후기
수업량이 너무 방대해서 어디서부터 어디까지 해야할지 기억범위가 너무 넓어서 막막한 느낌이 들었다
seaborn 사용법
-
설치되지 않았을 경우 재설치

-
numpy, pandas, matplotlib.pyplot, seaborn, matplotlib-rc, 한글폰트 세팅

예제1 : seaborn 기초
-
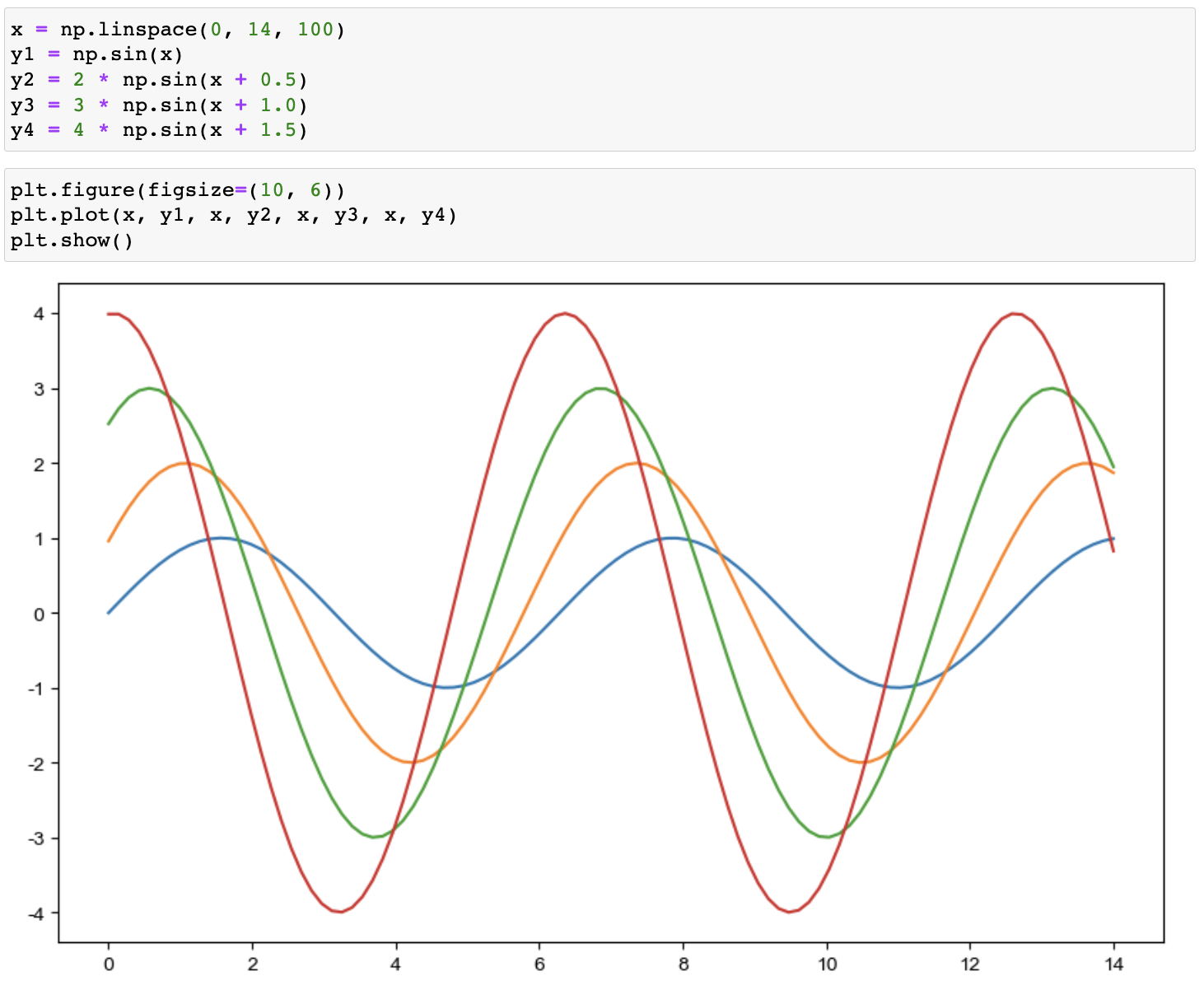
0부터 14사이 100개의 수

-
0부터 14사이 100개의 수 그래프로 만들기
-
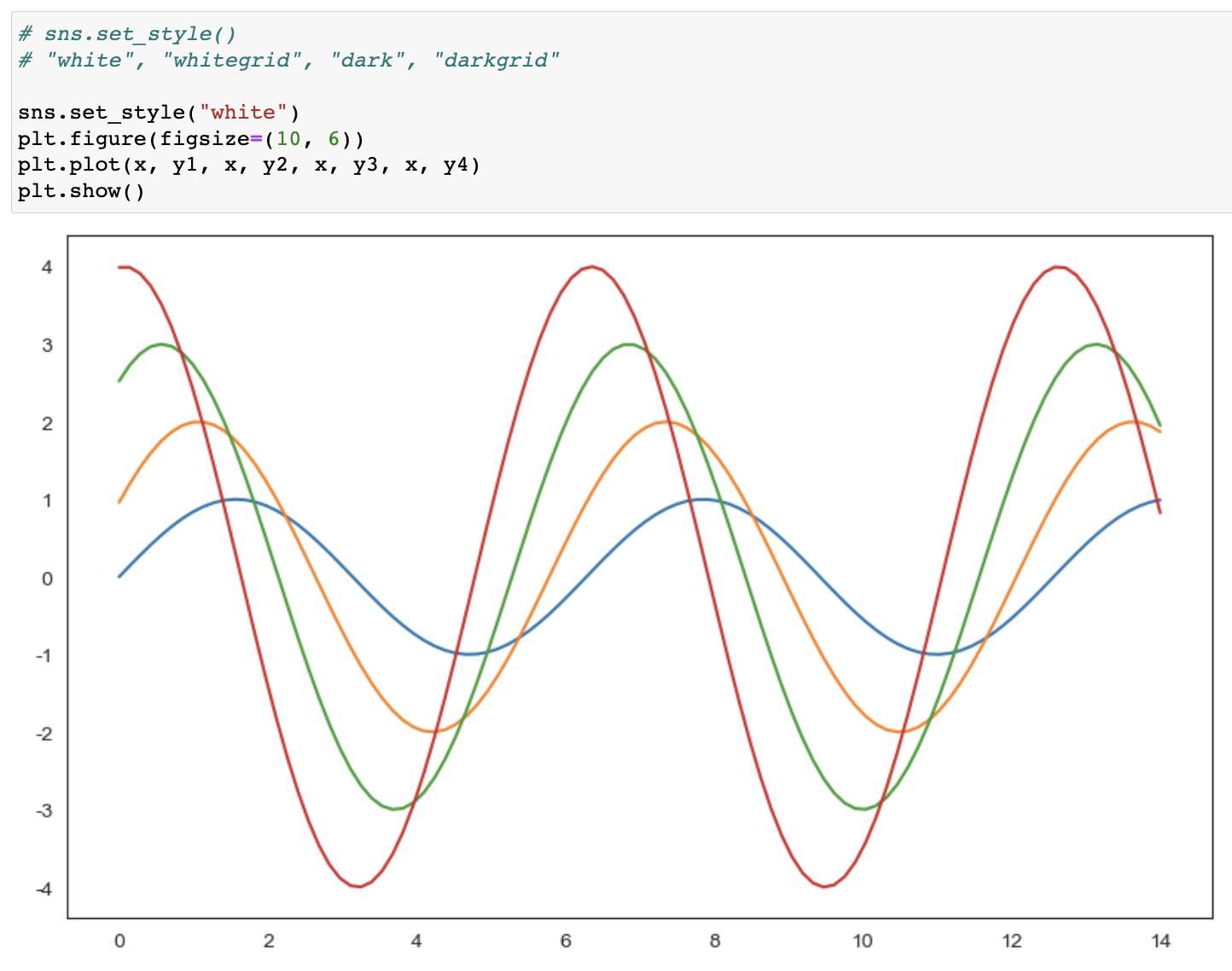
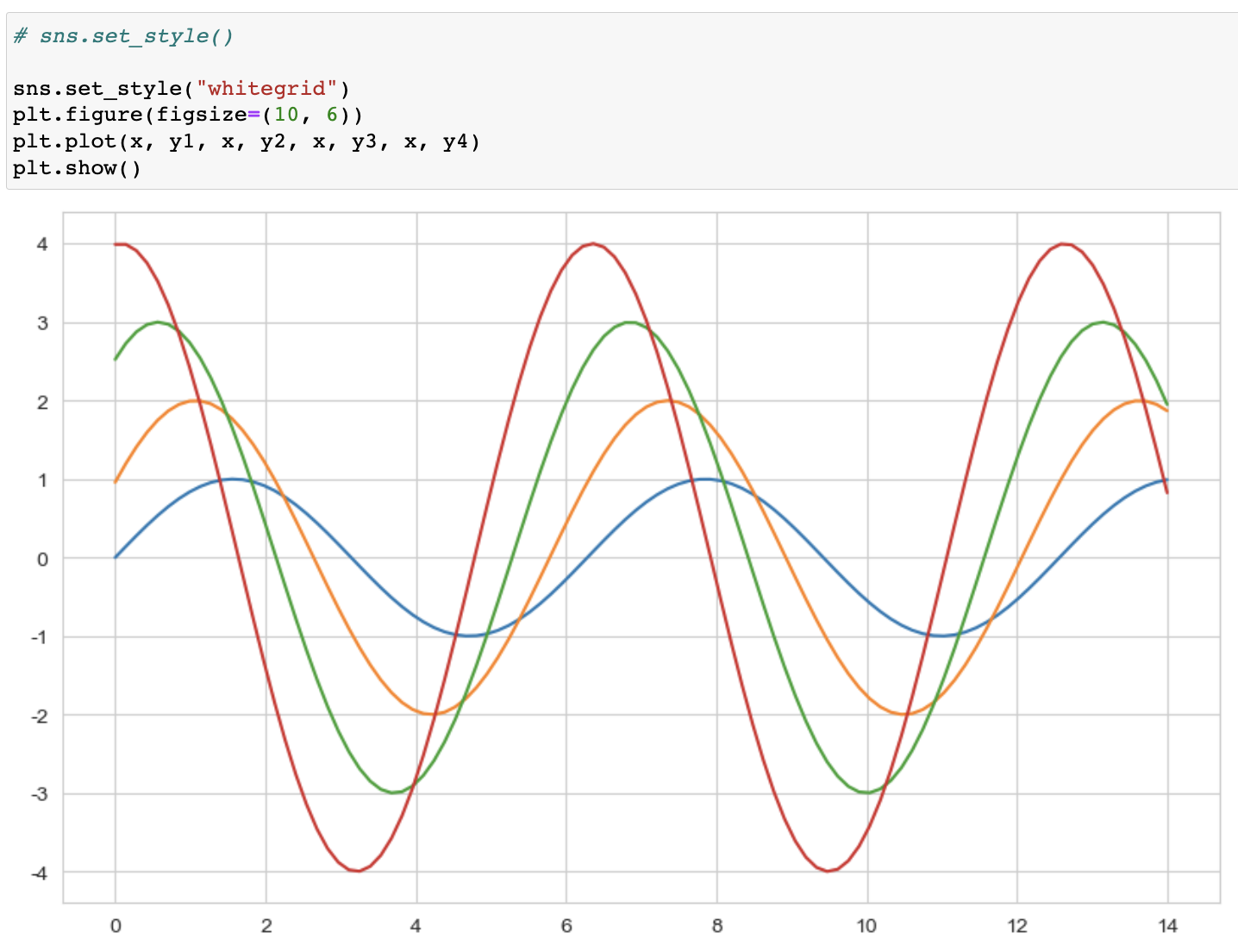
