2024/2/14 arxiv에 투고된 논문
LoRA가 Full Fine-tuning 보다 성능이 떨어지는 한계를 극복했다고 한다.
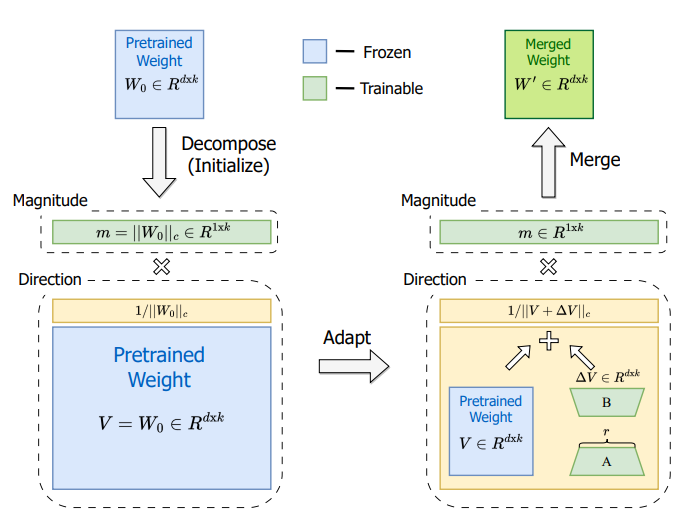
핵심 아이디어는 다음과 같다.
pretrained-weight를 two components(magnitude and direction)로 나누자.
초록
peft는 현재 널리 쓰이고 있다.
특히 추론 비용에 대한 부담이 없기 때문에 LoRA와 그 유사한 방법이 인기가 있다.
하지만 여전히 Full fine-tuning과의 정확도 차이는 존재한다.
따라서 Full fine-tuning과 유사한 학습 수용력을 목표로 DoRA를 제안한다.
DoRA는 사전학습 가중치를 크기와 방향의 두 구성요소로 분해한다.
특히, 훈련 가능한 파라미터를 최소화 하기 위해 방향 업데이트에 LoRA를 사용한다.
DoRA를 적용함으로써 추론 지연은 피하고 LoRA의 학습 수용력과 학습 안전성을 강화시켰다.
LLaMa, LLaBa, VL-BART를 다양한 태스크에 대해 파인튜닝하여 실험한 결과 LoRA보다 좋은 성능을 달성했다.
(accept 된 후 코드 및 모델 공개)
서론
최근 NLP 분야에서 언어 모델을 다운스트림 태스크에 FUll fine-tuning 하여 좋은 성능을 내고 있으나, 모델과 데이터 규모가 커지면 FUll fine-tuning에 드는 비용에 부담이 있다.
이에 peft 방법이 등장하며 특히 LoRA는 간단함과 효율성으로 주목받기 시작했다. 하지만 LoRA는 여전히 FUll fine-tuning과 비교하여 성능 차이가 존재한다.
따라서, 가중치 정규화(Salimans & Kingma, 2016) 방법을 바탕으로 모델의 사전학습 가중치를 크기와 방향으로 분해하는 새로운 방법을 소개한다.
결론적으로 크기와 방향 구성 요소로 분해한 후 두 가지를 fine-tuning 하는 방식이다.
여기서 방향성 구성 요소가 상당히 크다는 점을 고려하여, LoRA를 활용하여 효율적인 fine-tuning을 진행한다.
DoRA가 FT(Full Fine-Tuning)와 유사한 학습 행동을 경험적으로와 수학적으로 보여줌으로써, FT와 밀접하게 유사한 학습 능력을 시사하여, NLP부터 Vision-Language까지 다양한 작업과 LLM 및 LVLM을 포함한 다양한 백본에서 DoRA를 검증했다.
DoRA가 LoRA의 장점처럼 추론 효율성을 향상시켰다고 한다.
예를 들어, commonsense reasoning(+3.4/+1.0 on LLaMA-7B/13B), visual instruction tuning (+0.6 on LLaVA-7B), 그리고 image/video-text understanding(+0.9/+1.9 on VL-BART)에서 일관되게 LoRA보다 우수하다고 한다.
