
0~2강
머신 러닝 > 딥러닝
머신 러닝 ?
컴퓨터 학습 시키는 것. 개 고양이 분류 해볼래? 하고 명령 내림 / nnn개의 사진 사용해서 뭐가 개고, 고양이인지 특징을 학습 시킴.
1. 전통적 머신러닝 : 개와 고양이의 특징을 구분 시켜야한다. 사람이 만든 가이드라인을 줘야한다.
vs
2. 딥러닝 : 가이드라인이 필요 없음. 컴퓨터가 알아서 찾음. 처음엔 예측하는데 실패하겠지만, 사진 천만장 씩 학습시키면 나중엔 결국 사진을 구분하게 됨.
ex. 구글 알파고
- 바둑 두는 법을 가르치지 않음. 알아서 하도록 학습시킨다. 모델이 학습에 성공하면 알아서 바둑 두는 법을 체득하게 된다.
딥러닝 장점
- 기존 머신 러닝보다 적용할 수 있는 범위가 많다.
- 내가 그 분야에 대해 잘 몰라도 ai를 만들 수 있음.
- 문제에 대한 지식, domain knowledge가 필요 없음.
딥러닝은 어떻게 가이드 없이 학습이 가능한가?
뉴럴 네트워크(신경망)를 이용해 머신 러닝을 진행하는게 딥러닝이다!
딥러닝이 매우 잘하는 분야
- 이미지 구분, image classification / object detection -> 자율 주행
- sepuence data 분석 & 예측 -> 순서가 있는 sequence 데이터, 어순 같은 데이터
"나는 너를 사랑해"(순서 데이터) -> i love you (순서 데이터)
-> 번역 ai 만드는 거싱 가능
🤖 머신 러닝
기계를 학습 시키는 것
ex. 사람 얼굴 인식
- 모종의 알고리즘을 가지고 판단하게 됨
(ex. 여기랑 저기가 까맣다? 그럼 사람일 가능성 +10 해라) - 가이드 안주고, 알고리즘을 기계 스스로 학습하게 하면 그것이 머신 러닝이다.
머신러닝 적용 예시
스팸 메일 분류
- 머신러닝 : 어떤 제목이 스팸 메일인지 nnn개 분석해서 알아서 깨우침
vs
- 인간 하드코딩 : 제목에 '광고', '할'인 같은 말 들어가면 스팸으로 분류 되도록 프로그래밍
🤖 머신러닝의 종류
- 풀고자 하는 문제나 데이터의 종류에 따라 다르다
1. Supervised Learning
데이터에 정답이 있고 정답 예측 모델을 만들 때 (ex. 동물 사진 구별)
2. Unsupervised Learning
데이터에 정답 (라벨)이 없음.
기계보고 알아서 비슷한 것 끼리 분류 군집화 해보라고 시킴.
ex) 옷 추천, 기사 추천 등의 알고리즘이 이에 해당
3. Reinforcement Learning (강화 학습)
게임과 비슷하다. 정답을 맞췄을 때 보상을 한다.
최종 점수를 높이는 방향으로 알아서 움직이도록 명령한다.
모델은 수만 번 시도해서 최적의 경우를 알아냄
어떻게 학습하지?
예를 들어, 6월 모고, 9월 모고 점수를 사용해 수능 성적을 예측해본다고 가정하자.



- weight (가중치, w) : 어떤 데이터가 얼마나 큰 영향력을 가지는 가
- bias (편향, b) : 6월, 9월이랑은 관련 없는데 수능이랑은 관련 있는 요소
ex) 난이도
위 수식을 컴퓨터에게 찾도록 시킨다면?

컴퓨터에게 완벽한 w1, w2를 찾도록 시킨다!
이때, 완벽한 w1, w2를 정하는 기준을 알려줘야한다.
이것은 실제 데이터를 제공해줌으로서 ✨총오차가 가장 적어지는✨ 경우의 w1, w2를 찾도록 하면 된다.
이때, 총오차를 계산하기 위한 방법은 다양하다.
딥러닝 모델?
딥러닝 모델을 시각적으로 나타내면 다음과 같다.
perceptron을 여러 개 연결해서, 중간에 layer을 만들자.
딥러닝은 여러개의 layer가 모여 Neural Network가 형성된 모습이다.
이걸 거쳐서 결과를 예측하도록 하는 것이 바로 딥러닝이다.

