BoostCamp_NLP
1.부스트캠프 week6 day1

자연어처리NLU, NLG컴퓨터 비전 분야와 더불어 인공지능 개발이 활발하게 일어나는 분야이번 코스에서 다루게 될 것.자연어처리 주요 컨퍼런스(ACL, EMNLP, NAACL)low-level parsing : tokenizationstemming(한국어는 더 다양한 어
2.부스트캠프 week6 day1 추가학습

일반적으로, 단어를 Bag-of-Words로 표현하고 원핫 벡터로 표현하게 된다면 단어 간 유사도를 계산할 수 없다. 따라서, 단어 간 유사도를 계산하여 단어의 의미를 벡터화할 수 있는 방법으로 나온 것이 바로 Word2Vec이다.여기에서는 Word2Vec을 이용한 단
3.부스트캠프 week6 day2
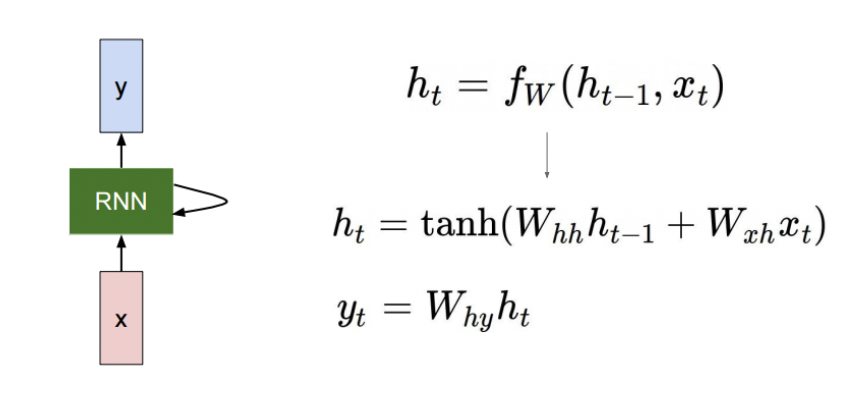
이전 시점의 hidden state와 현재 시점의 입력 데이터로 현재 시점의 출력 데이터를 만들어내는 순환적인 구조의 Neural Network이다. 매 타임 스텝에서 같은 W를 공유하는 것이 특징.How to calculate the hidden state of RN
4.부스트캠프 week6 day2 추가학습
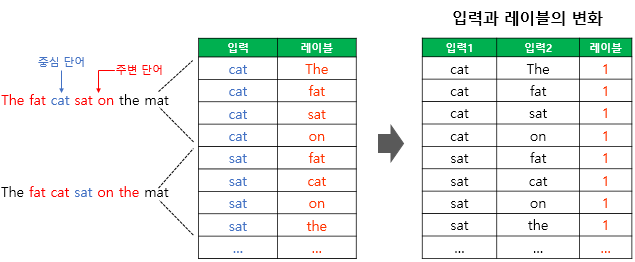
