머신러닝
1.[sklearn] (확률적)경사하강법과 SGDClassifier
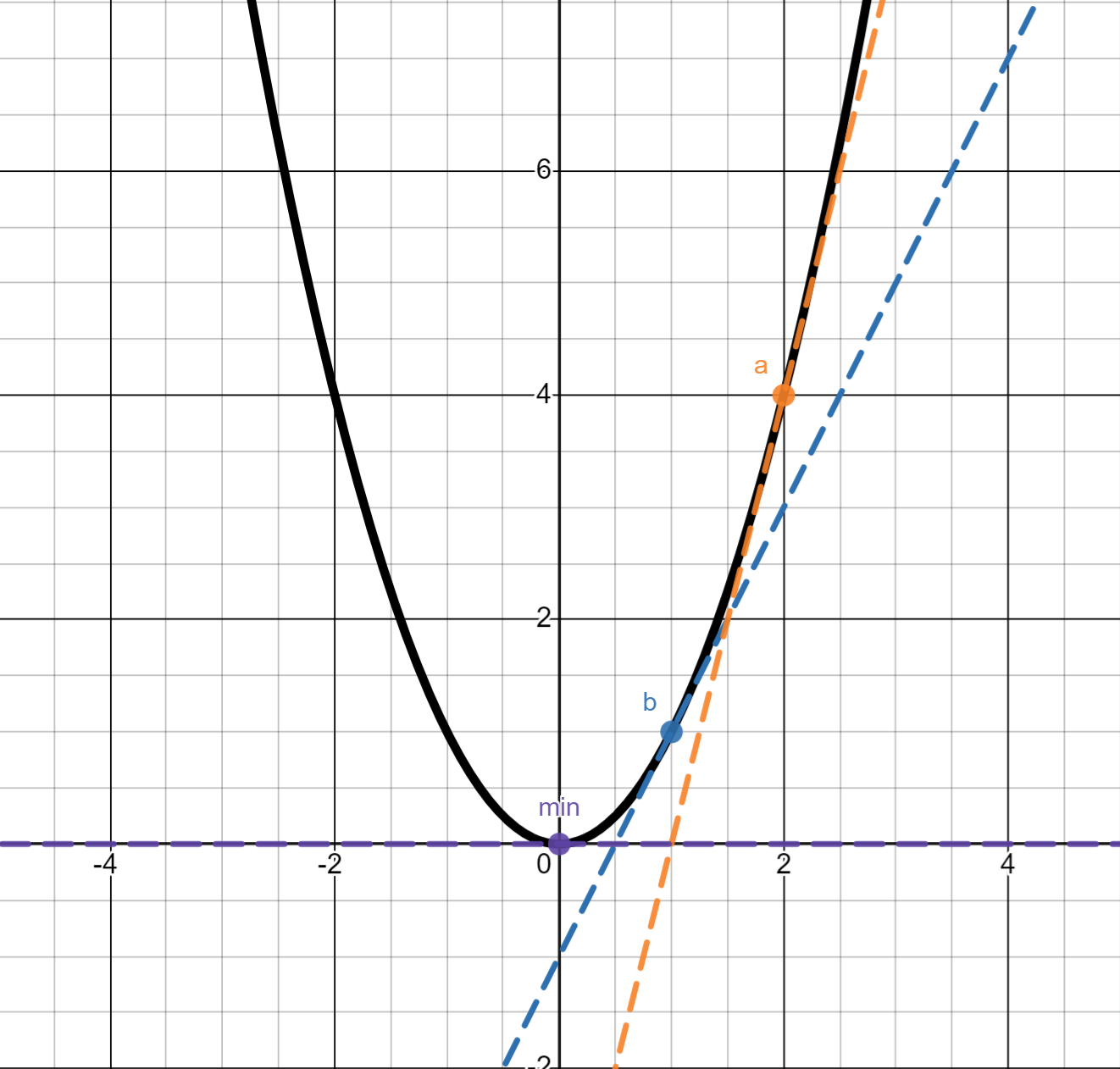
확률적 경사 하강법(Stochastic Gradient Decent:SGD)을 통해 SVM, logistic regression 등의 선형 분류기를 학습시킬 수 있는 분류기입니다.
