후기
수업과정을 진행해 나가기는 하는데 속도도 많이 더디고 능률이 낮은것 같다 고민이다. 파이썬과는 다른느낌으로 생각해야할 것들이 많은데 큰일이다..
python 반복문
for문 사용법

Pandas에 잘 맞춰진 반복문용 명령 iterrows()
- Pandas 데이터 프레임은 대부분 2차원
- 이럴 때 for문을 사용하면, n번째라는 지정을 반복해서 가독률이 떨어짐
- Pandas 데이터 프레임으로 반복문을 만들때 itterows() 옵션을 사용하면 편함
- 받을때, 인덱스와 내용으로 나누어 받는 것만 주의
6. Goole Maps를 이용한 데이터 정리
map 정보 불러오기
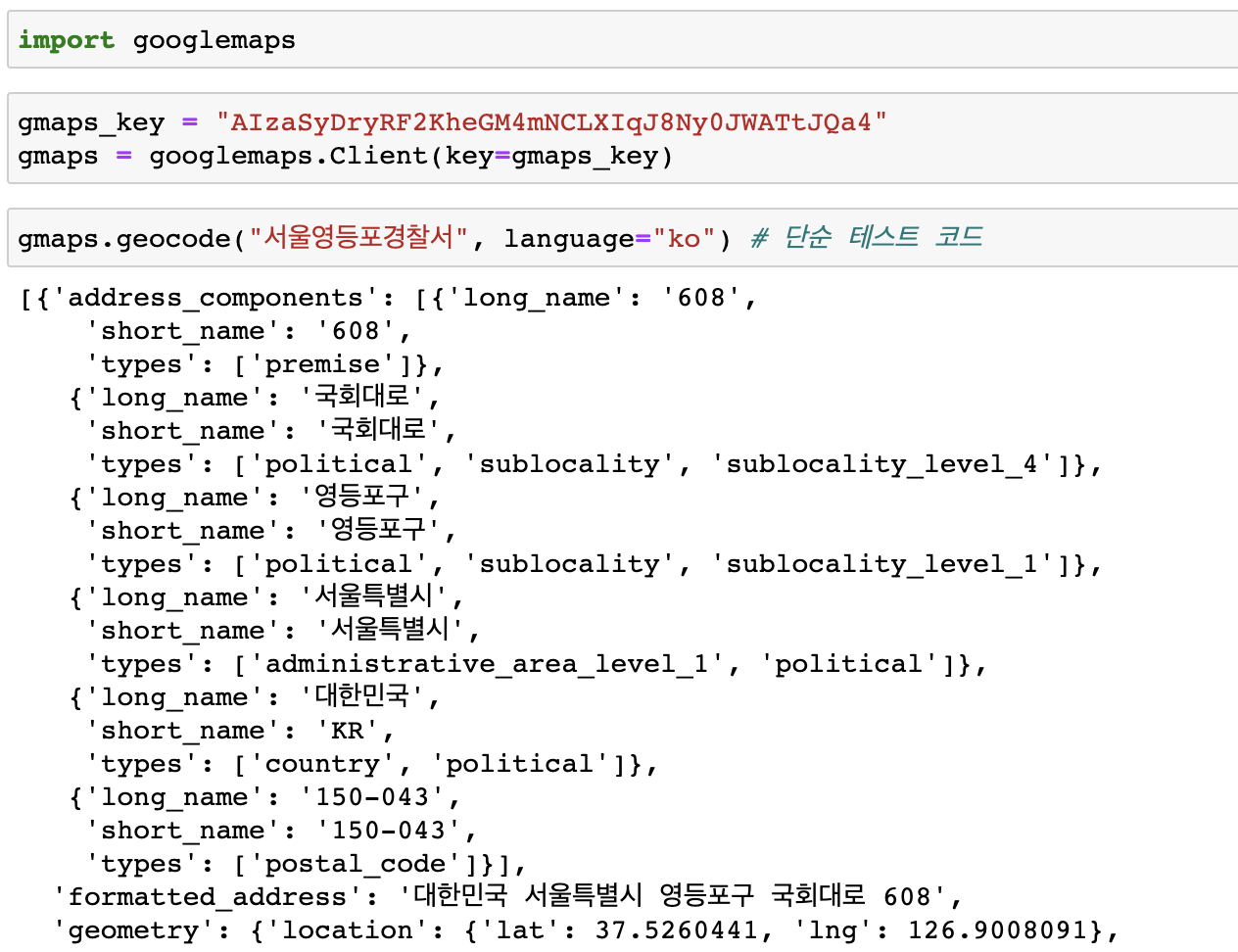
tmp변수에 담고, tmp 길이 = 1 (리스트안에 딕셔너리로 확인)
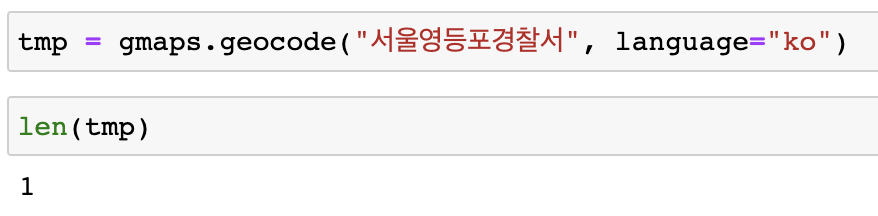
tmp list 정보 불러오기
