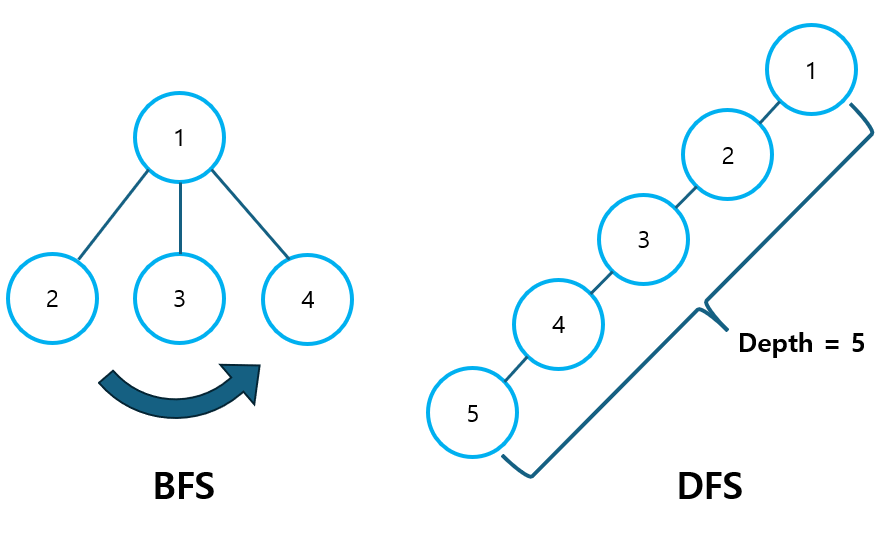
지금까지 배운 Graph의 개념을 활용하여, 이번에는 Tree 자료구조와 관련한 실전 문제를 풀어보도록 하겠습니다. 특히 이번 포스팅에서는 BFS와 DFS를 활용하는 방법에 대해 알아보겠습니다.
1. 사전 지식
1) BFS/DFS 선택
BFS/DFS 문제 중에는 BFS/DFS 중 적합한 방법을 결정하기 어렵거나, 문제를 보고도 BFS/DFS를 활용해야 하는 문제임을 파악하기 어려운 경우가 많다. 노드 탐색의 방향성이 명확하게 상하 또는 좌우인 경우에 대해서는 각각 DFS와 BFS를 사용하면 되지만, 그렇지 않은 경우에 대해서는 아래와 같은 기준이 유용할 수 있다.
- 인접한 노드를 탐색해야 하는 문제 → BFS
- 노드간 연결 깊이를 따져야하는 문제 → DFS
만약, BFS/DFS를 모두 사용해도 되는 문제인 경우, 재귀함수로 구현을 단순화할 수 있는 DFS를 사용하는 것이 일반적이지만, 최단 거리를 구해야 하는 문제에는 BFS를 사용(가중치가 없는 그래프 한정)해야 한다.
2) Tree의 표현
Tree를 표현할 때에는, 아래와 같은 방법을 사용할 수 있다.
① 딕셔너리
- Tree Traversal 문제에서 사용
- 부모 노드를 Key로, 자식 노드 튜플을 Value로 사용
② 배열
