
01 : 머신러닝 개념 및 정의
- 인공지능 > 머신러닝 > 딥러닝
E(경험)을 통해 작업 T(일)의 P(성능)을 높임
학습 종류
1) 지도 학습
- 분류 : class레이블 중 하나를 선택 / 옳바른 정답이 있는 경우(레이블)
이진 분류 or 다중 분류 - 회귀 : (예측 변수를 사용해서) 연속적 답 예측하기
ex. 주가예측, 가격이라는 정답
2) 비지도 학습 : 군집 / 시각화
-
인풋에 옳바른 정답이 없는 데이터가 주어지는 경우!
-
비슷한 것 끼리 하나의 class로 묶는 군집)
-
ex) 구글 뉴스들을 비슷한 뉴스를 하나의 클러스터로 묶음
3) 준지도 : 지도 + 비지도
4) 강화학습 : 그냥 먼저 해보고 결과를 판단하기
- 알파고, 게임 등에 사용
- 옳바른 행동을 할 때 마다 보상을 해서, 바른 행동을 할 수 있도록 그 행동을 강화
머신 러닝 vs 프로그래밍
일반화
일반화 : training 데이터와 input 데이터가 달라도 똑같은 성능으로 출력하기 위한 목적
일반화가 안됐을 경우의 문제
1) 과대적합 (딥러닝에서 중요) : training에선 잘 됐는데, 새로운 input 데이터에서 정확성이 떨어질 때
2) 과소적합 : 너무 단순해서 input의 복잡한 점은 구별 못함
02 : 머신 러닝 용어 및 라이브러리
-
모델이란 : 머신러닝 시스템 ex) 스팸 메일을 분리해내는 시스템
-
특성 : 데이터를 설명하는 입력 변수 ex) 개 고양이 분류 : 눈, 귀 모양 등
-
레이블 : 예측하는 실제 항목 ex) 개냐 고양이냐
-
추론 : 학습된 모델을 사용해 새로운 데이터에 적용해 예측하는 것
-
Numpy 라이브러리 (파이썬)
행렬 관련해서 많이 쓰임
코랩(구글 무료 코드 편집기) -
Pandas : 머신러닝 라이브러리 중 젤 많이 씀
-
Matplotlib : 시각화에 좋은 라이브러리
-
Scikit - learn : 지도/비지도학습에서 모델 만들 때 씀
-
NLTK 라이브러리 : 자연어처리 모델 만들 때 사용, 토큰화 할 때 사용
03 : 선형 회귀

- 선형 회귀 (지도 학습, 레이블 존재)
H(x) = Wx + b
W 기울기, b 절편
H : 가설 (이 그래프가 데이터를 가장 잘 대변하는 그래프일 것이다. 라는 가설)

- MSE : 잔차의 제곱을 구하기. 답과의 오차를 제곱한 것을 다 더함, 이후 평균을 구한다 (데이터와의 오차가 어떤 값은 음수고, 어떤 값은 양수일 것이므로)
-
cost(w) 비용함수 = 얼마나 잘 맞는가?를 나타냄
-
선형 회귀분석 목적 : MSE를 통해 가장 적합한 h와 b 찾기
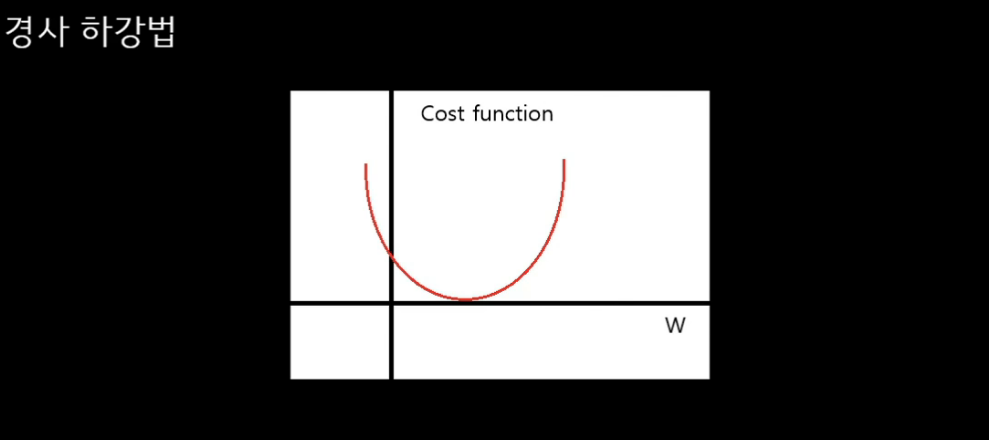
- 경사하강법 : 비용 함수 값이 가장 작을 때를 찾는 것
임의로 w를 정함. w을 편미분하면 접선의 기울기가 나옴
접선의 기울기가 0일 때, 최적의 w값이 된다.

- 러닝레이트(알파 값) = 보폭
- 러닝레이트가 너무 크면 : 왔다갔다 할 수 있음, 최적의 점을 지나치게 되어 최적점을 찾기 힘들다.
- 러닝레이트가 너무 작으면 : 오래걸림

- 경사 하강법의 단점 : 최적점을 한번에 못 찾을 수 있다.
(로컬 미니멈 vs 글로벌 미니멈)
04 : 다중 선형 회귀

이전에는 y 값에 영향을 미치는 값인 x가 하나였다.
이제는 y값에 영향을 미치는 값이 여러 개라고 생각해보자.
1) 전진선택법
상수 모형으로부터 시작하여 중요하다고 여겨지는 설명 변수부터 차례대로 모델에 추가
2) 후진제거법
가장 덜 영향을 준다고 생각하는 변수를 전체에서 1개씩 제거해 나감
05 : 선형 회귀 모델 구현
- Google Colaboratory (코랩 colab)
- GPU 사용 : 런타임 유형 선택
중간 쯤 부터 선형회귀코드(x값이 하나인)
키와 수학 점수 사이의 상관관계
06 : 로지스틱 회귀 모델
-
선형 회귀 분석이란 : 회귀식에서 mse를 통해 가장 적합한 w와 b 값을 찾는 것
-
로지스틱 회귀 분석이란 : 반응 변수가 1 또는 0인 이진형 변수에서 쓰이는 회귀분석 방법

