Self-Attention
Bidirectional RNN에 대한 설명은 여기를 참조하자.
이 방법을 쓰면서 사람들은 RNN이 가지고 있는 '한 방향으로만 정보를 습득한다'는 단점을 해소할 수 있게 되었다. 어떠한 타임 step에서 Forward와 Backward에서 나온 정보를 바탕으로 앞 뒤 단어 문맥을 고려해 다음 단어를 예측할 수 있게된 것이다.
하지만 여전히 RNN은 매 타임 스텝마다 계산을 하면서 긴 Sequence일 때 너무 긴 시간이 소요되고, 문맥 정보도 희석된다는 단점이 있었다. 이러한 단점을 해소하기 위해 Transformer에서 등장한 것이 바로 Self-Attention 개념이다.
Seq2Seq with Attention과의 가장 큰 차이 중 하나는 RNN이 없어졌다는 것이다. 기존의 Seq2Seq이 특정 타임 스텝의 Decoder Hidden State를 Encoder의 Hidden States와 연산을 하는 과정이었다면, 이제는 Encoder 자체에서 각 단어에 대해서 연산을 하는 과정으로 변하는 것이다.
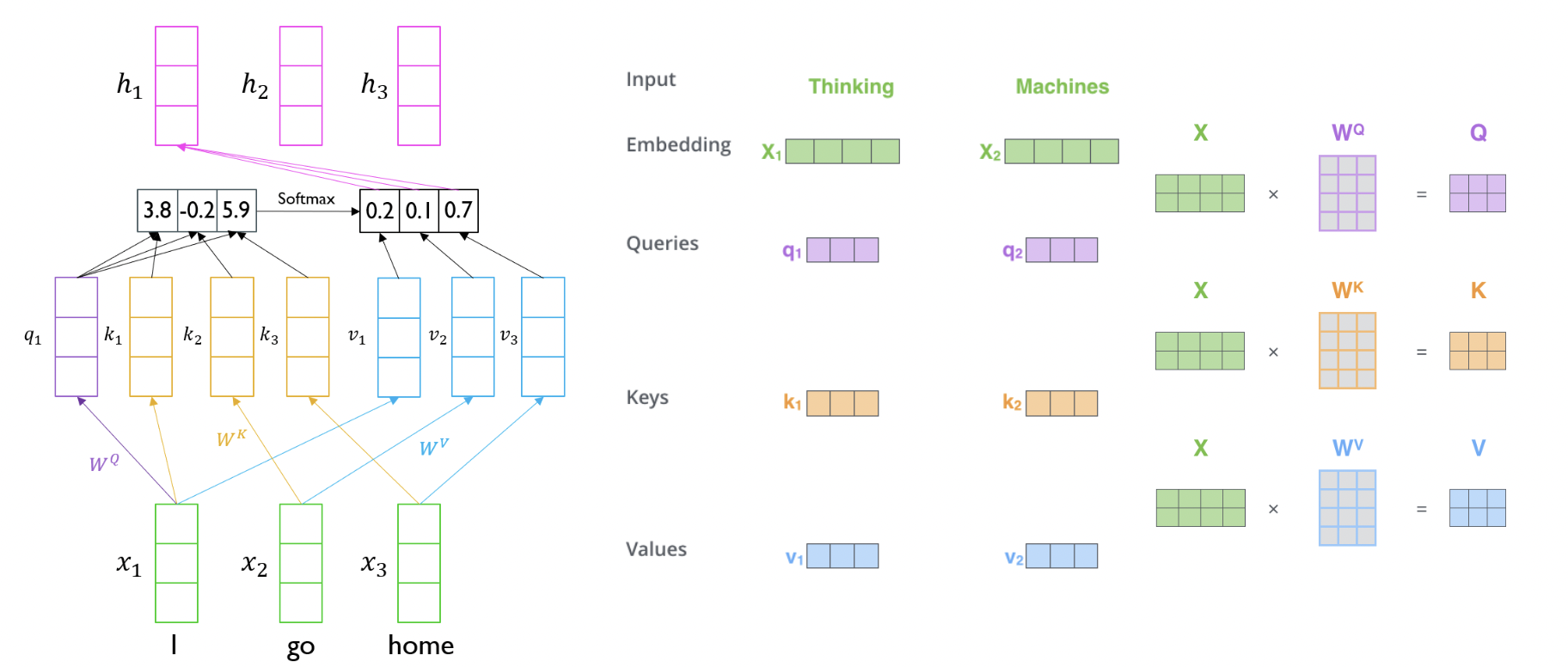
아래 사진이 Self Attention의 개념을 잘 보여준다.