-- tmp[0] --> 전체 결과크기가 1인 list형이라서 tmp[0]으로 접근
-- .get() 정보 가져오기
# .get("불러올제목")["불러올내부값"]
tmp[0].get("geometry")["location"]
-
.split() --> 가져온정보 list에 넣기, 원하는단어 인덱스확인

-
(구별, lat, lng) 컬럼 만들기
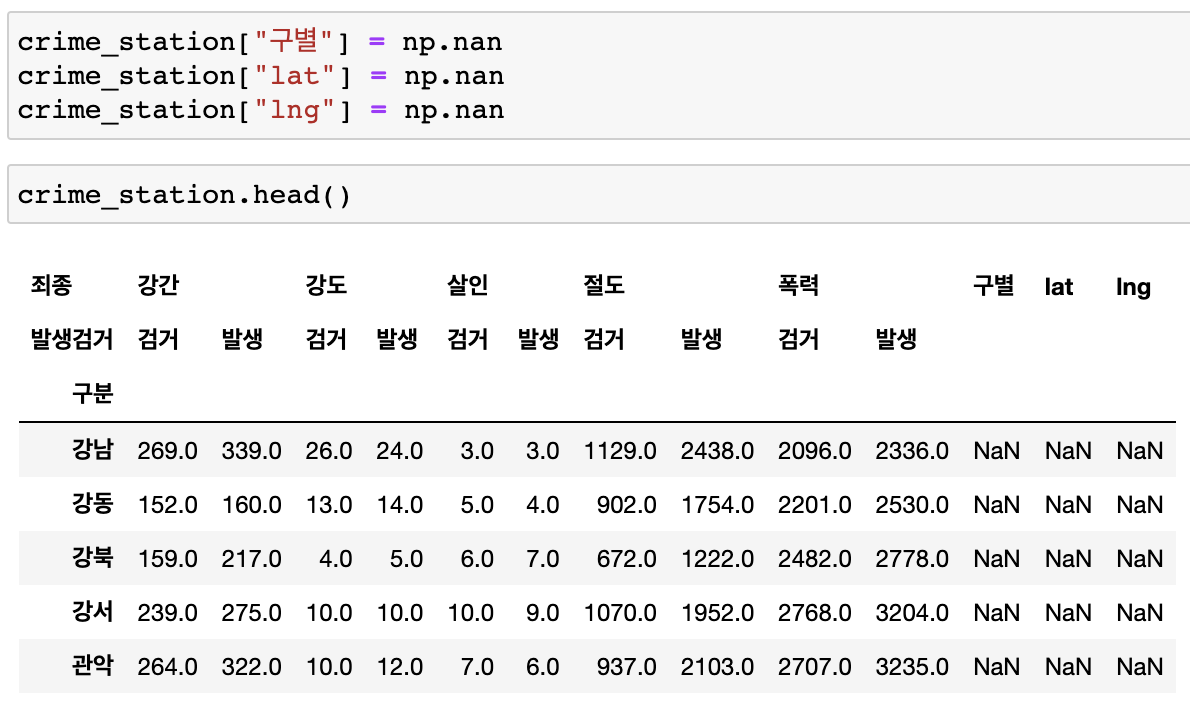
-
NaN값 변경위 위한 예제
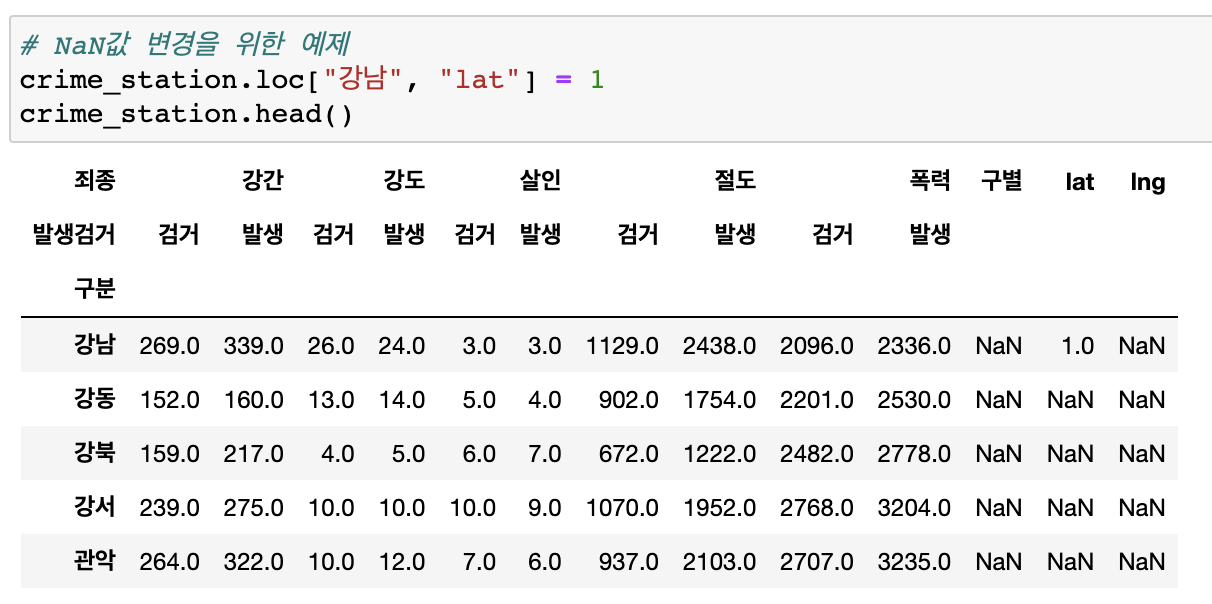
- 경찰서 이름에서 소속된 구이름 얻기 (idx, rows)
- 구이름과 위도 경도 정보를 저장할 준비
- 반복문을 이용해서 위 표의 NaN을 모두 채워줍니다
- iterrows()
iterrows()
-
경찰서 이름 구하기 (idx, rows 데이터 이용)
-
iterrows() 함수를 사용해 idx, rows 도출