- 완전 이진 트리(전 이진 트리)에서 사용 (배열의 index는 1번부터 시작)
- i 노드의 왼쪽 자식은
2i인덱스에 위치 - i 노드의 오른쪽 자식은
2i + 1인덱스에 위치 - i 노드의 부모는
i // 2인덱스에 위치
- i 노드의 왼쪽 자식은
③ 인접 리스트
- 문제의 입력이 간선 형태인 경우 사용
- 사실상 거의 모든 문제에서 사용
④ 인접 행렬
- 문제의 입력이 행렬 형태인 경우 사용
2. 문제 풀이
1) 연결 요소의 개수 구하기
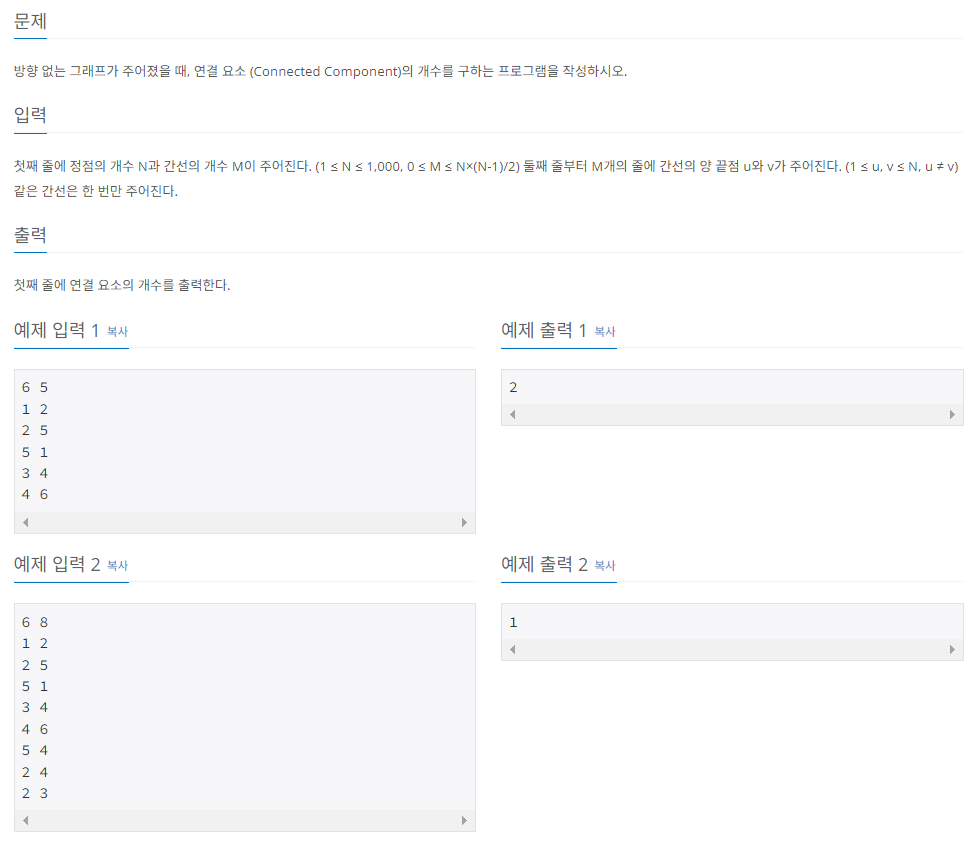
문제의 내용이 조금 불명확한데, 문제에서 말하는 연결 요소의 개수는 연결 그래프의 개수를 말하는 것이다. 즉, 몇 번의 BFS 또는 DFS를 활용해야, 모든 노드를 방문할 수 있는지 알아내야 한다는 것이다. 이 문제는 BFS와 DFS를 모두 사용할 수 있는 문제이므로, DFS를 사용하기로 한다.
또한, 위 문제의 입력이 간선인 것으로 보아, 적합한 트리 표현 방식은 인접 리스트가 될 것이다. 다만, 문제에서 주어지는 입력 값만으로는 상하 관계를 알 수 없으므로, 일단은 양방향 간선으로 간주하기로 하자. 참고로, Tree는 유향 그래프와 무향 그래프로 모두 표현될 수 있으나, 위 문제와 같이 상하 관계가 명확하지 않은 경우에는 무향 그래프로 구현한다.
