Programmers 인공지능 데브코스
1.Programmers 인공지능 데브코스 - Week 1 Day 1

첫날. OT 이후 간단한 아이스브레이킹 시간을 가지고, 본격적인 실습 및 수업에 시작하게 되었다.자료구조 & 알고리즘에 대한 복습이 첫날의 대부분.Programmers에서 항상 풀어왔던 알고리즘 웹 IDE 페이지 + 동영상 강의의 형태로 수강하였다.아무래도 첫날이다보니
2.Programmers 인공지능 데브코스 - Week 1 Day 2

둘째날, 첫째날에 이어서 자료구조 알고리즘 강의 수강.Programmers에 존재하는 어서와 자료구조 알고리즘은 처음이지? 강의를 듣는다. 상당한 난이도의 자료구조는 아니기 때문에, 적당히 복습도 되는 느낌이고 쉽게 풀이할 수 있었다. 다만 조금 귀찮다
3.Programmers 인공지능 데브코스 - Week 1 Day 3

셋째날은 Hash, sorting, greedy 알고리즘에 대해 복습했다.누군가에겐 처음 듣는 알고리즘일수 있지만, 일단 CS전공이라면 보통 알고있는 알고리즘이다.적어도 한번쯤은 들어봤을만한?쨌든, 강사님이 주신 풀이는 꽤나 좋은 접근법에, 좋은 풀이여서 아주 만족스러
4.Programmers 인공지능 데브코스 - Week 1 Day 4

1주차 - Day4넷째날, Heap, DP, DFS/BFS 에 대한 복습을 했다.아직은 첫주여서 이지한 내용들로 다루고 있는중.매운 것을 좋아하는 Leo는 모든 음식의 스코빌 지수를 K 이상으로 만들고 싶습니다. 모든 음식의 스코빌 지수를 K 이상으로 만들기 위해 Le
5.Programmers 인공지능 데브코스 - Week 1 Day 5-7

다섯째날, 코딩테스트 연습만 주구장창 하다가 집중력의 한계를 깨닫고 다른 공부를 조금 했다.Docker랑 Kubernetes에 대해 관심이 가고, 추후 Tensorflow 2.0과 함께 Kubeflow를 사용할 예정이다.문제가 꽤 많아서 약 30문제? 풀다 지치고 풀다
6.Programmers 인공지능 데브코스 - Week 2 Day 1
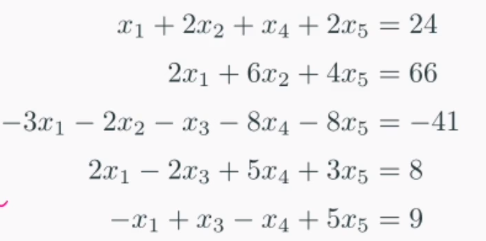
중학교 때 배운 소거법으로 위의 연립일차방정식을 간단히 해결할 수 있습니다. 이것을 정형화한 것이 Gauss 소거법입니다. Gauss 소거법에 대한 내용은 추후에 다룹니다.위의 연립일차방정식 또한 우리가 가지고 있는 지식 안에서 쉽게 해결할 수 있습니다.하지만 식이 1
7.Programmers 인공지능 데브코스 - Week 2 Day 2

인수분해는 어떤 경우에 쓸모가 있나요?결과적으로 수를 두 수의 곱으로 변환하는 것이 여러모로 응용이 되는데, 이를 행렬에 적용한 것이 행렬분해의 의미입니다.주어진 행렬을 행렬분해 한 상태로 가지고 있자는 것이 행렬분해입니다. 이렇게 한다면 계산이 굉장히 편해질 경우가
8.Programmers 인공지능 데브코스 - Week 2 Day 3

두 벡터 u,v 간의 내적이 0이면 두 벡터는 직교 (orthogonal) 입니다.두 벡터 u, a가 있을 때, 벡터 u를 a 위에 투영한 벡터를 projau라 하고 다음과 같이 구합니다.proj (ection) a (위에) u (를 떨궜다) 라는 뜻입니다.투영된(프로
9.Programmers 인공지능 데브코스 - Week 2 Day 4

😃[2주차 - Day4]😃 확률 고전적 정의 - 표본공간, 사건, 어떤 사건이 일어날 확률 표본공간 = 모든 가능한 실험 결과들의 집합 사건 = 관심있는 실험결과들의 집합, 표본 공간이 부분집합 어떤 사건이 일어날 확률 = 사건의 원소의 수 / 표본공간의 원소
10.Programmers 인공지능 데브코스 - Week 2 Day 5

