Abstract
- 딥러닝에서 데이터 양과 품질 간 딜레마 해결이 지속적인 과제.
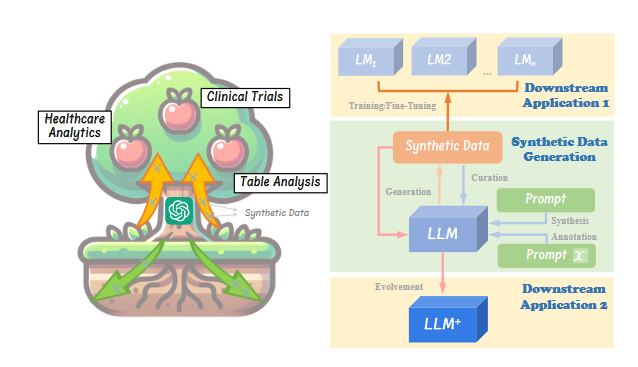
- LLM(대규모 언어 모델)을 활용한 합성 데이터 생성은 데이터 중심의 새로운 솔루션 제공.
- 본 논문은 합성 데이터 워크플로우에 대한 연구를 체계적으로 정리.
Introduction
- 고품질 데이터: 인간 의도를 반영한 다양성 있는 데이터가 이상적.
- 문제점: 높은 비용, 데이터 부족, 개인 정보 보호 문제와 더불어, 인간 생성 데이터가 편향적일 수 있음.
- LLM의 가능성:
- 사전 학습과 명령 수행 능력을 활용해 데이터 생성 최적화 가능.
- 정확성과 다양성을 갖춘 데이터 생성을 위해 신중한 설계 필요.
Preliminaries
2.1 문제 정의
- Seed sample 활용: 소규모 샘플(예: Dsup)을 제공하여 데이터를 생성하며, 이는 중요한 입력값.
- 수식 표현:
Dgen ← Mp(T, Dsup)