--> station_name = "서울" + idx + "경찰서" 만들어줌 -
idx 값
-
rows값
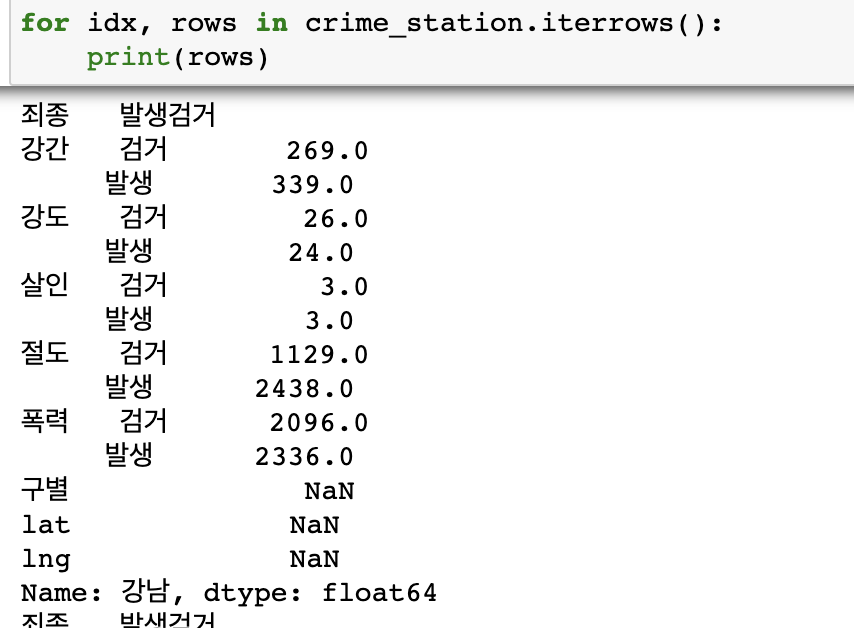
-
idx 이용해 이름 합치기
(station_name = "서울" + str(idx) + "경찰서)
(문자열 더하기 --> (idx -> str(idx))
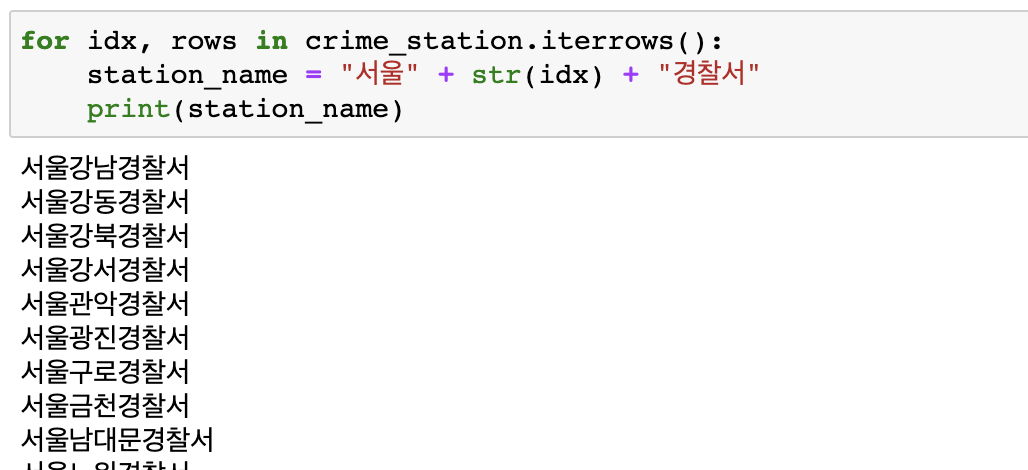
-
(구별, lat, lng) 컬럼 변경
(count로 진행상황 확인가능)
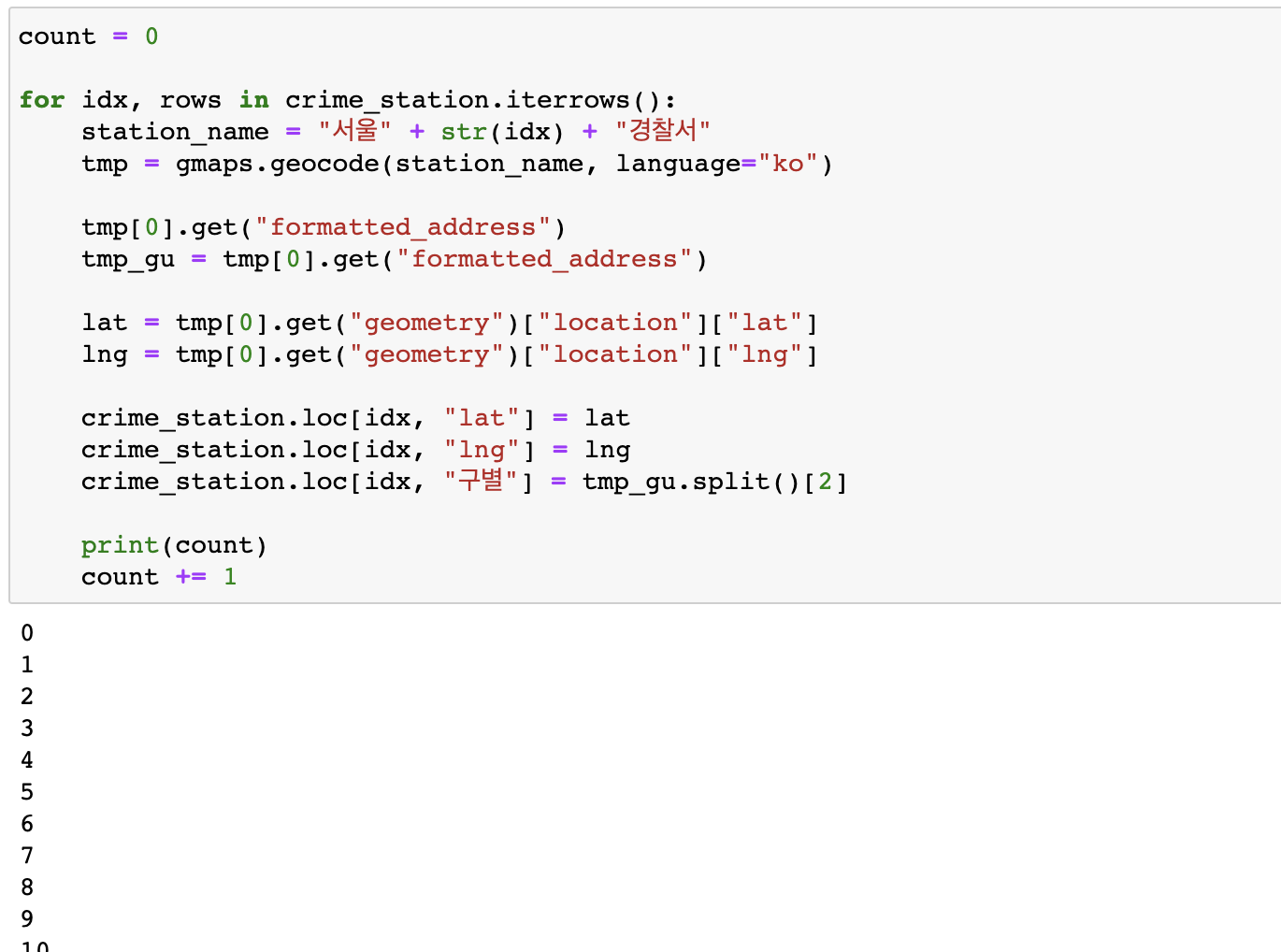
-
(구별, lat, lng) 컬럼 values 변경완료
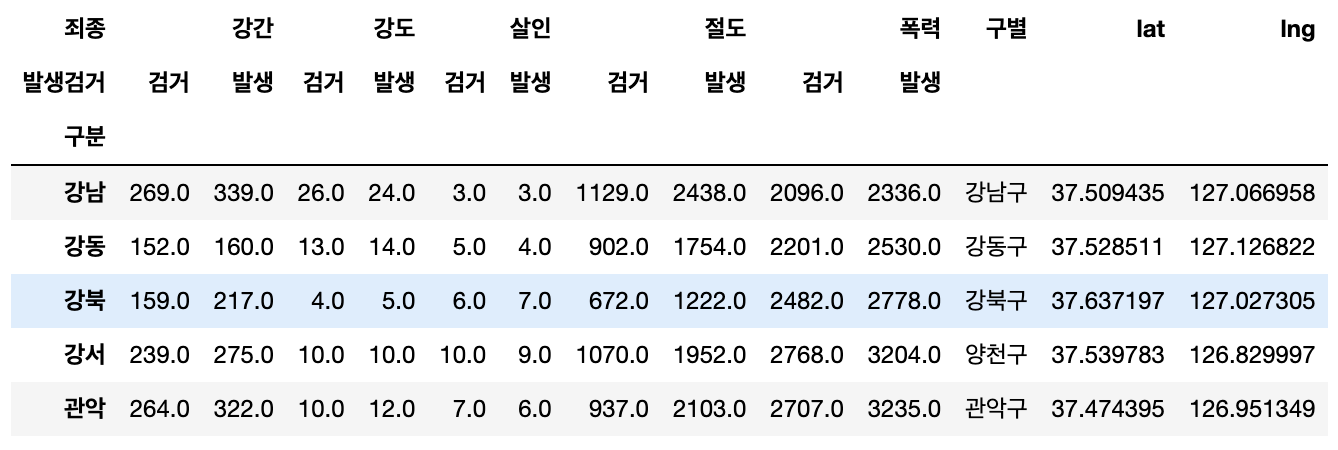
-
변경 하고자 하는 부분
-
컬럼 확인
(.get_level_values() -->컬럼인덱스 확인)
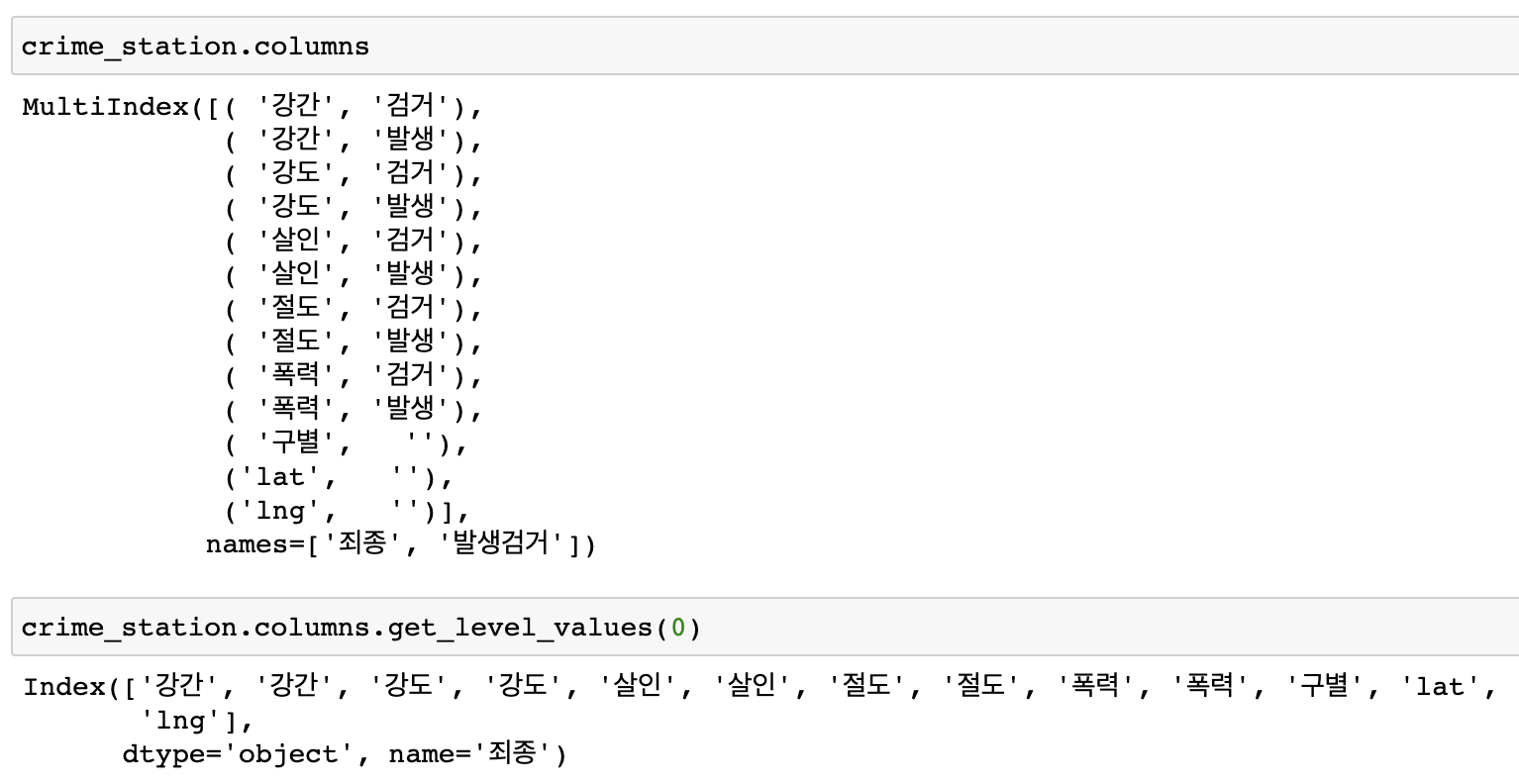
-
