자연어 처리
자연어의 의미를 컴퓨터로 분석해서 특정 작업에 사용할 수 있도록 만드는 것
기계번역, 감성분석, 문서분류, 질의응답시스템, 챗봇, 언어생성, 음성인식, 추천시스템에 사용된다.
딥러닝은 컴퓨터 비전 분야에 CNN이 쓰이면서 발전하기 시작했다. 또한 반대로도 마찬가지로 사용되고 있다.
단어와 말뭉치(Corpus)
문장부호(, ? !)가 문장의 의미에 영향을 주는 경우 유의미한 단어일 수 있다.
구어체 문장의 경우, fragments, filed pauses를 단어에 포함시키는 경우가 좋다
표제어(lemma)
여러 단어들이 공유하는 뿌리 단어, e.g. cat/cats/cats'/cat's 의 경우 cat이라는 표제어를 공유
말뭉치
하나의 말뭉치는 일반적으로 대용량 문서들의 집합
언어, 방언, 장르 (뉴스, 소설), 글쓴이의 인구통계적 특성 (나이, 성별)에 영향을 받음
텍스트 정규화 (Normalization)
모든 NLP는 텍스트 정규화가 필요하다
- 토큰화 (Tokeninzing Words)
- 단어 정규화 (Normalizing word formats)
- 문장 분절화 (Segmenting sentences)
토큰화
문서가 주어졌을 때 단어들의 시퀀스로 표현하는 것
중국어 같이 띄어쓰기가 없는 경우 token화가 어렵다
한국어의 경우 token화가 복잡하다 -> subword 단위로 토큰화를 한다
Subword Tokenization
만약 학습데이터에서 보지 못했던 새로운 단어가 나타났을 때의 대처 방법을 생각
-> 학습 데이터: low, new, newer -> 테스트데이터: lower
-> -er, -est 등과 같은 형태소를 분리할 수 있으면 좋을 것이다
Byte-Pair Encoding(BPE)
-
Vocabulary를 단일 문자들의 집합으로 초기화
-
말뭉치에서 연속적으로 가장 많이 발생하는 두개의 기호들 (Vocabulary내 원소들)을 찾는다.
-
두개의 기호를 병합하고, 새기호로 Vocabulary에 추가한다.
-
말뭉치에서 그 두 기호를 병합된 기호로 대체한다.
위 과정을 k번의 병합이 일어날 때까지 반복한다
기호병합은 단어안에서만 이루어진다. 이것을 위해서 단어끝을 나타내는 특수기호 _를 단어 뒤에 추가한다
Wordpiece
기호들의 쌍을 찾을 때 빈도수 대신에 likelihood를 최대화시키는 쌍을 찾는다
BPE에 비해 확률적인 부분이 추가되었지만 완전히 확률적인 모델은 아니다
Unigram
확률모델(언어모델)을 사용한다
학습 데이터 내의 문장을 관측(observed) 확률변수로 정의한다
주변 우도(marginal likelihood)를 최대화시키는 tokenization을 구한다.
-> EM(expectation maximization)을 사용
단어정규화 (Word Normalization)
단어들을 정규화된 형식으로 표현하는 것을 의미
e.g. uhhuh or uh-huh
검색엔진에서 문서들을 추출할 때 유용할 수 있다
Case folding
모든 문자들을 소문자화하여 표현하는 것을 의미
감성분석 등의 문서분류 문제에서는 오히려 대소문자 구분이 유용할 수 있다
(국가이름 “US” vs 대명사 “us”)
최근의 경향
단어 정규화를 aggressive하게 하지 않는다
단어임베딩을 사용해서 단어를 표현하게 되면 단어정규화의 필요성이 줄어듦
언어모델
문장이 일어날 확률을 구하는 것, 연속적인 단어들에 확률을 부여하는 모델
P(W) = P(w1,w2, ... , wn)
Chain Rule을 사용해서 결합확률을 계산하면 이 P(W)를 구할 수 있다.