• Dgen: 최종 생성된 데이터셋을 나타냄
• p: 모델 추론에 사용되는 프롬프트
• T: 생성 작업(예: 재작성, 질의응답, 주석 등)을 지정
2.2 데이터 요구사항
- 정확성(Faithfulness):
- 생성된 데이터는 논리적, 문법적으로 일관성이 있어야 하지만, LLM의 환각(hallucination) 문제로 오류가 발생할 수 있음.
- 다양성(Diversity):
- 텍스트 길이, 주제, 스타일의 변화를 반영해야 하며, 다양성이 부족할 경우 모델 과적합 및 편향 발생 가능.
3. Generic Workflow
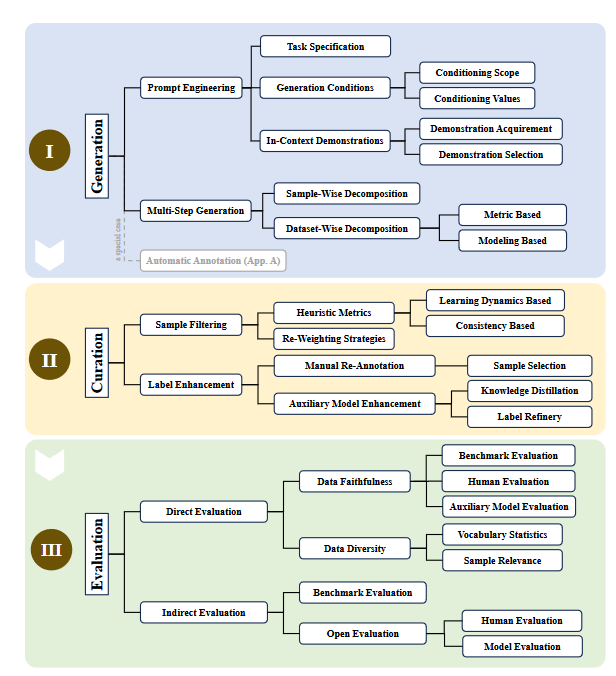
3.1 데이터 생성(Data Generation)
-
프롬프트 엔지니어링
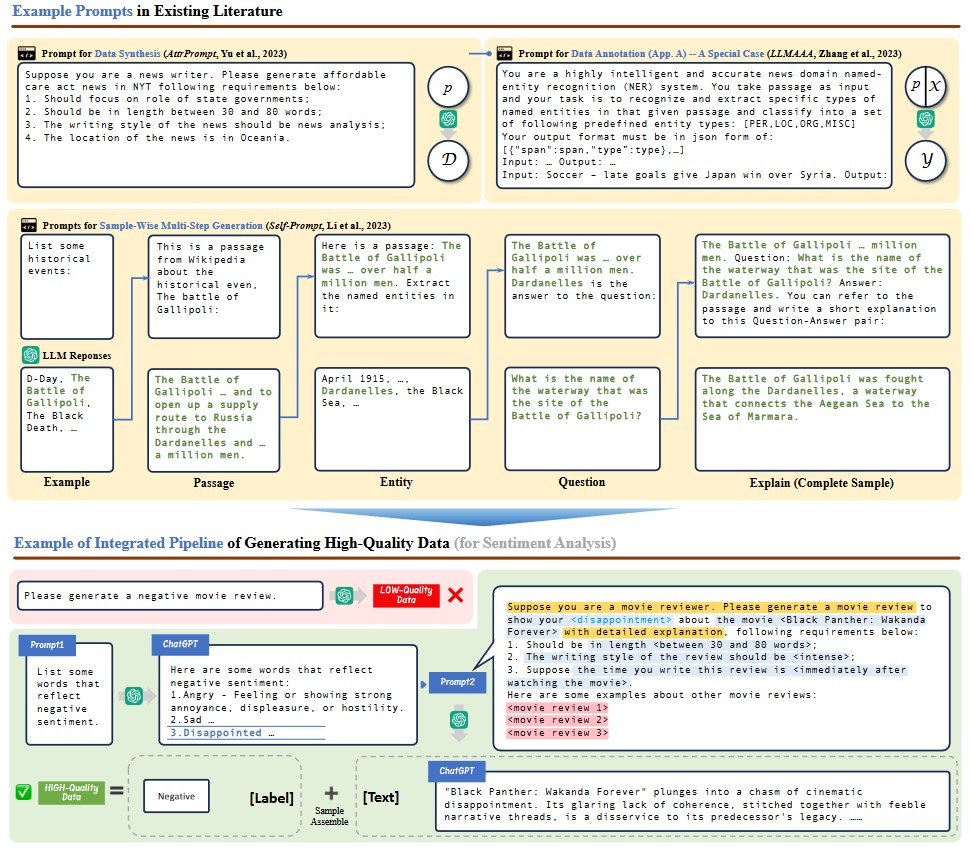
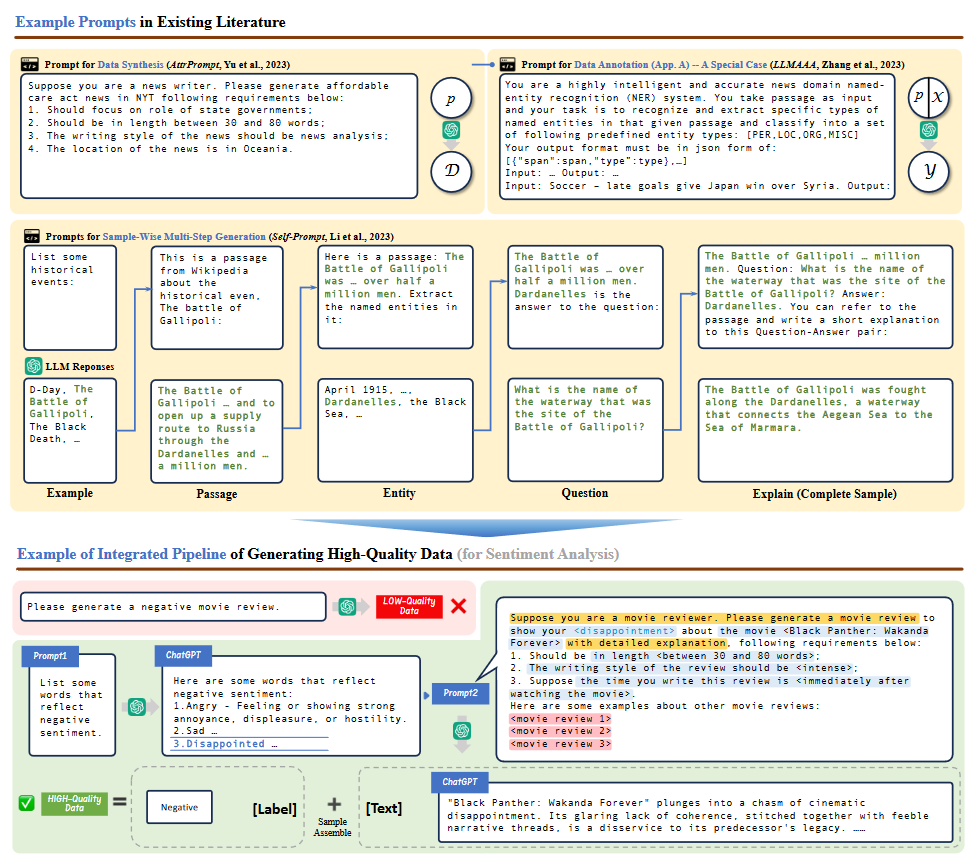
- 태스크 명세, 생성 조건, 예시를 포함하여 정확성과 다양성을 높임.