컬럼 내용 확인 예제
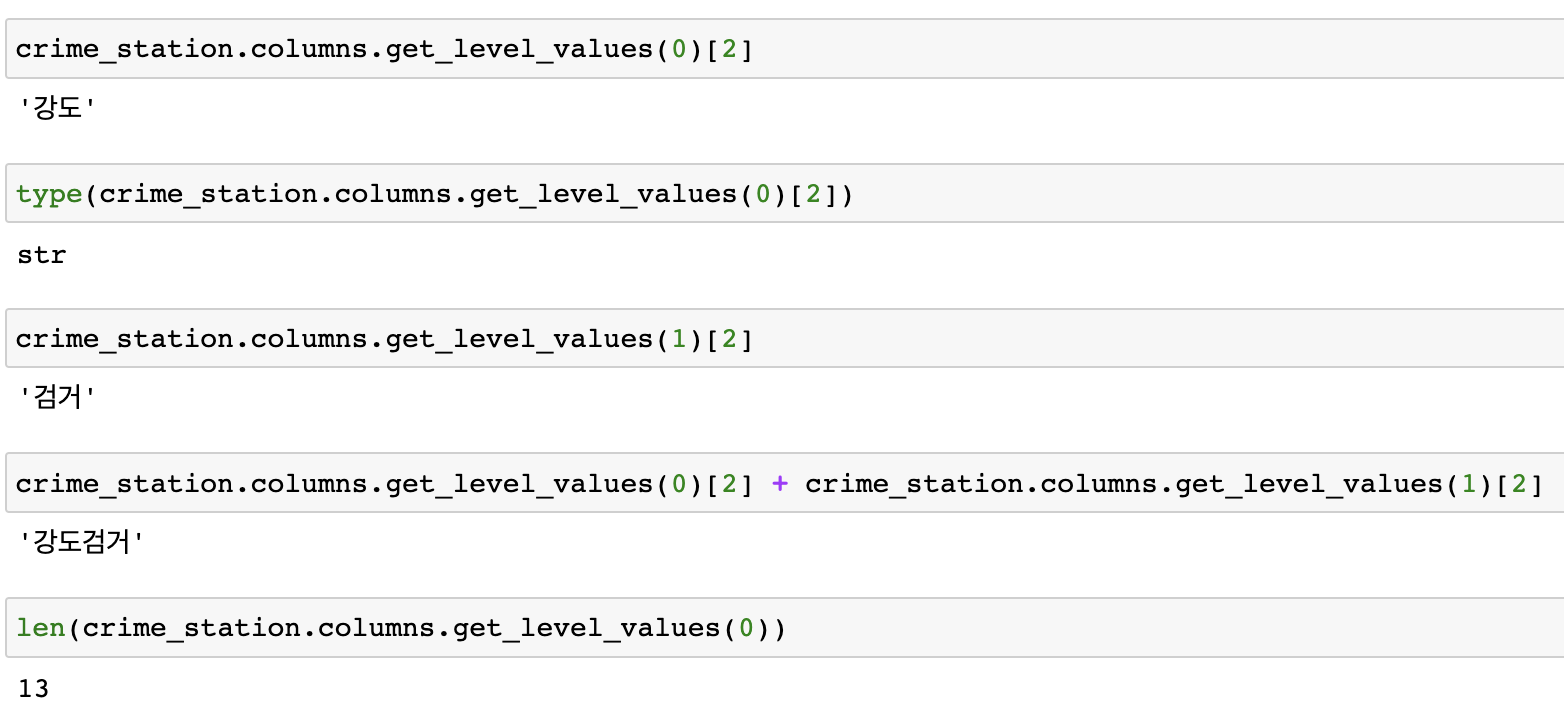
-
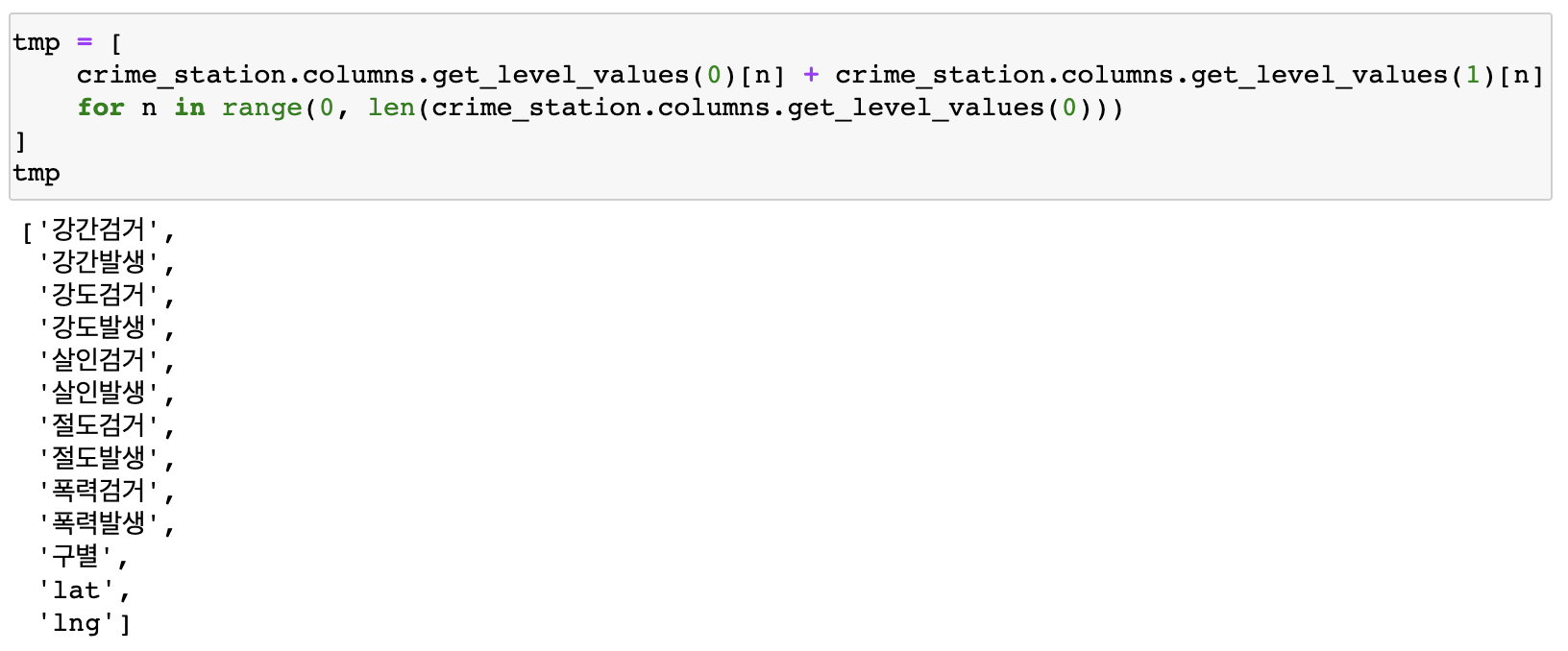
for문을 이용해 컬럼이름 합치고 tmp변수담기
-
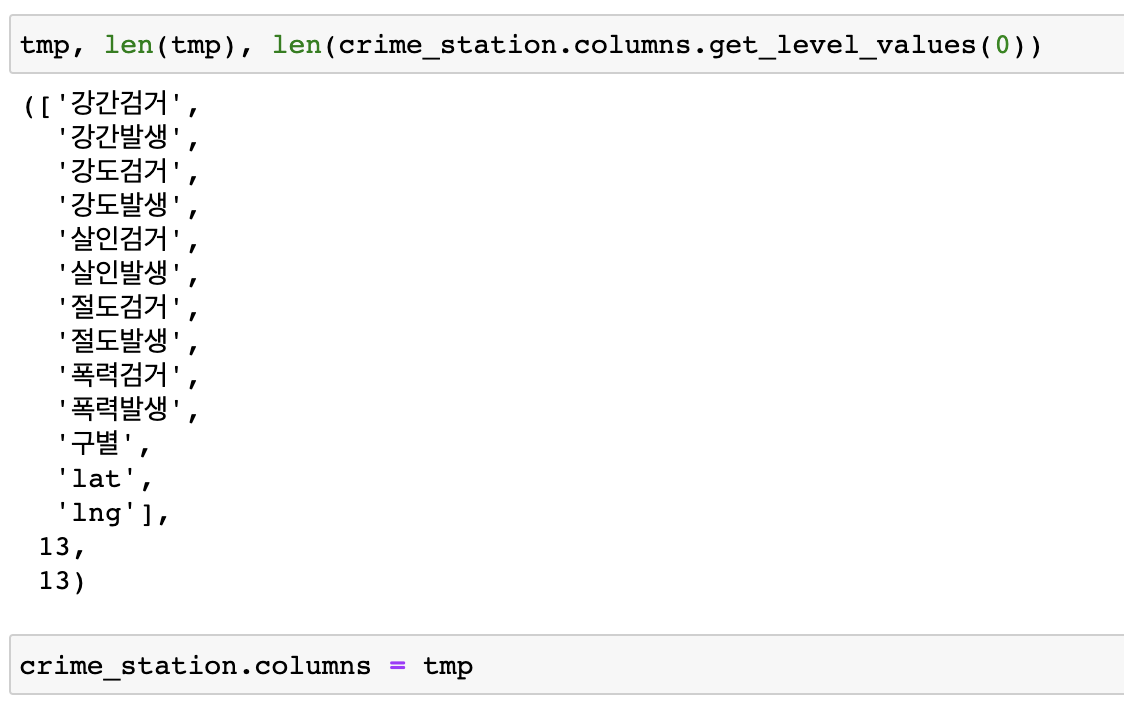
tmp길이 확인 / 변수담기
-
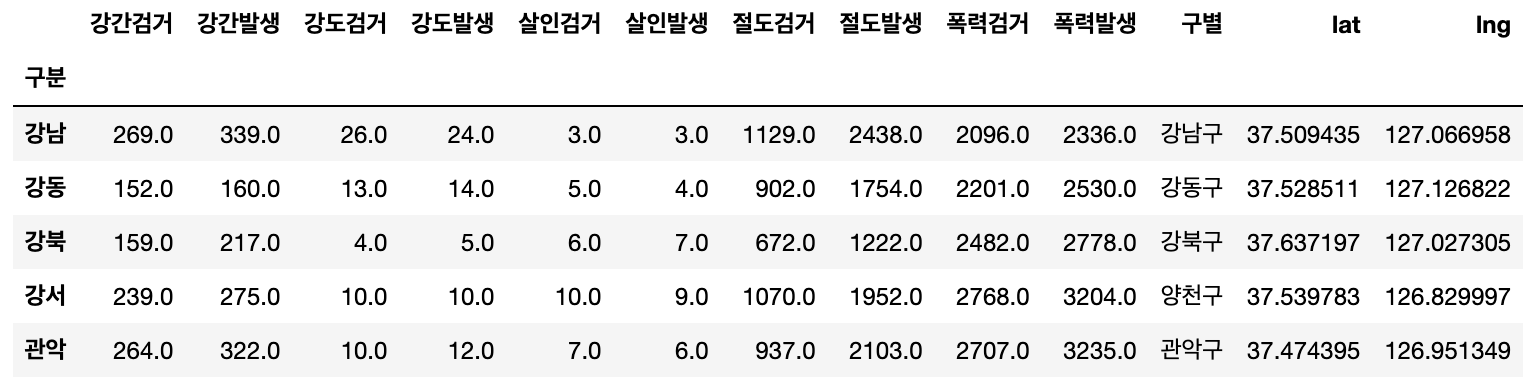
컬럼, values 변경 완료
-
저장, 읽기

7. 구별 데이터로 정리
-
crime_anal_station변수로 파일읽기

-
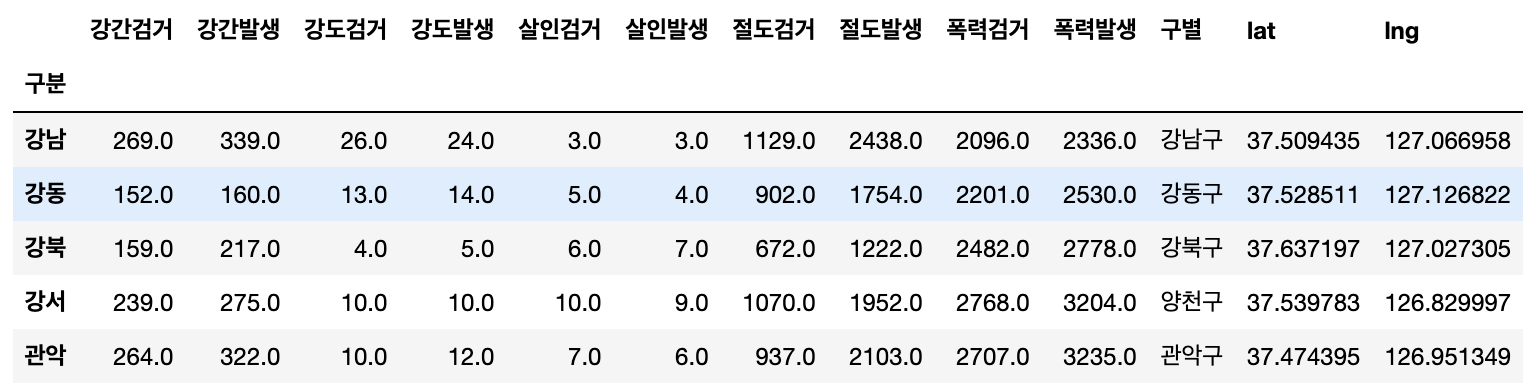
del, drop() 이용해 (lat, lng) 삭제

-
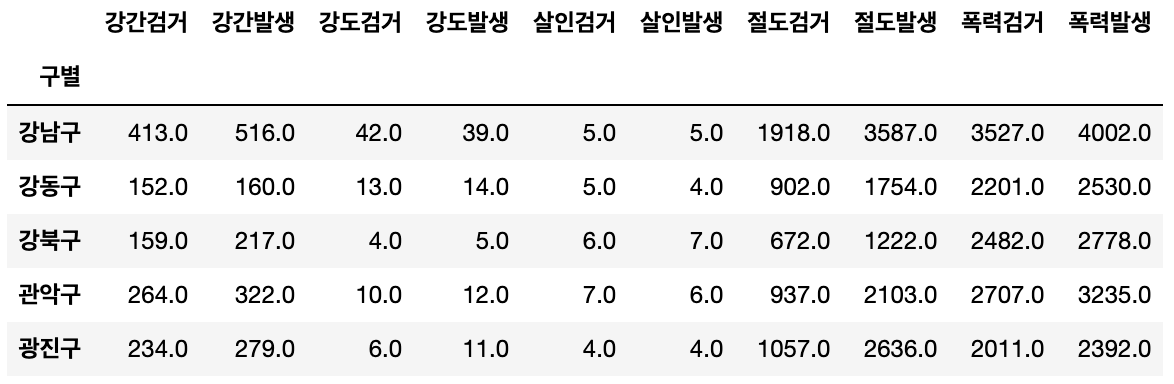
검거율 생성을 위한 컬럼 나누기 예제



-
다중나누기로 검거율 구하기
-
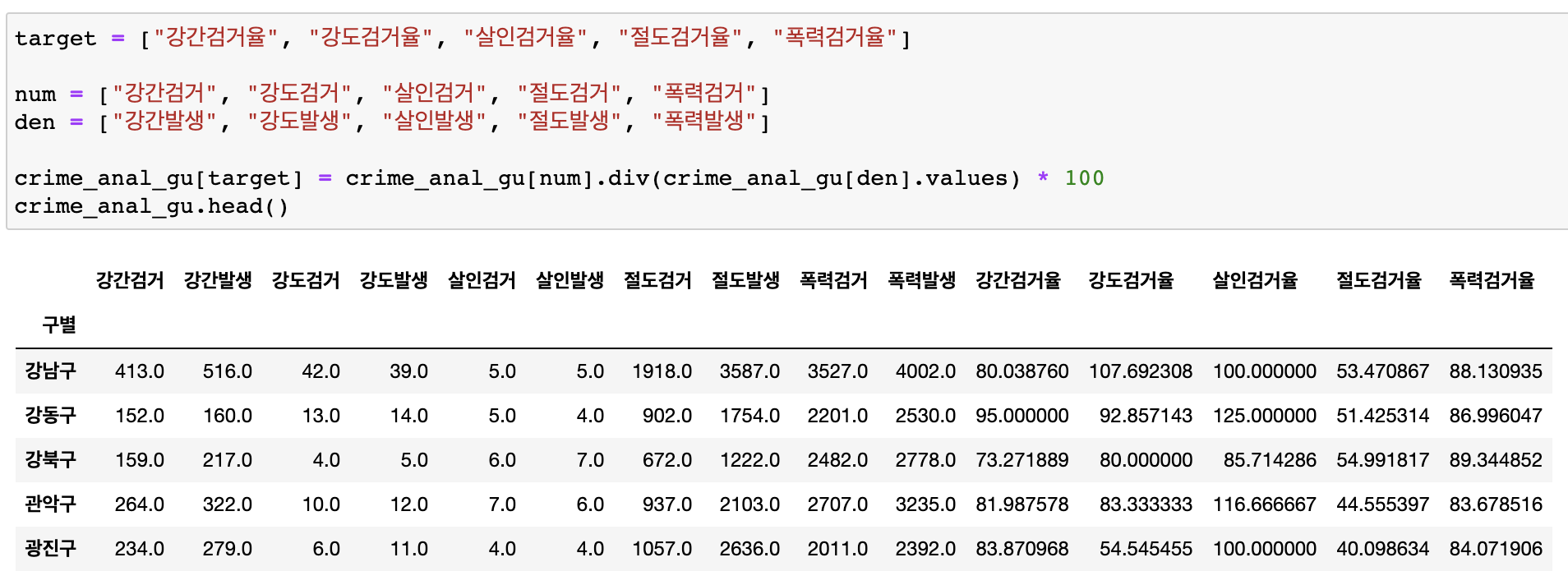