기여 요약
- 가중치 분해를 통해 FT와 유사한 학습 능력을 달성하고, 추가적인 추론 지연 없이 LoRA를 능가하는 PEFT 방법인 DoRA를 소개
- FT와 다양한 PEFT 방법들 사이의 학습 패턴의 근본적인 차이를 밝히기 위해 새로운 가중치 분해 분석을 소개
- DoRA는 NLP부터 Vision-Language 벤치마크 및 LLM 및 LVLM을 포함한 다양한 백본을 통해 LoRA를 일관되게 능가
3. LoRA와 FT 패턴 분석
3.1 LoRA
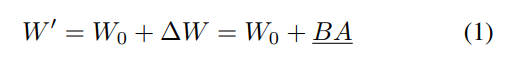
LoRA는 사전 학습된 가중치 행렬 W0 + 가중치 업데이트 ∆W를 기준으로 ∆W ∈ R d×k 를 low-rank decomposition을 통하여 ∆W=BA로 표현한다.
결국 파인 튜닝된 가중치 W′는 W′ = W0 + ∆W = W0 + BA로 표현하는데사전학습 가중치는 고정하고 BA만 학습하는 구조이다.
(행렬 A는 균일한 Kaiming 분포로 초기화되며, B는 처음에 0으로 설정되어 훈련 시작 시 ∆W = BA가 0)
LoRA는 추론 지연을 방지하데 장점이 있다.
32 Weight Decomposition Analysis
LoRA와 FT는 훈련 파라미터의 개수로 인해 정확도 차이가 발생한다는 후속 연구들이 존재한다(Hu et al., 2022; Kopiczko et al., 2024).
해당 연구는 LoRA와 FT의 학습 패턴의 차이를 밝히기 위해 크기와 방향이라는 두개의 요소로 가중치를 분해하여 분석한다.
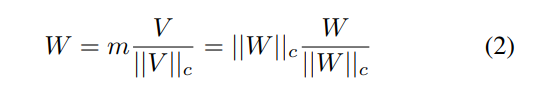
m∈R 1×k 는 크기 벡터이고, V∈R d×k 는 방향 행렬이다. ∣∣⋅∣∣c는 각 열 벡터의 정규화를 의미하는데 유클리드 정규화를 의미한다.
즉 V/∣∣V∣∣c는 단위 벡터(크기가 1인 방향만 존재하는 벡터)를 의미하고 m이라는 크기 스칼라값을 곱하여 각 벡터의 크기를 정의한다고 보면 된다.

출처 : https://kr.mathworks.com/help/matlab/ref/vecnorm.html
해당 연구는 four image-text tasks에 파인튜닝된 VLBART를 활용하여 분석을 진행한다고 한다.
여기서 LoRA는 셀프어텐션의 Q,K 가중치만 적용하여 실험했다.
여기서는 총 3가지의 가중치를 분해했다.
W0(사전학습 가중치), WFT(풀 파인튜닝 가중치), WLoRA(LoRA 가중치)
W0와 WFT의 크기와 방향의 차이는 다음과 같이 정의되었다.

ΔM t FT와 ΔD t FT는 각각 t번째 훈련 단계에서 W0와 WFT 사이의 크기 및 방향 차이를 의미한다.
Cos는 코사인 유사도를 의미하며 m n,t FT 와 m n 0 은 각각 해당하는 크기 벡터의 n번째 스칼라이며(행렬의 n번째 열 크기), V n,t FT 와W n 0는 각각 V t FT 와 W0의 n번째 열(행렬의 n번째 열의 열벡터)을 의미한다.
WLoRA와 W0의 차이도 위 식과 동일하게 계산된다.
분석을 위해 4개의 훈련 스텝에서 저장된 체크포인트를 불러와서 가중치 분해 분석을 수행하였다고 한다. 이때에는 서로 다른 레이어에서 ΔM와 ΔD를 결정(?)했다 한다.