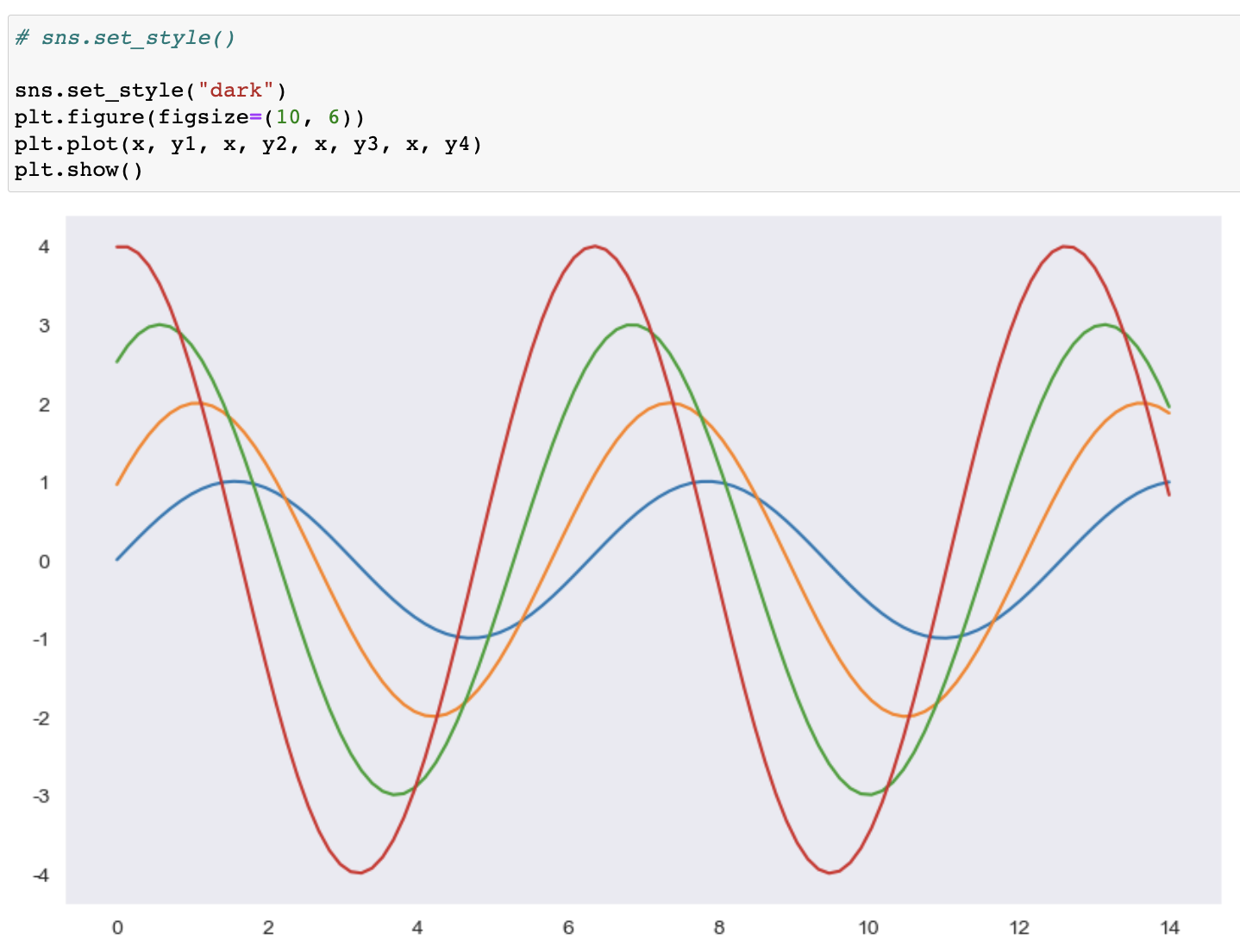
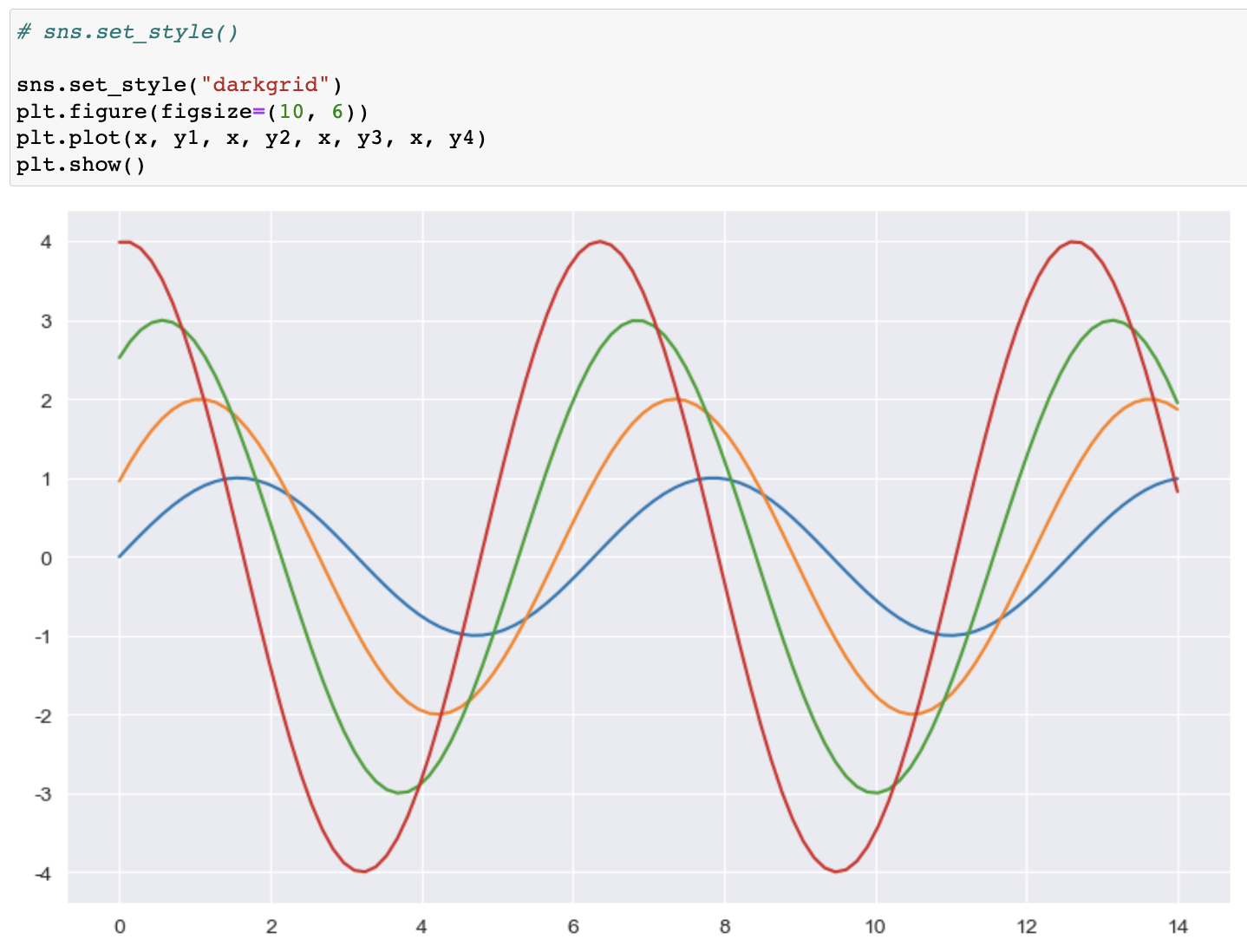
seaborn set_style()
-- white, whitegrid, dark, darkgrid
예제의 문제들은 기본으로 제공되는 포맷들을 사용
- tips data
- flights data
- iris data
- anscombe data
예제2 : seaborn tips data
-
boxplot
-
swarmplot
-
lmplot
-
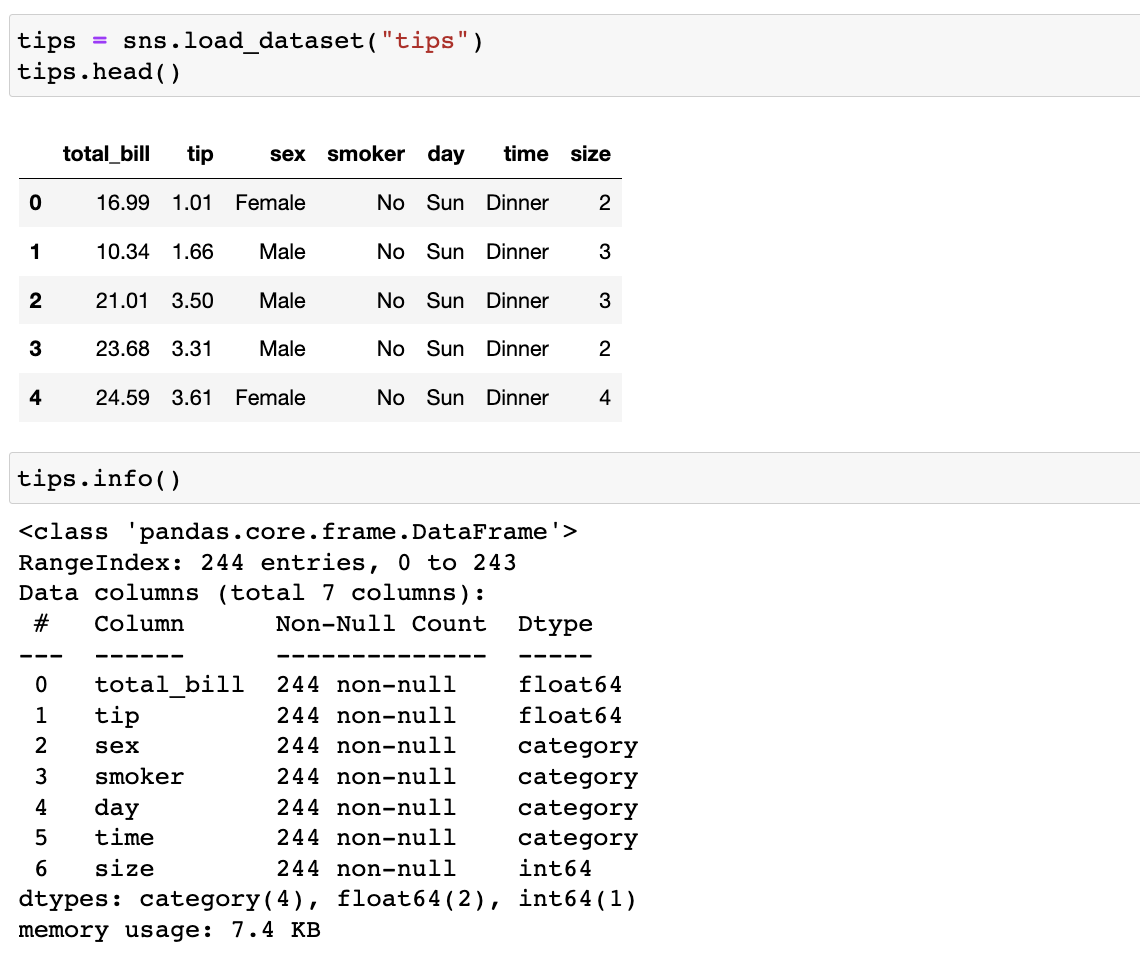
