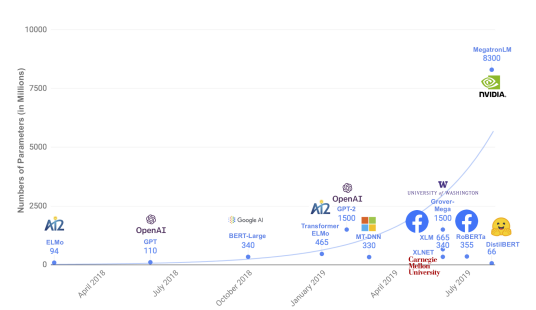
기존 문제점
- BERT는 Pre-trained + finetuning 하여 사용
- Pre-trained는 메모리 용량 및 프로세스 성능 등 많은 자원을 소요하는 문제
DistilBERT 개요
- DistilBERT는 기존 BERT-base 보다 40% 가볍고, 60% 빠름
- 모바일 device에 탑재하여 추론 가능한 속도의 모델
DistilBERT 특징
- 3가지의 Loss를 선형 결합하여 사용
- soft target loss (Lce) : Teacher와 Student 모델의 출력으로 구함
- hard target loss (Lmlm) : 같은 데이터로 일반적인 MLM Loss 최소화하도록 학습
- cosine embedding loss (Lcos) : 허깅페이스 팀에서 추가한 Loss. Teacher와 Student의 마지막 레이어의 은닉 상태 벡터를 가져와 Loss를 구함
- Teacher의 가중치로 초기화, 6개의 레이어를 사용하고 있기 때문에 Teacher의 레이어 2개 중 하나씩 선택
DistilBERT의 기존 BERT와 차이점
- Token-type Embedding 제거(즉, Segment Embedding 제거, NSP 안함, PyTorch에서 Token_type_ids와 동일)
- Pooler 제거(기존 BERT의 마지막 레이어의 은닉상태벡터에서 첫번째 토큰인 Pooler output 사용을 안함)
- 레이어 개수 절반(트랜스포머 구조에서 사용하는 프레임워크는 행렬 연산이 최적화 되어 있어 차원은 유지)
실험 결과
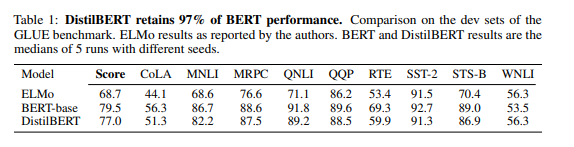
-
2개의 BiLSTM을 사용한 ELMo model과 original BERT와 GLUE로 성능을 비교. 9개의 Task에서 ELMo와 비슷하거나 높은 성능
-
BERT-base의 97% 성능 도달 (하지만 40% 적은 파라미터를 가짐)
-
WNLI Task에서는 BERT-base를 역전
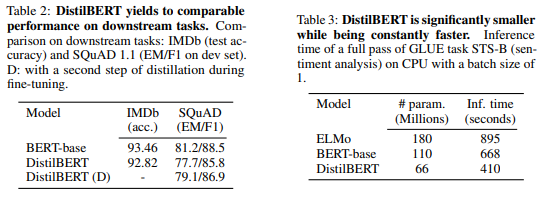
-
다운스트림 태스크에서는 감성분류와 질의응답 태스크를 수행
-
두 task 모두 BERT-base와 유사한 accuracy와 F1 Score
Ablation study
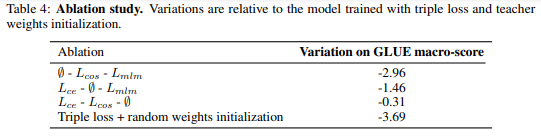
- Loss의 3가지 요소, 가중치 초기화 방법까지 4가지 요소를 하나씩 빼며 성능 비교
- MLM Loss 제거 손실이 가장 성능에 적은 영향을 미침

NLP