표본 조사는 반드시 오차가 발생합니다.표본조사를 할 때 표본과 모집단과의 관계를 이해해야 합니다.표본 추출 방법은 단순랜덤추출법, 난수표 사용, 랜덤넘버 생성기 사용을 하는 방법이 있습니다.표본조사를 통해 파악하고자 하는 정보는 모수입니다.모수의 종류는 모평균, 모분산
11.Programmers 인공지능 데브코스 - Week 3 Day 1

😃[3주차 - Day1]😃 Git 사용법 https://medium.com/webeveloper/%EA%B9%83%ED%97%88%EB%B8%8C-%EC%82%AC%EC%9A%A9%EB%B0%A9%EB%B2%95-github-tutorials-4a63f31bb6
12.Programmers 인공지능 데브코스 - Week 3 Day 2

😃[3주차 - Day2]😃 Pandas COVID KAGGLE 데이터 사용하여 아래의 실습 진행합니다. Github Week3에 가시면 커밋로그를 확인하실 수 있습니다.
13.Programmers 인공지능 데브코스 - Week 3 Day 3

데이터를 보기좋게 표현해봅시다.크기 : figsize제목 : title라벨 : \_label눈금 : \_tics범례 : legend꺾은선 그래프 (Plot)산점도 (Scatter Plot)박스그림 (Box Plot)막대그래프 (Bar Chart)원형그래프 (Pie Ch
14.Programmers 인공지능 데브코스 - Week 3 Day 4

탐색적 데이터 분석을 통해 데이터를 통달해봅시다. with Titanic Data라이브러리 준비분석의 목적과 변수 확인데이터 전체적으로 살펴보기데이터의 개별 속성 파악하기Hint : Fare? Sibsp? Parch?함께 보면 좋은 라이브러리 documentnumpyp
15.Programmers 인공지능 데브코스 - Week 4 Day 1

RESTful Api를 구성하기?Representational state transfer이는 어떠한 하나의 방법론이며, 요즘 가장 흔하고 유명한 방법입니다.GraphGL이 무섭게 치고올라오고 있는중.HTTP URI : 웹 상에서 정보를 요청할 때 대상의 위치에 대한 식
16.Programmers 인공지능 데브코스 - Week 4 Day 2

프라이빗 클라우드퍼블릭 클라우드하이브리드 클라우드퍼블릭의 경제성과 프라이빗의 보안성을 모두 고려함.IaaSPaaSSaaS클라우드 서비스가 제공 방식에 따라 3가지 형태로 구분됩니다.SaaS는 소프트웨어까지 전부 제공받아서 사용하는 형태입니다. (MS365와 비슷한 형태
17.Programmers 인공지능 데브코스 - Week 4 Day 3,4

Python 기반 웹 프레임워크 ( pinterest, instagram이 Django 사용! )플라스크의 경우 “마이크로” 웹 프레임워크입니다. 최소한의 기능을 갖고 있으며 살을 붙여가면서 빌드업을 하는 구조입니다.반면 장고의 경우, 이미 거의 모든 것이 내장되어있는
18.Programmers 인공지능 데브코스 - Week 5 Day 1 - 확률이론