seaborn에 사용할 데이터 tips에 담기
📍 boxplot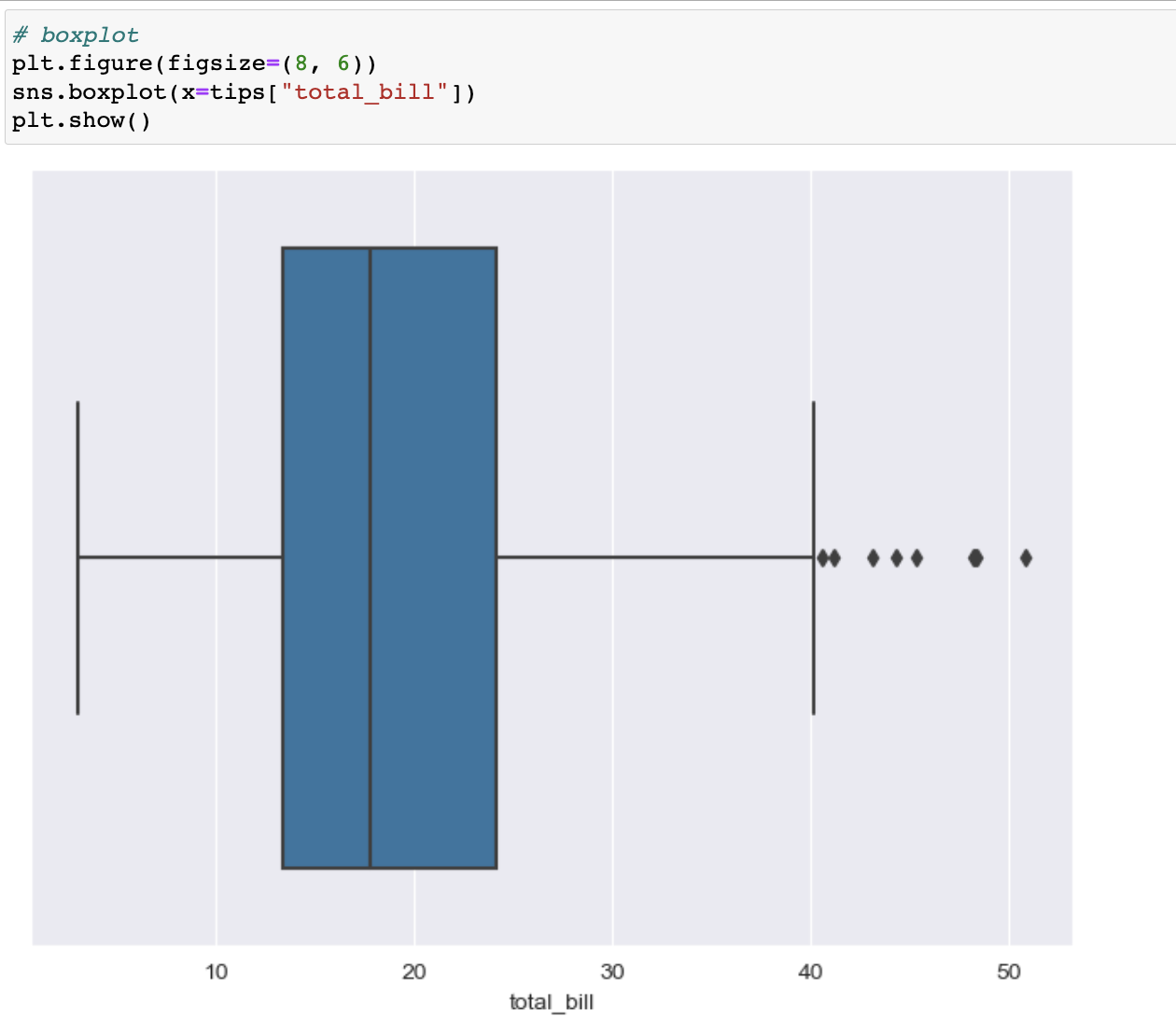
-
day, total_bill이용한 boxplot만들기
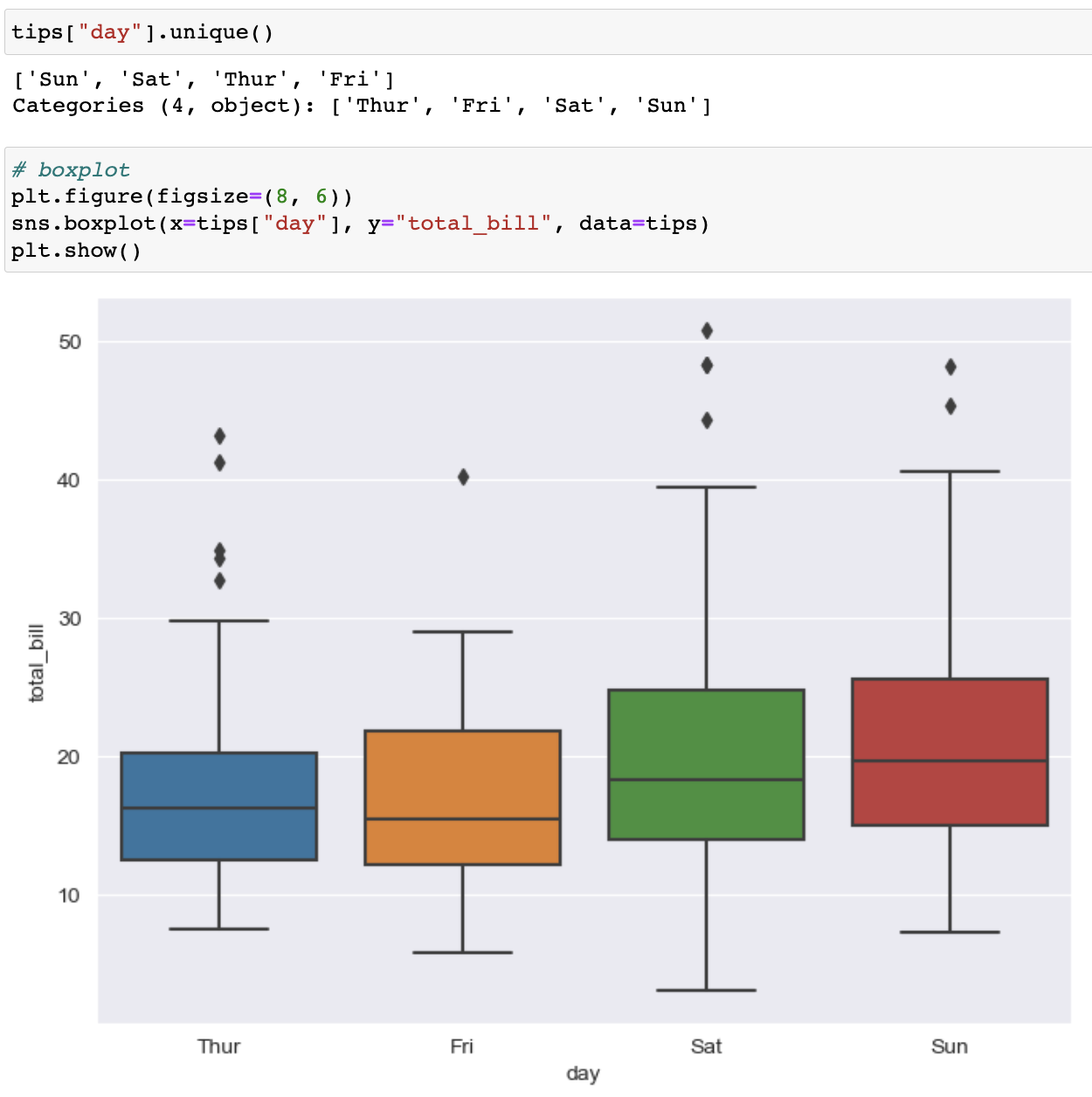
-
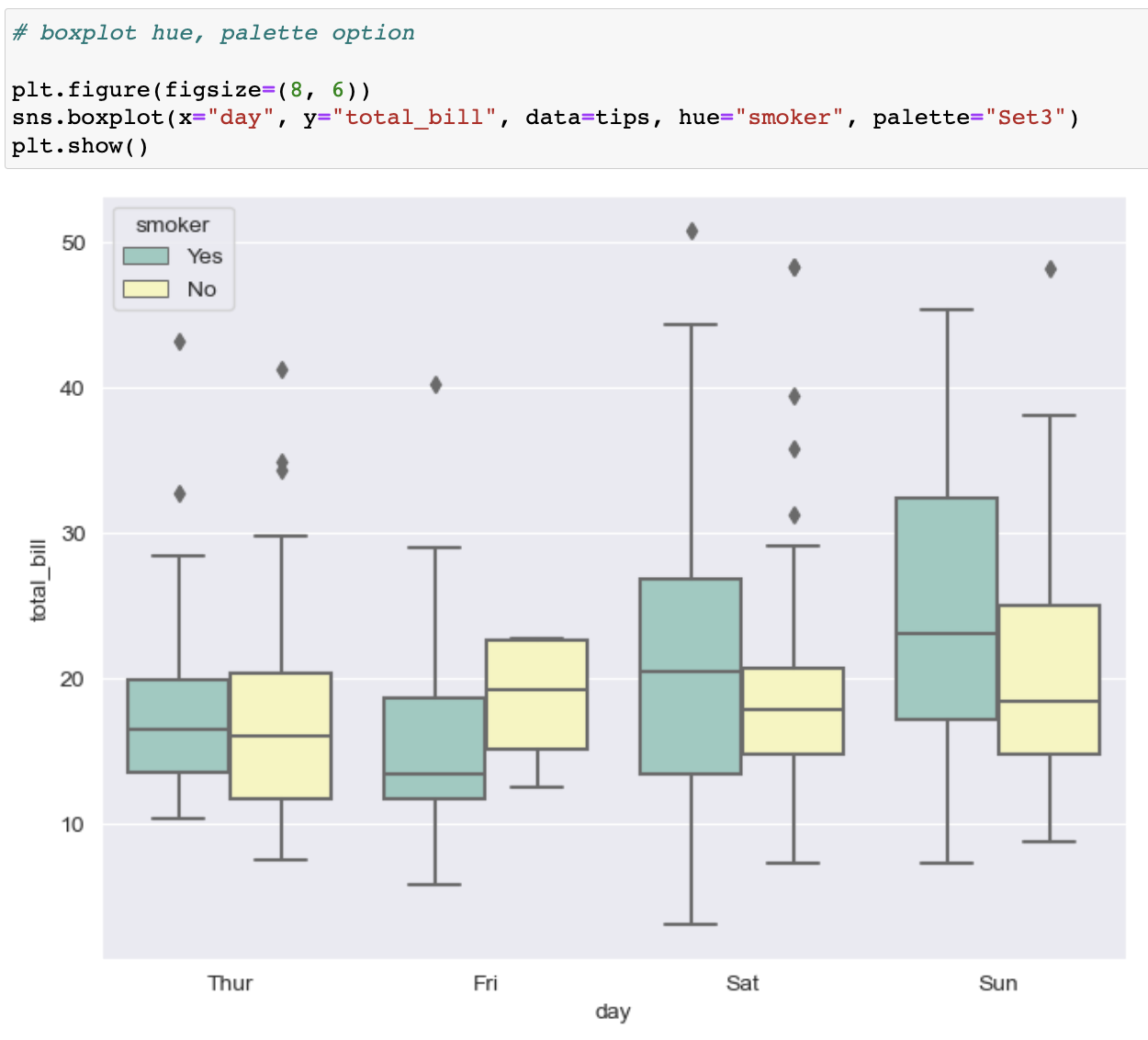
boxplot hue option
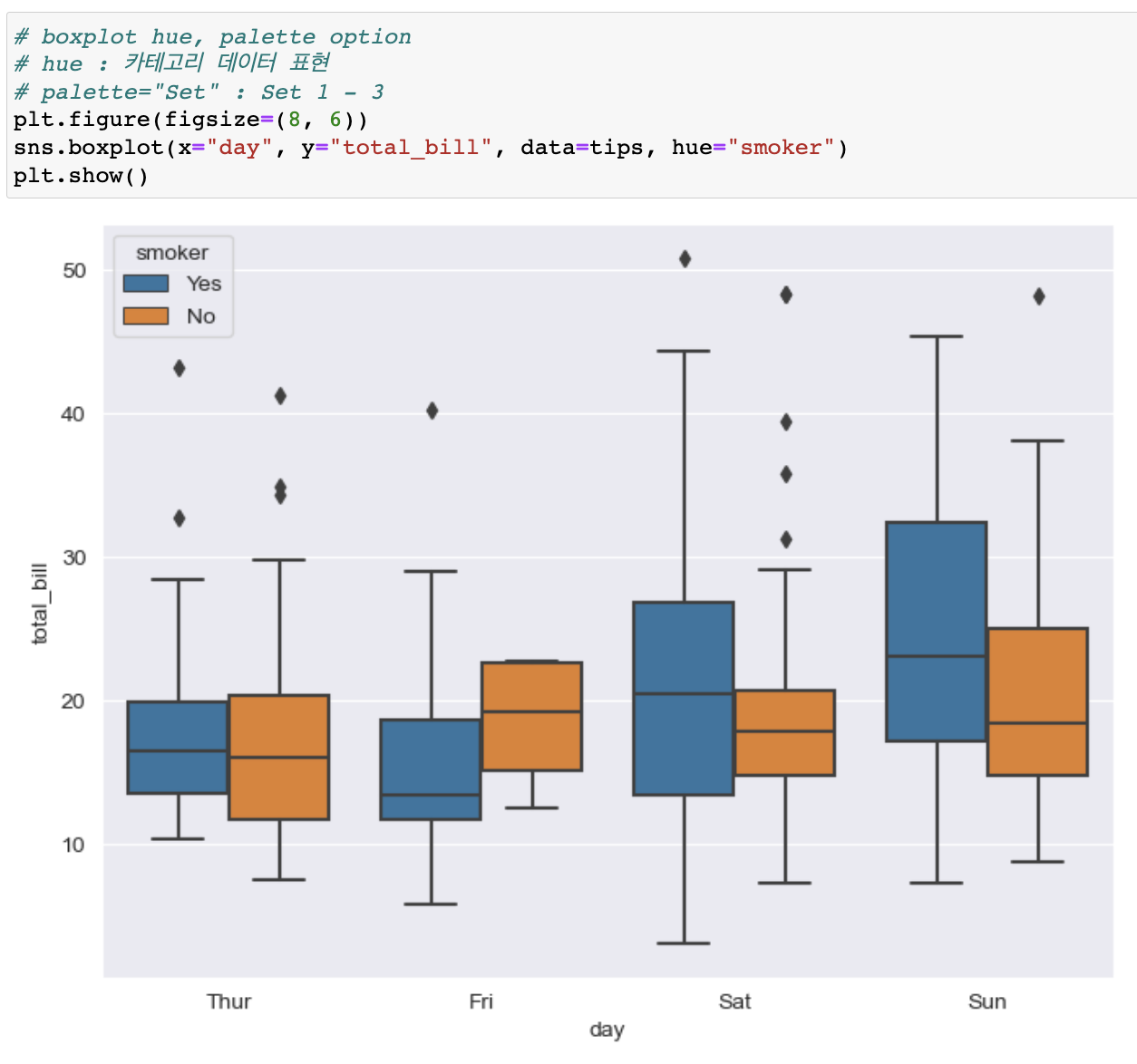
boxplot hue, palette 옵션
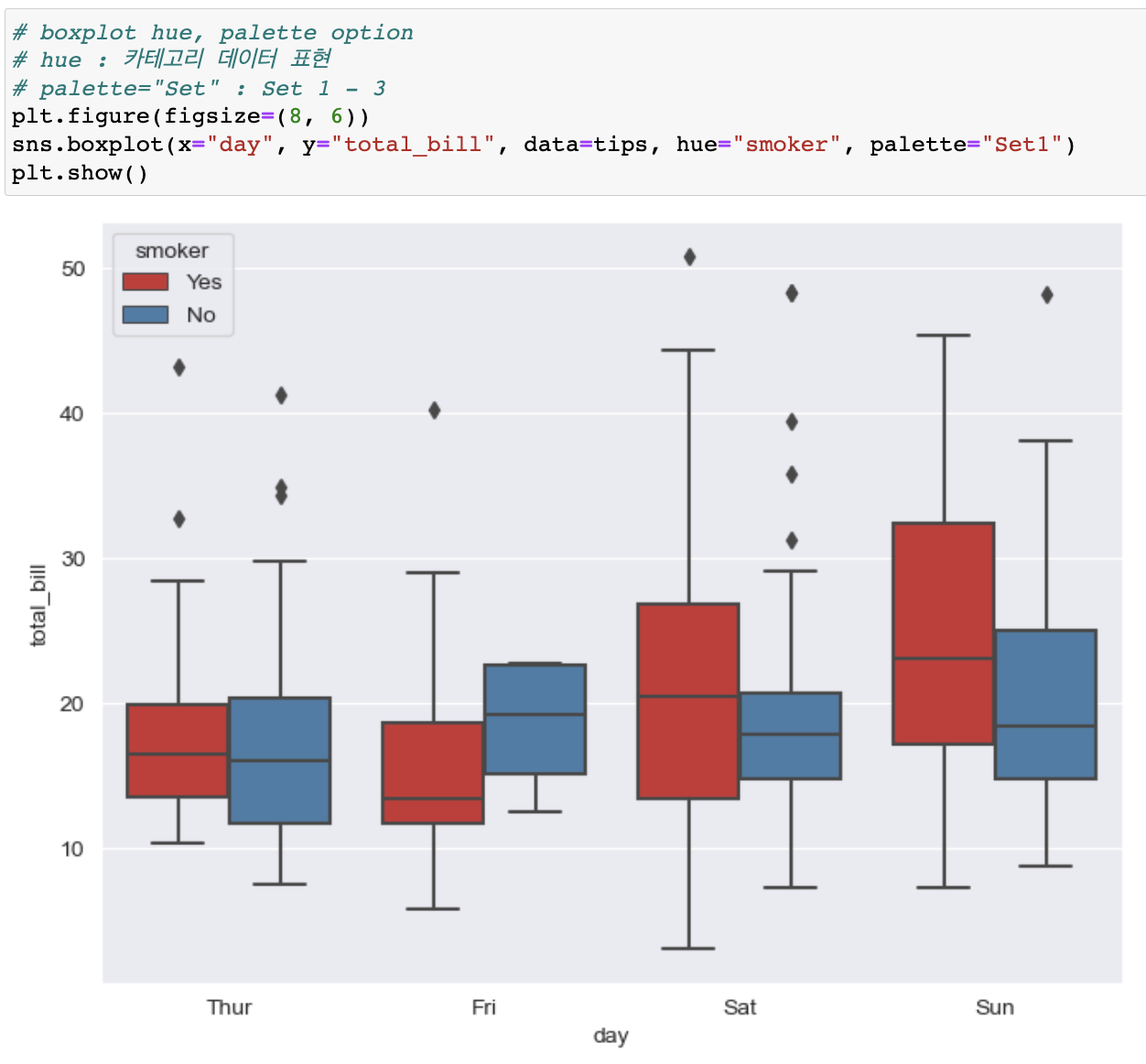
