02. Analysis Seoul Crime
1. 프로젝트 개요
- 데이터 경로, 데이터를 통해서 얻고자 하는 자료
2. 데이터 개요
데이터읽기
# 필요모듈 import
# numpy, pandas 사용
import numpy as np
import pandas as pd
# 숫자값의 콤마를 문자로인식될수 있기때문에
# 천단위구분(thousands=",")이라고 알려주고 콤마를제거 숫자형으로 읽는다
thousands=",", encoding="euc-kr"죄종추출 -> 죄종에서 NaN만 추출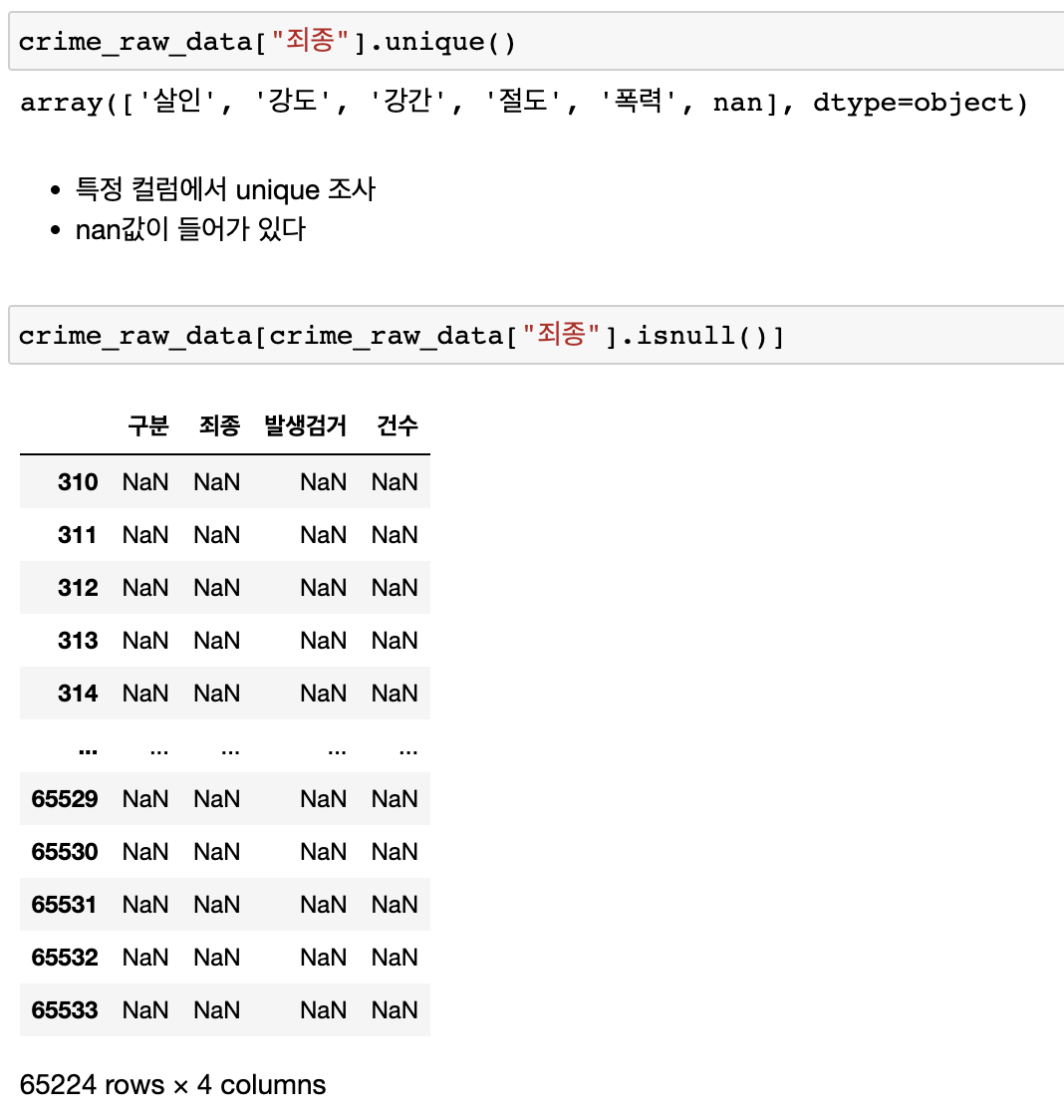
- 엑셀을 읽을때는 정상이지만 추출하면 nan데이터가 보임
- index가 65535크기를 갖게 되면서 실제 value와의 크기차이가 발생했기때문