필요없는 컬럼 지우기
-
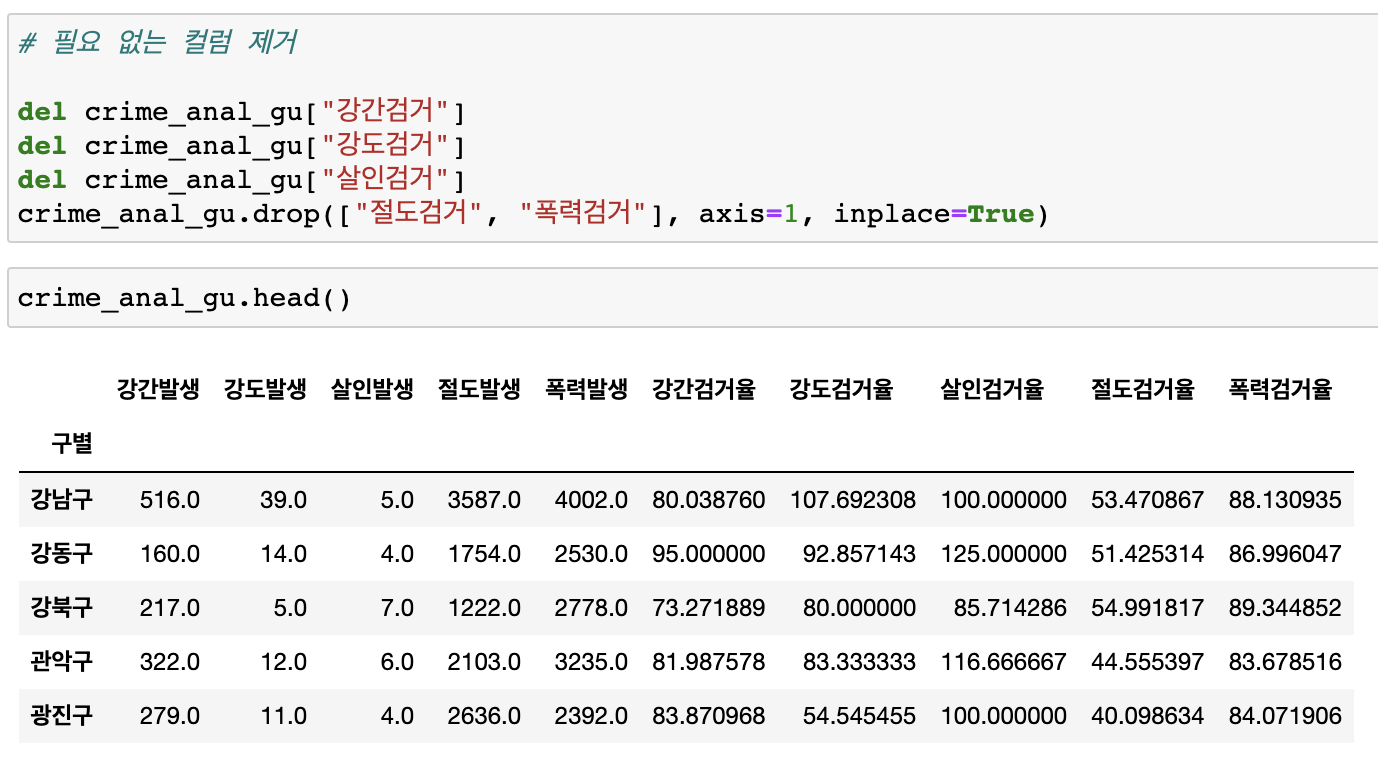
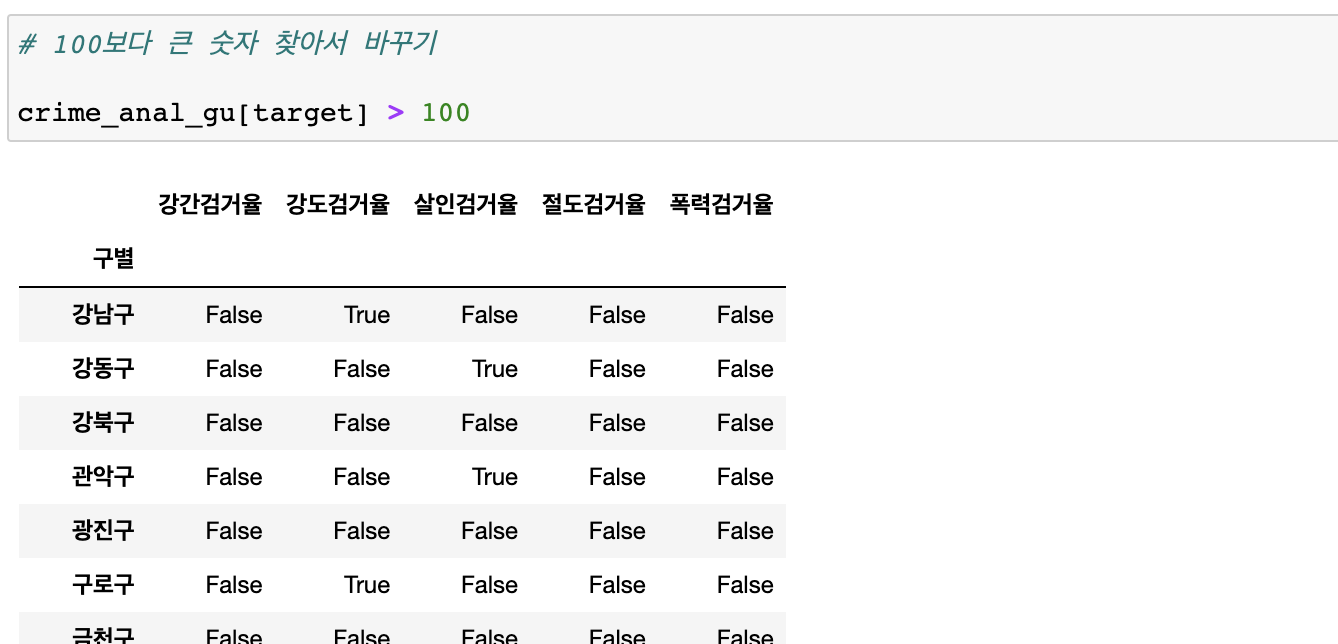
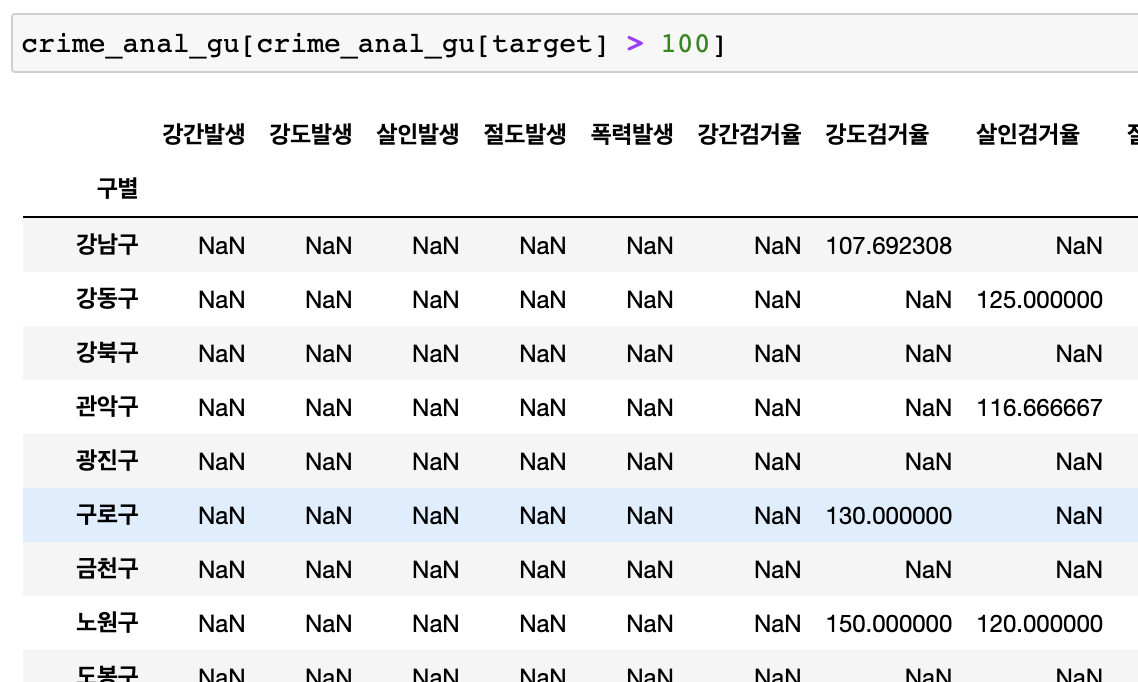
검거율 100이상인 결과 걸러내기
-- 100이상이면 True 아니면 False
-- 100이상인 결과 숫자로 보여주기
-- 100이상인 결과 100으로 변경
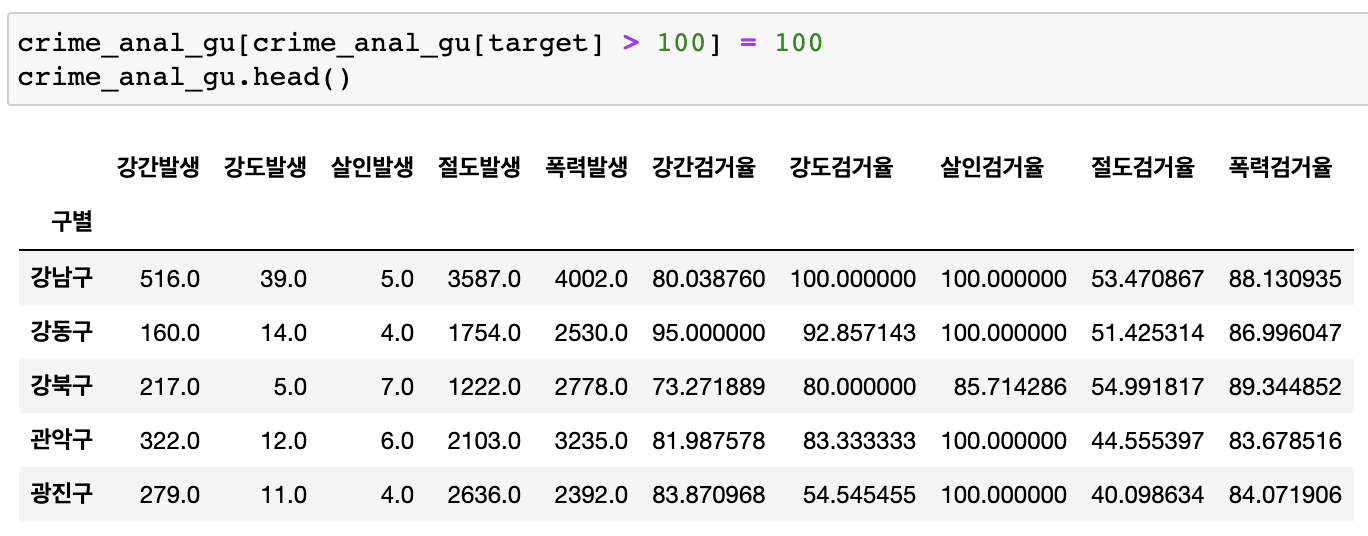
-
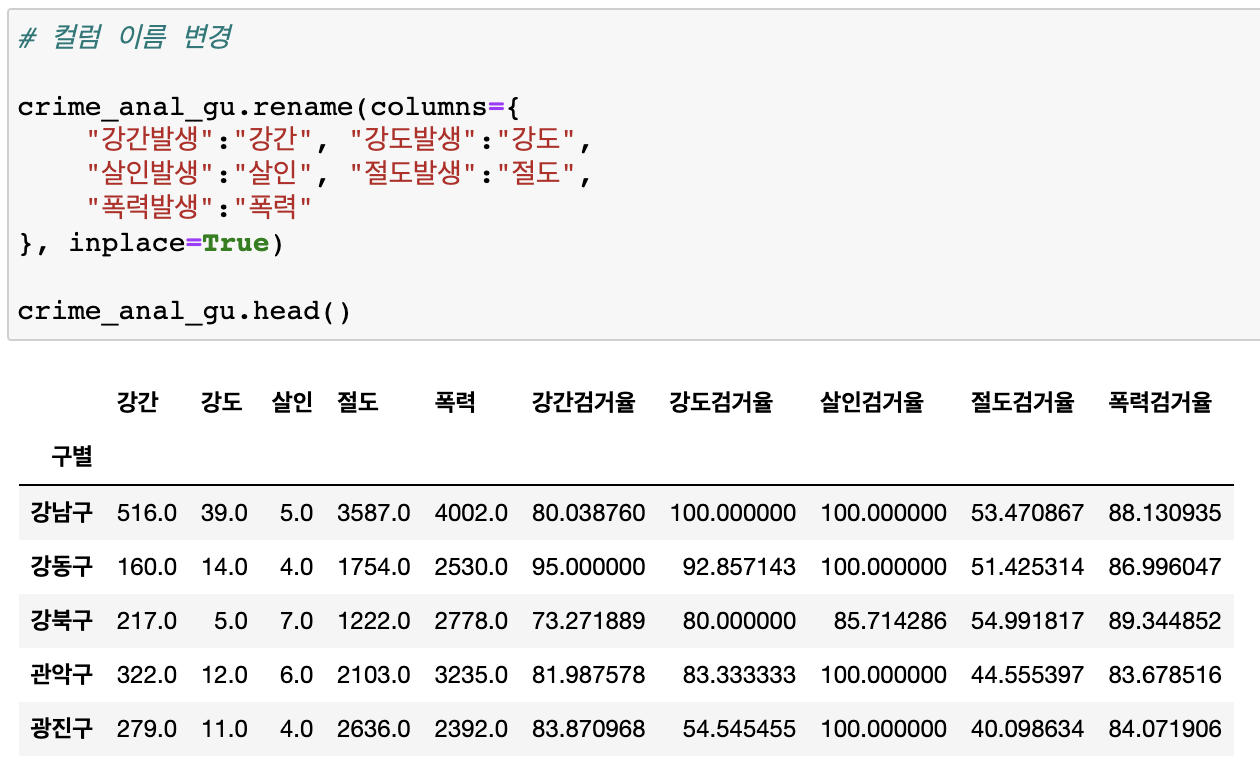
컬럼이름변경
-
강간발생 -> 강간, 강도발생->강도, 살인발생->살인 ...등
8. 범죄 데이터 정렬을 위한 데이터 정리
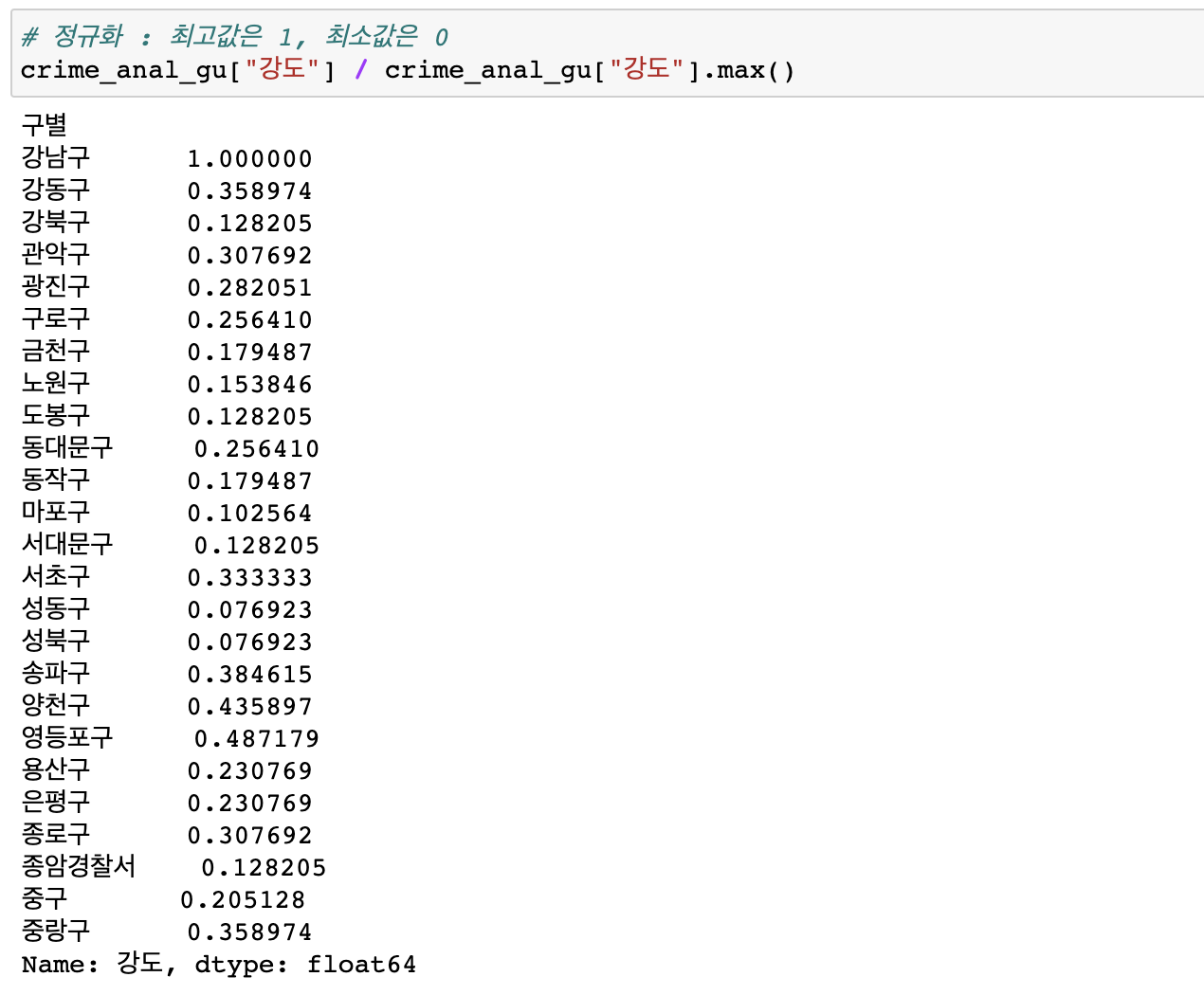
데이터값 정규화시키기
- 최대값, 최소값 으로 정리할 수 있음