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10 ** 8)
N, M = map(int, input().split())
tree = [[] for _ in range(N + 1)]
visited = [0] * (N + 1)
def dfs(V):
visited[V] = 1 # 방문 표시
# 인접 노드 중 방문하지 않은 노드에 대해 DFS 실행
for i in tree[V]:
if visited[i] == 0:
dfs(i)
for i in range(M):
u, v = map(int, input().split())
tree[u].append(v)
tree[v].append(u) # 양방향 간선
result = 0
for i in range(1, N + 1):
if visited[i] == 0: # 방문하지 않은 모든 노드에 대해 DFS 실행
result += 1 # DFS의 호출 횟수
dfs(i)
print(result)2) 미로 탐색하기
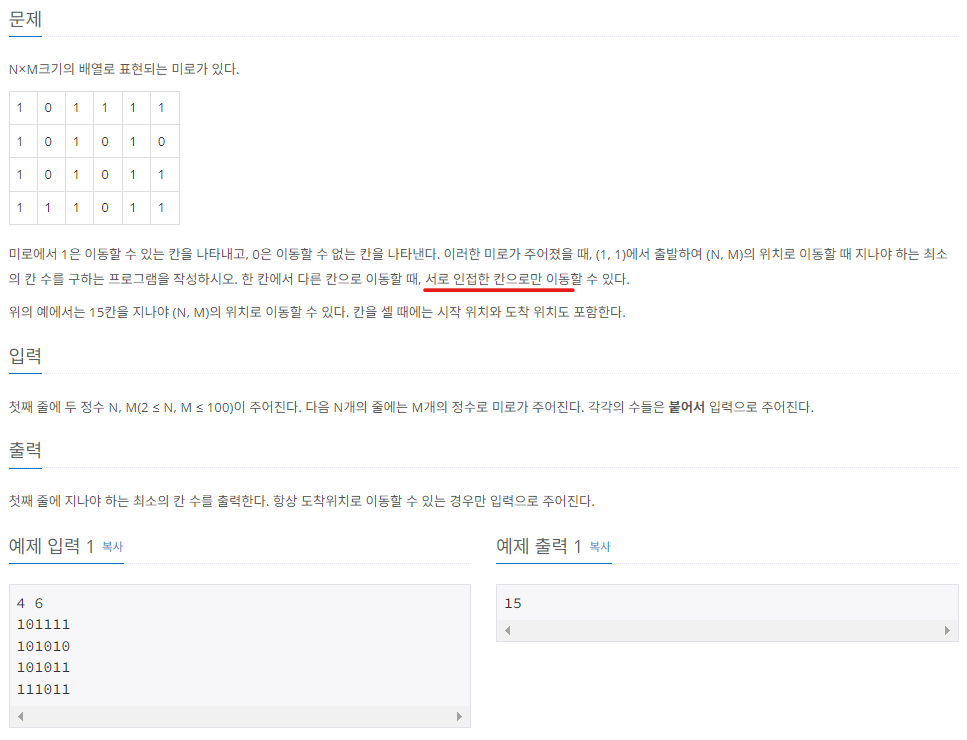
위 문제의 경우 인접한 칸으로 이동하는 문제임과 동시에, 노드 간 연결 깊이를 출력해야 하는 문제이다. 물론, BFS/DFS를 모두 사용할 수 있는 문제이긴 하지만, 최단 거리를 구하는 문제라는 점에서 BFS가 적합하다.
import sys
input = sys.stdin.readline
from collections import deque
N, M = map(int, input().split())
graph = [list(map(int, input().strip())) for i in range(N)]
visited = [[0 for col in range(M)] for row in range(N)]
# 인접 노드로 이동하기 위한 배열(상 -> 하 -> 좌 -> 우 순 탐색)
di = [0, 0, -1, 1]
dj = [-1, 1, 0, 0]
def bfs(i, j):
deq = deque()
deq.append((i, j))
visited[i][j] = 1
while deq:
i, j = deq.popleft()
for k in range(4): # 상하좌우 탐색
row = i + di[k]
col = j + dj[k]
if 0 <= row < N and 0 <= col < M: # 인덱스 유효성 평가
if visited[row][col] == 0 and graph[row][col] == 1: # 이동이 가능하면서 방문하지 않은 칸
deq.append((row, col))
visited[row][col] = visited[i][j] + 1 # 최단 거리 측정을 위해 노드를 이동할 때마다 1씩 더함.
bfs(0, 0)
print(visited[N - 1][M - 1])위 문제와 같이 공백 없이 입력되는 숫자를 리스트로 받아야 할 때는, 일단 문자열 형태로 입력 받은 후, 그 값을 리스트로 변환해야 한다.
3) 트리의 지름 구하기
위 문제는 최장 거리를 구하는 문제이므로, DFS가 적합하다. DFS가 유리한 이유에 대해서는 아래의 속성을 참고하라.
- 트리에 존재하는 특정 노드에서 최대 거리에 있는 노드는, 반드시 트리의 리프 노드 중 하나이다.
BFS/DFS를 이용하여 노드 간 최단 거리 및 최장 거리를 구하는 문제는 아래와 같이 해결할 수 있다.
- visited 배열을 -1로 초기화한다.
- 특정 노드를 방문했을 때, 출발 노드로부터 해당 노드까지의 거리로 방문을 표시한다.