- nan데이터만 꺼내오기
- 일부 연도별 정보만 일어난상황
pandas pivot table
- index, columns, values, aggfunc
# 엑셀 불러오기 안될경우 (openpyxl 설치)
!pip install openpyxl
# 엑셀 불러오기
df = pd.read_excel("../data/02. sales-funnel.xlsx")
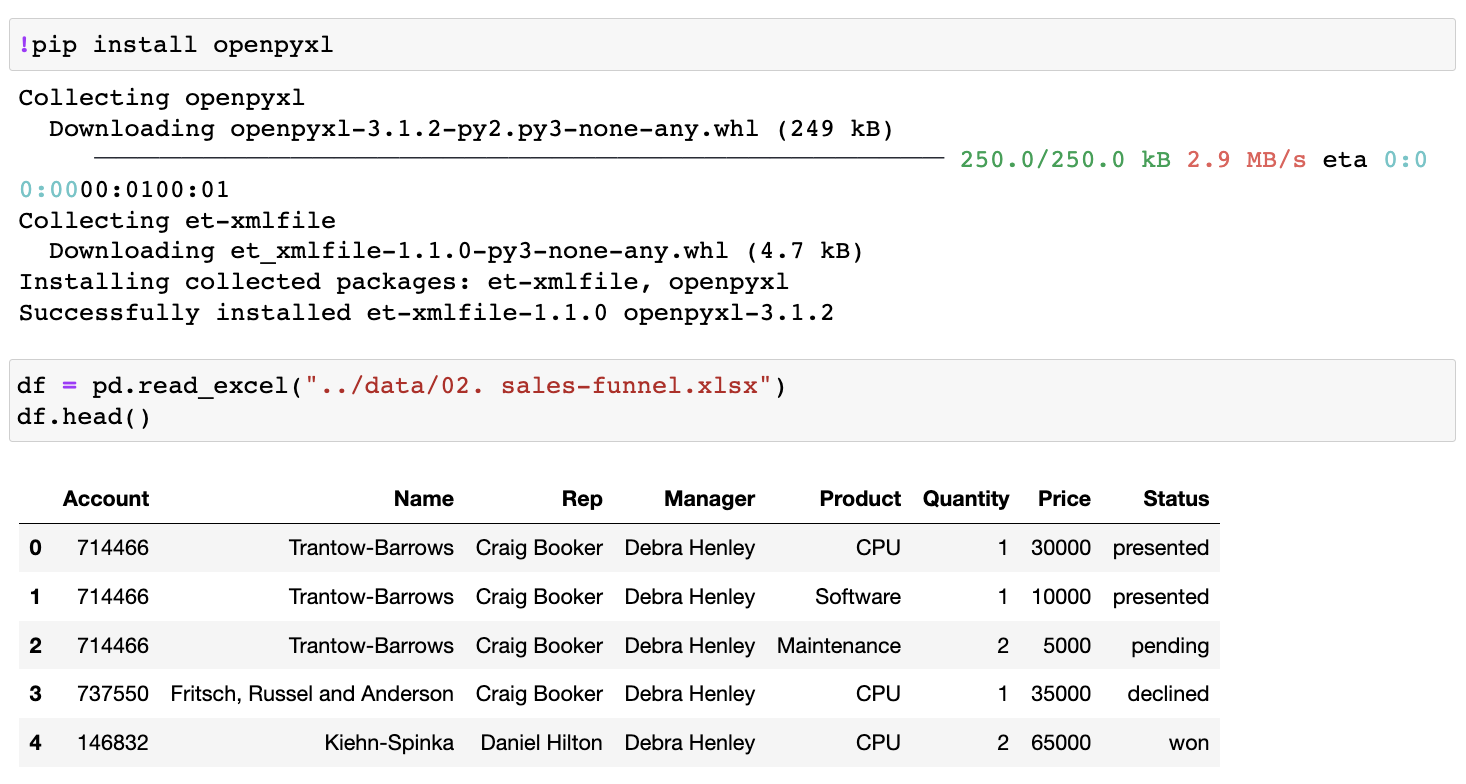
pivot_table() --> (괄호)안의 정보들로 표를 만들어라
index 설정
# Name 컬럼을 인덱스로 설정
# pd.pivot_table(df, index="Name")
df.pivot_table(index="Name")