- 최대를 1로 잡고 전체값을 정규화시킴
- 각구의 강도 컬럼을 / 강도컬럼의 최대값으로 나눔
-
정규화 예제
-
살인, 강도, 강간, 절도, 폭력의 정규화값
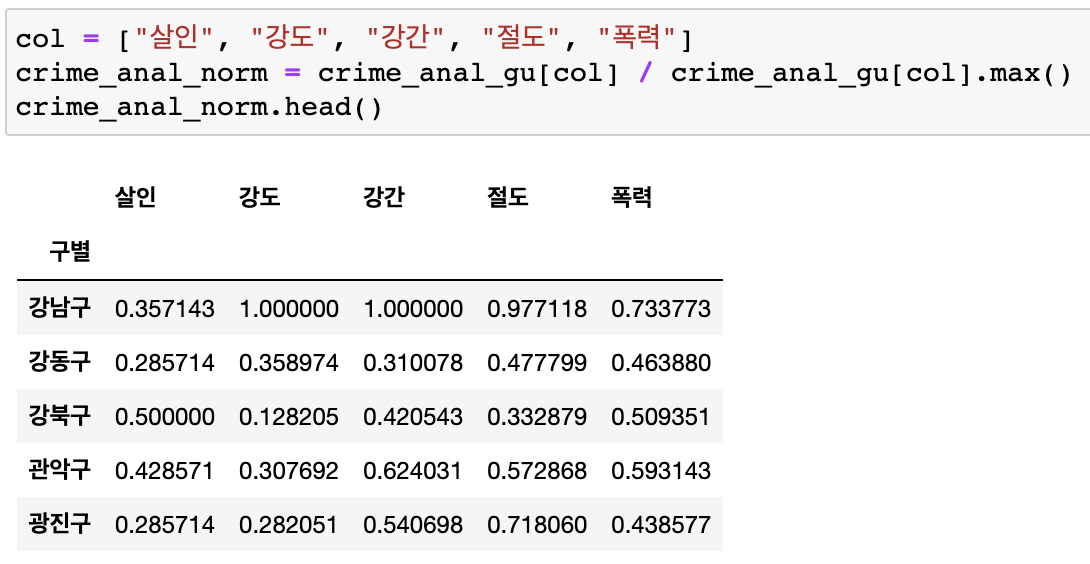
-
검거율 자료 불러오기

-
검거율 추가
(crime_anal_gu에 있던 검거율 --> crime_anal_norm에 추가)
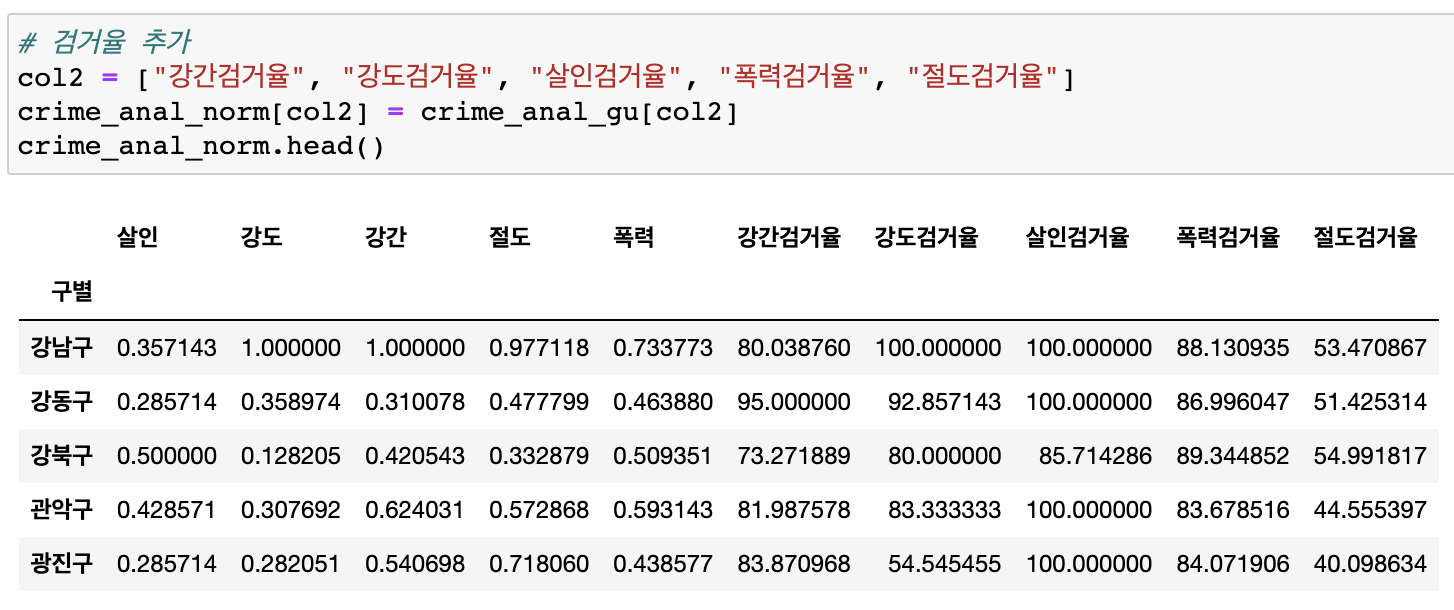
-
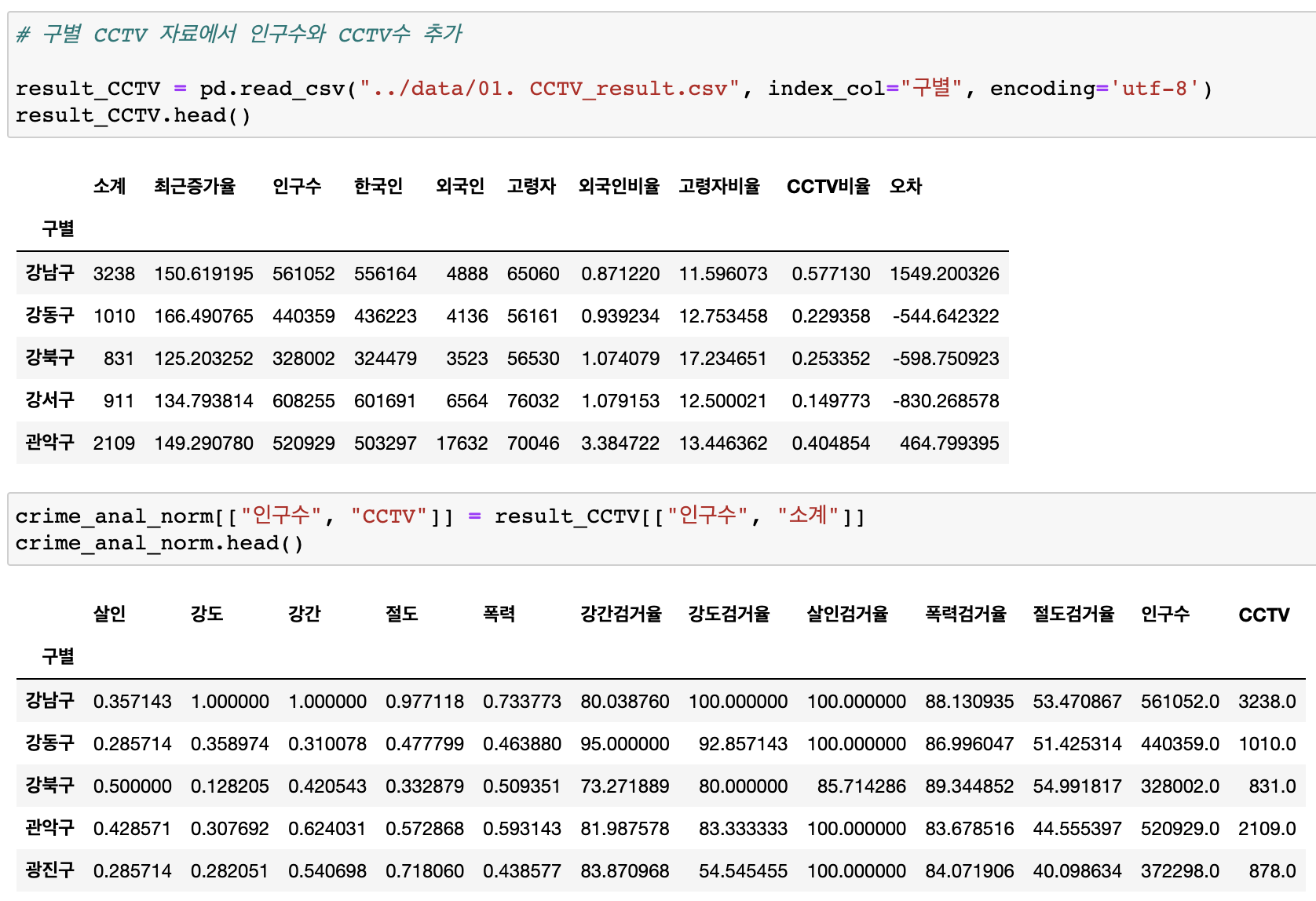
인구수와 CCTV수 추가
(result_CCTV에 있던 인구수, CCTV자료 --> crime_anal_norm에 추가)
np.mean()
(numpy 는 axis=1 행, axis=0 열 (pandas와는 반대))
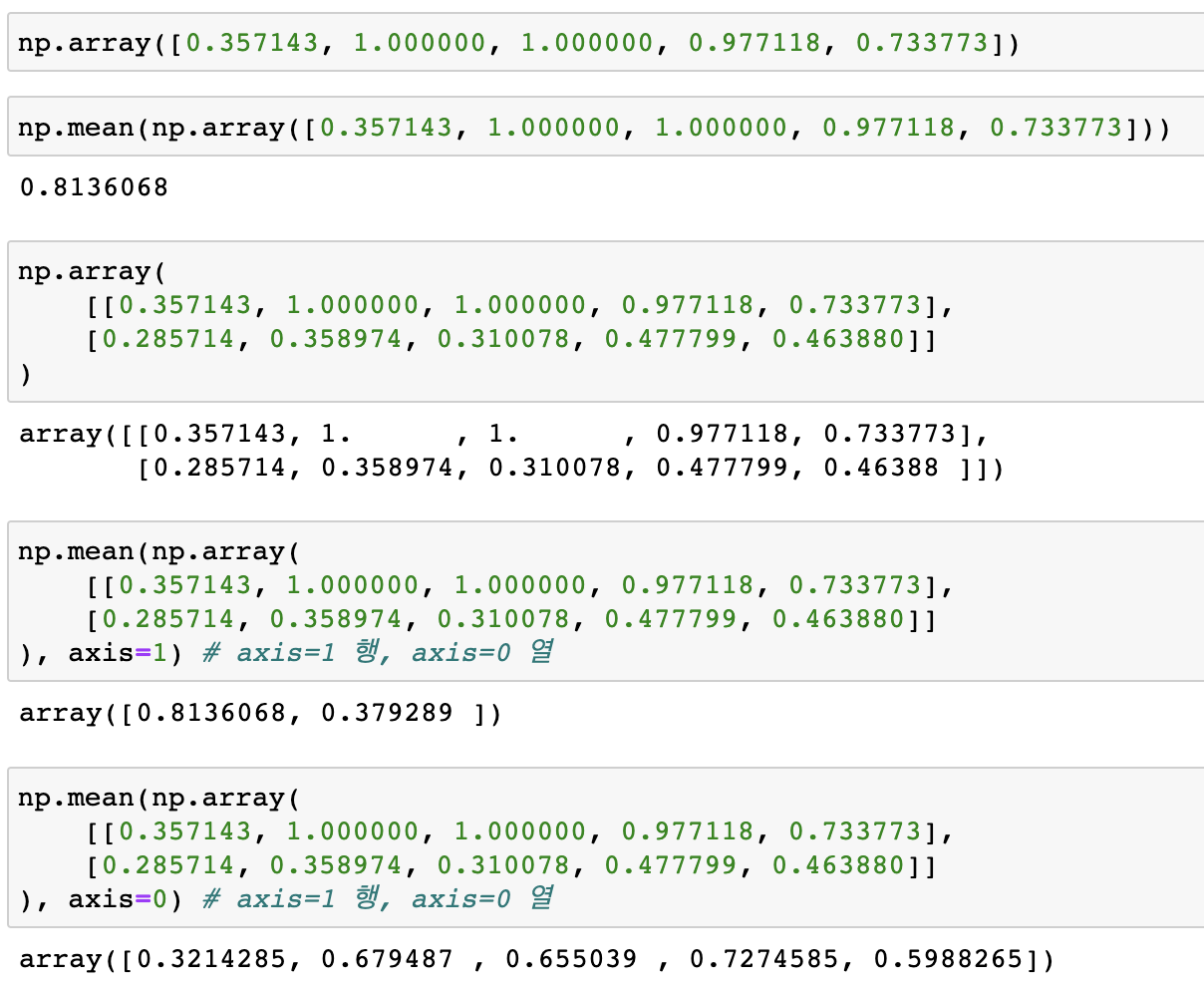
-
정규화시킨 5대범죄 전체의 평균을 구해 --> 범죄 컬럼 대표값으로 사용