그런데 위 문제에서는 출발 노드가 어디인지 알 수 없으므로, 조금 특별한 방법을 사용하기로 한다. 임의의 노드를 선택한 후 그 노드로부터 DFS를 실행하면, 여러 개의 리프 노드에 도달하게 될 것이다. 그 중에서 최장 거리를 만드는 리프 노드는, 반드시 트리의 최장 경로의 양 끝 노드 중 하나가 된다.
이 내용이 잘 이해되지 않는다면, 아래의 예시를 참고하기 바란다.
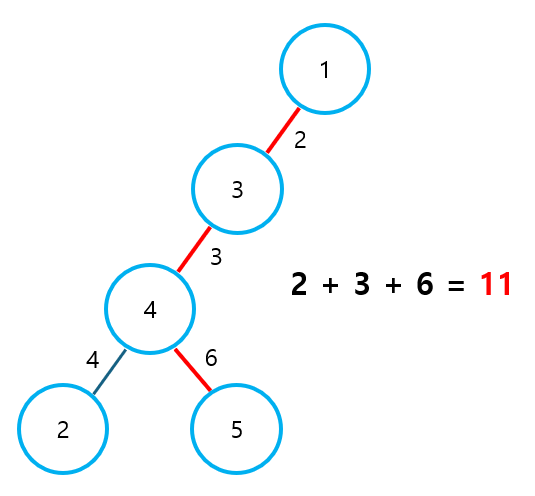
위 그림에서 빨갛게 표시된 경로는 최장 경로를 의미한다. 이 때, 임의의 노드를 선택하여 DFS를 실행한 후 최장 거리를 만들어내는 노드의 번호를 구하면, 반드시 최장 경로의 양 끝점인 1번 또는 5번 노드가 된다.
① 1번 노드 기준 → 5번 노드 선택
- 2번: 경로 가중치 9
- 5번: 경로 가중치 11
② 2번 노드 기준 → 5번 노드 선택
- 1번: 경로 가중치 9
- 5번: 경로 가중치 10
③ 3번 노드 기준 → 5번 노드 선택
- 1번: 경로 가중치 2
- 2번: 경로 가중치 7
- 5번: 경로 가중치 9
④ 4번 노드 기준 → 5번 노드 선택
- 1번: 경로 가중치 5
- 2번: 경로 가중치 4
- 5번: 경로 가중치 6
⑤ 5번 노드 기준 → 1번 노드 선택
- 1번: 경로 가중치 11
- 2번: 경로 가중치 10
즉, 임의의 노드에 대해 DFS를 실행하여 최장 경로의 출발 노드를 찾아낸 후, 해당 노드로부터 다시 DFS를 실행하여 최종적으로 최장 경로를 구하게 되는 것이다.
import sys
input = sys.stdin.readline
sys.setrecursionlimit(10 ** 8)
V = int(input())
tree = [[] for _ in range(V + 1)] # 인접 리스트를 이용한 트리 표현
visited = [-1] * (V + 1)
visited[1] = 0 # 1번 노드를 임의의 노드로 선정
def dfs(u, dist): # dist는 u 노드까지의 거리를 되물림하기 위한 용도로 사용
visited[u] = dist
for v, w in tree[u]:
if visited[v] == -1:
dfs(v, visited[u] + w) # (출발 노드부터 v까지의 거리) = u까지의 거리 + u-v의 가중치
for i in range(1, V + 1):
lst = list(map(int, input().split()))
for j in range(1, len(lst) - 1, 2):
tree[lst[0]].append((lst[j], lst[j+1]))
dfs(1, 0) # 최장 경로의 출발 노드를 찾기 위한 DFS
Max = 0
leaf_idx = 0
for i in range(1, V + 1):
if Max < visited[i]:
Max = visited[i]
leaf_idx = i # 최장 거리를 만드는 리프 노드의 번호
visited = [-1] * (V + 1) # visited 배열 초기화
visited[leaf_idx] = 0 # 구해진 리프 노드를 출발 노드로 선정
dfs(leaf_idx, 0) # 최장 거리를 구하기 위한 DFS
print(max(visited)) # 최장 거리 출력4) 신기한 소수 찾기
소수를 찾는 문제라는 점에서 에라토스테네스의 체를 이용한 풀이를 떠올릴 수 있다. 이전 포스팅에서 에라토스테네스의 체 문제를 풀이할 때에는, 메모리 제약을 먼저 계산해야 한다고 배웠다. 문제에서 N의 최대 값은 8이므로 최악의 경우, (1억 - 1)개의 숫자를 저장해야 한다. 이는 대략적으로만 생각해도 4MB의 메모리 제한을 크게 초과하는 수치이다.