경험을 통해 자동으로 개선하는 컴퓨터 알고리즘의 연구!학습데이터 : 입력벡터들 x1, ... , xN, 목표값들 t1, ... , tN머신러닝 알고리즘의 결과는 목표값를 예측하는 함수 y(x)를 구하는 것입니다.학습단계 : 함수 y(x)를 학습데이터에 기반해 결정하는
19.Programmers 인공지능 데브코스 - Week 5 Day 2 - 결정이론
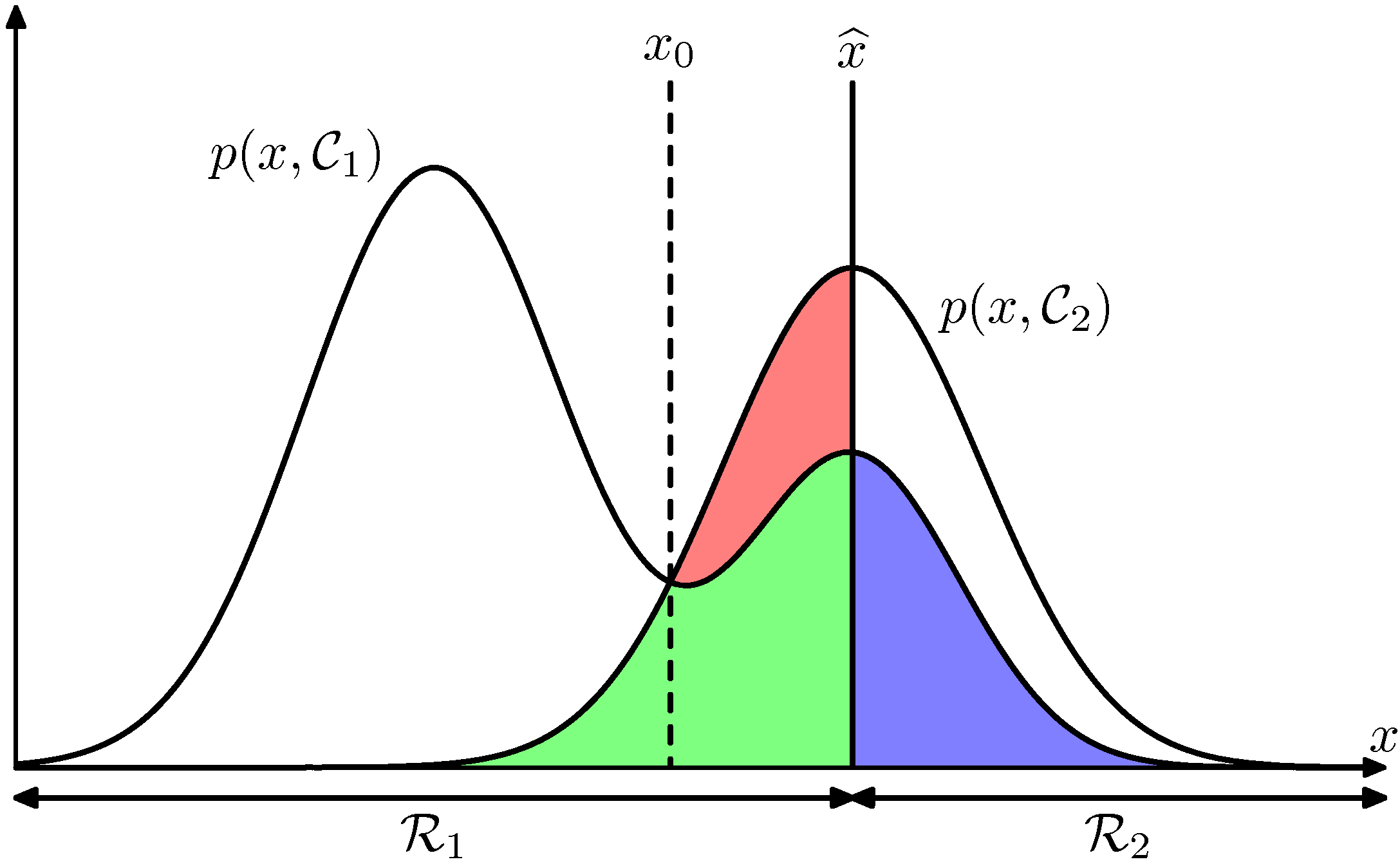
😃[5주차 - Day2]😃 결정이론 새로운 값 x가 주어졌을 때 확률모델 p(x,t)에 기반해 최적의 결정을 내리는 것! 직관적으로, 조건부확률을 최대화시키는 k를 찾는 것이 가장 좋은 결정인 것으로 보입니다. 결정영역은 클래스 i에 속하는 모든 x의 집합을
20.Programmers 인공지능 데브코스 - Week 5 Day 3 - E2E Project

부동산 회사에 막 고용된 데이터 과학자라고 가정하고 예제 프로젝트를 진행하는 과정을 살펴봅니다.지도학습(supervised learning), 비지도학습(unsupervised learning), 강화학습(reinforcement learning) 중에 어떤 경우에 해
21.Programmers 인공지능 데브코스 - Week 5 Day 4 - Linear Algebra

😃[5주차 - Day4]😃
22.Programmers 인공지능 데브코스 - Week 5 Day 5 - Probability

😃[5주차 - Day5]😃
23.Programmers 인공지능 데브코스 - Week 6 - Probability Distributions

정보이론에서 엔트로피를 최대화시키는 확률분포가 가우시안 분포이고, 중심극한정리에서도 가우시안 분포가 일어납니다.동일한 확률변수 N개가 있을 때 이것들의 평균이, N이 커질수록 가우시안 분포에 가까워진다는 정리가 중심극한정리입니다.
24.Programmers 인공지능 데브코스 - Week 7 Day 1 - Deep Learning