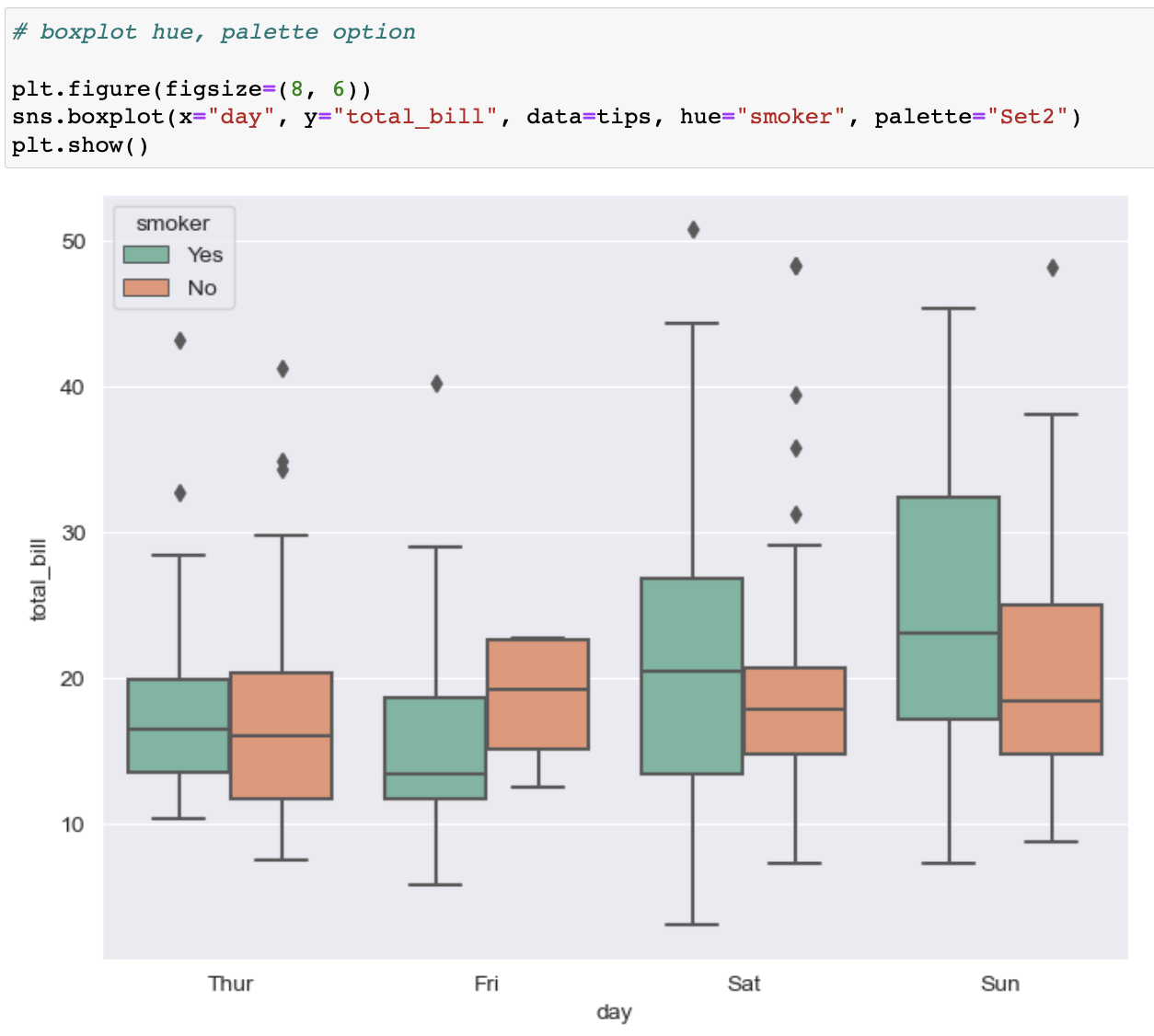
📍 swarmplot
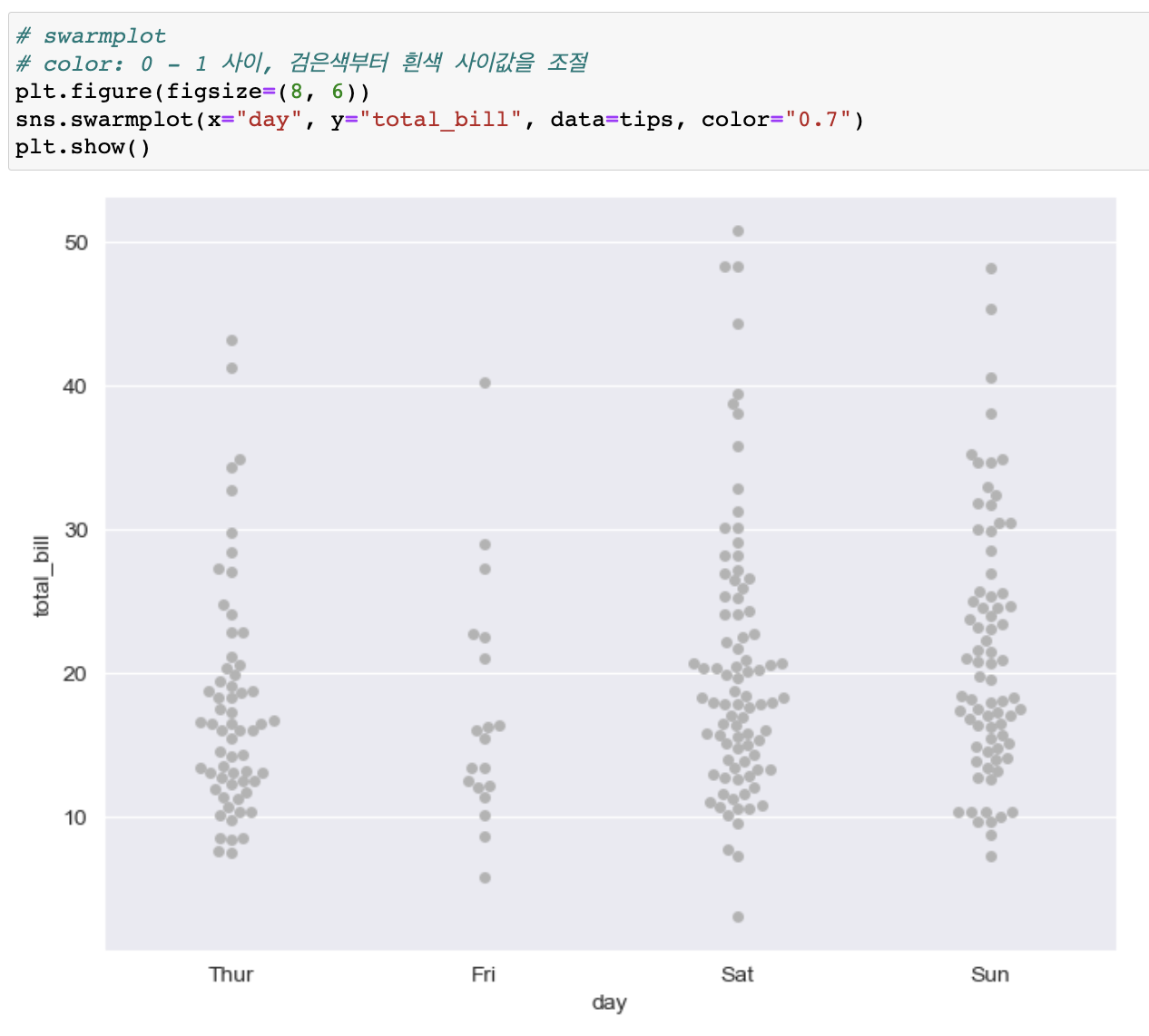
swarmplot
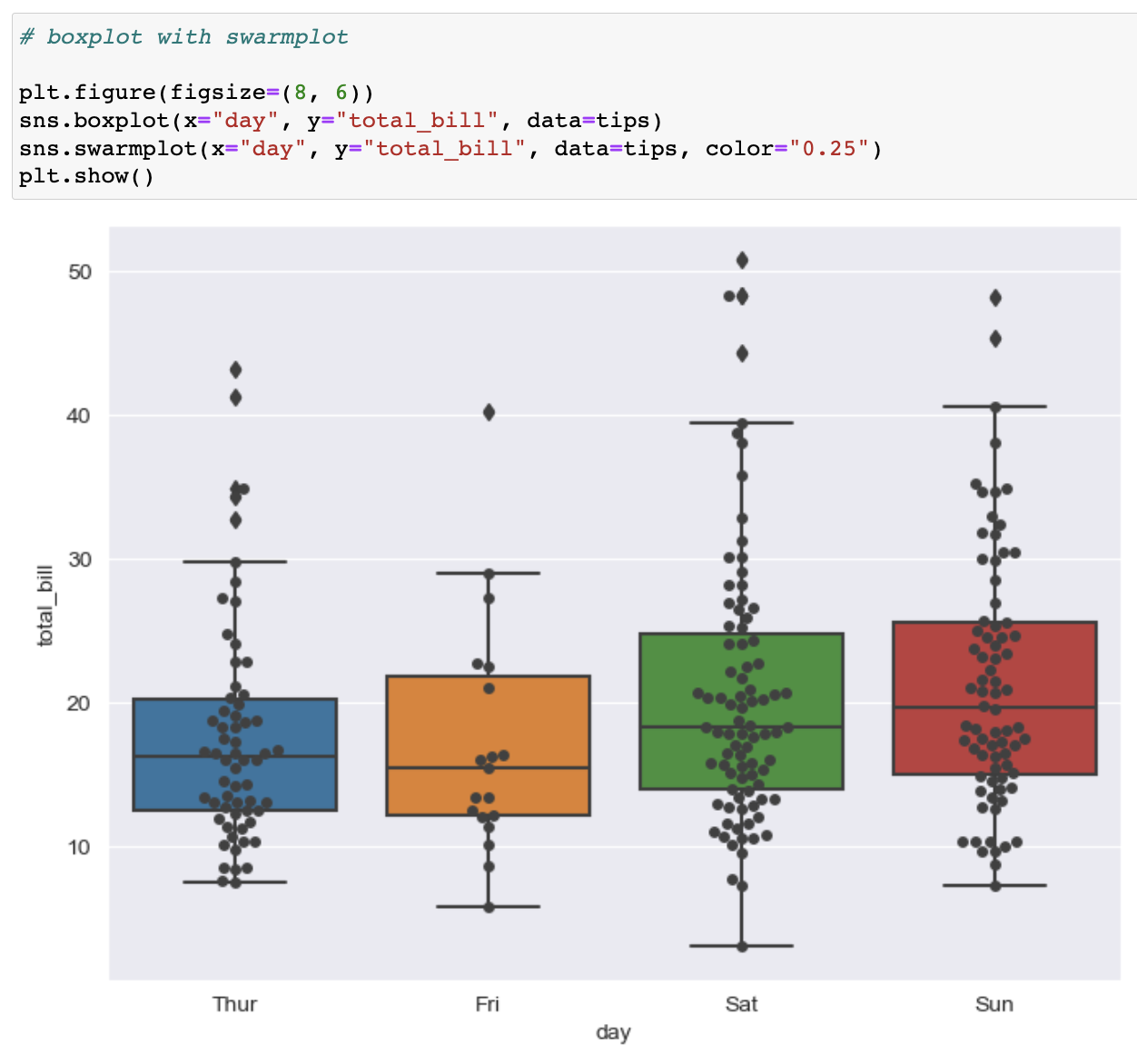
boxplot + swarmplot
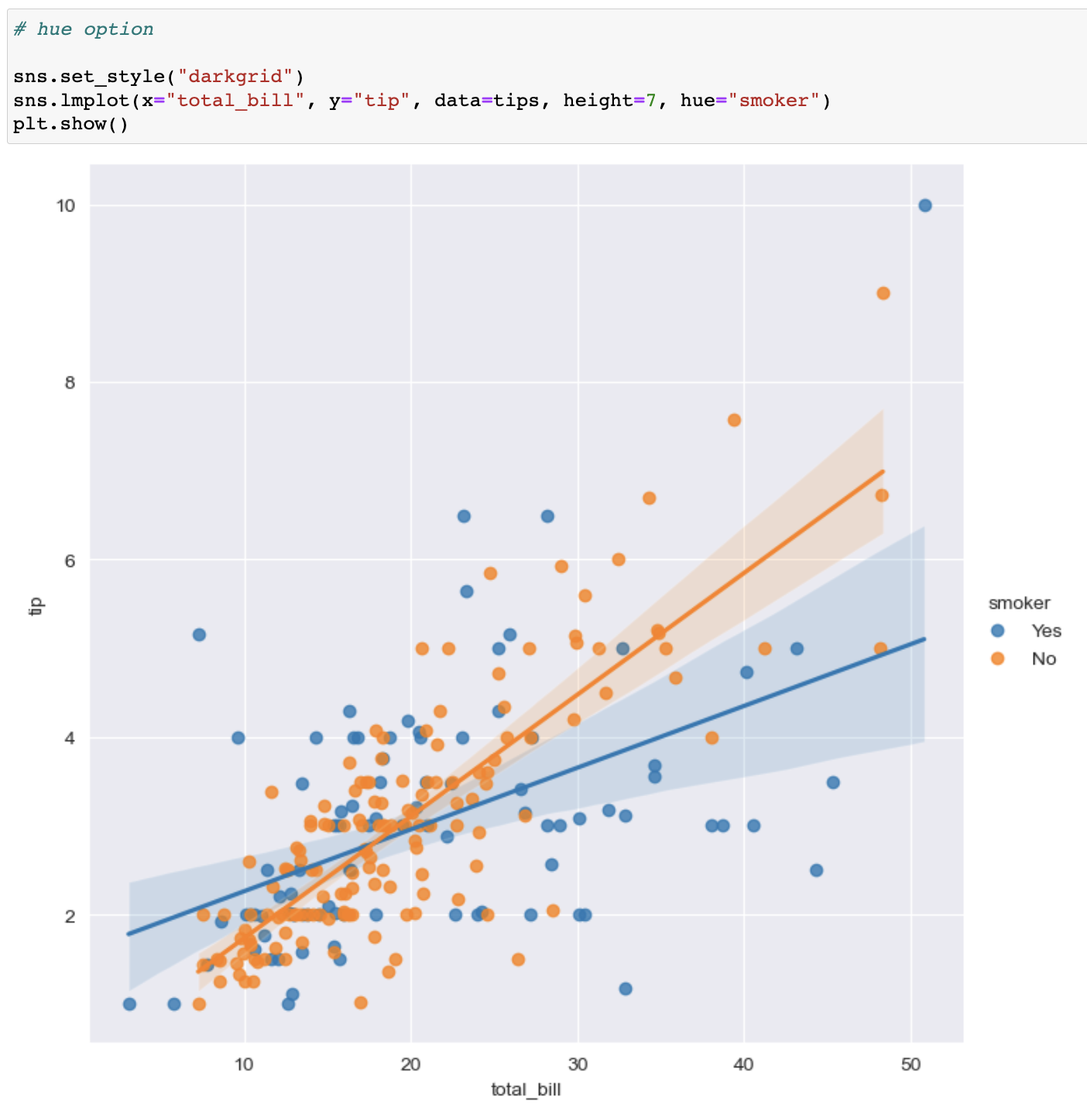
📍 lmplot
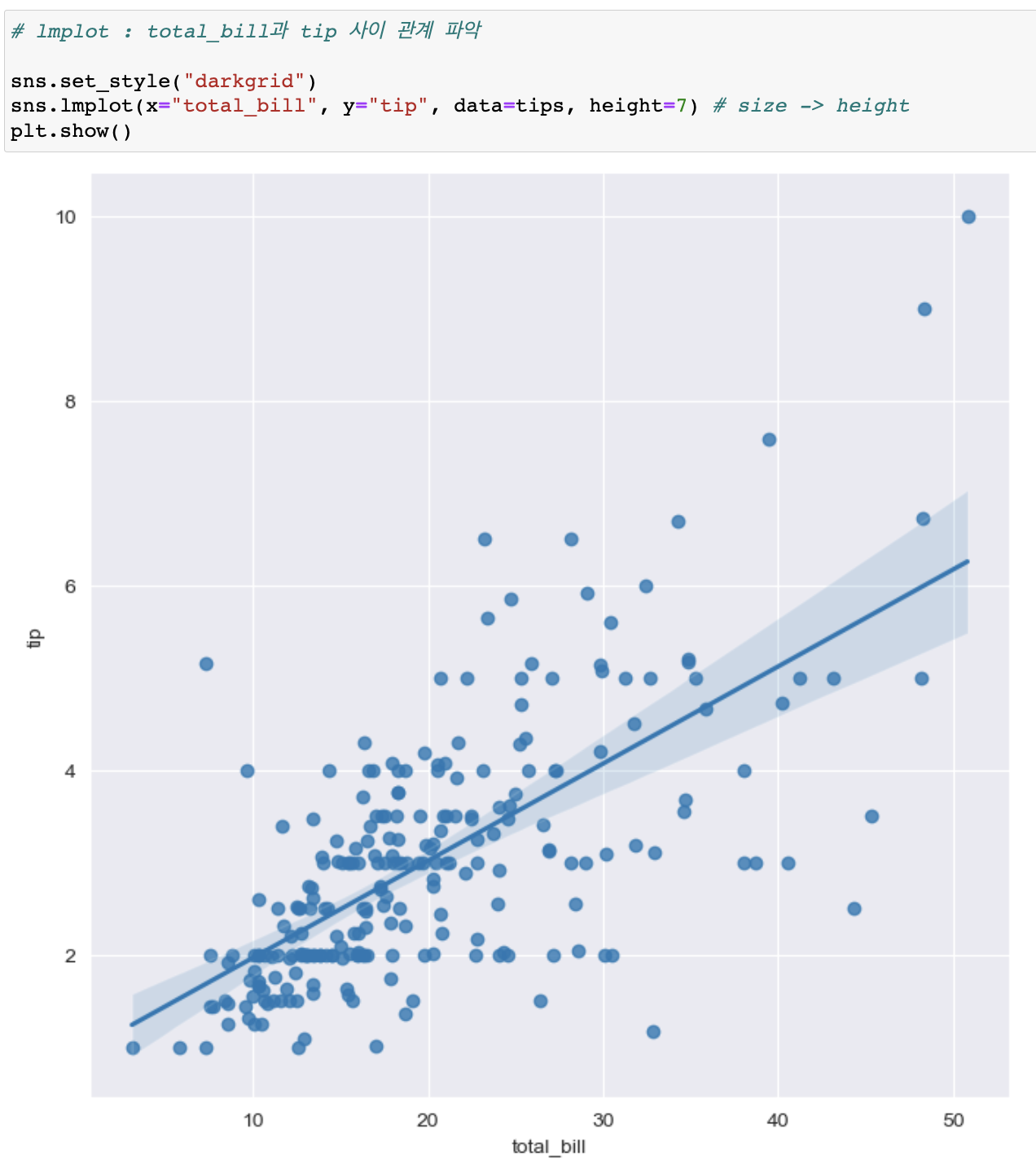
lmplot
lmplot에 hue 옵션 적용
예제 3 : flights data
-
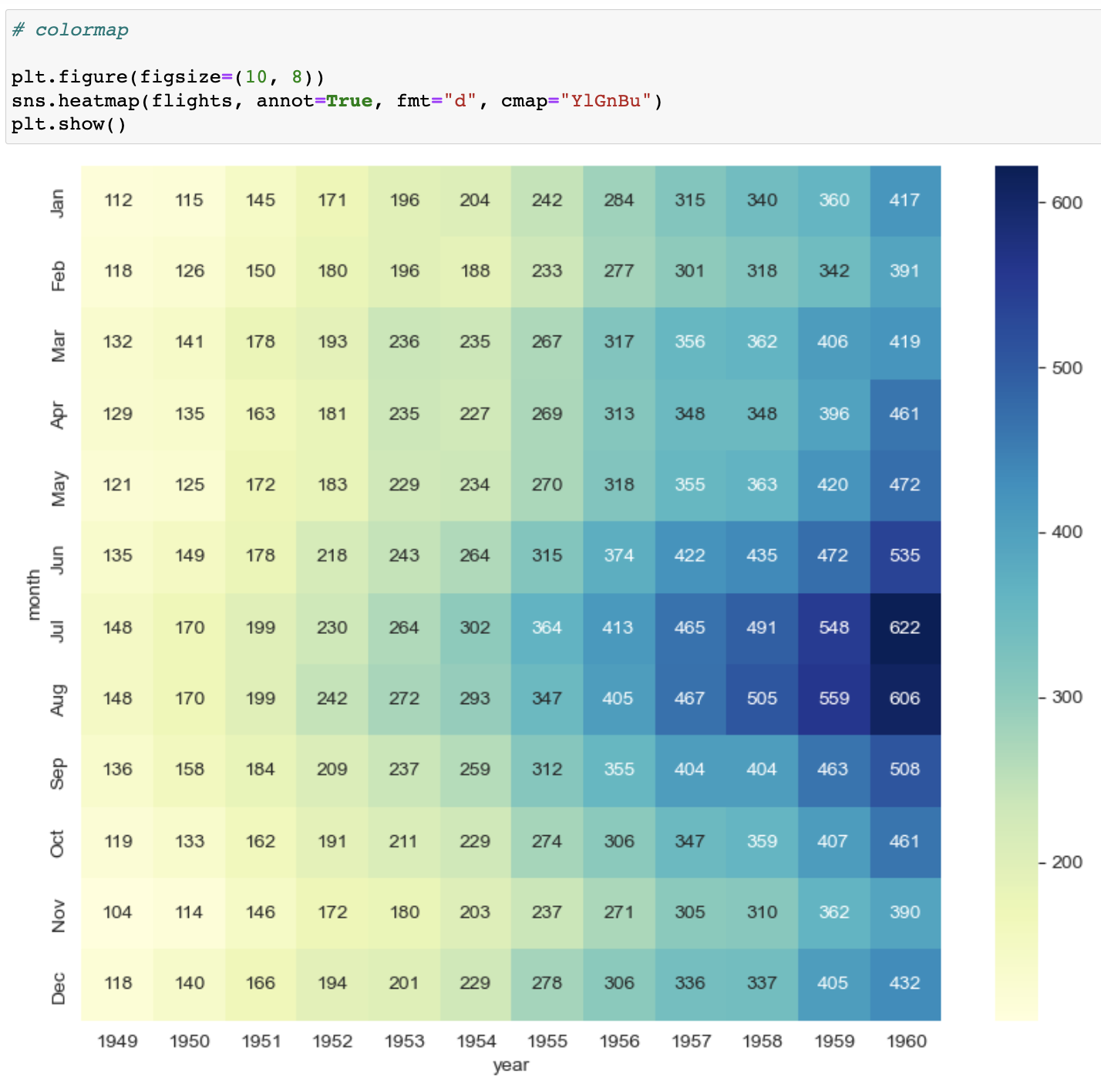