따라서, 신기한 소수를 찾아내는 다른 전략을 생각해보기로 하자. 위 문제 풀이에 중요한 단서가 되는 내용은 아래와 같다.
- 반드시 N자리 숫자여야 한다.
- N 자리 수의 맨 앞 자리 수는 반드시 2, 3, 5, 7 중 하나여야 한다.
- 맨 앞자리를 제외한 뒷 자리수는 짝수만 아니면 된다(1, 3, 5, 7, 9 중 하나여야 한다).
즉, 탐색 깊이가 N이 될 때까지 탐색하여, 위 조건을 만족하는 소수를 출력하면 되는 문제이므로 DFS로 풀이할 수 있다. 참고로, 소수 판별 방법은 에라토스테네스의 체에서 사용하던 방법을 그대로 사용할 것이다.
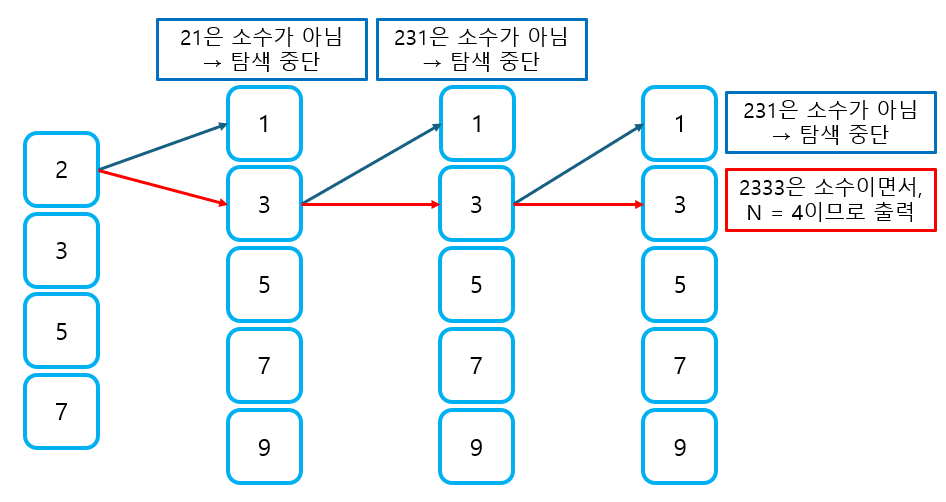
import sys
input = sys.stdin.readline
N = int(input())
def isPrime(num): # 에라토스테네스의 체에서 사용하던 알고리즘
for i in range(2, int(num ** 0.5) + 1):
if num % i == 0:
return False
return True
def dfs(num):
if len(str(num)) == N: # 탐색 깊이가 N이면
print(num) # 출력
else:
for i in range(1, 10, 2):
if isPrime(num * 10 + i): # 소수인 경우에만 계속 탐색
dfs(num * 10 + i)
first_digits = [2, 3, 5, 7] # 맨 앞 자리는 반드시 소수
for i in first_digits:
dfs(i)5) 친구 관계 파악하기
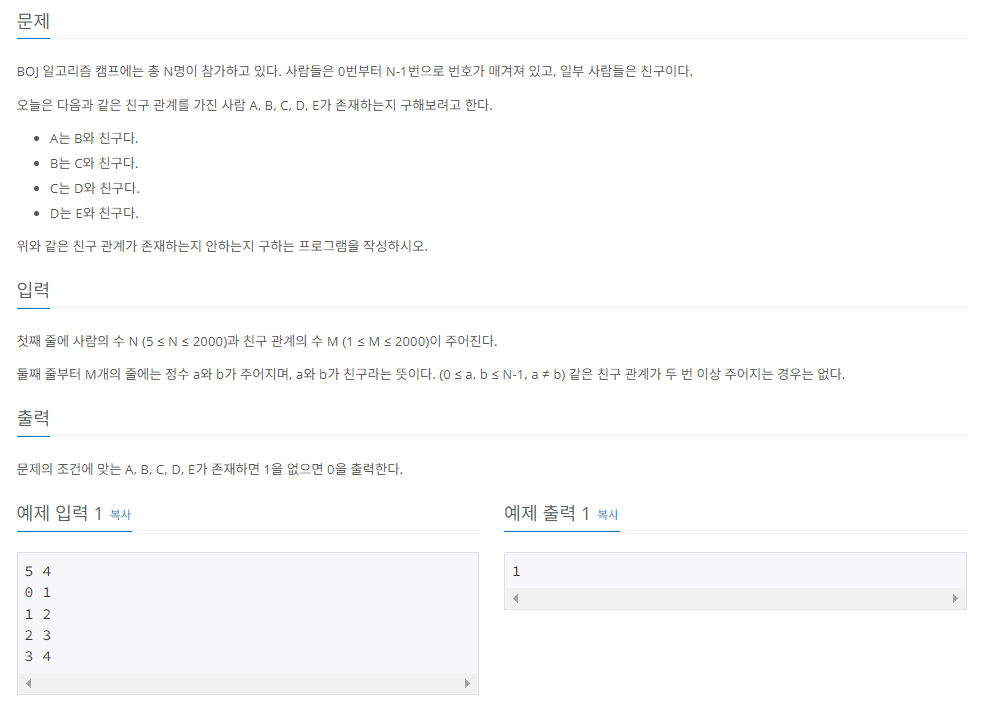
위 문제는 쉽게 말해 노드간 연결 깊이가 5가 되는 경우가 존재하는지를 판별하라는 것이다. 따라서, DFS를 이용하여 풀이할 수 있다.
import sys
input = sys.stdin.readline
N, M = map(int, input().split())
graph = [[] for i in range(N)]
visited = [0] * N
