X∩Y| / |X∪Y|))를 통해 유저간의 유사성을 구하면,
S N M = (유저 N과 유저 M가 얼마나 많은 유사도를 보이는지)
S 23 (0.66) > S 12 (0.5) > S 13(0.4)
로 표현할 수 있다.
이것을 기하학적으로 표현하면 그림 (b)와 같다.
이때, 유저4(u4)를 추가해보자.
그러면
S 41 (0.6) > S 43 (0.4) > S 42(0.2)
이라는 순서를 가진다. 이것을 기하학적으로 표현하면 p4 혹은 p4' 자리에 들어가야할텐데, 저 좌표공간위에 어디에 두던 정확히 표현할 수 없다.
그럼 차원을 늘리면 되는거 아닌가요? 3차원이라던지, 4차원이라던지
맞다. 가능은 하다. 그러나, latent space의 차원을 늘리게 되면, setting 자체가 너무 sparse해져 버린다. 너무 흩어져버린다는 것이다. 그러기 때문에 overfitting이 일어나 버릴 가능성이 높아진다. 그렇기에 연구자들은 고민을 했다.
하지만 여기서 DNN이 나타난다면?

3. NEURAL COLLABORATIVE FILTERING

위는 NCF의 전체적인 구조이다.
input으로는 Matrix 형태로 sparse한 상태로 입력된다. 이후 Embedding Layer를 통해 dense vector 형태로 layer를 통과 되게 된다.
layer 1, layer 2, layer 3 .... layer x 까지 모두 통과한 후 마지막은 활성 함수에 logisitc이나 probit을 사용하여 0~1의 값이 출력되도록 한다.
최종 결과는 '23번 유저가 54번 아이템이 관련있을 확률은 0.89651 입니다!' 라고 나오는 것이다.

NCF의 loss function을 나타낸 것이다.
위에 Y도 있고 Y-도 있는데, 뭐 다른건가요?
다르다. Y는 interaction이 있는 items에 해당되는 것이고, Y-는 interaction이 없는 items에 해당되는 것이다.
이 연구에서는 Y-의 크기를 Y의 크기와 균일하게 샘플링 한다고 한다.
물론 다르게도 할 수 있다. 이것을 negtive sampling ratio 라고 한다.
그러나 이 논문에서는 균일 샘플링을 진행했다고 한다.(추후 연구or 다른 사람이 연구)
3-1. Generalized Matrix Factorization (GMF)
MF을 그대로 쓰기보다, 조금 Generalize 해서 쓰면 어떨까?
먼저, 여기서는 one-hot encoding을 통해 user latent vector, item latent vector 를 만들고, 이걸 아다마르 곱(element-wise product) 을 한다.
아다마르 곱이 뭐에요 ㅠㅜ
울지마라. 나도 몰랐다. 링크를 들어가서 확인만 해주자. 누군가 아주 잘 설명해놨다. 감사합니다 위키백과.
아다마르 곱 알아보러 가기(위키백과)
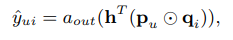
위의 식은 GMF의 유저와 아이템 간 점수를 나타낸 식이다.
hT = 가중치
p = user latent vector
q = item latent vector
이때 마지막 a out 에 sigmoid를 적용 하여 기존의 쌩 MF 보다 더 non-linear 해진다는 것이 연구자들의 설명이다.
3-2. Mulit-Layer Perceptron (MLP)
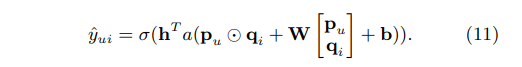
마찬가지로 MLP에서도 user latent vector, item latent vector 를 사용한다.
user latent vector 와 item latent vector 를 concatenation하여 입력해준 후, 여러 단계의 ReLu함수를 통과하여 non-linear를 확보한다.
3-3. Fusion of GMF and MLP
자! 이제 두개를 합쳐보자!
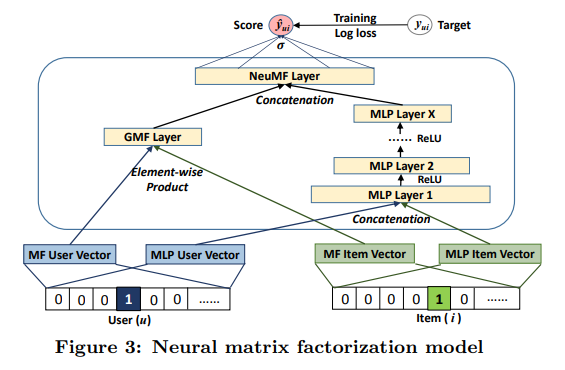
이후 local optimum에 빠지지 않게 하기 위해 2개의 layer에 각각 pre-trained를 적용하고, GMF, MLP 에는 Adam optimizer, NeuMF에는 SGD 옵티마이저를 적용했다고 한다.
4. EXPERIMENTS
pinterest 와 movielens 이라는 곳에서 데이터를 얻어 실험해 보았다고 한다.
가볍게 결과만 확인하고 가자.
위의 HR@K이라는 지표는 Hit Rate이라는 지표로
'유저의 interaction 중 하나를 제외하고 나머지 interaction을 학습에 데이터로 주었을 때, 하나를 제외한 interaction을 정확히 추정해냈는가?' 라는 지표이다.
K는 '몇개를 후보군으로 추출하였는가?'이다.
NDCG@K는 K개의 후보군에 순서중요도 까지 추가한 지표이다.
이제 이것을 우리도 실제 데이터에 써보도록 하자!
하지만 그것은 다음시간에..
오늘은 여기까지!