heatmap
-
seaborn작업할 데이터 flights에 넣고 pivot
-
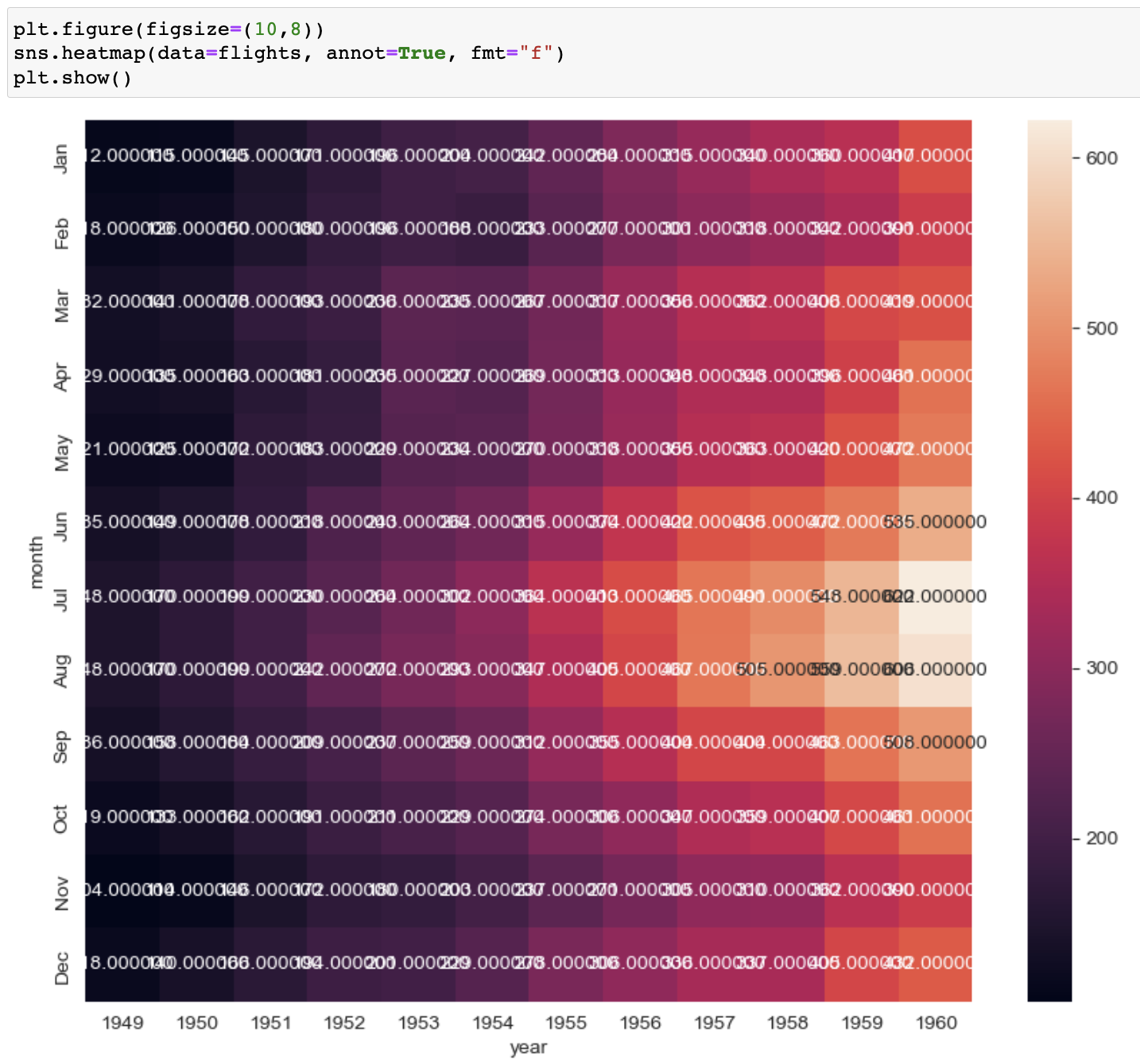
heatmap
sns.heatmap(data=flights, annot=True, fmt="d"
data=flights --> 데이터는 flights 사용
annot=True --> 그래프 내부에 수치를 표시해라
annot=False --> 그래프 내부에 수치를 표시하지 말아라
fmt = "d" --> 그래프에 표시하는 데이터를 'd'정수로 해라
fmt = "f" --> 그래프에 표시하는 데이터를 'f'실수로 해라