for i in range(M):
a, b = map(int, input().split())
graph[a].append(b)
graph[b].append(a) # 양방향 간선
def dfs(V, depth):
if depth == 5:
print(1)
exit(0) # depth가 5인 것을 확인하면, 1을 출력하고 프로그램을 종료
visited[V] = 1
for i in graph[V]:
if visited[i] == 0:
dfs(i, depth + 1)
visited[V] = 0 # DFS 백트래킹(아래의 설명 참고)
for i in range(N):
dfs(i, 1)
print(0) # 프로그램이 종료되지 않았다면, 0을 출력위 문제 풀이에서 가장 주의해야 할 부분은 바로 DFS 백트래킹이다. 여기서 DFS 백트래킹이란, DFS를 수행하는 도중 현재의 경로가 문제의 해가 될 수 없다는 것을 알았을 때, 방문한 노드를 미방문으로 변경하면서 다시 돌아오는 것을 말한다.
문제가 아래의 조건을 모두 만족할 경우, 반드시 DFS 백트래킹을 적용해야 한다.
- 사이클이 포함된 그래프에서 노드 간 연결 깊이를 따져야 하는 경우
- 특정 조건을 만족할 때, 탐색을 중단해야 하는 경우
즉, 위 문제가 대표적으로 DFS 백트래킹을 사용해야 하는 문제인 것이다. 사실, 백트래킹 없이 DFS를 구현해도 대부분의 경우에서 잘 동작한다. 이는 모든 노드에 대해 DFS를 수행할 때, 적어도 하나의 DFS에서만 깊이 5 이상의 연결을 확인하면 되기 때문이다. 즉, DFS만 이용해도, 충분히 높은 확률로 깊이 5 이상의 연결을 확인할 수 있는 것이다.
그러나, DFS는 어디까지나 모든 노드를 중복 없이 방문하는 알고리즘일 뿐이므로, 깊이가 5 이상인 연결을 찾아낼 수 있음을 보장하지는 못한다. (사이클이 존재하는 그래프에서의 DFS는 각 노드의 연결 깊이를 제대로 계산하지 못할 수 있다.) 즉, 운이 나쁜 경우, 모든 DFS에서 깊이가 5 이상인 연결을 찾지 못할 수도 있는 것이다. 아래의 그림을 보자.