초창기 - 지식기반 방식이 주류가 되는 학습이었습니다.하지만 이 방식에는 한계가 있고, 모든 규칙을 나열하기란 불가능합니다.이러한 한계를 깨닫고, 기계학습으로의 전환이 시작되었습니다.인공지능의 주도권이 지식기반에서 기계학습, 심층 학습 순서로 발전되어 왔습니다. 이는
25.Programmers 인공지능 데브코스 - Week 7 Day 2 - Deep Learning

수학은 목적함수를 정의하고, 목적함수의 최저점을 찾아주는 최적화 이론을 제공합니다. 우리가 만든 가설 = 모델이라고 하는 것의 매개변수를 찾는 과정이며, 이 과정을 최적화 이론에 기반하고 있습니다.텐서나 벡터로 결과값을 유추해내는 과정이 선형대수를 배우는 이유주어진 데
26.Programmers 인공지능 데브코스 - Week 7 Day 3 - 퍼셉트론

확률론적 신경망 - 고유의 임의성을 가지고 매개변수와 조건이 같더라도 다른 출력을 가지는 신경망입니다.우리가 보는 신경망은 대부분 결정론적 신경망입니다.퍼셉트론을 어떻게 배치할지에 대해서 다양한 신경망의 구조가 존재합니다.인간의 신경망을 모방한게 인공신경망이고, 뉴런을
27.Programmers 인공지능 데브코스 - Week 7 Day 3 - PyTorch 및 Tensorflow 실습

Tensor는 NumPy의 ndarray와 유사합니다.초기화되지 않은 5x3 행렬을 생성합니다 : 무작위로 초기화된 행렬을 생성합니다:dtype이 long이고 0과 1으로 채워진 행렬을 생성합니다:데이터로부터 직접 tensor를 생성할 때는:새로운 double타입의 x
28.Programmers 인공지능 데브코스 - Week 7 Day 4 - 다층 퍼셉트론

XOR 문제 같은 경우 선형분리가 불가능하고, 75% 정확도의 한계가 존재합니다.이를 다층 퍼셉트론으로 구축시킨다면 이를 해결할 수 있을 것입니다.하나의 퍼셉트론이 가진 한계를 서로 연결하면서 그 사이에서 새로운 의미를 찾아가는 과정을 수행하게 되었습니다.복수개의 퍼셉
29.Programmers 인공지능 데브코스 - Week 7 Day 5 - 심층학습, CNN

A
30.Programmers 인공지능 데브코스 - Week 8 Day 1 - CNN

CNN에 관한 간단한 설명
31.Programmers 인공지능 데브코스 - Week 8 Day 2 - CNN
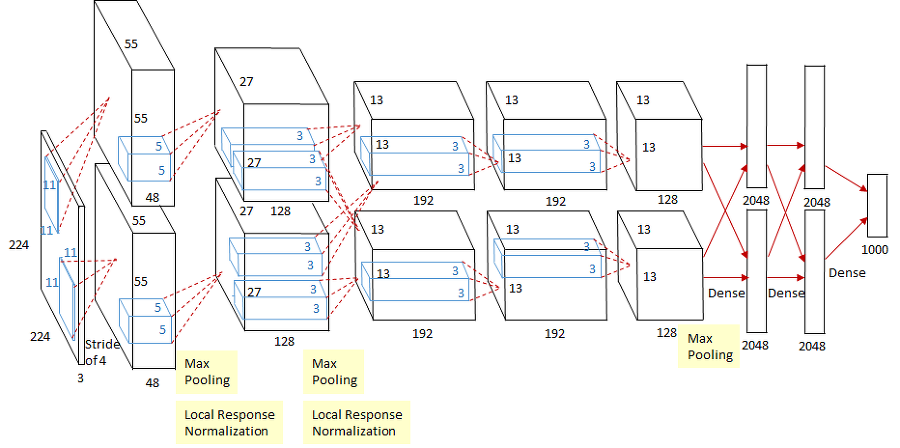
CNN, 생성모델에 대한 간단한 설명
32.Programmers 인공지능 데브코스 - Week 8 Day 3 - CNN Models
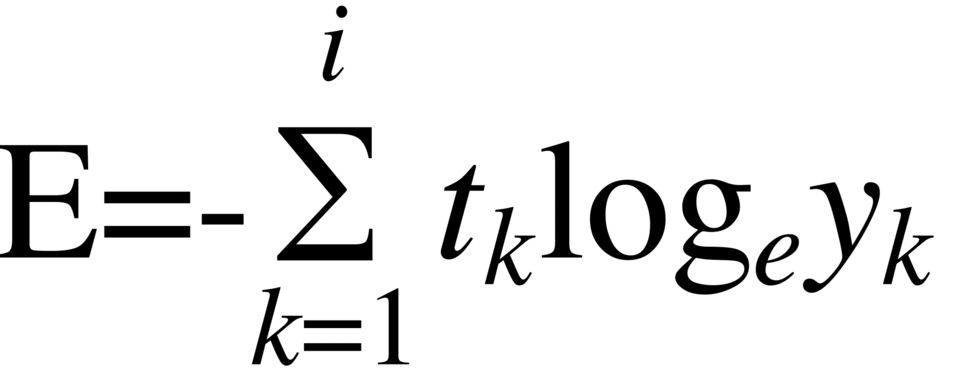
기계학습 최적화에서 중요한 점은 일반화 능력이 좋아야 합니다.예측값 - 실제값 = 오차오차를 계산할 때, 어떤 것들을 판단 기준으로 삼느냐에 따라 gradient descent를 이용해 갱신해줄텐데요. 로스나 에러를 어떻게 정해주느냐에 따라 다른 양상을 보일 수 있습니
33.Programmers 인공지능 데브코스 - Week 8 Day 4 - DeepLearning 최적화