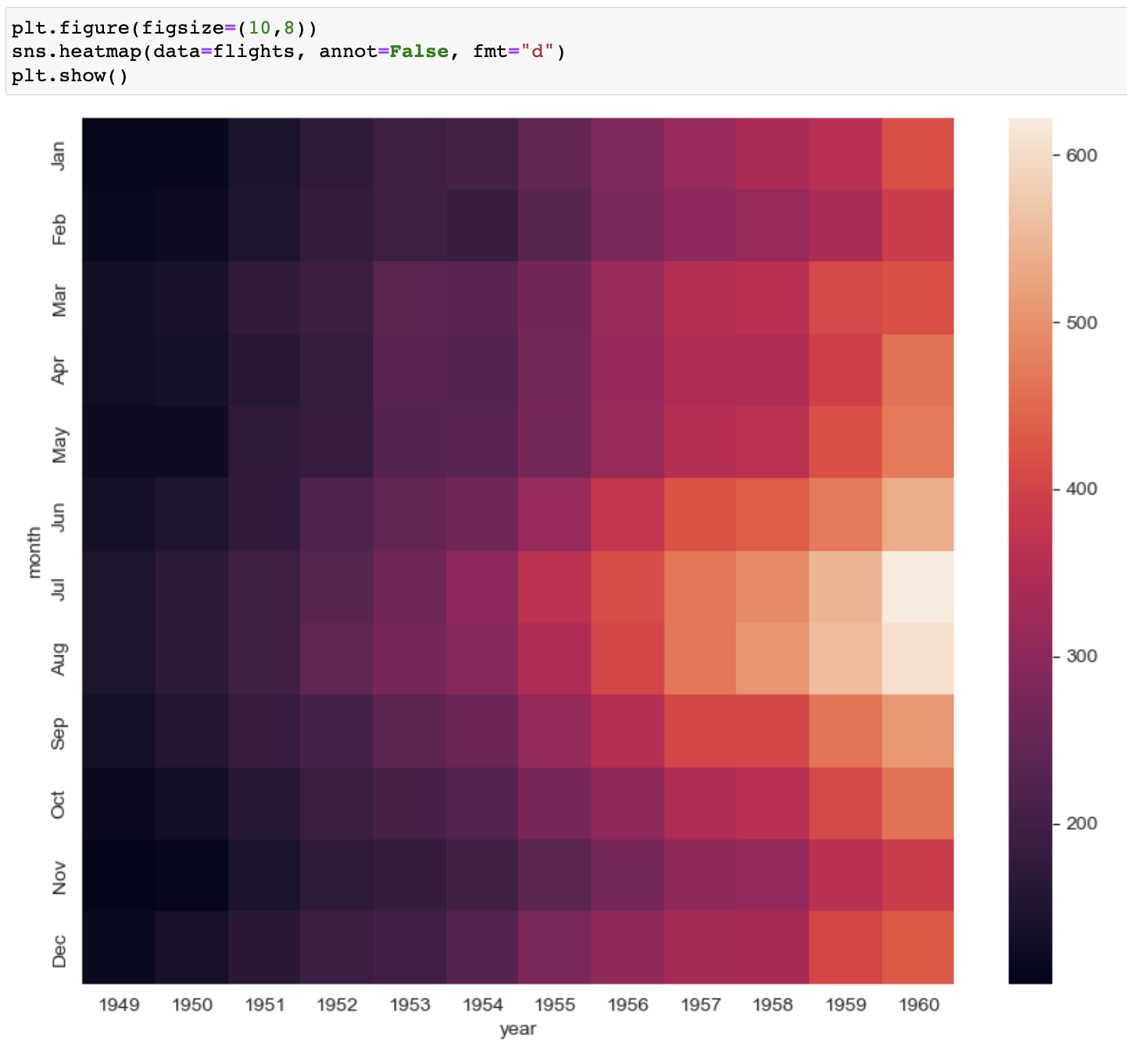
- colormap ( cmap = "") --> 컬러주소는 검색하면 나옴
예제4 : iris data
-
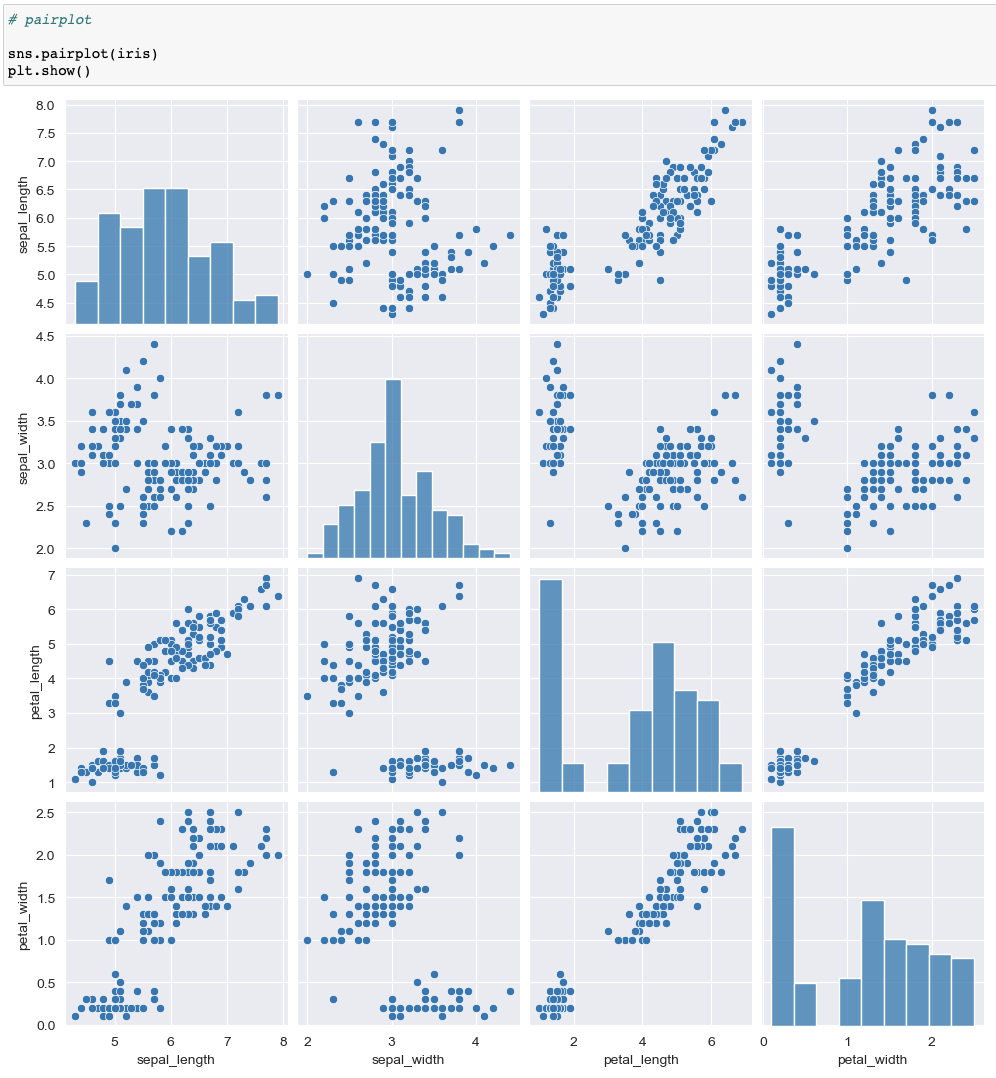
pairplot
-
데이터 정보 알아보기 (iris.info() 가능)
-
pairplot
-
기본 style
-
sns.set_style("ticks")
(ticks style)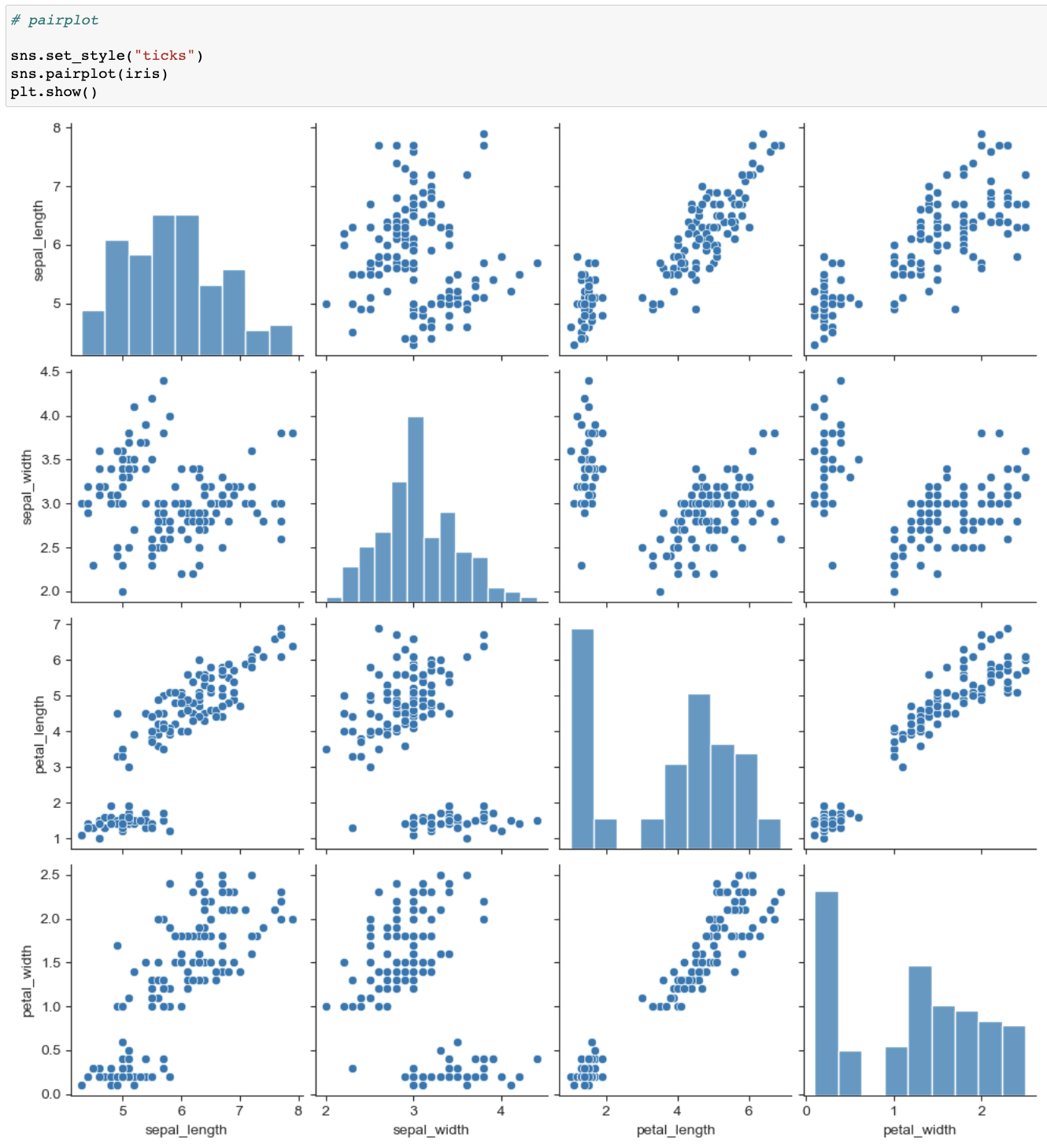
-
pairplot의 hue option
-