# 멀티 인덱스 설정
df.pivot_table(index=["Manager", "Rep"])
df.pivot_table(index=["Name", "Rep", "Manager"])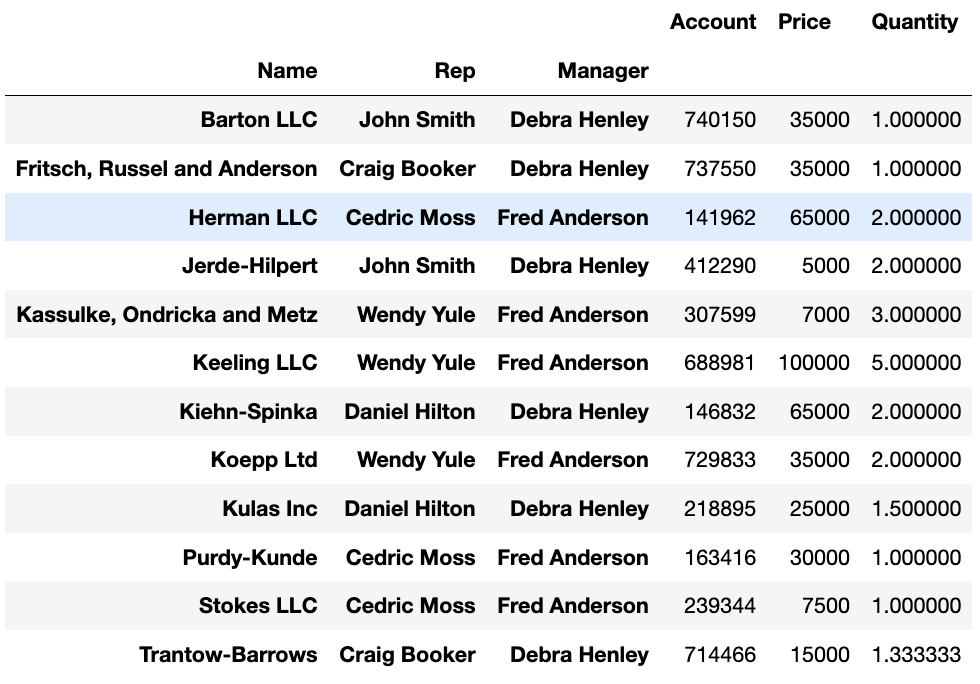
values 설정
- values에 함수 적용가능
- 디폴트는 평균
- 합산등의 다른 함수를 적용할 때는 aggfunc 옵션 지정
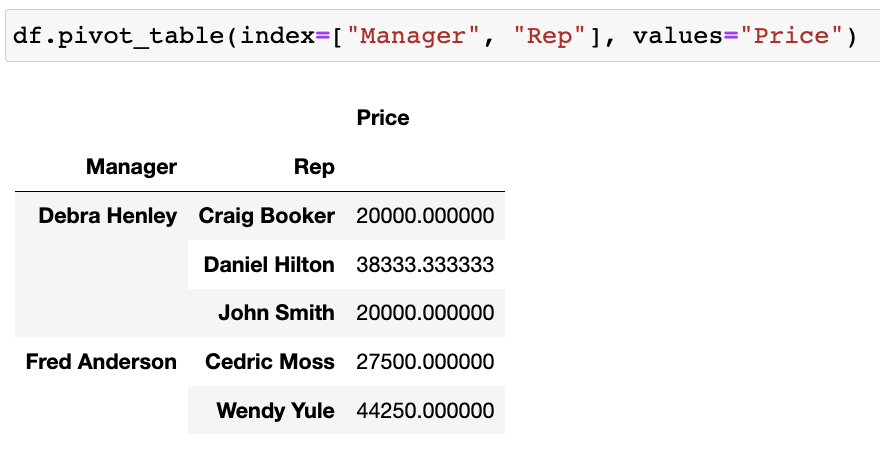
# values=Price 컬럼 sum 연산 적용
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=np.sum)
# values=Price 컬럼 len 갯수 적용