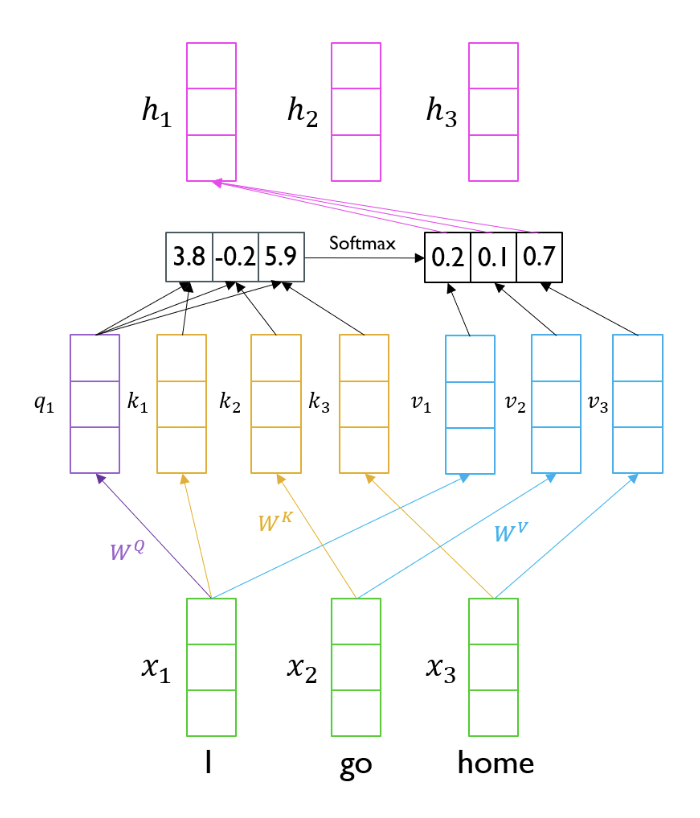
그런데 벡터 내적으로 생각하면 단어 자기 자신에 높은 유사도를 주게 되고 이는 크게 의미가 없어진다. 따라서 Query, Key, Value의 세 가지 형태로 Input을 바꿀 수 있다. Query는 현재 기준이 되는 단어, Key, value는 유사도 계산의 재료 벡터라고 생각할 수 있다. 따라서 같은 단어 벡터에서도 Q, K, V 세 가지 선형 변환을 주어 서로 다른 형태로 표현한다.
위의 계산을 행렬의 선형 변환이라고 생각하면 기존에 각 타임 스텝에 맞게 진행했던 Seq2Seq모델과 다르게 병렬처리를 할 수 있다.
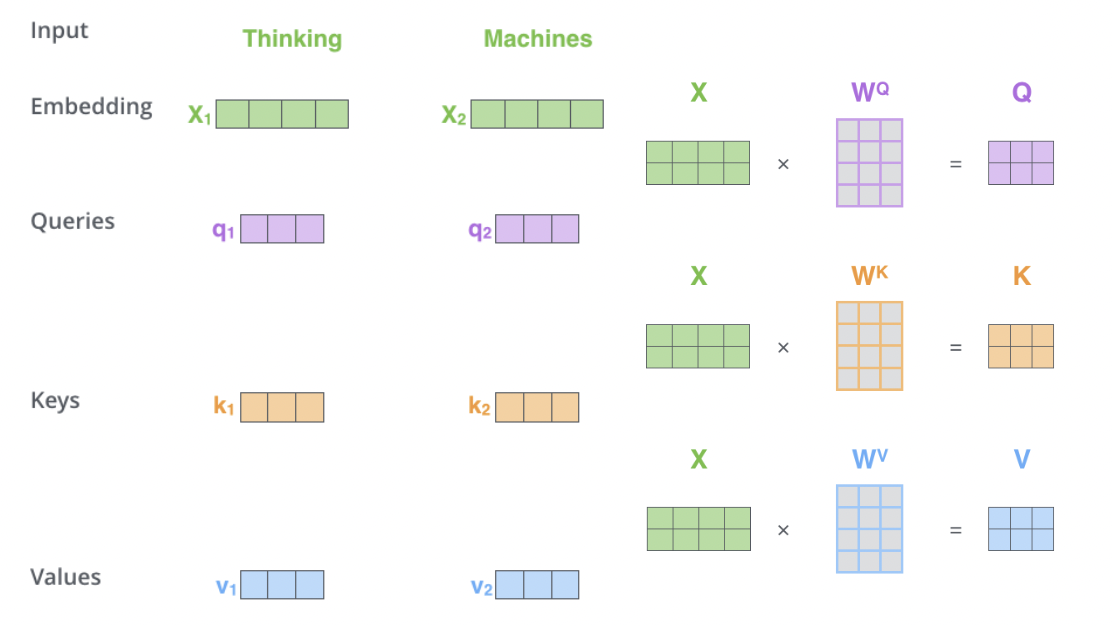
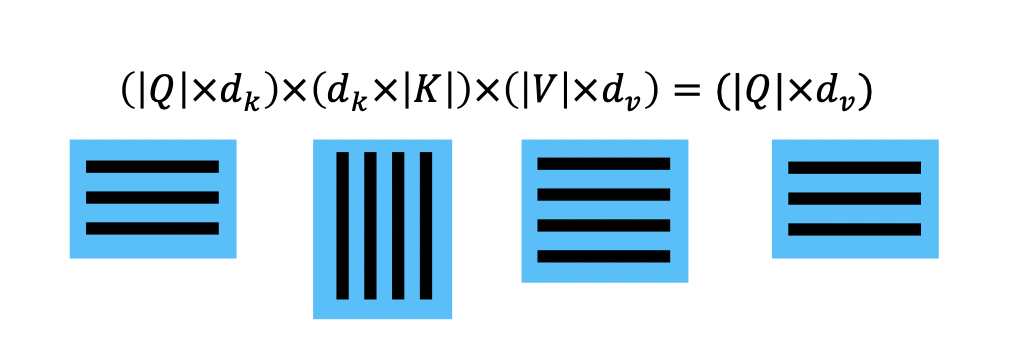
그리고 이는 타임 스텝이 먼 정보에 대해서도 적절하게 판단할 수 있어 Long-Term-Dependency의 문제를 완전히 해결했다고 볼 수 있다. 이를 수식으로 아래와 같이 나타낸다.
이 때, 는 Query와 Key의 차원이고, 내적 시 임의의 스칼라 곱을 해주는 것을 Scaled Dot-Product Attention이라 한다.
Scaled Dot Product를 쓰는 이유?
의 제곱근을 나눠주는 형태로 Transformer를 구해주는 이유를 통계적으로 알아보자.