그치만 문제는 가능한 문장의 개수가 너무 많고 이것을 계산할 수 있는 충분한 양의 데이터를 가지지 못함
Markov Assumption
한 단어의 확률은 그 단어 앞에 나타나는 몇 개의 단어들에만 의존한다 라는 가정으로 이 문제를 해결
이를 위한 모델들이
- Unigram
- Bigram
- N-gram
라그랑주 방법을 사용해서 MLE(Maximum likelihood Estimation)를 최대화시킴
언어모델 평가
언어모델이 좋은지 판단하기 위해선 그 과제의 평가지표를 사용하는 경우가 많다
언어모델이 학습하는 확률 자체를 평가할 필요성도 있다
최적의 언어모델이 최종 과제를 위해서는 최적이 아닐 수도 있다
언어모델의 학습과정에 버그가 있었는지 확인하는 용도로만 쓰일 수 있다
좋은 모델은 테스트 데이터를 높은 확률로 예측하는 모델이다.
Perplexity를 최소화하는 것이 확률을 최대화
문서분류 (Text Classification)
텍스트를 입력으로 받아 텍스트가 어떤 종류의 범주에 속하는지를 판단하는 작업
e.g. 감성(리뷰) 분류, 이메일 스팸 분류 등등
문서 분류 방법
- 규칙 기반 모델
- Snorkel
- Machine Learning
단어들의 조합을 사용한 규칙들을 사용해서 분류할 단어가 존재하면 분류함
머신러닝 중에는 Naive bayes, logistic-regression, k-Nearest Neighbors 등의 모델이 있는다.
Naive Bayes 분류기
Naive Bayes 가정과 Bag of words 표현에 기반한 모델
Bag of words 표현은 단어의 순서를 고려하지 않은 단어들의 집합이며, 각 단어의 빈도수로 단어를 나타내는 것을 의미한다
적은 학습 데이터로도 충분히 좋은 성능을 보여주며 속도도 빠르다
조건부독립 가정이 실제 데이터에서 성립할 때 최적의 모델
단어 임베딩
단어는 어근(lemma)와 의미(sense)로 구성
동의어(synonyms)는 문맥상 같은 의미를 가지는 단어
유사성(similarity)는 동의어는 아니지만 유사한 의미를 가진 단어들을 의미
현대 머신러닝 방법들은 단어를 모두 다 벡터로 표현한다. 고로, 벡터를 사용해 분포적 유사성을 표현하고자 한다.
이렇게 벡터로 표현된 단어를 임베딩 (embedding)이라고 한다.
- 희소 벡터(sparse vector) : TF-IDF, Vector Propagation
- 밀집 벡터(dense vector) : Word2Vec, glove
TF-IDF
Term-document 행렬은 각 document별로 단어가 등장하는 횟수를 나타내는 행렬
빈도수는 높으나 의미 구별하는데 도움이 되지 않는 단어들의 영향력을 줄이기 위해 TF-IDF가 나옴
tf-idf는 정보검색에도 활용된다. tf-idf를 사용하여 도움이 되지 않는 단어들의 영향력을 줄일 수 있음
Word2Vec
더 작은 개수의 학습 파라미터와 테스트 데이터에 새로운 단어가 나와도 유연하며, 동의어/유사어를 더 잘 표현할 수 있는 것이 dense 벡터이다.
예측값이 아니라 가중치 벡터를 단어 임베딩으로 사용한다
Skip-gram
한 단어가 주어졌을때, 그 주변단어를 예측할 확률을 최대화 하는것이 목표
word2vec은 negative sampling을 사용하여 계산을 단순화
NLP 딥모델
- RNN(LSTM)
- TextCNN
- Transformer
- BERT(Transformer encoder)
- GPT(Transformer decoder)
Transformer는 병렬화가 가능하며, BERT, GPT의 기반이 된 모델이며 많은 모델들이 Transformer 모델에 기반을 둔다
오직 attention으로만 단어의 의미를 문맥에 맞게 잘 표현할 수 있다.
https://jalammar.github.io/illustrated-transformer - 정리가 잘 된 블로그
Self-Attention
각 단어의 임베딩이 Self-Attention의 인풋으로 들어가면서 다른 단어들과의 관계를 사용해서 단어의 의미가 좀더 정확해진다.
단어의 의미는 문맥에 따라 결정된다는 것이다 같은 단어라 할지라도 문맥에 의해서 뜻이 달라진다는 개념
즉 각각의 단어의 의미를 이해하는데 있어 주변의 문맥을 사용한다.

