Paper Review
1.DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter
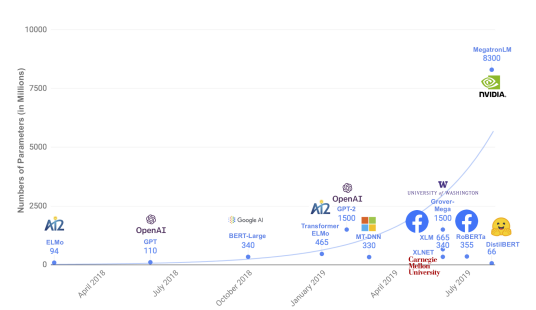
기존 문제점 BERT는 Pre-trained + finetuning 하여 사용 Pre-trained는 메모리 용량 및 프로세스 성능 등 많은 자원을 소요하는 문제 DistilBERT 개요 DistilBERT는 기존 BERT-base 보다 40% 가볍고, 60% 빠름
2023년 3월 7일
2.DoRA: Weight-Decomposed Low-Rank Adaptation
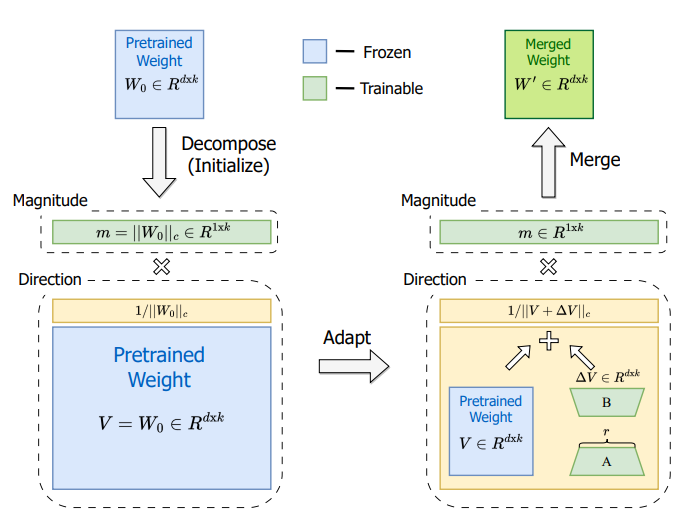
DoRA
2024년 2월 19일
3.SELF-INSTRUCT : Aligning Language Models with Self-Generated Instructions

Introduction 최근 언어 모델은 거대한 사이즈와 Instruction Data를 통한 학습으로 우수한 성능을 자랑한다 하지만,
2024년 5월 9일
4.On LLMs-Driven Synthetic Data Generation, Curation, and Evaluation: A Survey
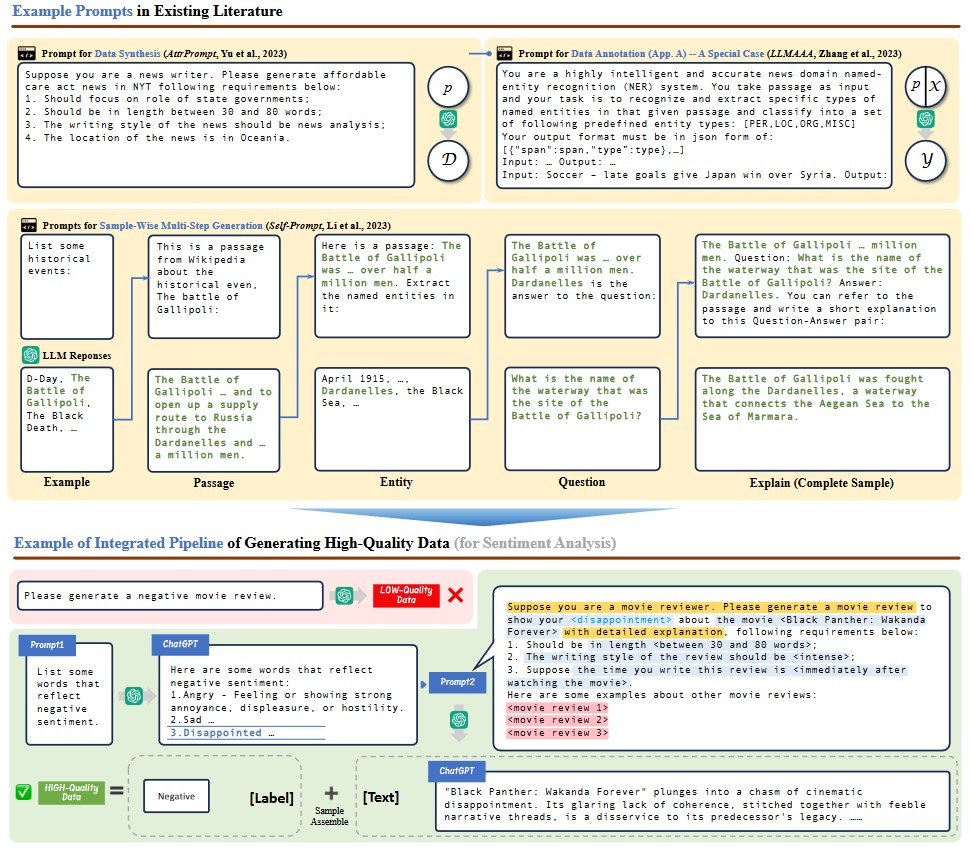
LLM 기반 합성 데이터 Survey
2025년 1월 10일