3강
- 동그라미 : 하나의 node라고 말하고, 노드가 합친건 layer라고 한다.
- node는 그냥 숫자로 표현된다.
- perceptron (인공 신경망)
새로운 노드와 연결된 노드들을 모두 더한다. 이때, 가중치 w값을 곱해서 더해준다!
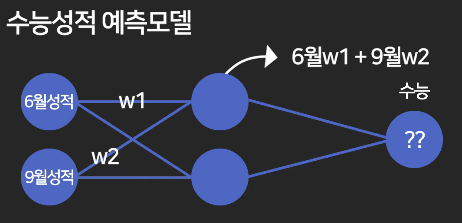
- w값은 아직 알 수 없다. w값은 컴퓨터가 알아내도록 디자인해야한다.
- 노드가 많아지면 w1..w2..w3... 이런식으로 많아진다.
- 계산된 node는 h1(hidden node)로 표현한다.
최종적으로 수능 성적은 어떻게 구할까?

이렇게 다 곱해서 구하면 된다.
그리고 컴퓨터(머신 러닝)한테 오차를 최소화하는 w값을 찾으라고 명령한다.
- 이때, 오차라는게 뭔지, 오차를 어떻게 계산하는지도 모델에게 알려줘야한다.
오차는 실제 데이터를 가지고 예측값을 비교하면 된다.
총 오차 구하기
아래와 같이 오차의 합을 구한다.

하지만? 오차가 마이너스 값으로 나올 수 있다. 이로인해 오차값이 줄어드는 현상이 생길 수 있다.
이를 방지하기 위해 절댓값을 취하거나,
평균 제곱 오차를 구하기도 함 (오차^2 한 것을 다 더하고, 평균을 낸다)
Loss Fuction (손실 함수)
이 모델의 정확도 구하는 함수, 오차를 구하는 수식

- y^ : 우리 모델이 예측한 예측값
- y : 실제 값

위 수식은 텐서플로우 쓰면 파이썬 한줄로 구할 수 있다.
- 배운거 1. 히든 레이어가 있을 때 예측 결과 계산하는 법
- 배운거 2. 내 모델이 정확한지 오차 계산하는 법 (Loss Function)
4강
문제 : 히든 레이어가 있나 없나, 결과는 똑같다는 문제 !!
활성함수(active function)
중간 레이어에 활성 함수를 적용해서 문제 해결

- 제일 유명한 활성함수는 sigmoid 함수
: 양수는 0에서 1 사이 값, 음수는 0에 가까운 값으로 변환
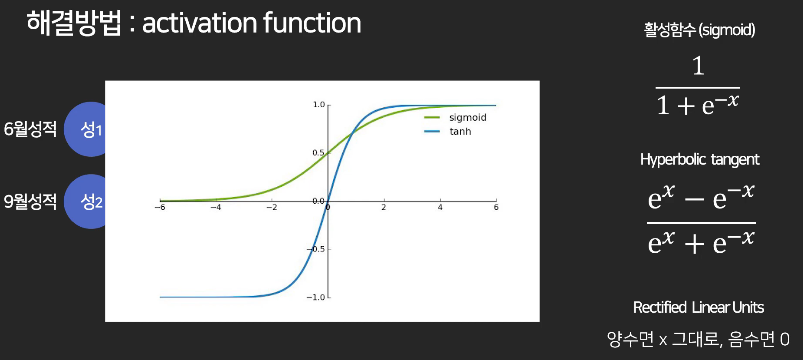
- 좀 더 극단적으로 변환하는 버전
: 양수 값은 그대로 출력, 음수는 다 0으로 바꿈

함수 중 아무거나 적용하면 된다. 이를 통해 레이어가 의미가 있어지는 것
활성 함수 쓰는 이유
비선형적인 예측을 하기 위함이다
activation func으로 non-linearity 부여하기

선을 딱 그었을 때는 선형적인 예측만 가능하다.
구부러진 선으로 예측하면? 더 특이한 케이스도 예측 가능하다.