df.pivot_table(index=["Manager", "Rep"], values="Price", aggfunc=[np.sum, len])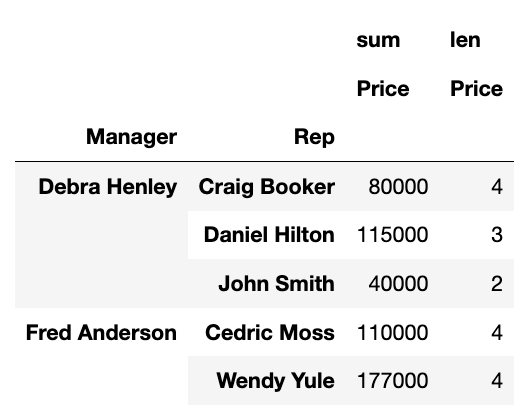
columns 설정
# product를 컬럼으로 지정
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum)
# Nan 값 설정 : fill_value
df.pivot_table(index=["Manager", "Rep"], values="Price", columns="Product", aggfunc=np.sum, fill_value=0)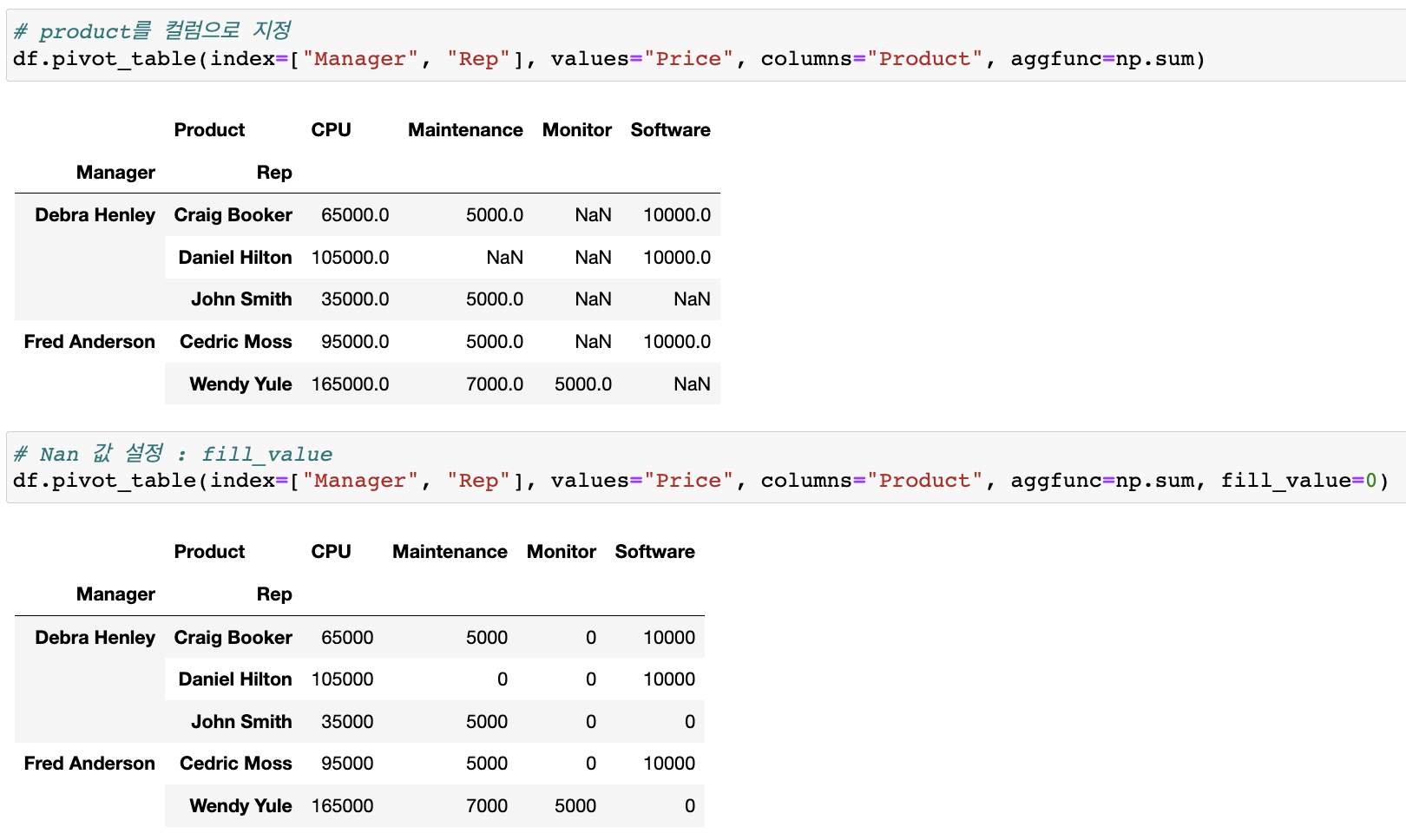
# index, values, aggfunc 2개 이상 설정
df.pivot_table(index=["Manager", "Rep", "Product"],