활성함수와 규제에 관한 내용
34.Programmers 인공지능 데브코스 - Week 8 Day 5 - RNN
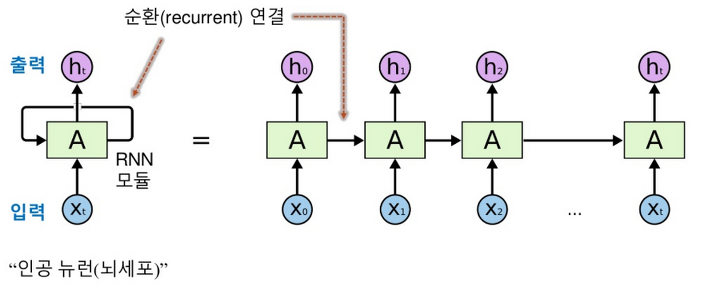
입력층 은닉층 출력층을 가지는 깊은 신경망과 유사합니다.다른 점은 은닉층이 순환 연결(recurrent edge)를 가진다는 점입니다.앞에서 들어왔던 정보들을 재활용 할 수 있는 방법입니다.U, W, V의 매개변수를 공유하기 때문에 추정할 매개변수의 수가 획기적으로 줄
35.Programmers 인공지능 데브코스 - Week 9 - 빅데이터, 하둡, 스파크

데이터 엔지니어는 데이터 웨어하우스를 만들고, 내부나 외부 데이터를 적재한다. 데이터 엔지니어가 ETL, 데이터 파이프라인을 구현한다. ETL이란 ETL(Extract, Transform, Load) - 데이터를 가져다가 데이터 웨어하우스에 로드하는 작업을 말한다.
36.Programmers 인공지능 데브코스 - Week 10 - 자연어 처리, 임베딩

자연어의 의미를 컴퓨터로 분석해서 특정 작업에 사용할 수 있도록 만드는 것 기계번역, 감성분석, 문서분류, 질의응답시스템, 챗봇, 언어생성, 음성인식, 추천시스템에 사용된다. 딥러닝은 컴퓨터 비전 분야에 CNN이 쓰이면서 발전하기 시작했다. 또한 반대로도 마찬가지로
37.Programmers 인공지능 데브코스 - Week 11 - Faster RCNN, YOLO, GAN

region proposal에 피쳐 맵이 들어간 뒤 pooling layer를 지나치며 224 -> 112 -> 56 -> 28 -> 14 -> 7으로 7 by 7의 형태로 바뀜 region proposal에는 3 by 3 convolution을 수행함
38.Programmers 인공지능 데브코스 - Week 12 - 추천 엔진, 협업 필터링, 오토인코더

사용자가 관심있어 할만한 아이템을 제공해주는 자동화된 시스템비즈니스 장기적인 목표를 개선하기 위해 사용자에게 알맞은 아이템을 자동으로 보여주는 시스템추천 엔진을 기반으로 이메일 마케팅, 신상품 마케팅, 관련 상품 추천 등의 개인화가 이루어짐추천 엔진의 예시 : 아마존