다양한 케이스에 적용 가능한 모델을 구현하려면 activation func이 필요하다
- But 출력층 (맨 마지막 레이어)에는 활성함수가 반드시 쓰이는 것은 아니다.
5강
총손실 E를 최소화하는 w를 찾는 원리


우리는 최적의 w를 찾아야 한다.
처음엔 랜덤으로 w1값을 찍어서 구한다. 여기서 w1에서의 총손실 값도 구할 수 있다.
이후 시도에서는 약간씩 조정해서 구한다.
w1 하나면 2차원 그래프 그려서 판단 가능한데,
w값이 수백개면 그래프를 통해 구할 수가 없다.
그래서 w1을 최적값으로 변경하기 위해 경사하강법을 쓴다.
현재 w1값에서의 접선의 기울기를 w1에서 뺀다.

"머신에게 러닝을 시킨다"
= 손실을 최소화하는 w값을 찾게 시킨다
= 그 방법은 경사하강법이다.
딥러닝의 학습 과정
- w값을 랜덤으로 찍음
- 그 값을 바탕으로 총손실 E 계산
- 경사하강으로 새로운 w값 업데이트
- .. 총손실 E가 더이상 안줄어 들때 까지 반복한다.
코드로 변환하면 아래와 같다.

문제 상황
경사하강법을 쓰는데, 실제 최저점을 못찾는 현상이 발생할 수 있다.


해결책
기울기만 빼지 말고, (learning rate X 기울기) 를 빼면 된다.
상수인 알파 (learning rate)
- learning rate에는 정답이 없음. 실험적인 값이다.
- 일명 trial and error
- 고정된 값만 주면, 복잡한 문제의 경우 학습이 안일어나는 경우도 있다
해결책
학습이 일어날 때 마다 알아서 learning rate을 가변적으로 변경되게 하면 된다.
이를 통해 최저점을 빠르게 찾을 수 있게 한다.
이런 알고리즘이 여러개 존재한다. (ex. 아래 사진 참고)