분석 결과
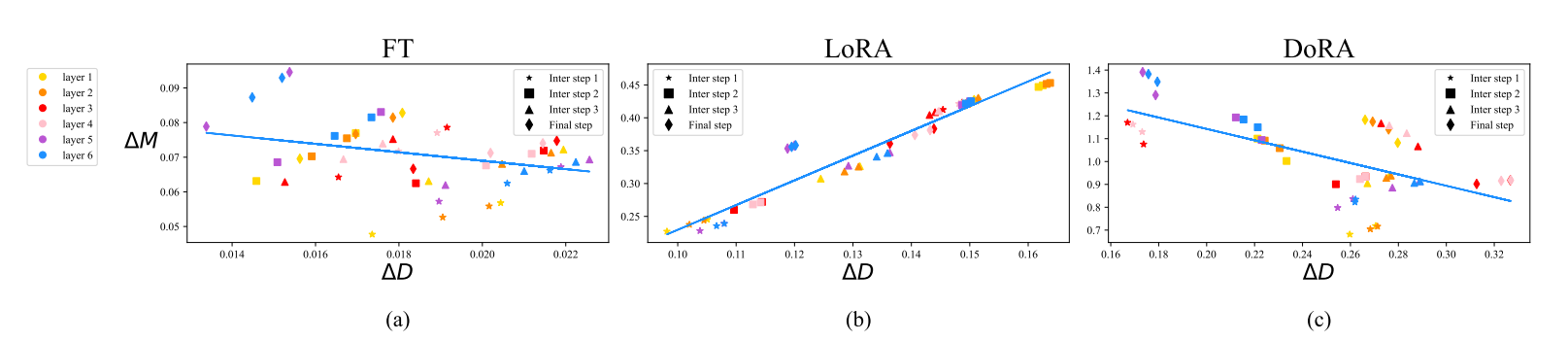
(a) FT, (b) LoRA, 그리고 (c) DoRA의 쿼리 행렬의 크기 및 방향 업데이트를 서로 다른 레이어와 훈련 스텝 별로 표시한 그림이다. 서로 다른 훈련 스텝은 다른 기호로, 각 레이어는 다른 색상으로 표현했다.
x축은 방향의 변화량, Y축은 크기의 변화량을 나타내는데, LoRA의 변화량 기울기를 봤을 때 양의 관계를 가지고 있다.
하지만 FT는 비교적 음의 기울기 관계를가지고 있고, 다양한 학습패턴이 있음을 알 수 있다.
이러한 차이는 학습 능력의 차이를 반영한다고 볼 수 있다. 즉, LoRA는 섬세한 조정을 위해 세밀한 능력을 가지지 못한다는 것을 의심한다.이에 따라 LoRA의 학습 패턴이 FT와 유사하도록 만들고 현재보다 더 나은 학습 능력을 만들기 위해 제안한다.
4. 방법론
4.1 Weight-Decomposed Low-Rank Adaptation
앞서 분석한 결과에 따라 사전학습 가중치를 크기와 방향으로 분해한 다음 두 가중치를 모두 업데이트 한다. 여기서 방향 행렬은 파라미터 수가 많기 때문에 추가적으로 LoRA를 적용하여 분해를 진행한다.
해당 연구에서는 2가지의 관점을 통해 진행한다.
1. LoRA는 방향 벡터 업데이트에만 집중하도록 제한하는 것이 작업을 단순화할 수 있는 방법이다.
2. 가중치 분해를 통해 방향 벡터 업데이트하는 것이 더 안정적이다.
DoRA는 일반적인 가중치정규화 방법보다 더 안정적이라고 한다. 왜냐하면 가중치 정규화 시 초기화를 어떻게 했는지에 따라 민감하지만 DoRA는 사전학습 가중치를 기준으로 초기화했기 때문에 더 안정적이라고 한다.
DoRA는 다음과 같이 정의된다고 한다.
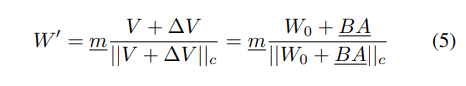
우선 크기벡터와 방향벡터를 사전학습 가중치를 기준으로 초기화 한다음, LoRA를 적용한 방향벡터에서 V는 고정하고 ∆V 행렬과 m벡터는 훈련가능한 가중치로 설정한다. 여기서는 분해를 했으니 V는 단위 벡터일 것이고 여기에 LoRA를 적용해서 크기벡터m과 BA를 업데이트하는 것으로 본다.
가중치를 크기벡터와 방향벡터로 분해한뒤 방향 벡터에 LoRA를 적용한 구조이기 때문에 LoRA와 동일하게 추론지연을 발생하지 않는다고 한다.