sns.pairplot(iris, hue="species")
(iris의 species컬럼을 이용한 hue option)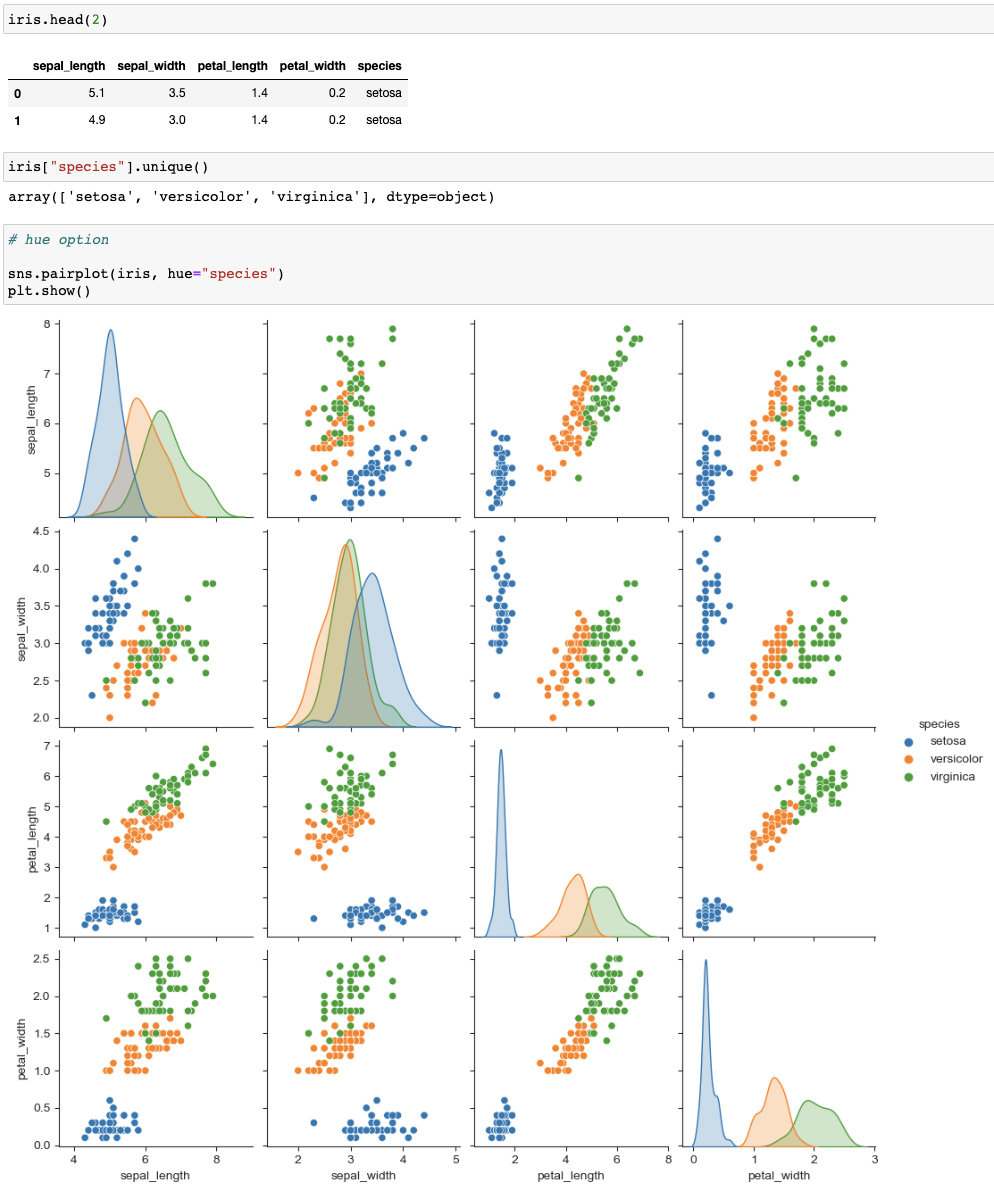
-
원하는 컬럼만 pairplot
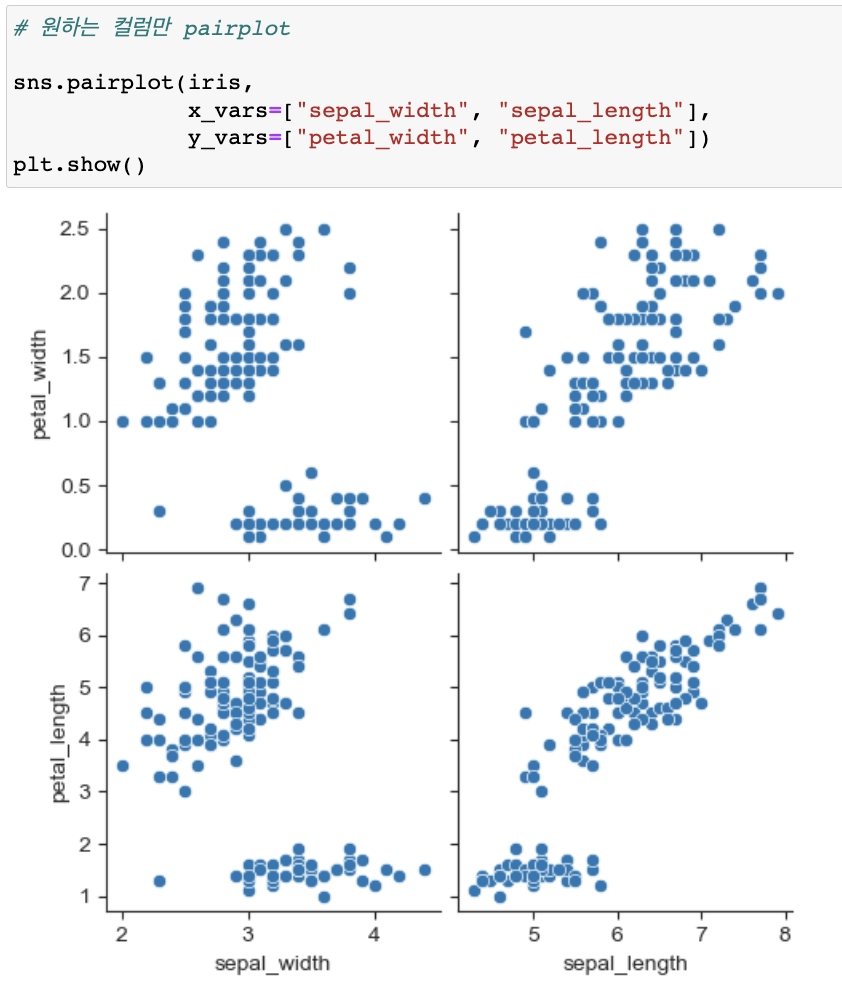
예제5 : anscombe data
-
lmplot
-
lmplot 그래프그리기
(용어 변경 size --> height로 변경)
sns.lmplot(
x="x", y="y",
data=anscombe.query("dataset == 'I'"),
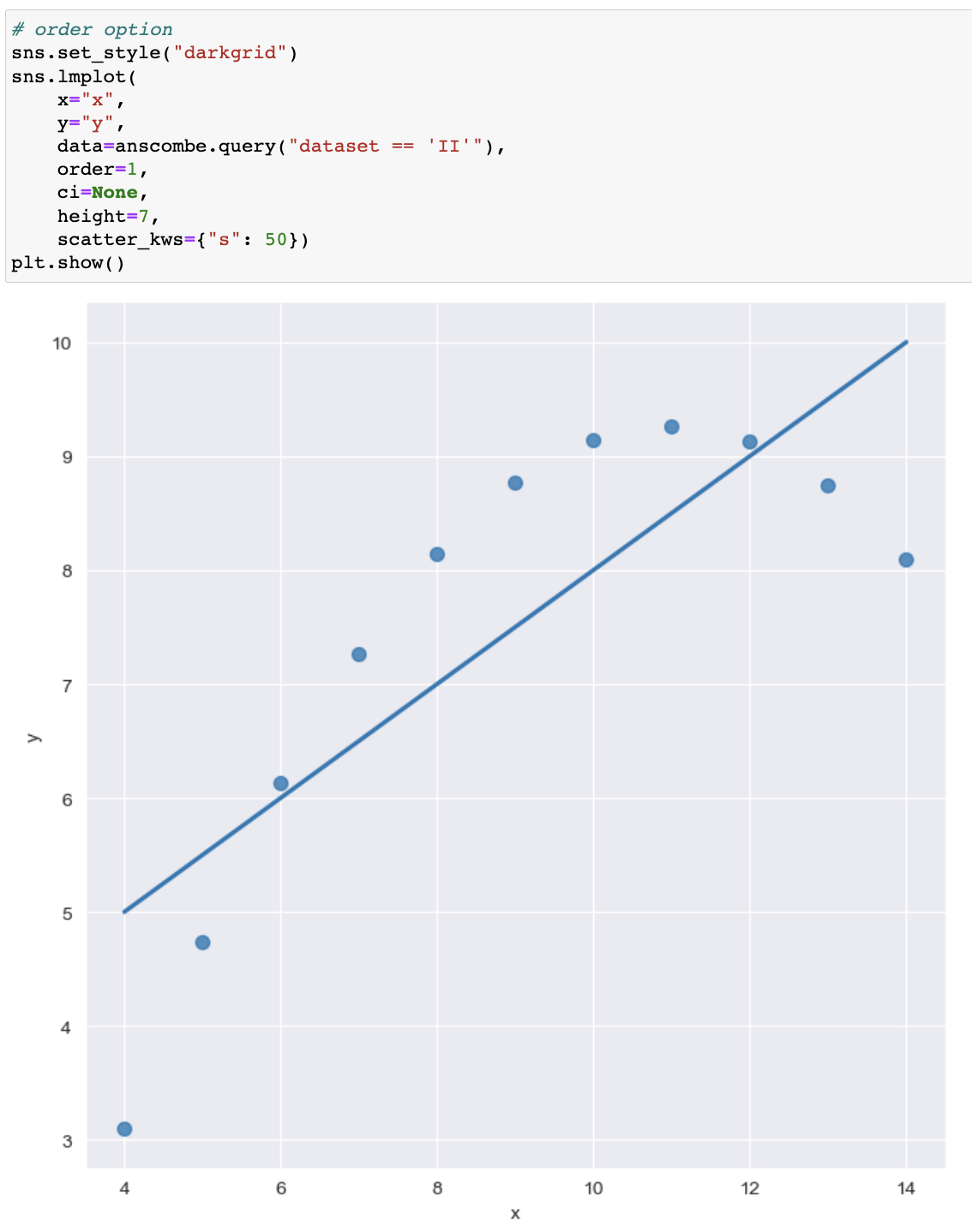
