eda 수업 벌써 다 끝났는데 실력은 마이너스라 다시 듣는 중
목표 : 인구수별로 cctv 현황 그래프 그리기
인구수 대비 cctv 시각화
- 서울시 구별 cctv현황, 인구현황 데이터 확보 # python, pandas
- cctv데이터와 인구현황 데이터 합치기
- 데이터 정리, 정렬
- 그래프그리기 # matplotlib
- 전체적인 경향 파악 # regression using numpy
- 경향에서 벗어난 데이터 강조 # insight and visualization
-
모듈 import
import pandas as pd
import matplotlib.pyplot as plt
import numpy -
데이터 불러오기
cctv_seoul=pd.read_csv('../data/01. Seoul_CCTV.csv',encoding='utf-8') # .. : 현재폴더에서 상위폴더로 이동
pop_seoul=pd.read_excel('../data/01. Seoul_Population.xls') -
데이터 합치기
data_result=pd.merge(cctv_seoul,pop_seoul,on='구별') # 구별 컬럼 중심으로 합치기
-
상관관계 알아보기(인구대비 상대적으로 cctv 적은 구를 찾고 싶음)
data_result.corr() # 0.2 이상인 데이터 비교
data_result['cctv 비율']=(data_result['소계']/ data_result['인구수']) * 100
data_result.sort_values(by='cctv 비율',ascending=False).head() # cctv 비율 컬럼 추가 -
시각화
from matplotlib import rc
plt.rcParams['axes.unicode_minus']=False
rc('font',family='Malgun Gothic') # 한글 깨짐 방지def drawGraph():
data_result['cctv비율'].sort_values().plot(
kind='barh',grid=True,title='cctv 많은 구',figsize=(10,10)
) # cctv비율로 정렬해서 그래프 그리기def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'],data_result['소계'],s=50)
plt.xlabel('인구수')
plt.ylabel('cctv')
plt.grid()
plt.show()
선형회귀 trend 파악(numpy)
- np.polyfit : 직선을 구성하기 위한 계수 계산
- np.poly1d : ployfit로 찾은 계수로 python에서 사용할 함수로 만들어 줌
import numpy as np
fp1=np.polyfit(data_result['인구수'],data_result['소계'],1) # 1차식으로 만들어라
fp1
f1=np.poly1d(fp1) # 함수 생성
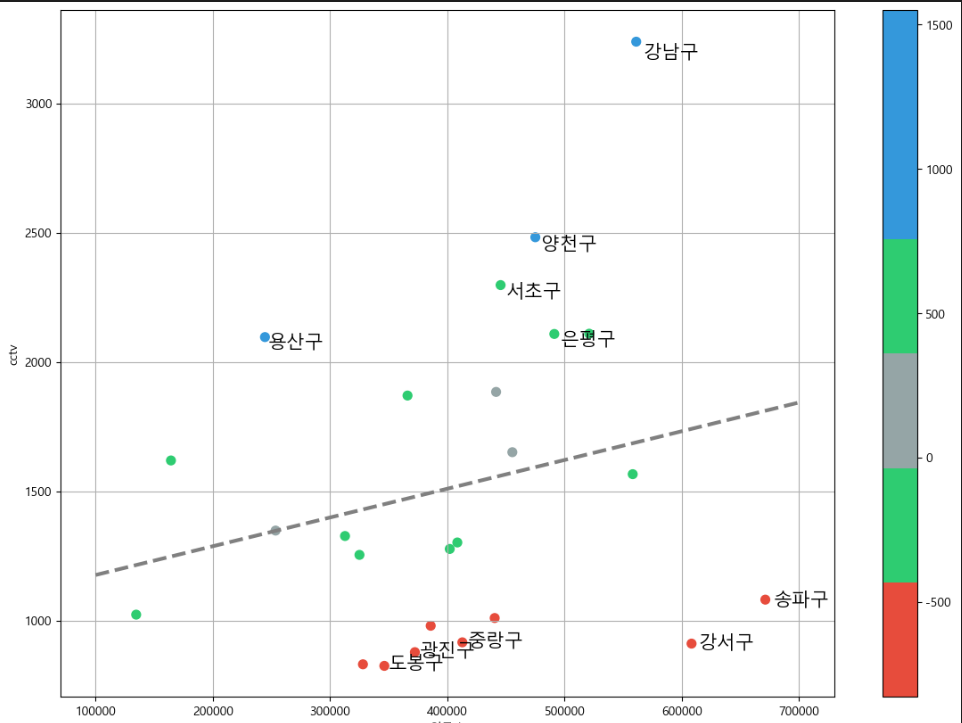
인구 400000인 구에서 서울시의 전체 경향에 맞는 적당한 cctv 수?
: f1(400000) # 1510개
-
경향(trend)과의 오차 -> 오차 컬럼 만들어주기
예측값과 실측값이 다름data_result['오차']=data_result['소계']-f1(data_result['인구수']) # 실제값 - 예측값
-
함수로 정리
def drawGraph():
plt.figure(figsize=(14,10))
plt.scatter(data_result['인구수'],data_result['소계'],c=data_result['오차'],s=50,cmap=my_cmap) # s : size, c: color
plt.plot(fx,f1(fx),ls='dashed',lw=3,color='grey')for n in range(5): plt.text( # 글자 찍는 함수 (x좌표, y좌표, 넣을 글자) df_sort_f['인구수'][n] * 1.01, df_sort_f['소계'][n] * 0.98, df_sort_f.index[n], fontsize=15 ) plt.text( df_sort_t['인구수'][n] * 1.01, df_sort_t['소계'][n] * 0.98, df_sort_t.index[n], fontsize=15 )
plt.xlabel('인구수')
plt.ylabel('cctv')
plt.colorbar()
plt.grid()
plt.show()drawGraph()