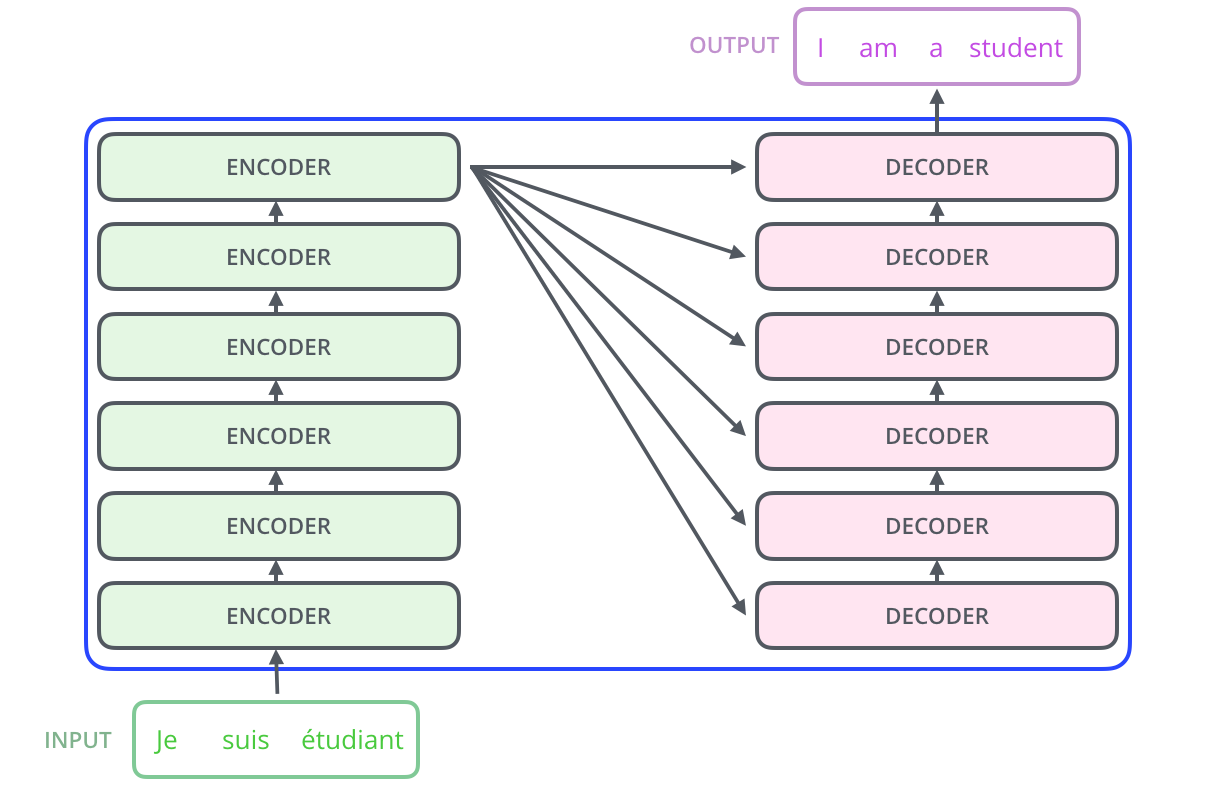
Encoder
동일한 구조를 가진 인코더들이 여러개가 쌓여 transformer를 만듬
하나의 인코더에서 나온 아웃풋의 다른 인코더의 인풋
제일 상단에 있는 인코더가 디코더 부분의 인자로 전달된다
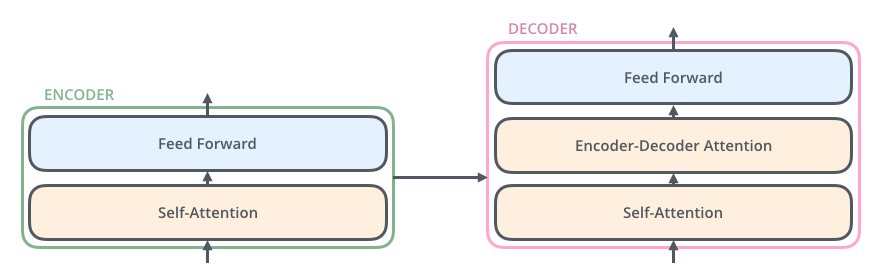
Decoder
입력 단어들의 시퀀스에 대해 번역 등의 출력을 해줌
디코더에서 출력된 임베딩 벡터를 가지고 하나의 출력값을 계산하는 것이 목표
에러 함수로 Cross-Entropy를 사용한다