values=["Price", "Quantity"],
aggfunc=[np.sum, np.mean],
fill_value=0,
margins=True) # 총계(All) 추가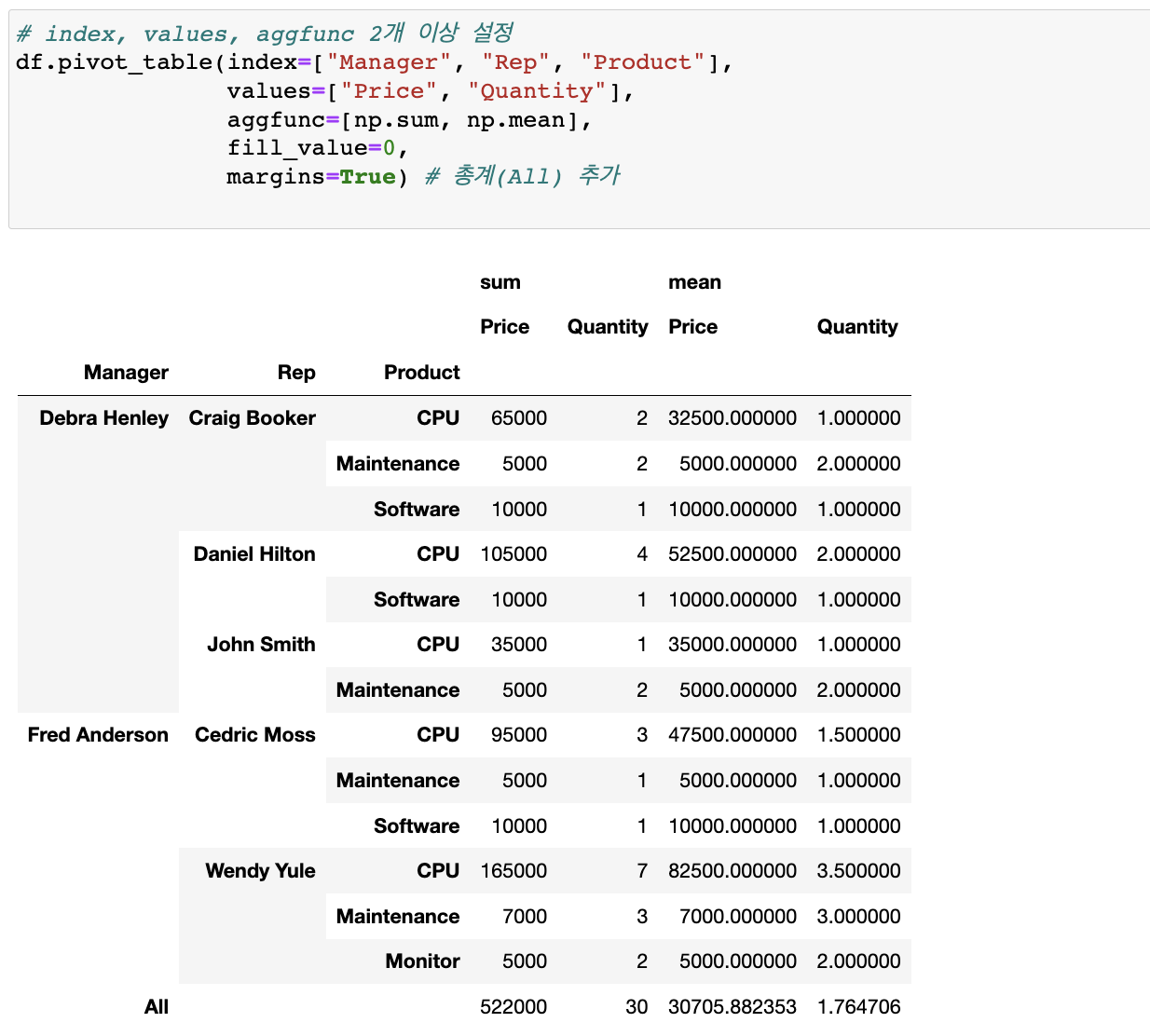
3. 서울시 범죄 현황 데이터 정리
- 경찰서 이름으로 index넣기
- 평균(mean)이 디폴트기때문에 aggfunc=np.sum --> 사건의합 기록
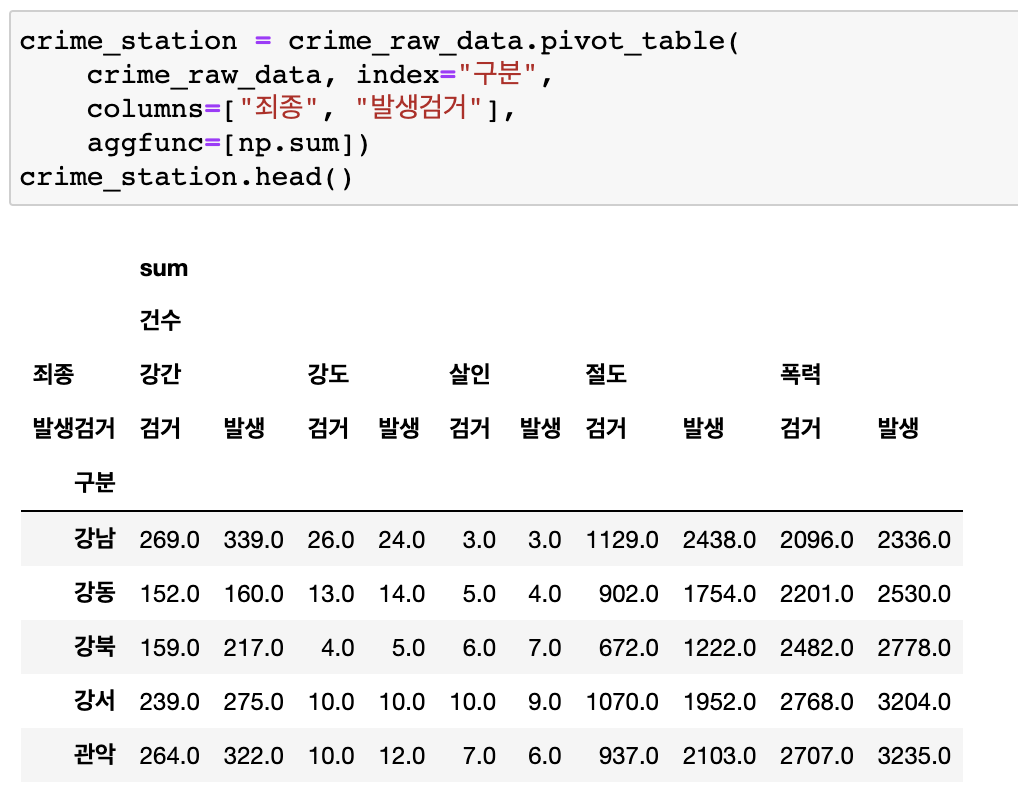
- 다중컬럼 (multiindex정리)
# Multiindex
crime_station.columns
# sum, 건수, 강도, 검거 컬럼 자료 확인
crime_station["sum", "건수", "강도", "검거"][:5]