DoRA는 LoRA와 반대로 FT와 같이 방향 벡터의 변화량과 크기 벡터의 변화량이 음의 상관 관계를 갖고 있다고 한다. (FT와 DoRA가 각각 -0.62 및 -0.31)
따라서 FT과 비슷한 학습 패턴을 갖고 있기 때문에 LoRA보다 더 우수한 학습 능력을 가지고 있다고 주장한다.
4.2 Gradient Analysis of DoRA
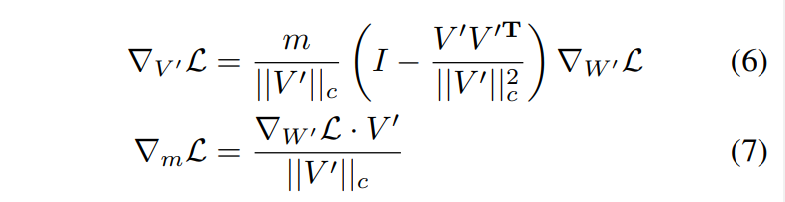
해당 연구의 분해 방법이 ∆V의 최적화에 어떻게 이점이 있는지 분석
식 (6)은 가중치 기울기가 m/||V'||c로 스케일링 되고, 현재 가중치 행렬에서 멀어지는 것을 의미한다.
이는 가중치 공분산 행렬을 항등 행렬과 더 가깝게 정렬하는 데 기여하며, 따라서 최적화에 유리하다고 한다.
또한, V' = V + ∆V인 점을 고려하면,그래디언트 ∇V' L은 ∇∆V L과 동등하다(LoRA는 ∆V만 업데이트 하기 때문에)
따라서, 이 분해의 이점은 ∆V에 모두 전달되기 때문에 LoRA의 학습 안전성을 향상시킨다.
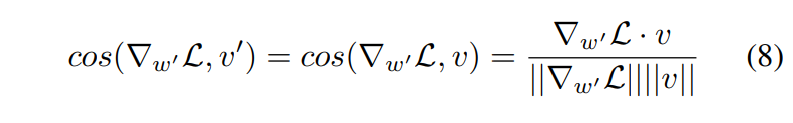
추가적인 분석을 위해 먼저 가정한다. S1 은 방향 가중치를 작게 업데이트하는 경우, S2는 방향 가중치를 크게 업데이트 하는 경우를 가정한다. 두 시나리오의 변화량 벡터의 크기가 같다고 가정한다. (||∆wS1|| = ||∆wS2||).
이때 훈련을 진행하지 않았을 때(time 0) ∆v = 0이고 v' = v이다.(왜냐하면 전혀 변화한게 없기 때문에)
그리고 ∆DS1 < ∆DS2 이기 때문에, |cos(∆wS1, w′ )| > |cos(∆wS2, w′ )|이다 (변화한게 더 적기 때문에 w′와 더 유사함)
또한, ∆w ∝ ∇w' L를 가정했다(비례함) 따라서, |cos(∇S1 w' L, w')| > |cos(∇S2 w' L, w')|가 된다.
4.1 절에서는 v를 v0로 초기화하고 훈련을 진행하지 않았을 때(time 0) w' = w0이라고 가정하면, |cos(∇w' L, w')| = |cos(∇w' L, v')| = |cos(∇w' L, v)|가 된다. ∆v = 0을 통해 코사인 유사도 방정식을 사용하면 그림 (8)과 같다.
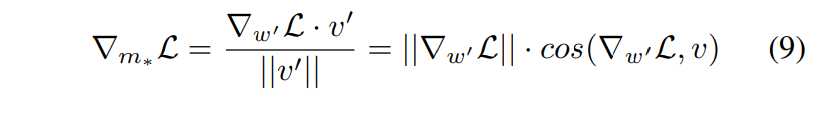
벡터 w'의 크기 스칼라를 m*로 표시하면, 그림 (7)에 대한 m에 관한 그래디언트는 그림(9)과 같다.
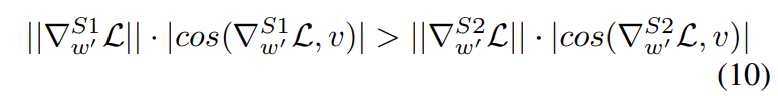
S1과 S2에 대해 ||∆wS1|| = ||∆wS2||이고, ||∇S1 w' L|| = ||∇S2 w' L||를 고려하면 그림 (10)과 같다.
|∇S1 m L| > |∇S2 m L|이 되어 S1이 S2보다 큰 크기 업데이트를 가지면서 S2보다 작은 방향 변경을 갖는다는 것을 나타 낸다.