Query와 Key는 의 차원을 가진 어떠한 벡터이다. 이 때 각 원소를 평균이 0, 분산이 1인 Guassian 분포라고 가정하자.이 때, Query와 Key의 내적 연산에서 총 번의 덧셈이 일어나기 때문에 내적 결과값의 분산이 만큼 커지는 것을 알 수 있다. 이는 Softmax를 취해야할 Attention Score가 너무 편차가 커져 한 쪽으로 몰리게 되는 결과를 낼 수 있다. 또한 이는 Backpropagation 연산 중 Gradient Vanishing의 문제가 발생할 수도 있다.
따라서 로 내적 결과를 나누어주면 분산을 1로 맞춰주게 되어 Softmax의 결과가 더욱 고르게 나타나고 학습을 적절하게 이루어질 수 있도록 만든다.
Multi Head Attention
기존에 하나의 Q,K,V 벡터들로 연산을 했다면, Transformer는 여러개의 QKV 변환 행렬을 가지는 MHA형태를 지닌다. 서로 다른 정보들을 병렬적으로 처리해서 상호 보완적으로 정보를 볼 수 있게 된다는 장점이 있다.
복잡도
주요 변수들은 다음과 같다.
𝑛 is the sequence length
𝑑 is the dimension of representation
𝑘 is the kernel size of convolutions
𝑟 is the size of the neighborhood in restricted self-attention
Complexity per Layer에 해당하는 연산은 이다.