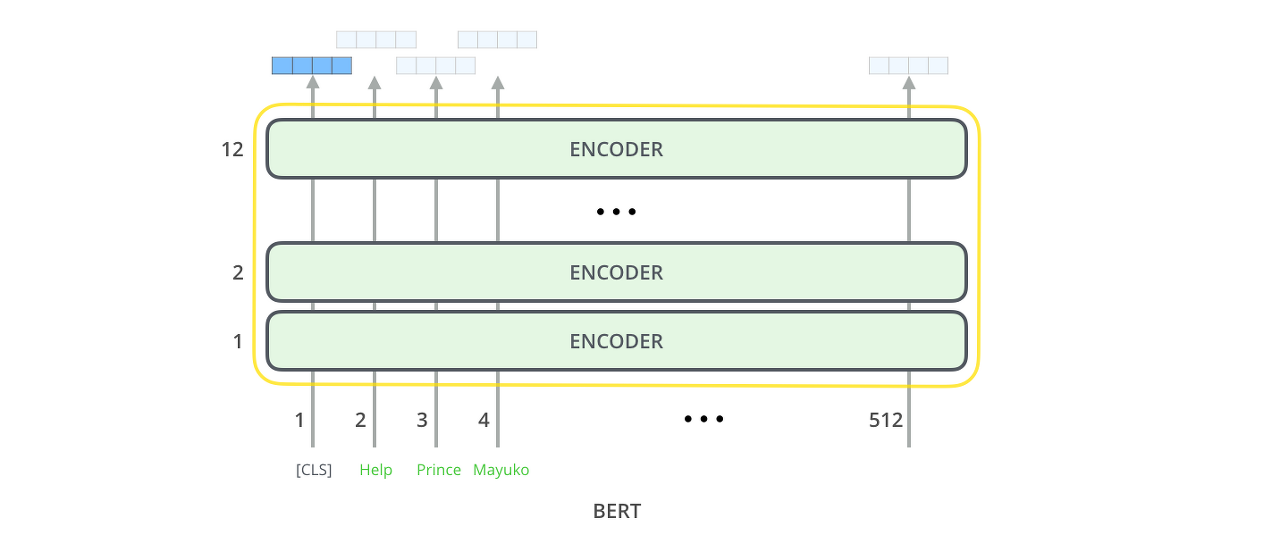
BERT
Transfer learning을 통해 적은 양의 데이터로도 양질의 모델을 학습하는 것
Transformer모델의 인코더 부분을 사용한다
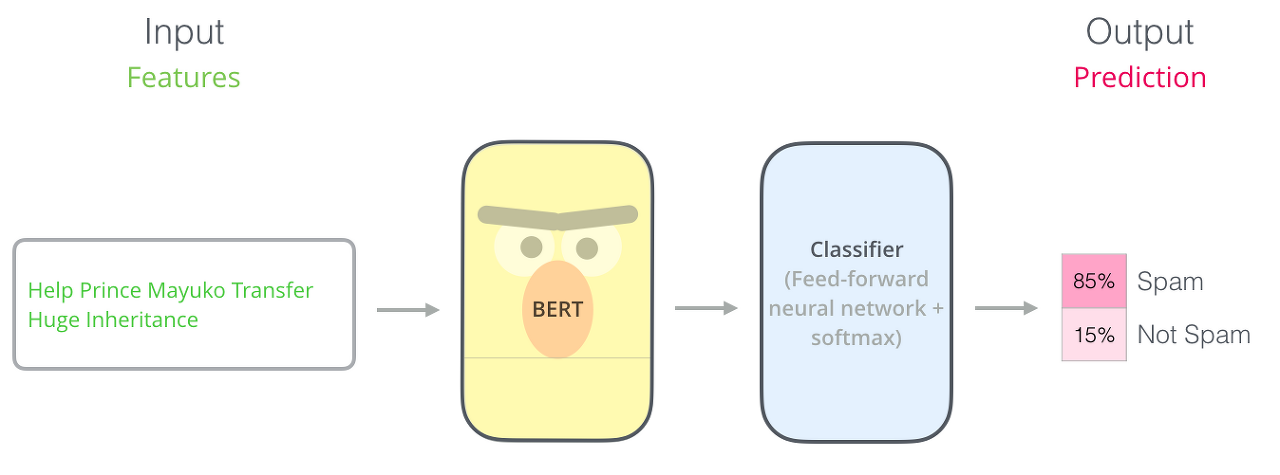
Masked language model - input의 여러 단어 중 랜덤하게 하나를 mask로 숨기고 BERT 모델의 출력을 통해서 가려진 단어를 예측하게 한다. 이 과정을 통해 모델 파라미터를 학습시킨다.