1. Outlier rejection
Data
- lnlier data : 예상한 데이터 분포 안의 관측치 / correct
- outlier data : 데이터 분포에서 벗어난 관측치 / incorrect

-
왼쪽 픽셀 * F -> 오른쪽 epipolar line
-
epipolar line 위에 있는 픽셀 즉, coplanarity를 잘 지키는 점들은 초록색, 그렇지 않으면 빨간색
-
descriptor matching을 했을 때 이것도 match라고 평가가 됐겠지만 motion 값 즉, Fundamental matrix로 추론했을 때는 부정확한 값
-
match들을 가지고 Fundamental matrix를 계산하기 전에는 어떤 match가 잘된건지 판단할 수 없다 -> Fundamental matrix로 검증을 하고 나서야 옳은 matching인지 알 수 있다 -> inlier와 outlier를 구분할 수 있다
-
outlier가 나타나는 원인
- illumination changes (조명)
- rotation
- heavy occlusions : 가림
- abrupt motions : 모션 블러
model fitting
outlier rejection의 필요
- outlier는 알고리즘의 전제조건을 흔드는 위험한 데이터
- statistically incorrect
- geometrically incorrect
- noise가 있을 때 모델을 추정할 때 outlier rejection은 필수적이다!!
- well-known techniques
- RANSAC
- M-Estimator
- MAXCON
컴퓨터 비전에서의 2종류 알고리즘
-
closed form algorithm
- onluy accepts geometrically consistent data
- 수많은 minimum solver 방법들
- fundamental matrix를 만드는 8-point방법에서 하나라도 잘못된 데이터가 있으면 결과가 잘못된다 -> 알고리즘의 전제조건이 정확한 기하학적 조건을 가지고 있을 때 작동하도록 설계되어 있기 때문
-
iterative optimization algorithm
- only accepts statistically consistent data
- 많은 데이터를 가지고 작동 -> 모든 데이터가 동의할 수 있는 결과가 나올 때까지 지속적으로 알고리즘을 찾아간다
- inlier들로 패턴을 찾아가는데 outlier가 있으면 잘못된 패턴을 찾을 수도 있다
- VSLAM에서는 이런 형태의 알고리즘을 많이 사용함
- 그래서 알고리즘을 수행하기 전에 outlier를 제거해주는 것이 중요하다
linear regression
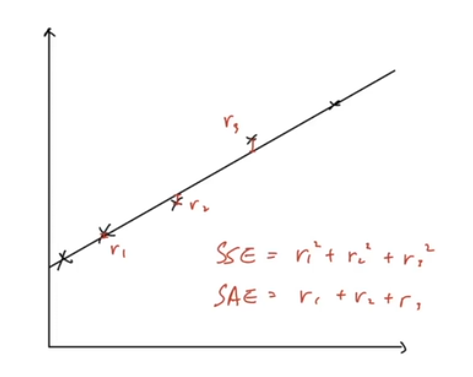
- line fitting
- error metrics
- SSE : Sum of Squared Error (제곱)
- SAE : Sum of Absolute Error (절대값)
- outlier가 있을 경우
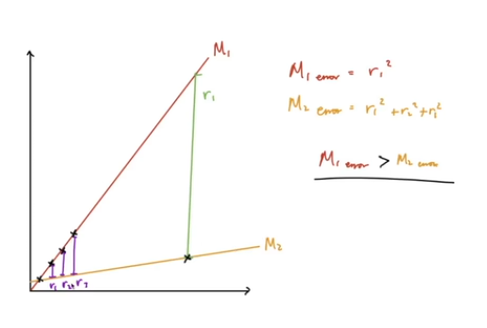
- 노란선 위에 있는 것이 outlier
- error를 계산하였을 때 M1 > M2 여서 M2가 더 좋은거라고 예측 but! 실제로는 M1이 좋다
2. RANSAC (Standard RANSAC, 1981)
- RANdom SAmple Consensus
- 무작위하게 샘플을 뽑아 모델을 만들고 모델에 대한 데이터의 합의도를 알아본다
- RANSAC은 template algorithm
- framework일 뿐이고 실제로 안에서 돌아가는 알고리즘은 따로 있다
- 예를 들어 fundamental matrix를 만들 때 8-point 방법을 사용하지만 그 전에 RANSAC을 통해 데이터를 랜덤으로 뽑는다
RANSAC 알고리즘
- 랜덤하게 minimal set of data (모델을 추론하기 위한 최소한의 데이터)를 뽑는다
- 뽑은 데이터를 통해 모델 추론
- 추론한 모델을 기반으로 model score 측정 : best score와 비교하여 score를 updata하거나 버린다
- 1번으로 돌아간다
예시 : homography + RANSAC algorithm
- 4개의 feature correspondence를 뽑는다
- homography matrix 추론
- reprojection error 계산 : 왼쪽 이미지의 픽셀 * matrix -> 오른쪽 이미지에 재투영 -> gt와의 픽셀거리 측정해서 error 계산 -> score update
- 1번으로 돌아간다
몇 번의 loop??