6강
cmd에서 텐서플로우 다운받기
pip install tensorflow
1. 기본 텐서 만들기
Tensor 자료형

import tensorflow as tf
텐서 = tf.constant([3,4,5]) # 텐서 자료형 (그냥 숫자, 리스트 등등,, 담을 수 있다.)
print(텐서)
# 인풋이 3개라고 가정하자.
# 행렬로 노드를 계산하면 된다.
# 텐서가 필요한 이유 : 행렬 계산을 하기 위함
# - 행렬로 인풋/w 값 저장 가능
# - 그럼 node 값 계산식이 쉬워짐!
텐서1 = tf.constant([3,4,5])
텐서2 = tf.constant([6,7,8])
print(텐서1 + 텐서2) #결과 : tf.Tensor([ 9 11 13], shape=(3,), dtype=int32)
# 텐서로 행렬 표현하기, 다음 행렬을 텐서로 표현
# 1 2
# 3 4
텐서3 = tf.constant([[1,2],[3,4]])
# 여러가지 함수 : .add / .subtract / .divide / .multiply / .matmul() = 행렬의 곱, 일명 dot product
print(tf.add(텐서1, 텐서2)) # 더하기 함수도 있음
텐서4 = tf.zeros(10) # 0이 10개 들어있는 텐서 생성
print(텐서4)
텐서5 = tf.zeros([2,2]) # 0으로 가득 찬 2행 2열의 텐서
print(텐서5)
텐서6 = tf.zeros([2,2,3]) # 0이 3개인, 2행, 2개
print(텐서6) # 이것을 텐서의 shape, 모양이라고 한다
print(텐서6.shape) # 텐서의 모양 / 몇 차원의 데이터인지
# 텐서의 datatype
# 정수 넣으면 int, 실수면 float라고 나옴 (맨 뒤에 dtype 같이 나옴)
# tf.cast() # 자료형 바꾸는 함수
# weight 저장하고 싶다면 variable 만들기
# w는 계속 업데이트 되므로 변수임, 초깃값 지정 가능!
w = tf.Variable(1.0) # 변수(=weight 값) 선언
# numpy로 변수를 불러올 수 있음
print(w.numpy())
# 변수 변경
w.assign(2)
print(w)7강
신발 사이즈를 통해 키 예측하는 모델
코드
import tensorflow as tf
키 = [170,18,175,160]
신발 = [260,270,265,255]
# 그래프 구하기 y = ax + b
# 문제 : 키로 신발사이즈를 추론해보자
# 신발 = 키 * a + b 임의로 식 세워보자 (가설)
# a와 b를 정의한다.
a = tf.Variable(0.1)
b = tf.Variable(0.2)
def 손실함수():
# 손실값 : 실제 값 - 예측값
return tf.square(260- (170 * a + b)) # 손실값(오차)를 제곱
# 경사 하강법 사용
opt = tf.keras.optimizers.Adam(learning_rate=0.1) #변수 업데이트 자동으로 해줌, gradient를 알아서 스마트하게 바꿔줌
# 경사 하강 실행, 두가지 인풋 필요
# 한번 실행 됨
opt.minimize(손실함수, var_list=[a,b]) # 업데이트 할 w 목록
# 여러번 실행
for i in range(300):
opt.minimize(손실함수, var_list=[a,b])
print(a.numpy(),b.numpy()) # 학습 통해 알아낸 a, b 값8강
대학 합격 예측 모델 만들기
# 1. 데이터 파일 열기
import pandas as pd # 파이썬으로 엑셀 데이터 다루고 싶을 때 판다스 쓴다
data = pd.read_csv('gpascore.csv') #파일 읽어옴
# 2. 데이터 전처리하기
# 데이터 중 빵꾸난거 : 빈부분에 평균값 넣거나, 아님 행 자체를 지우거나!
print(data.isnull().sum()) # 빈칸 몇개인지 알 수 있음
data = data.dropna() # 빈 행 자체를 없애줌
# data = data.fillna(100) # 빈칸 특정 값으로 채워줌
#data['gpa'].min() # 열만 출력 가능, 그 중 최소값 구할 수 있음
# .max() 최대값 / .count() 개수 출력 가능
y = data['admit'].values # 리스트 형태로 담음
x = []
for i,rows in data.iterrows(): #iterrow -> dataframe을 가로 한줄 씩 출력해준다.
# i 행 번호
# rows: i번째 행의 데이터
x.append([rows['gre'],rows['gpa'],rows['rank']])
# 3. 딥러닝 모델 디자인
import tensorflow as tf
# Sequential 쓰면 신경망 레이어 모델을 쉽게 만들 수 있다
model = tf.keras.models.Sequential([
# 레이어를 나열한다.
# 인자1 : 노드의 개수 (보통 2의 제곱수)
# 인자2 : 활성함수
tf.keras.layers.Dense(64,activation='tanh'),
tf.keras.layers.Dense(124, activation='tanh'),
# 마지막 출력 레이어
# sigmoid :모든 값을 0~1 사이로 압축해준다. 확률 구할 때 사용
tf.keras.layers.Dense(1, activation='sigmoid'),
])
# 4. 모델 compile하기
# optimizer가 learning rate를 상황에 따라 알맞게 조정해준다.
# loss 함수 = binary_crossentropy : 결과가 0과 1사이의 분류, 확률 문제일 때 가장 많이 쓴다
model.compile(optimizer='adam', loss='binary_crossentropy',metrics=['accuracy'])
# 5. 모델 학습 시키기
# x = training 데이터 ex) [[380,3.21,3],[380,3.21,3],[380,3.21,3] ]
# y = 정답 데이터 ex) [0,1,0,1,0]
# epochs : 몇 번 학습시킬것인가
import numpy as np # 다차원 리스트, 행렬 만들때 사용
# 파이썬 리스트 그대로 넣으면 안됨.
# numpy array 또는 tf tensor로 넣어야 가능
model.fit(np.array(x), np.array(y), epochs = 1000) # 1000번 학습시키기
# 6. 예측
# 다음과 같은 두가지 case에서 합격할 확률 예측하기
predict = model.predict([[750,3.70,3],[400,2.2,1]])
print(predict) # 합격 확률 