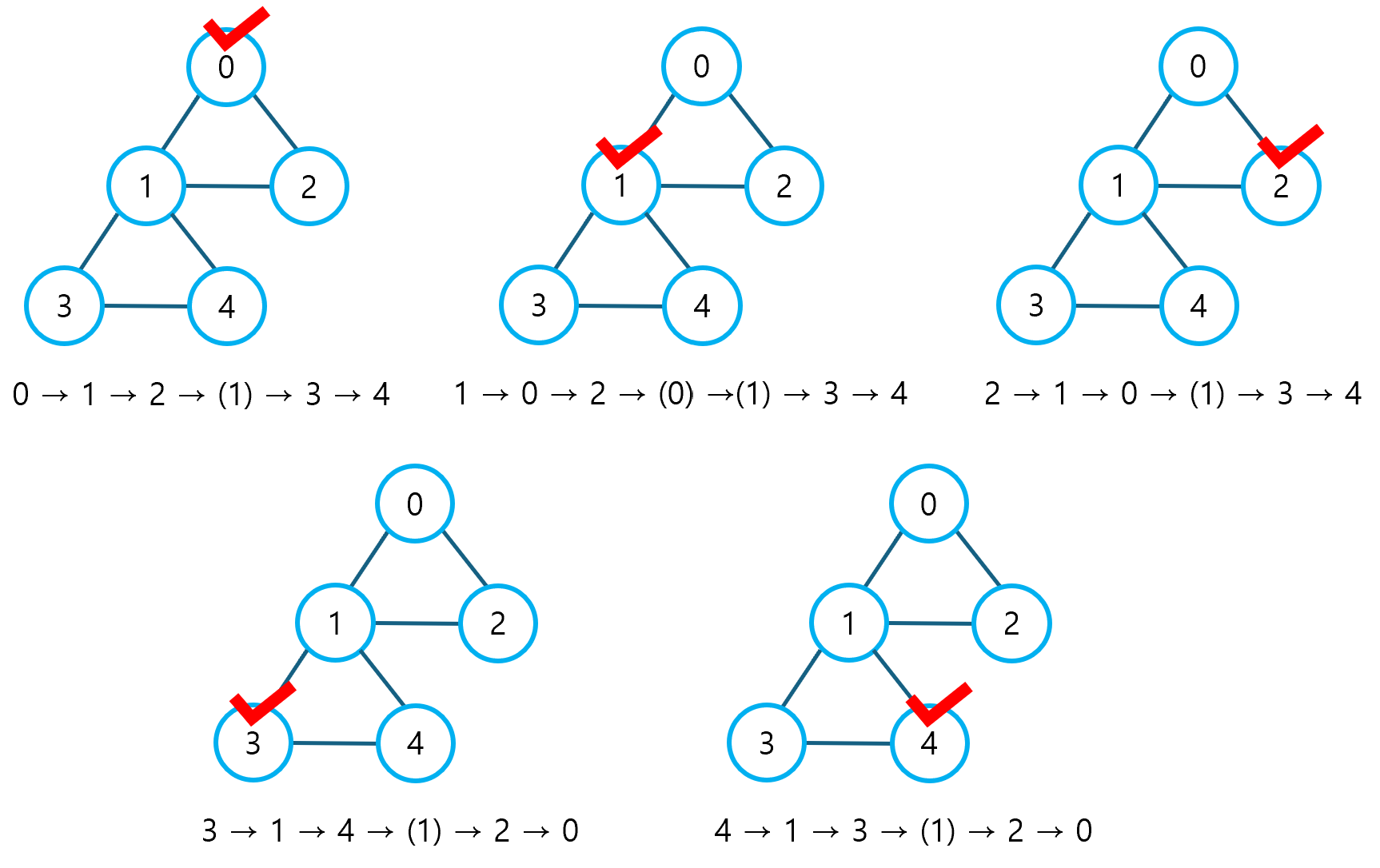
실제로 위 그림과 같이 동작할 경우, 분명 깊이가 5 이상인 연결이 존재함에도, 그 연결을 찾지 못하게 된다. (DFS가 깊이 5 이상의 연결을 보장할 수 없음을 설명하기 위한 그림일 뿐, 실제 동작과는 차이가 있을 수 있다.) 이 때, DFS 백트래킹을 사용하면, 깊이 5 이상의 연결을 반드시 찾을 수 있게 된다.