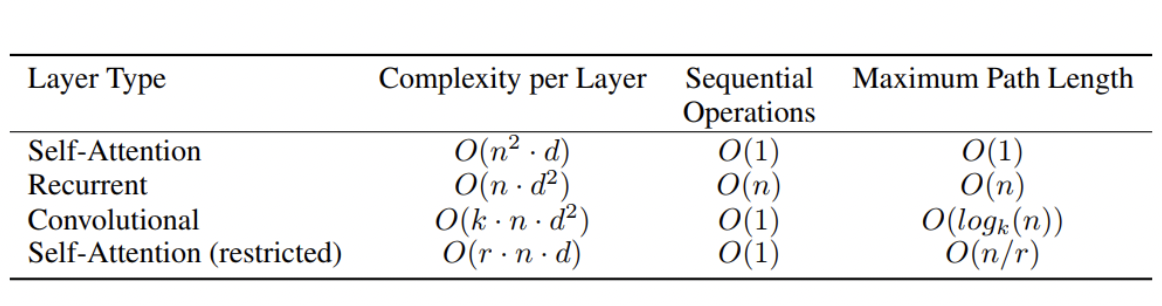
위의 표처럼, Self-Attention의 경우 RNN보다 많은 메모리 계산을 필요로하지만 실제 걸리는 시간은 RNN보다 짧다. 병렬 처리의 이점이라고 할 수 있다. 또한, Maximum Path Length에서 보듯이 RNN에서는 최대 n의 길이만큼의 time step을 거쳐야하지만, Self-Attention은 바로 인접한 단어라고 봐도 무방한 형태의 연산을 통해 훨씬 효율적인 계산을 진행할 수 있다.
Residual Connection
CV계열의 ResNet에서 고안된 Residual Connection은 Transformer에서도 MHA의 결과물에 대해서 동일한 작업을 수행한다. 입력값과 MHA를 통해 나온 결과값을 더해서 최종 결과값으로 출력하게되며, 이 때 MHA는 입력 데이터에 대해 자기 자신과의 차이에 대한 값을 계산하는 형태로 학습하게 된다. 이 과정을 통해 Gradient Vanishing 문제를 해결하고 학습을 안정화시킬 수 있다.
Layer Normalization
딥러닝에서는 다양한 Normalization 방법이 있다. 그 중에서 Transformer는 Layer Normalization을 적용했다.
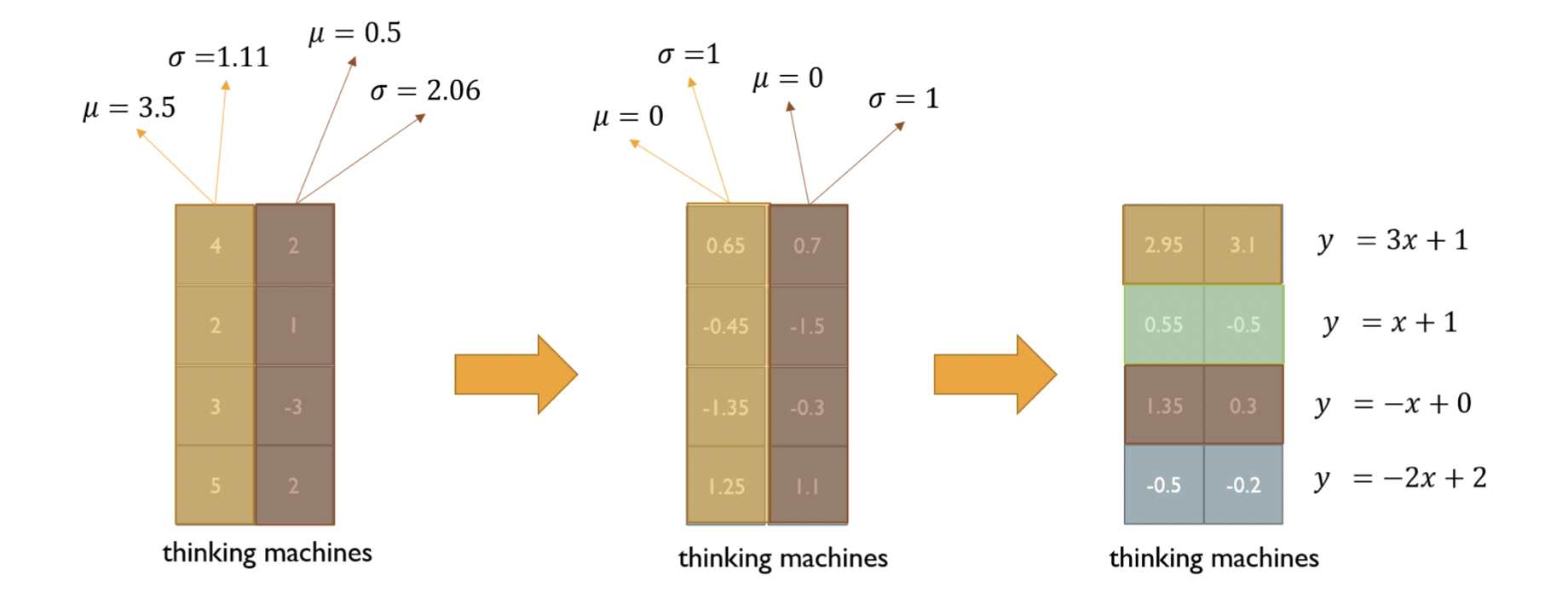
첫 번째 변환은 단어 기준으로 진행된다. 단어의 벡터들을 평균과 분산이 각각 0, 1의 정규분포로 만들어주게 된다. 두 번째 변환은 각 층에 대해서 진행하는 Affine Transformation이다. 일련의 선형 변환을 통해 앞서 Normalize한 데이터를 x로 넣게 되면, 에서 해당 데이터는 평균이 , 분산이 인 분포로 변환시킬 수 있다.