네거티브 샘플링글로브글로브2PackedSeqBidirectionalTeacher Forcing
5.부스트캠프 week6 day3
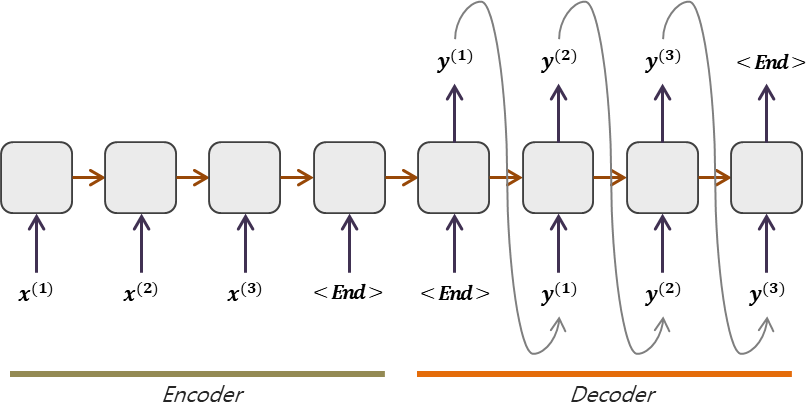
Many-to-Many RNN modelEncoder와 Decoder는 서로 Share하지 않는 모델들이다.Encoder의 마지막 셀에서 출력한 Hidden state는 decoder의 h0가 된다.Decoder에서 문장의 시작 입력데이터는 START, 또는 SOS라는
6.부스트캠프 week6 day4,5 RNN nn.module로 구현하기
피어세션 일정으로 4,5일 차 동안 RNN을 nn.module을 활용해 언어 모델을 구현하고, NSMC(Naver Sentiment Movie Corpus)를 활용한 Sentiment Classifier를 구현하기로 했다.그 전에, 언어 모델이라는 것이 구체적으로 무엇
7.부스트캠프 week6 추가학습

Mac에서는 다소 쉽게 설치가 가능하지만, window나 ubuntu에서는 Jdk를 설치해야하는 번거로움과 추가적인 설정이 필요해 불편함이 있다. 이를 해결하는 깃허브 설명하는 링크를 공유한다.Ubuntu 18.04 Mecab 설치이 코드에서 나온 여러가지 코드들을 리