- 최적의 loop 횟수를 계산하는 방법이 있다
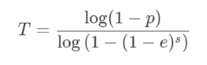
- T : 최적의 모델을 얻기 위해 돌려야하는 loop의 횟수
- p : 뽑은 데이터가 inlier일 확률 (inlier였으면 하는 확률)
- e : 전체 데이터에서 inlier와 outlier의 비율
- s : 매 loop마다 sampling할 데이터(minimal set)의 개수
장단점
장점
- 성공적으로 outlier를 제거할 수 있다 (데이터 분포를 분석하지 않고도 가능)
- 전체 프로세스 시간을 대략적으로 알 수 있다
- 조금더 빠르게 끝내는 기법을 추가할 수 있다
- 이해하기 쉽다
단점
- 알고리즘 자체가 ramdom이기 때문에 돌릴때마다 결과가 다르게 나타날 수 있다
- 전체 데이터에서 outlier가 inlier보다 많아질 경우 실행시간이 급격하게 늘어난다
- 실패하게 되면, 모든 가능성을 순회하는 속도로 수렴된다
- 하나의 데이터셋에서 여러 모델을 동시에 추출할 수 없다
3. Modern RANSAN's
- 기존의 RANSAC의 단점을 해결하기 위해 나온 Modern RANSAC
Standard RANSAC의 문제점
- data 분포를 고려하지 않는다
- prior data를 사용하지 않는다
- noise를 포함한 sampled data를 고려하지 않는다
- openCV 4.5.0부터 modern RANSAC이 지원되었다
Modern RANSAN의 종류, 선택
- MSAC, MLESAC, Lo-RANSAC, NAPSAC, P-NAPSAC 등등
- 필요한 것을 선택하고 조합해서 사용
- early stop + PROSAC + Lo-RANSAC -> F/E matrix에 효과적
Early-stop method
- 운좋에 좋은 모델을 찾았을 경우, RANSAC을 바로 종료하는 기법
- 필요한 3가지 변수
- minimum iteration : 최소한의 품질을 보장하기 위한 RANSAC loop의 수
- maximun iteration : 최대 loop 수
- success score : 성공 지표
PROSAC
- 이미지 매칭에 특화된 RANSAC 기법
- 데이터 prior를 잘 이용한 기법
- descriptor distance를 prior로 사용
- descriptor match를 할 때 distance를 측정하는데 feature descriptor 간의 distance가 적은 match일수록 모델 추론을 할 때 정확하게 할 가능성이 높다. 즉 inlier일 확률이 높다라는 점을 이용
- low distance = similar descriptor = better match = inlier일 확률 높다
- 따라서 기존 RANSAC의 ramdom sampling 과정을 좀 더 낮은 distance를 가진 descriptor match를 sampling하는 방법으로 변경 + 점진적으로(progressively) 높은 distance를 가진 descriptor match를 sampling
- PROSAC이 완전히 실패하는 경우에도 RANSAC의 성능으로 수렴 => PROSAN이 무조건 기존의 RANSAC 보다 성능이 좋다
- 일반적으로 첫 5~10개의 loop만에 결과를 찾는 경우가 많다
PROSAC 알고리즘
- 두개의 이미지에서 descriptor matching 수행 : 이 과정에서 descriptor distance 계산
- 낮은 distance에서 높은 distance로 sorting
- 몇 개씩 탐색할건지 pool size(n) 지정
- n개에서 data sampling
- 모델 추론
- 모델 평가
- if(score > best_score) -> score update
- if(score < best_score) -> n 크기 증가
- 1번으로 돌아간다
Lo-RANSAC
- 데이터의 distribution pattern을 잘 활용
- 일반적으로 inlier 데이터는 뭉쳐있고 outlier 데이터는 퍼져있는 경우가 많다 -> 이 특징 활용
- 따라서 한번 inlier 데이터를 활용하여 모델을 찾고 나면 정답은 그 근처에 있기 때문에 다른 random한 위치로 이동할 필요가 없다
- RANSAC cycle을 한번 돌릴 때 한번의 loop 속에서 작은 inner-RANSAC을 만들어서 더욱 정확한 값을 얻으려고 한다 + optimization까지 수행
- standart RANSAC 보다 낮은 loop로 정답에 도달할 수 있다
Lo-RANSAC 알고리즘
- minimal-set data sampling
- 모델 추론 & 평가
- if(score < best_score) -> return to step 1
- if(score > best_score) -> inner-RANSAC 실행(inlier들만 가지고 RANSAC -> 좋은 결과가 나올 확률이 높다)
2-1. inlier data 중에서 minimal-set data sampling
2-2. 모델 추론
- if(score > best_score) -> updata score
- if(score < best_score) -> return to step 2-1
- if(number of loop > maximum loop) -> go to step 3
- iterative local optimization (gauss-newton / levenberg-marquardt와 같은)
- if(score > best_score) -> update score
- return to step 1