# 다중컬럼에서 특정 컬럼 제거 (컬럼[0]자리 [1]자리 제거)
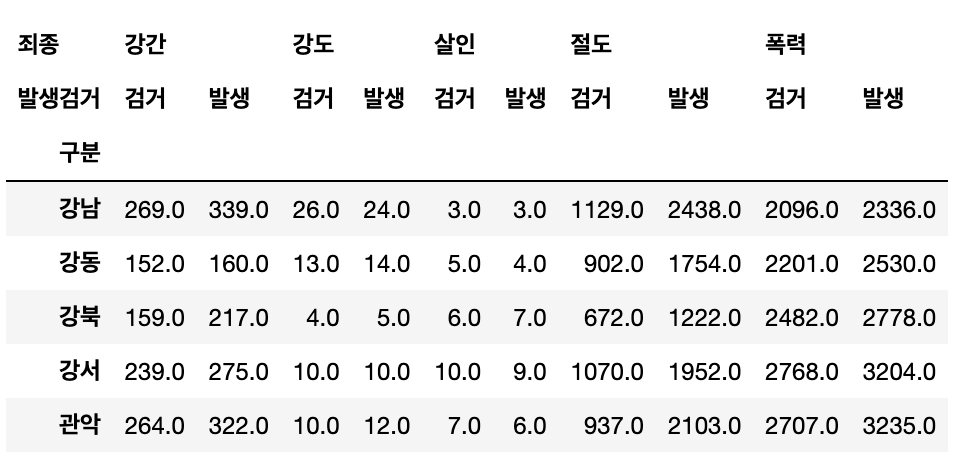
crime_station.columns = crime_station.columns.droplevel([0, 1])
crime_station.columns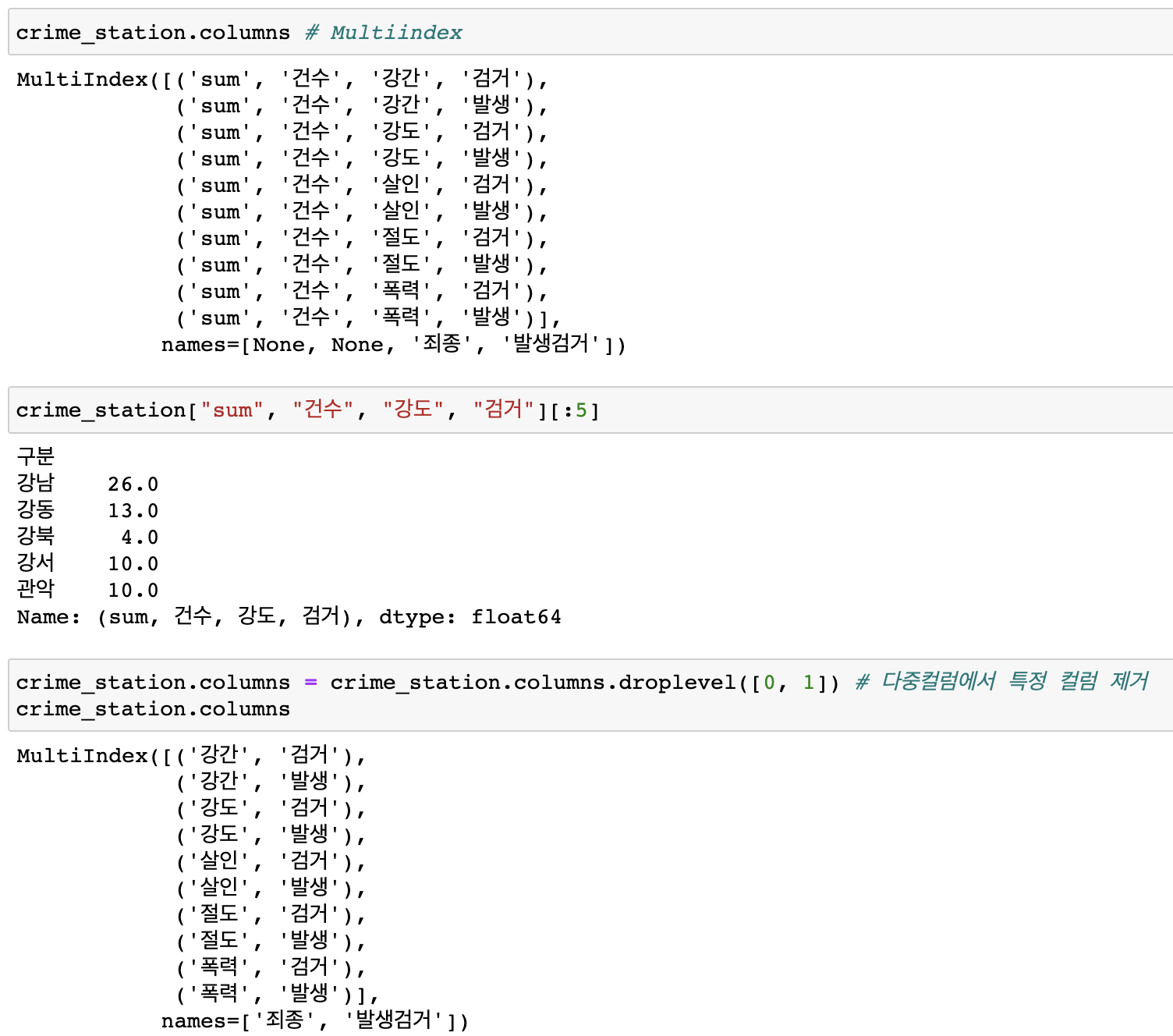
- 다중컬럼 정리완료
4. python 모듈 설치
pip 명령
- python의 공식 모듈 관리자
- pip list : 현재 설치된 모듈 리스트 반환
- pip install mudule_name : 모듈 설치
- pip uninstall module_name 설치된 모듈 제거
- mac(M1)
- ! 사용 명령어는 오류가 날 수 있음
conda 명령
- conda list : 설치된 모듈 list
- conda install module_name : 모듈 설치
- conda uninstall module_name : 모듈 제거
- conda install -c channel_name module_name
-지정된 배포 채널에서 모듈 설치 - Window, mac(intel)
5. Google Maps API 설치
- 경찰서가 속해있는 구를 알기위해 googleMaps설치
Windows, mac(intel)
- 터미널 -> (ds_study) 활성화 후
- conda install -c conda-forge googlemaps 설치
(google maps API Key 필요)
mac(M1)
-
pip install googlemaps
(google maps API Key 필요) -
서울영등포경찰서 정보 불러오기

코드, 언어
pd.read_csv() --> (괄호)안의 파일 읽기
변수명["컬럼"].unique() --> 특정컬럼의 unique조사(결과:array([자료, 자료, 자료])
pd.pivot_table() 내부에 사용가능 언어
index = ["Manager", "Rep"] --> 인덱스위치에 Manager, Rep 배치
values = ["Price"] --> 밸류위치에 Price 배치
columns = ["Product"] --> 컬럼위치에 Product배치
aggfunc = [np.sum, np.mean] --> np를 이용한 sum함수처리
fill_value = 0 --> NaN데이터를 0으로 처리