이 결론은 Fig2(c)와 같다. 따라서 DoRA가 LoRA의 학습 패턴과는 다르게 조정되고 FT의 패턴과 더 밀접하게 일치하도록 조정된다고 볼 수 있다.
4.2 Reduction of Training Overhead
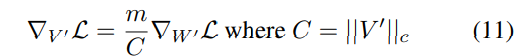
LoRA와 다르게 여기서는 방향 벡터에 LoRA를 적용하기 때문에 역전파중 추가적인 메모리를 필요로 한다.
이를 해결하기 위해 식 (5)에서 ||V + ∆V||c를 상수로 취급하고 이를 그래디언트 그래프(역전파 그래프?)에서 분리하는 것을 제안한다.
||V + ∆V||c가 ∆V의 업데이트를 동적으로 반영하지만, 역전파 중에는 어떤 그래디언트도 받지 않는다는 것을 의미한다고 한다.
이러한 경우 크기 벡터의 기울기는 동일하게 동작하지만, ∇V'L는 재정의 된다고 한다.
이 접근 방법은 그래디언트 그래프의 메모리 소비를 현저히 줄일 수 있으며 정확도에는 거의 차이가 없다고 한다.
ablation study에서 LLaMA-7B와 VLBART의 파인튜닝에 미치는 영향을 평가했을 때 결과는 LLaMA의 파인튜닝 메모리를 약 24.4% 줄이고 VLBART의 메모리를 약 12.4% 줄인다.
더 나아가, 수정된 DoRA의 정확도는 VLBART에서 변경되지 않으며 LLaMA에서 수정되지 않은 DoRA와 비교했을 때 0.2의 차이를 보인다고 한다(무시할 만한 차이라고 언급).
- 자세한 내용은 부록 테이블 7
5. 실험
5.1 Commonsense Reasoning
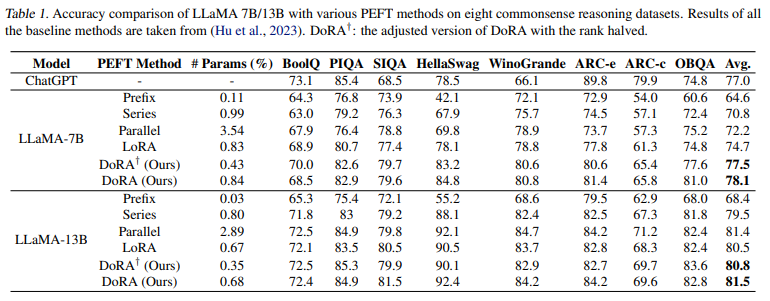
모델 : LLaMA-7B, LLaMA-13B
메트릭 : acc
DoRA의 학습 가능한 파라미터가 LoRA보다 0.01% 증가한 것은 학습 가능한 크기 벡터를 포함한 것이 원인이다
DoRA†는 rank를 반으로 줄인 경우를 의미한다
평균적으로 DoRA가 두 모델에서 모두 정확도가 높은 것을 알 수 있다
5.2 Image/Video-Text Understanding
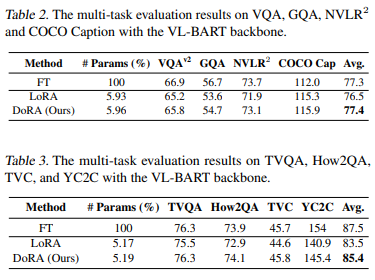
모델 : VL-BART(Visual-Linguistic BART)
메트릭 : acc
VL-BART(Visual-Linguistic BART)에서 DoRA를 LoRA 및 FT와 비교한다
네 가지 다른 이미지-텍스트 작업 및 VALUE Benchmark의 네 가지 다른 비디오-텍스트 작업에서 성능을 비교한다
DoRA는 일관되게 LoRA를 능가했다
5.3 Visual Instruction Tuning
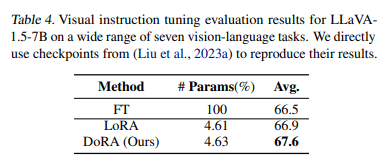
모델 : LLaVA-1.5-7B
메트릭 : average acc
vision language benchmarks VQAv2, GQA, VisWiz, SQA, VQAT, POPE, MMBench에서 평가헀다
DoRA는 LoRA와 FT 모두보다 우수한 성능을 나타내며, LoRA 대비 평균적으로 0.7%p, FT 대비 1.1%p 높다
5.4 Compatibily of DoRA with other LoRA variants