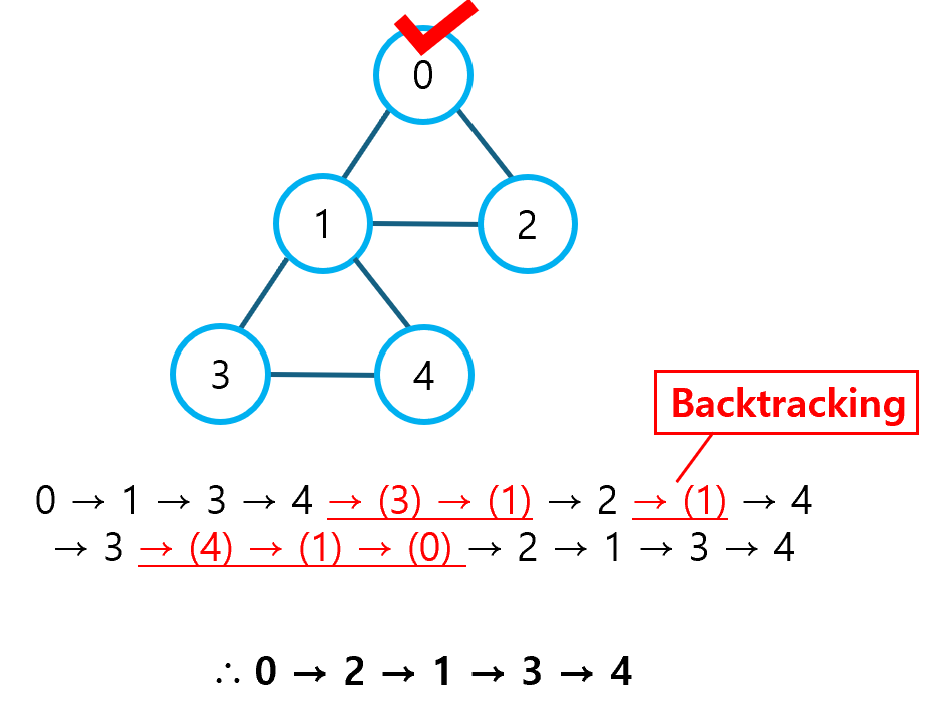
DFS 백트래킹에 대한 자세한 내용은 아래의 포스팅을 참고하기 바란다.
>> DFS 백트래킹
마지막으로, 위 문제에서 사용된 전역 변수에 대해 설명하는 것으로 이번 포스팅을 마치도록 하겠다.
① 전역 변수의 필요성
- def 스코프 내에서 외부에 선언된 변수를 읽는 것은 가능하지만, 수정하는 것은 불가능하다.
## 외부 변수를 읽어오는 것은 가능 ##
count = 1
def func():
print(count)
func() # 1 출력
## 외부 변수를 수정하는 것은 불가능 ##
count = 1
def func():
count = 100
func()
print(count) # 1 출력- 만약 def 스코프 내에서 외부 변수를 수정해야 한다면, global 키워드를 사용해야 한다.
count = 1
def func():
global count
count = 100
func()
print(count) # 100 출력② 전역 변수의 사용법
- 함수 외부에서 local variable 형태로 변수를 선언한다.
- def 스코프 내에서 외부 변수명 앞에 global 키워드를 추가한다.
- global 키워드는 함수 외부의 local variable을 global variable로 변환하는 역할을 수행하기 때문에, 선언과 동시에 할당이 불가하다.
found = False # 함수 외부에서 local variable 형태로 변수를 선언
def dfs(V, depth):
global found # def 스코프 내에서 외부 변수명 앞에 global 키워드를 추가
found = True # 선언과 동시에 할당이 불가 ex) global found = True (X)참고로, 함수를 정의하여 문제를 풀어야 하는 코딩 테스트 환경(Ex. 프로그래머스 등)에서는 내부 함수에서 외부 함수의 로컬 변수를 수정하기 위해 nonlocal 키워드를 사용한다. 기본적인 사용법은 global과 동일하므로, 아래의 예시 코드를 참고하기 바란다.
from collections import deque
def solution(stones, k):
N = len(stones)
visited = stones
cnt = 0 # cnt를 로컬 변수로 선언
def bfs(V):
nonlocal cnt # 함수 내부에서 cnt 변수를 수정하기 위해 nonlocal 사용
deq = deque()
deq.append(V)
...