8.부스트캠프 week7 day1 Transformer
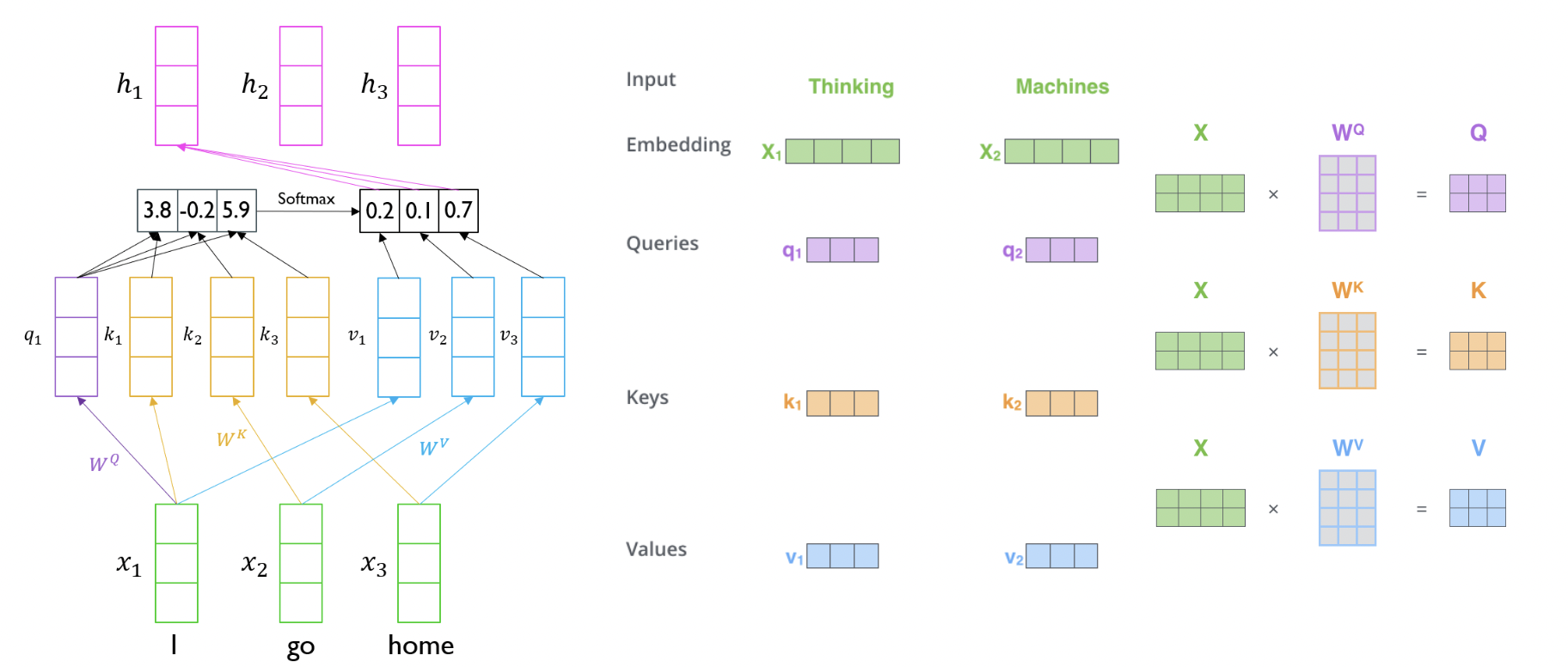
Bidirectional RNN에 대한 설명은 여기를 참조하자.이 방법을 쓰면서 사람들은 RNN이 가지고 있는 '한 방향으로만 정보를 습득한다'는 단점을 해소할 수 있게 되었다. 어떠한 타임 step에서 Forward와 Backward에서 나온 정보를 바탕으로 앞 뒤
9.부스트캠프 week7 day2 Self-supervised Pre-training Models

Recent Trends • Transformer model and its self-attention block has become a general-purpose sequence (or set) encoder and decoder in recent NLP applic
10.부스트캠프 week7 day2 추가학습 Perplexity, Softmax Loss, GPT1
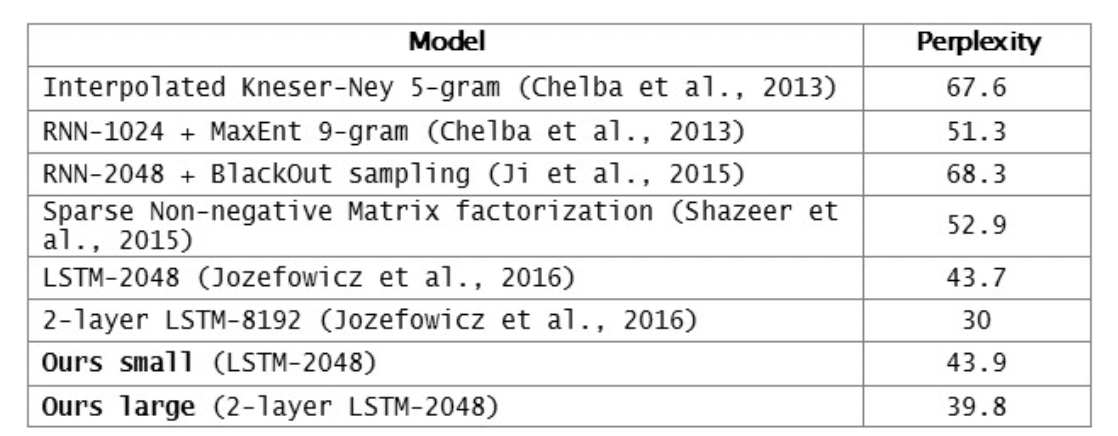
GPT의 학습 방법이나 이론적인 이해를 돕기 위해 추가적인 글을 올린다.이 영상이 많은 도움이 되었다.GPT는 대표적인 Generative 학습방법을 가지는 언어 모델이다. 보통 기계 학습 분야는 Generative, Discriminative 학습 방법을 가지며 보통