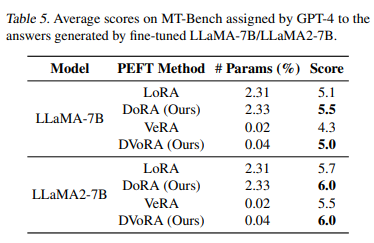
모델 : LLaMA-7B, LLaMA2-7B
메트릭 : evaluated by GPT-4
MT-Bench 벤치마크를 활용했다.(pre-defined set of 80 multi-turn questions)
DoRA와 DVoRA(VeRA+DoRA)가 LoRA와 VeRA 대비 성능이 우수함을 보인다
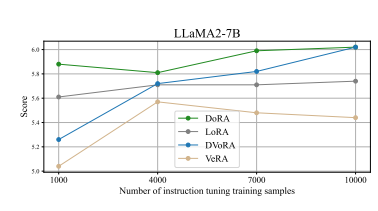
instruction-tuning sample sizes(1000, 4000, 7000, 10000)에 따라 평가했다
7000개의 학습 샘플에서, DoRA와 DVoRA는 각각 LoRA와 VeRA를 0.3 및 0.33 점씩 더 우수한 성능을 나타낸다
5.5 Robustness of DoRA towards different rank settings
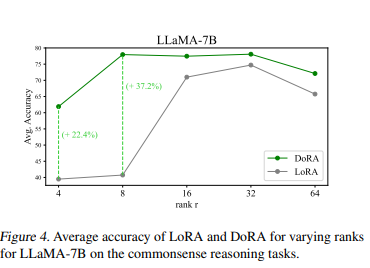
모델 : LLaMA-7B
메트릭 : average acc
r = 8 일 때 LoRA의 평균 정확도는 40.74%, r = 4 일 때는 39.49%로 감소한다. 반면에, DoRA는 r = 8 일 때 77.96%, r = 4 일 때 61.89%로 정확도를 유지하며, 랭크 설정에 관계없이 LoRA보다 항상 우수한 성능을 나타낸다.
5.6 Tuning Granularity Analysis

모델 : LLaMA-7B, LLaMA-13B
메트릭 : average acc
LoRA는 Multi-head Attention 및 MLP 레이어 모두를 업데이트하는 것이 최적의 성능을 달성할 수 있다고 한다.
DoRA는 Multi-head Attention의 방향 벡터 및 크기 벡터와 MLP 레이어의 크기 벡터만 업데이트하여 우수한 정확도를 달성할 수 있으므로 더 작은 파라미터를 사용하지만 더 우수한 성능을 확인했다(DoRA는 LLaMA-7B에서 LoRA를 2.8%p 능가하고 LLaMA-13B에서 0.8%p 능가).
6. 결론
LoRA와 FT 간의 구별되는 학습 패턴을 밝히기 위해 새로운 가중치 분해 분석을 수행했다.
이에 따라, LoRA 및 LoRA의 변형 메소드와 호환되며 FT의 학습 패턴과 더 유사성을 보이는 DoRA를 소개한다.
DoRA는 다양한 파인튜닝 및 모델 아키텍처에서 LoRA를 일관되게 능가한다.
특히, DoRA는 commonsense reasoning and visual instruction tuning tasks에서 LoRA를 개선했다.
또한, DoRA는 Alpaca instruction tuning task에서 VeRA와 호환성을 보여준다.
더불어, DoRA는 LoRA에 비해 비용이 들지 않는 대안이 될 수 있다.
학습 후 분해된 크기 벡터 및 방향 벡터를 사전 훈련된 가중치로 다시 병합하여 추론 지연 방지를 보장한다.
후속 연구는 DoRA의 언어 및 비전 분야를 넘어서는 일반화 가능성을 연구하고, 특히 오디오 분야에서의 잠재력을 조사하는 것을 제안한다.
또한, DoRA의 다양한 다른 응용 분야에서의 잠재력을 조사하는 것도 흥미롭게 여긴다.