Positional Encoding
Transformer의 Self-Attention개념에서 Q,K,V는 순서와 상관없이 계산하게 된다. 즉, Sequence정보를 담고 있는 것이 아니기 때문에 이런 문제를 해결할 수 있도록 Positional Encoding을 도입했다.
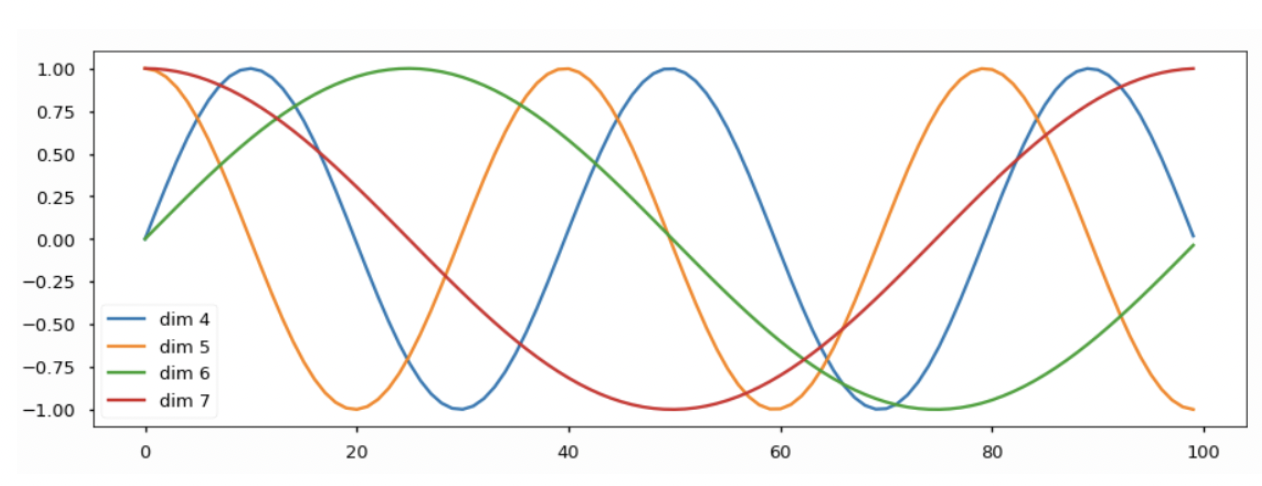
원리는 간단하다. 문장의 위치에 따라 순서를 특정할 수 있는 적절한 position 벡터를 더해주는 것이다. 원리는 그렇지만 실제 계산 시에는 간단하게 하는 것은 아니다. 각 단어에 해당하는 PE는 Sin, Cos 함수를 번갈아 사용하며, 해당하는 함수의 주기또한 계속 변하게 된다.