왼쪽은 로지스틱 회귀 분석(네모와 다이아를 구분짓는 그래프 구하기) , 오른쪽은 선형 회귀 분석 (앞으로의 네모 값이 어떻게 변할 것 인가 예측)

p : 확률, 0 또는 1 값을 가짐
양 변이 범위가 다르다는 문제 생김

odds : 성공 확률 나누기 실패확률 = p / (1-p)

- p 범위가 0~1이므로, odds의 범위는 0~무한대
- odds는 로그함수의 도메인에 적합
- 좌변, 우변 둘 다 범위가 마이너스 무한대 ~ 플러스 무한대


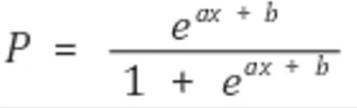
- 결론 : 위와 같이 정리할 수 있다.

- 그래프로 나타내면 위와 같다
- 이것이 바로 로지스틱 회귀 함수의 그래프
07 : 로지스틱 회귀 모델 구현
08 : 의사 결정 나무


- 가지 치기 종류 : 사전 가지치기 / 사후 가지치기 -> 오버피팅 방지
- 사전 가지치기 : 트리 생성을 일찍 중단시킴
- 사후 가지치기 : 트리 생성 뒤, 데이터 포인터가 적은 노드를 삭제하거나 병합
- 특성 중요도 : 트리를 만드는 결정에 각 특성이 얼마나 중요한지를 의미
-> 높은 중요도의 특성일수록 높은 노드에 위치

09 : 의사 결정 나무 구현
10 : 랜덤 포레스트
앙상블 (Ensemble) : 여러 머신러닝 모델을 연결하여 더 강력한 모델을 만드는 기법
- 배깅 : 가중치를 이용해 약분류기를 강분류기로 만든다.
- 부스팅 : 샘플 여러번 뽑아서 학습 시키고 결과물 집계. 처음 모델이 예측 >> 가중치 부여 됨 >> 다음 모델에 영향 줌

랜덤 포레스트 : 여러 결정 트리의 묶음
랜덤하게 만드는 방법 2가지?
- 데이터 포인트를 랜덤하게 선택
- 분기 특성을 무작위로 선택
- Max feature : 크면 트리들이 비슷해짐, 작으면 트리들이 많이 달라짐
11 : 랜덤 포레스트 구현
12 : KNN

- 위 그림에서 파란 점은 빨간 점에 이웃하는가? 분홍 점에 이웃하는가?
- 게으른 모델 : 별도 모델 작업 없이 각각의 관측치를 사용해 분류 및 회귀 작업을 시행함
K 정하기 : 최근접을 몇 개까지로 볼 것인가?
- 맨해튼 거리
- 장점 : 학습 데이터 내에 노이즈 값의 영향을 잘 안받는다
13 : KNN 구현
14 : 데이터 나누기
그동안은 라이브러리 안에 있는 데이터를 나눠서 사용했음.
Train과 Test 데이터로 나눠서 썼다.

train 데이터 > 학습 시킬 때 사용. 모델을 만들 때
- 머신러닝 : Train / Test
- 딥러닝 : Training / Validation(잘 학습되고 있는지 확인할 때) / Test

교차검증 : 테스트 데이터가 너무 적을 때
- K-Fold : 데이터를 K개로 나누고, 검증 데이터화 훈련 데이터로 나눈다. k번 반복한 성능의 평균을 구한다. > 내가 가진 데이터를 100% 테스트 데이터로 사용 가능

정밀도 Precision = a / a+c
- 모델이 True라고 구한 값 중에 진짜로 True인 것의 비율
재현율 = a / a+b
- 모델이 잘 예측한 True 값의 비율
정확도 Accuracy = a+d / a+b+c+d
- 전체 중 잘 예측한 값의 비율
F1 Score = 정밀도와 재현율의 조화 평균
- 2 x (정밀도 X 재현율) / (정밀도 + 재현율)
- 정밀도와 재현율이 어느 한쪽으로 치우치치 않을 때 높게 나옴
15 : 데이터 전처리
그동안 사용했던 데이터들은 예쁘게 잘 처리되어 있는 데이터였다.
결측치 처리
- 평균값 넣기
- 최빈값 넣기
- 또는 그냥 버리기
df.isnull().sum() 결측치 총 개수 세기
df.fillna(0) 0으로 채우기
범주형 변수 처리
- 원-핫 인코딩 : 범주형 변수를 0 또는 1 값을 가지는 새로운 feature로 변경
from sklearn.preprocessing import OneHotEncoder
- 데이터 바인딩 : 연속된 데이터를 구간으로 나눠 범주화
Feature Scaling
- 모델에 있어 데이터 feature를 맞춤. 데이터가 너무 크거나 작으면 영향을 미칠 수 없음.
- Min-Max Nomalization : 최소값과 최대값의 범위에서 0과 1 사이의 데이터로 표준화 시키는 것
from sklearn.prepocessing import minmaxscale()
- Standardization : 표준화 확률 변수를 구하고, z-score를 구하는 방법
16 : 최종 실습 - 타이타닉1
- 예측 모델 및 분석 대회 플랫폼
- 방대한 데이터 셋을 제공함