11.부스트캠프 week7 day3 LightConv/DynamicConv
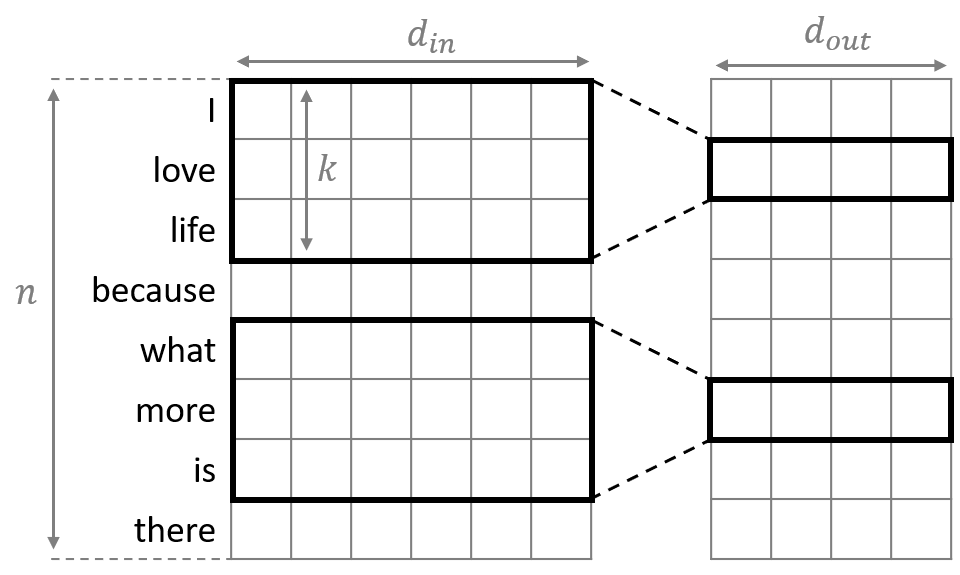
추가적으로 알아두어도 좋은 사항!kcBERT, KcBERT Github(with Colab)NSMC와 같은 댓글형 데이터셋은 정제되지 않았고 구어체 특징에 신조어가 많으며, 오탈자 등 공식적인 글쓰기에서 나타나지 않는 표현들이 빈번하게 등장한다.KcBERT는 위와 같은
12.부스트캠프 week7 day4 Huggingface Course Study

Huggingface Course
13.부스트캠프 week7 day4 Huggingface Course Study2
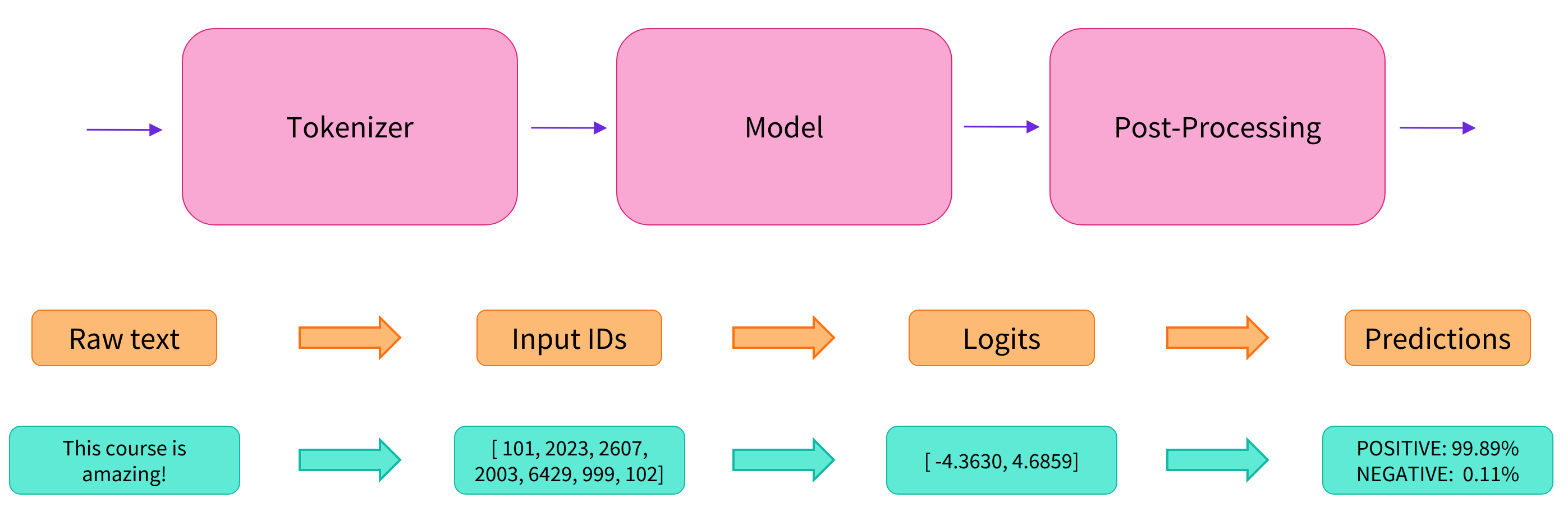
We'll learn about:How to use tokenizers and models to replicate the pipeline API’s behaviorHow to load and save models and tokenizersDifferent tokeniz
14.부스트캠프 week7 day5 Huggingface Finetuning