(np.mean() 을 이용한 평균구하기)
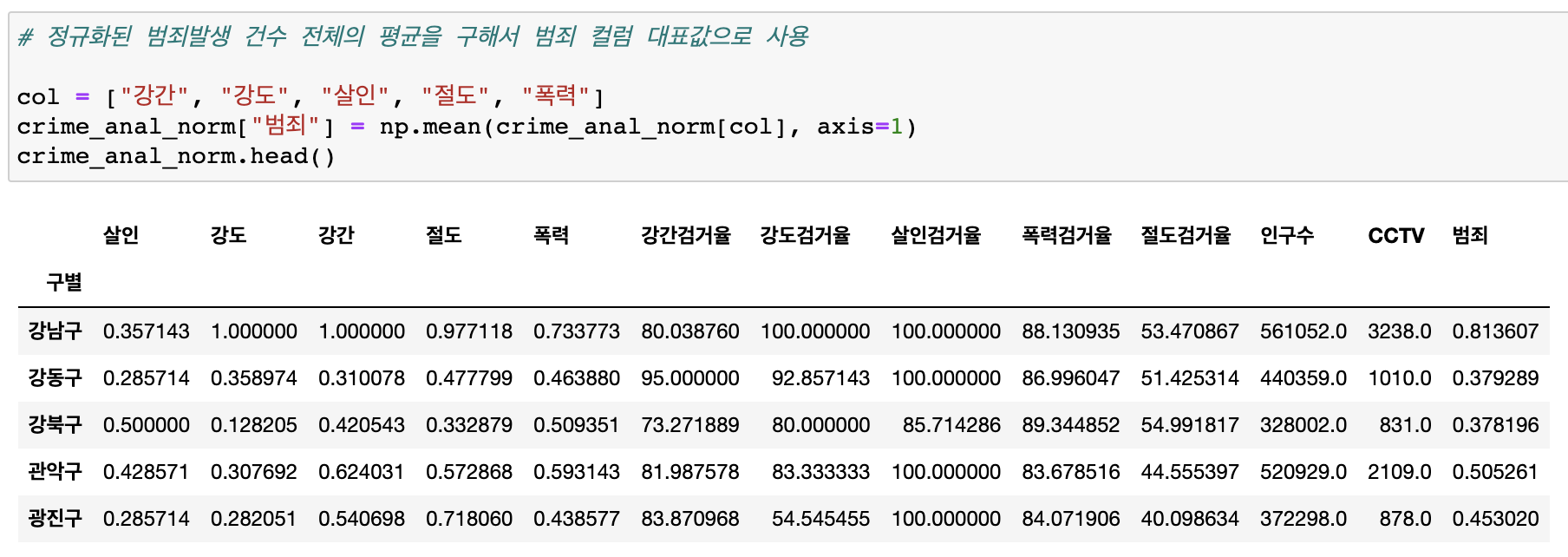
-
검거율의 평균 구해 --> 검거 컬럼의 대표값 사용
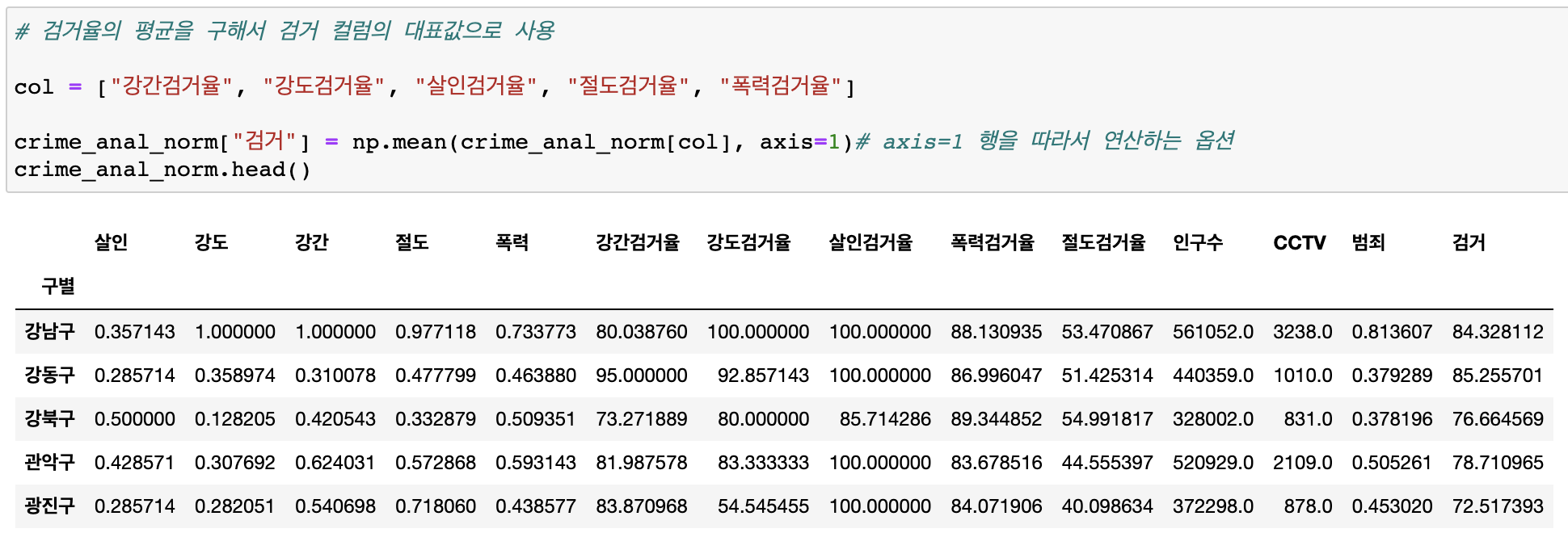
-
crime_anal_norm 완성된 결과
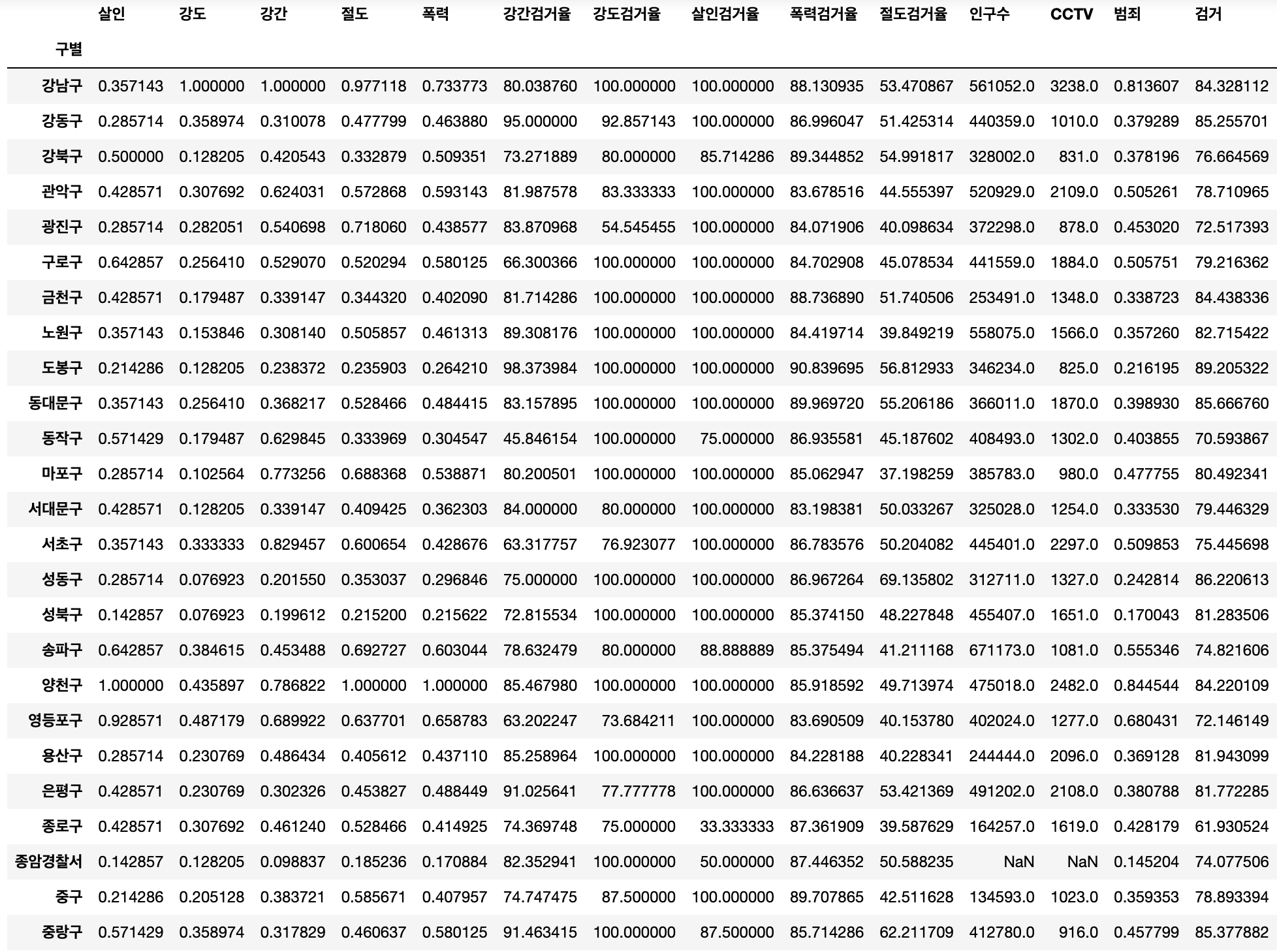
코드언어
gmaps.geocode("", language="ko") --> 지도내용 한글로 받아오기
.get()[] --> ()[]의 내용 불러오기
.split() --> 딕셔너리 내용 list로 하나씩 불러오기
.iterrows() --> for문을 돌려 idx, rows 추출 가능 함수
pd.read_csv() --> csv파일 읽기(불러오기)
del crime_anal_gu["lat"] --> lat 컬럼,value 삭제
crime_anal_gu.drop("lat", axis=1, inplace=True) --> lat 컬럼열 삭제, 변경상태 저장적용
crime_anal_gu["강도검거"].div(crime_anal_gu["강도발생]), axis=0) --> 강도검거 나누기 강도발생 행의 평균
crime_anal_gu[num].div(crime_anal_gu[den]).values) --> num리스트값 나누기 den리스트값 의 평균 밸류값
rename(columns={"강간발생":"강간", "강도발생":"강도"}, inplace=True) --> "강간발생-->"강간", "강도발생-->"강도"으로 컬럼이름변경
crime_anal_gu["절도"].max() --> 절도value의 최대값
np.mean() --> 평균값구하기
np.mean([1, 2, 3, 4], axis=0 or 1) --> axis=0 열값, axis=1 행값, (pansdas와 numpy의 axis값은 다르다)