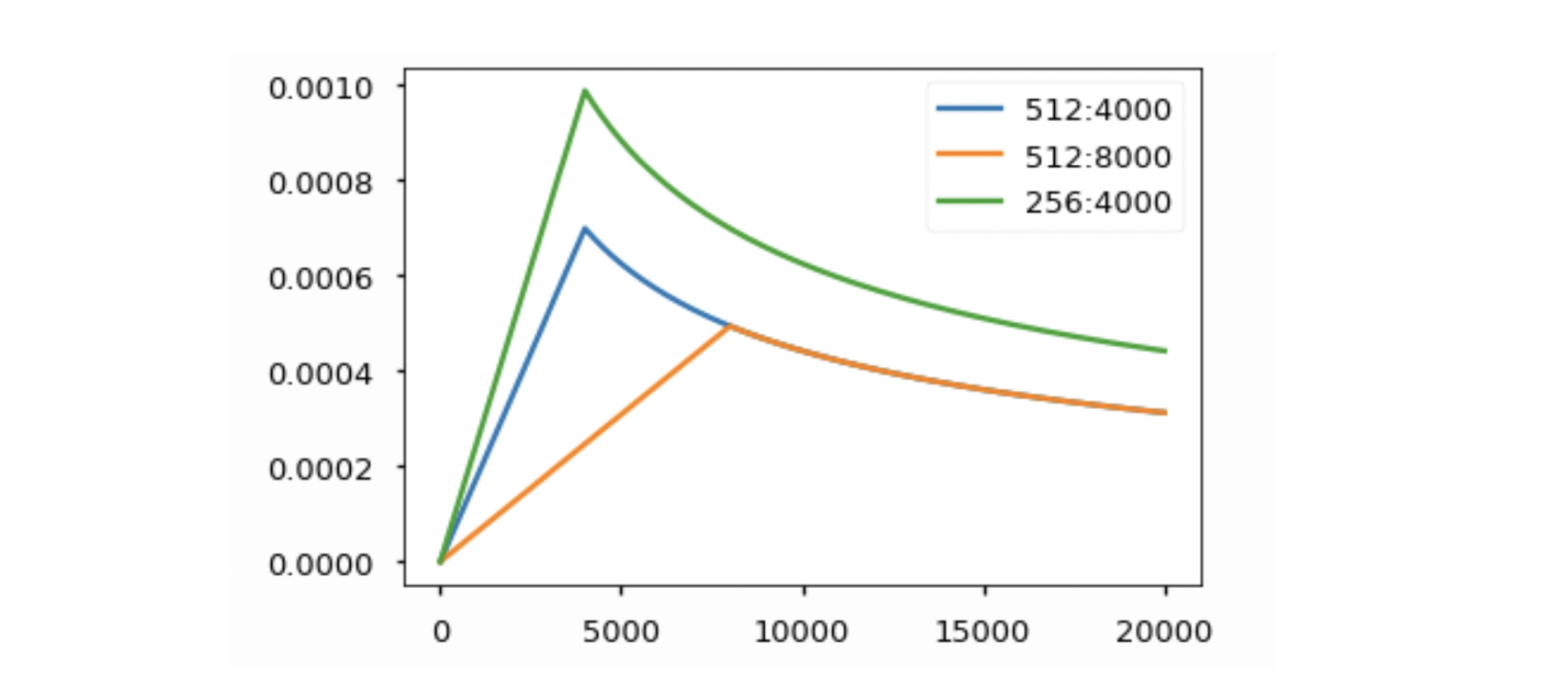
Learning rate Scheduler
Iteration이 진행됨에 따라 Optimal Minimum of objective function에 다가갈 수 있도록 처음에는 LR을 늘려주다가 어느 시점부터는 LR을 서서히 낮춰주는 형식이다.
Decoder
기존 Seq2Seq의 과정과 비슷하게 Input과 Output을 가지고 학습을 하게 된다. 하지만 달라지는 점은 MHA에서 Masked 설정을 해준다는 것과 두 번쨰 MHA과정에서 Encoder의 Key, Value를 활용해 Decoder의 Query와 Attention을 계산한다는 것이다. 후자는 Seq2Seq에서 Decoder의 매 Hidden States에 Encoder의 Hidden States들과 연산하는 과정과 닮아있다.
Masked Self Attention
Decoder는 구조상 Encoder와 달리 앞의 단어 정보만 가지고 뒤의 단어를 예측하는 형태로 만들어져야한다. 따라서 Decoder의 Attention 계산 시 뒤에 나오는 단어의 Key, Value 정보를 받지 않도록 0으로 만들어주는 것이다. 자세히 말하면, 계산 시에는 전체 단어를 기준으로 Attention을 계산하나 최종 출력물에서 현재 단어보다 뒤에 나오는 단어의 정보를 0으로 만들어 준다.
F.Q.
Attention은 이름 그대로 어떤 단어의 정보를 얼마나 가져올 지 알려주는 직관적인 방법처럼 보인다. Attention을 모델의 Output을 설명하는 데에 활용할 수 있을까?
참고: Attention is not explanation
참고: Attention is not not explanation