2023년 5월 16일
2.[sklearn] 서포트 벡터 머신(SVM)
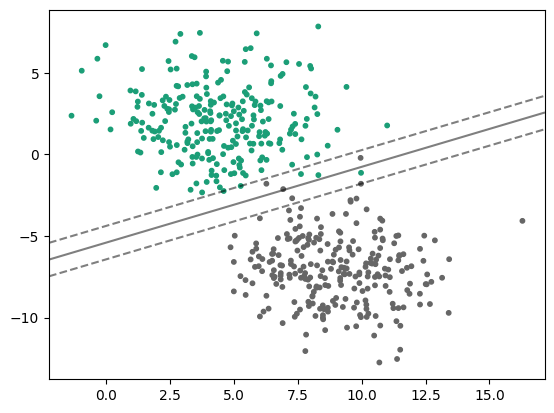
서포트 벡터 머신은 각 클래스를 분류하는 최대의 마진을 가지는 결정 경계를 찾는 알고리즘이다.
2023년 5월 18일
3.[머신러닝] 데이터의 스케일 조정

데이터의 스케일이 크게 차이가 나는 경우 서포트 벡터 머신과 같은 스케일에 민감한 모델들은 그 성능을 제대로 발휘하지 못하므로, 가급적 데이터의 스케일은 통일해주는 것이 좋다.
2023년 5월 24일
4.[머신러닝] 딥러닝의 변천사 및 유명 모델들의 구조
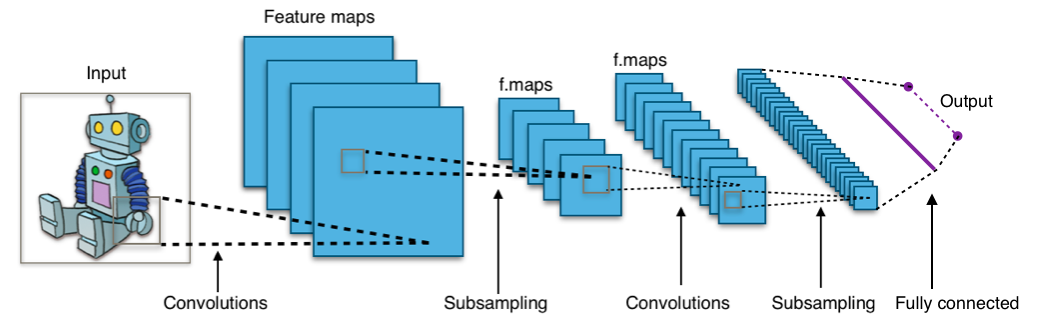
딥러닝은 인공신경망을 기반으로 한 기술로, 복잡한 패턴 인식과 추론을 수행하는 데 강점을 가지고 있습니다. 딥러닝의 기원은 인공신경망에 대한 연구로 거슬러 올라갑니다.
2023년 7월 16일
5.pytorch에서 데이터 로드하기
pytorch에서 데이터를 모델에 로드하는 경우 기존 머신러닝 라이브러리와 다르게 DataLoader class를 상속받는 별도의 클래스를 만들어 로드하여야 한다.
2023년 7월 22일
6.pytorch로 IMDB 영화 평점 데이터 분류하기
IMDB 평점 데이터는 Kaggle이나 각종 입문 강좌에서도 예제로 많이 사용하는 데이터라 매우 구하기 쉽다. 데이터는 (label: integer, text: string)으로 구성된다.
2023년 7월 24일
7.[강화학습] 강화 학습이란?(마르코프 결정 프로세스)
연구실에서 강화학습 기반 타임 슬롯 할당 기법에 대한 연구를 진행하고 있다. 이쪽 바닥에서 강화학습, 특히 DQN, DDPG 등 Q러닝 계열 강화학습 기법이 자주 쓰이고 있는 모양이다.
2024년 2월 13일