- 조건부 프롬프트(Conditional Prompting)는 데이터 다양성을 보장하기 위해 조건-값 쌍으로 설계.
-
다단계 생성(Multi-Step Generation)
- 복잡한 작업을 하위 작업으로 나누어 단계별로 데이터 생성.
- 샘플 단위 분해(Sample-Wise Decomposition)와 데이터셋 단위 분해(Dataset-Wise Decomposition) 전략 활용.
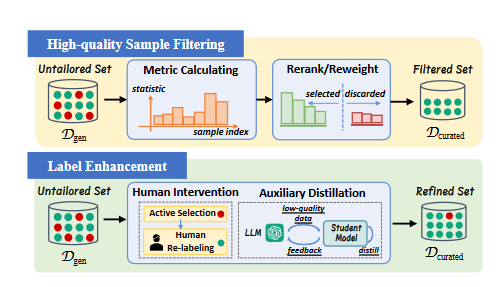
3.2 데이터 정제(Data Curation)
-
고품질 샘플 필터링
- 휴리스틱 기준(예: 확신 점수, 생성 확률)을 통해 저품질 데이터 제거.
- 샘플 재가중화(Re-weighting)로 데이터 중요도 조정.
-
라벨 보강(Label Enhancement)
- 인간 개입 또는 보조 모델(예: FreeAL, MCKD)을 활용해 라벨 정확도 향상.
- 비용 효율적인 지식 증류 방법 제안.
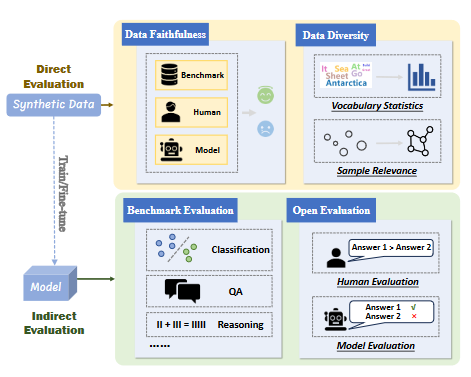
3.3 데이터 평가(Data Evaluation)
-
직접 평가(Direct Evaluation)
- 데이터 정확성(Faithfulness)과 다양성(Diversity)을 정량적 지표로 평가.
- 코사인 유사도 및 N-gram 빈도 기반 다변성 평가.
-
간접 평가(Indirect Evaluation)
- 생성 데이터를 사용한 다운스트림 모델의 성능을 평가(예: TruthfulQA, NIV2).
- 자동 평가 프레임워크(예: GPT-4 기반 평가) 활용으로 비용 절감.
4. Future Directions
4.1 복잡한 작업 분해(Complex Task Decomposition)
- LLM 기반 데이터 생성 에이전트를 개발하여 복잡한 시나리오 지원.
4.2 지식 강화(Knowledge Enhancement)
- 외부 지식 그래프 및 자동 조건 제어로 데이터 정확성과 효율성 향상.
4.3 대규모 및 소규모 모델 협업(Synergy between Large & Small LMs)
- 다양한 협업 구조 설계를 통해 데이터 품질 개선.
4.4 인간-모델 협업(Human-Model Collaboration)
- 인간 중심 인터랙션 시스템 설계로 데이터 편향 문제 해결 및 효율적 협업.
5. 결론(Conclusion)
- LLM을 활용한 데이터 생성, 정제, 평가 워크플로우를 체계적으로 제시.
- 기업과 조직이 도메인 특화 데이터셋을 효과적으로 구축하도록 지원.
- 미래에는 LLM 커뮤니티가 자가 개선 능력을 갖춘 생체공학적 AI로 발전할 가능성 탐구.
핵심 요약
- 본 논문은 LLM 기반 합성 데이터 생성 및 활용 전략을 다루며, 다양한 분야의 데이터 중심 AI 개발에 중요한 지침을 제공합니다.

NLP