서포트 벡터 머신
서포트 벡터 머신은 각 클래스를 분류하는 최대의 마진을 가지는 결정 경계를 찾는 알고리즘이다.
서포트 벡터 머신은 시각적으로 이해하는 것이 가장 직관적이다. 예제를 보며 이해해보자.
데이터 생성
from sklearn.svm import SVC
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=500, centers=2, cluster_std=2, random_state=36)
plt.scatter(X[:,0], X[:, 1], s=10, c=y)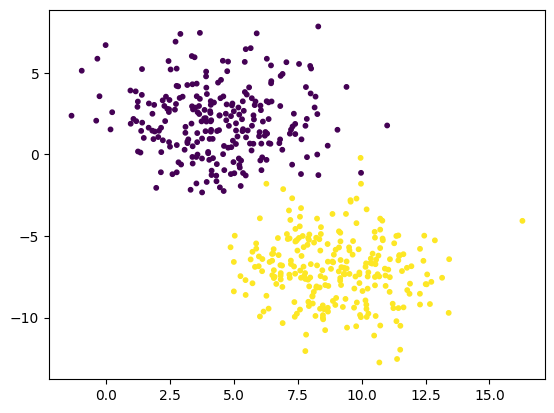
두 묶음으로 된 데이터가 준비되었으니 SVM을 훈련시켜보자.
sklearn의 sklearn.svm.SVC는 서포트 벡터 머신 분류기인데 이 분류기는 후술할 커널 트릭을 고려하여 설계된 분류기이므로 단순 선형 분류 성능이 조금 느리다. 선형 SVM만 필요하다면 sklearn.svm.LinearSVC을 사용하는 것이 좋다(대신 얘는 커널 트릭을 지원하지는 않는다).
from sklearn.svm import LinearSVC
linear_svc = LinearSVC(max_iter=5000)
linear_svc.fit(X, y)- SVM 분류기가 훈련되었다. 이제 결정 경계를 그려 어떻게 분류되었는지 확인해보자.
SVM의 결정 경계를 그려보자
def plot_svm_boundary(clf, X, y):
X_min, X_max = X[:, 0].min() - 1, X[:, 0].max() + 1
y_min, y_max = X[:, 1].min() - 1, X[:, 1].max() + 1
xx, yy = np.meshgrid(
np.arange(X_min, X_max, .01),
np.arange(y_min, y_max, .01)
)
Z = clf.predict(np.c_[xx.ravel(), yy.ravel()])
Z = Z.reshape(xx.shape)
plt.contourf(xx, yy, Z, cmap="Dark2", alpha=0.1)
plt.scatter(X[:,0], X[:, 1], s=10, c=y, cmap="Dark2")
plt.xlim(xx.min(), xx.max())
plt.ylim(yy.min(), yy.max())
plt.show()
plot_svm_boundary(linear_svc, X, y)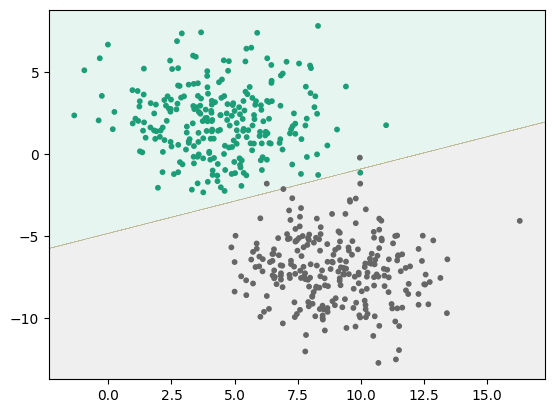
두 영역 사이의 경계선이 결정 경계이다. 녹색과 회색으로 구분된 두 데이터가 대체적으로 잘 분류된 것을 확인할 수 있다.
하드 마진과 소프트 마진
선형 SVM에서, 결정 함수는 이며 결정 함수의 값이 0보다 큰 경우와 작은 경우로 나누어 분류를 진행한다.
이 때 마진(margin)은 결정 함수 의 값이 , 일 때의 두 직선 사이의 거리로 정의한다.
- 하드 마진(hard margin)
- 하드 마진은 위에서 정의한 마진 사이에 데이터가 들어가는 것을 용납하지 않는다. 따라서 결정 경계가 데이터를 잘 대표하지 못할 가능성이 비교적 높다.
- 소프트 마진(soft margin, C-SVM)
- 소프트 마진은 마진 사이에 데이터가 들어가는 것을 허용한다. 대신 마진에 들어온 데이터의 수만큼 내부적으로 패널티를 부과한다.
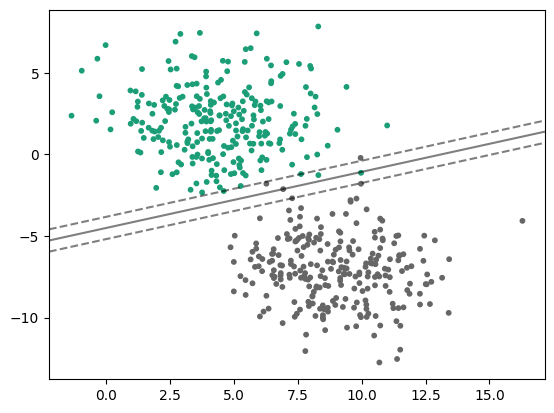
- 하이퍼파라미터로C가 있는데, 이 파라미터를 통해 부과하는 패널티의 정도를 조절하여 마진 폭을 조절할 수 있다.C가 커지면 마진 폭이 줄어들고C가 작아지면 마진 폭이 커진다.C=1일 때 결정 경계와 마진
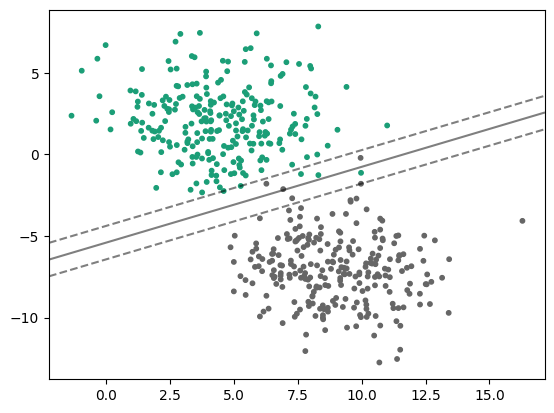
C=10일 때 결정 경계와 마진

네트워크와 인프라를 좋아하는 학부생