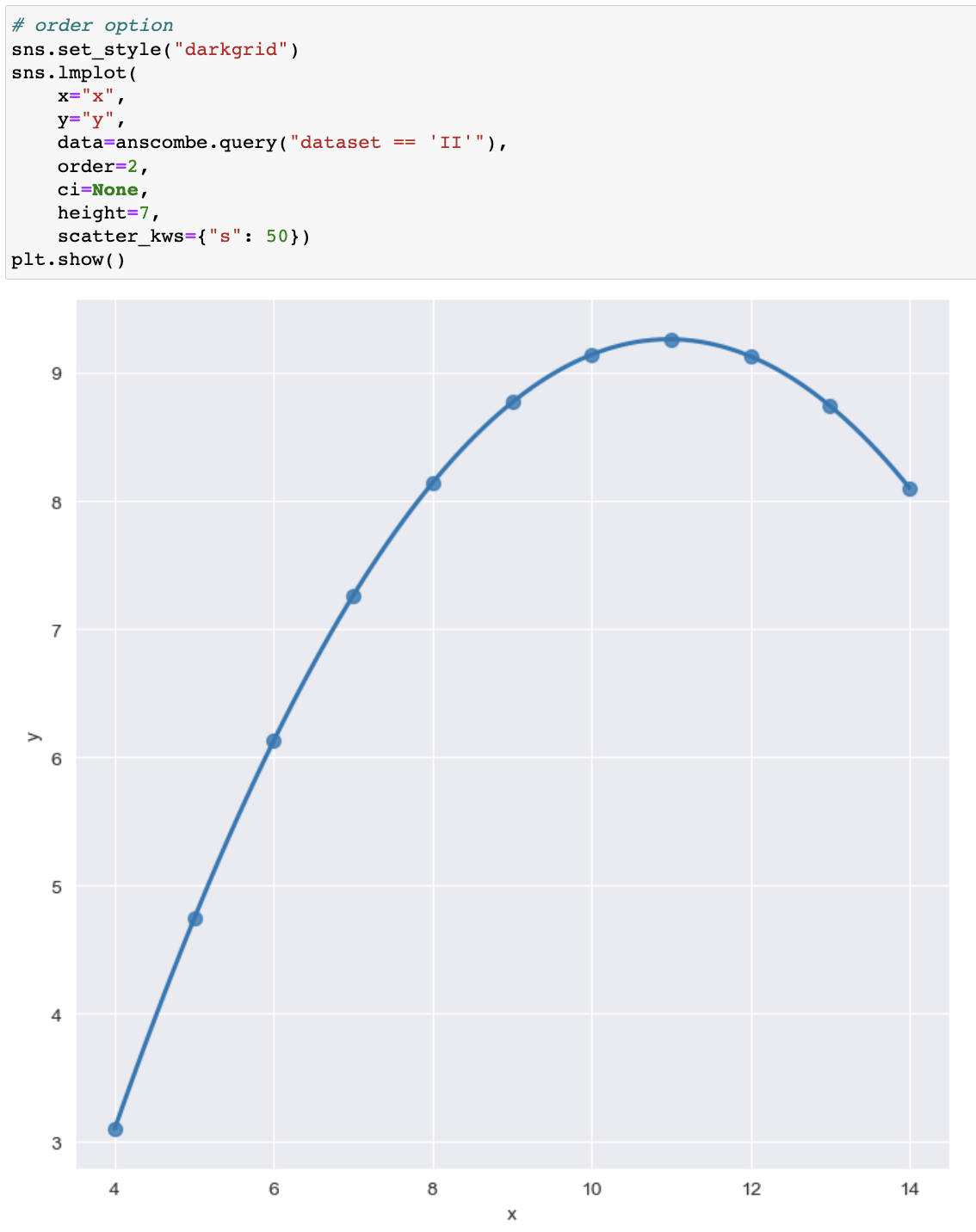
order=1
ci=None,
height=7,
scatter_kws={"s" : 50})
# ci -> 신뢰구간선택
# scatter _kws = {"s" : 50} -> scatter점 사이즈 50으로
# order=1 or 2 -> 직선곡률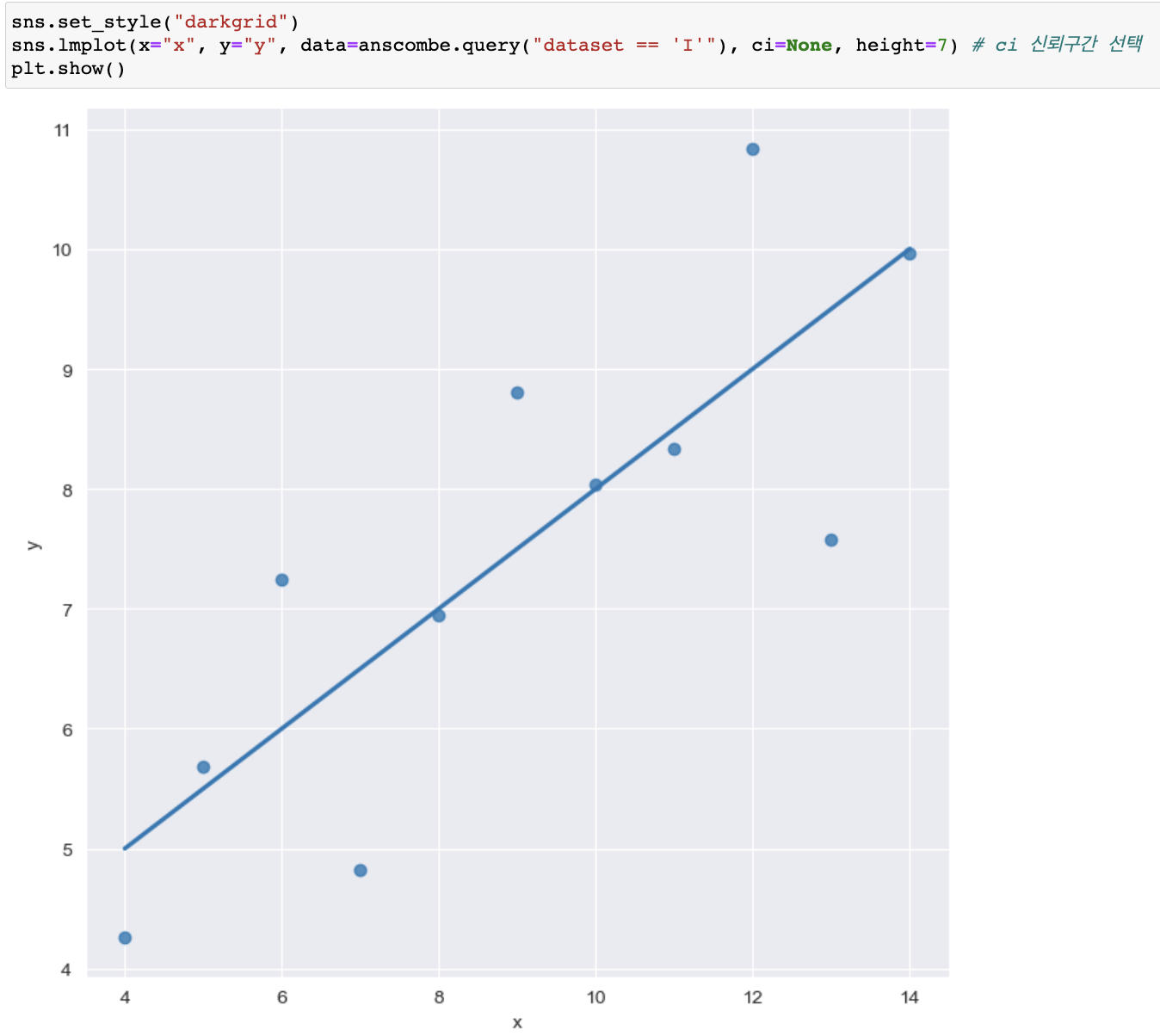
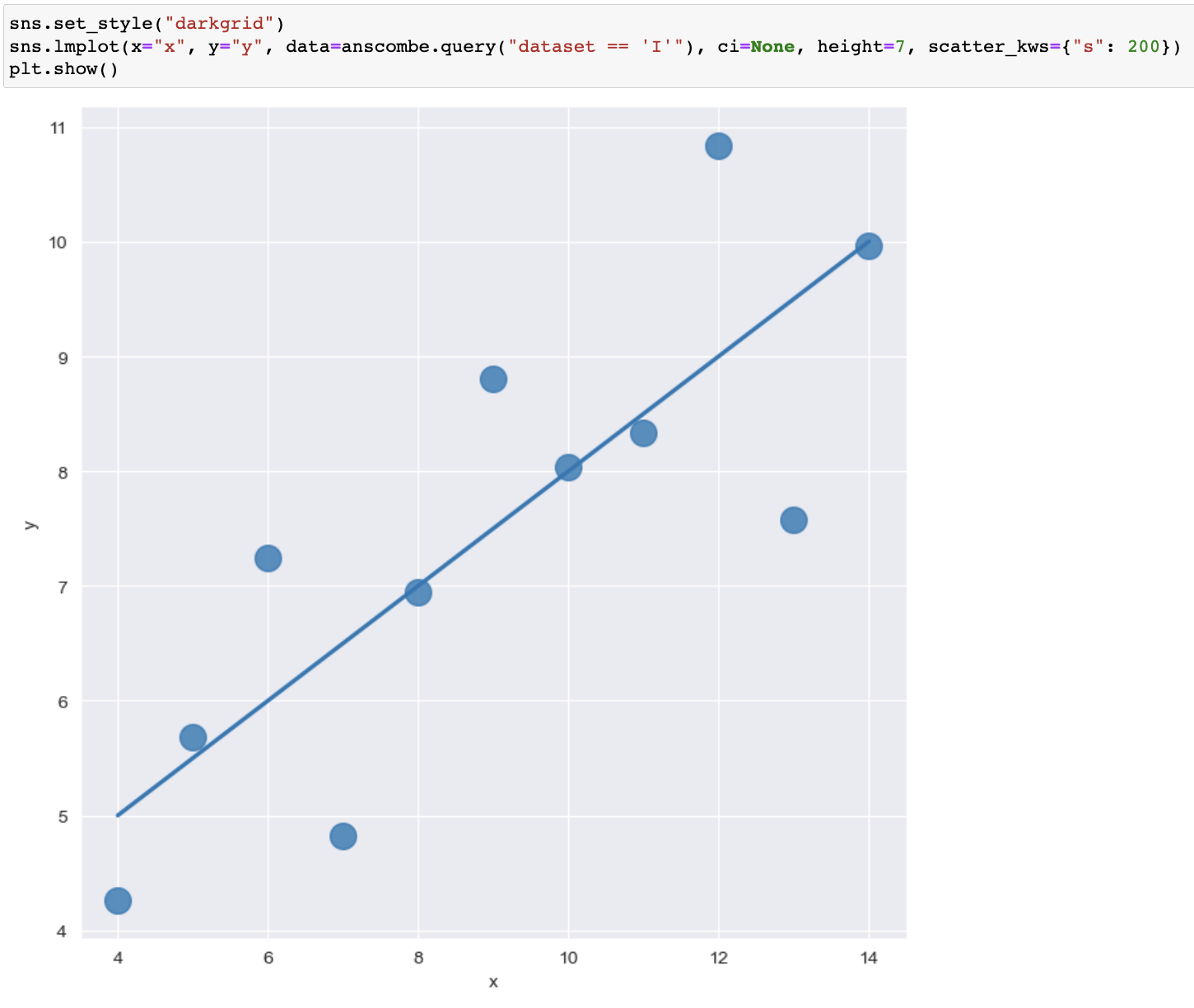
- 라인곡률 order
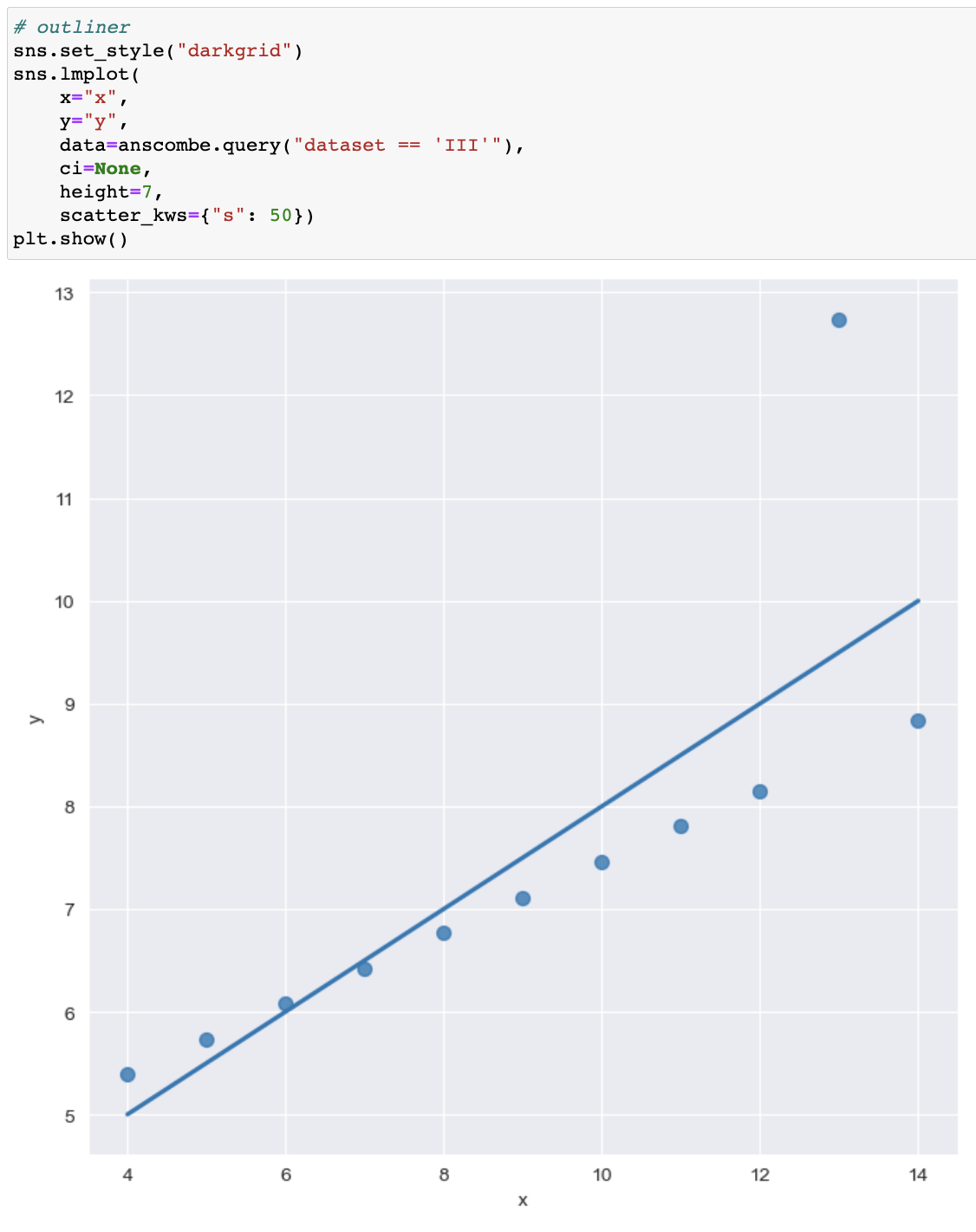
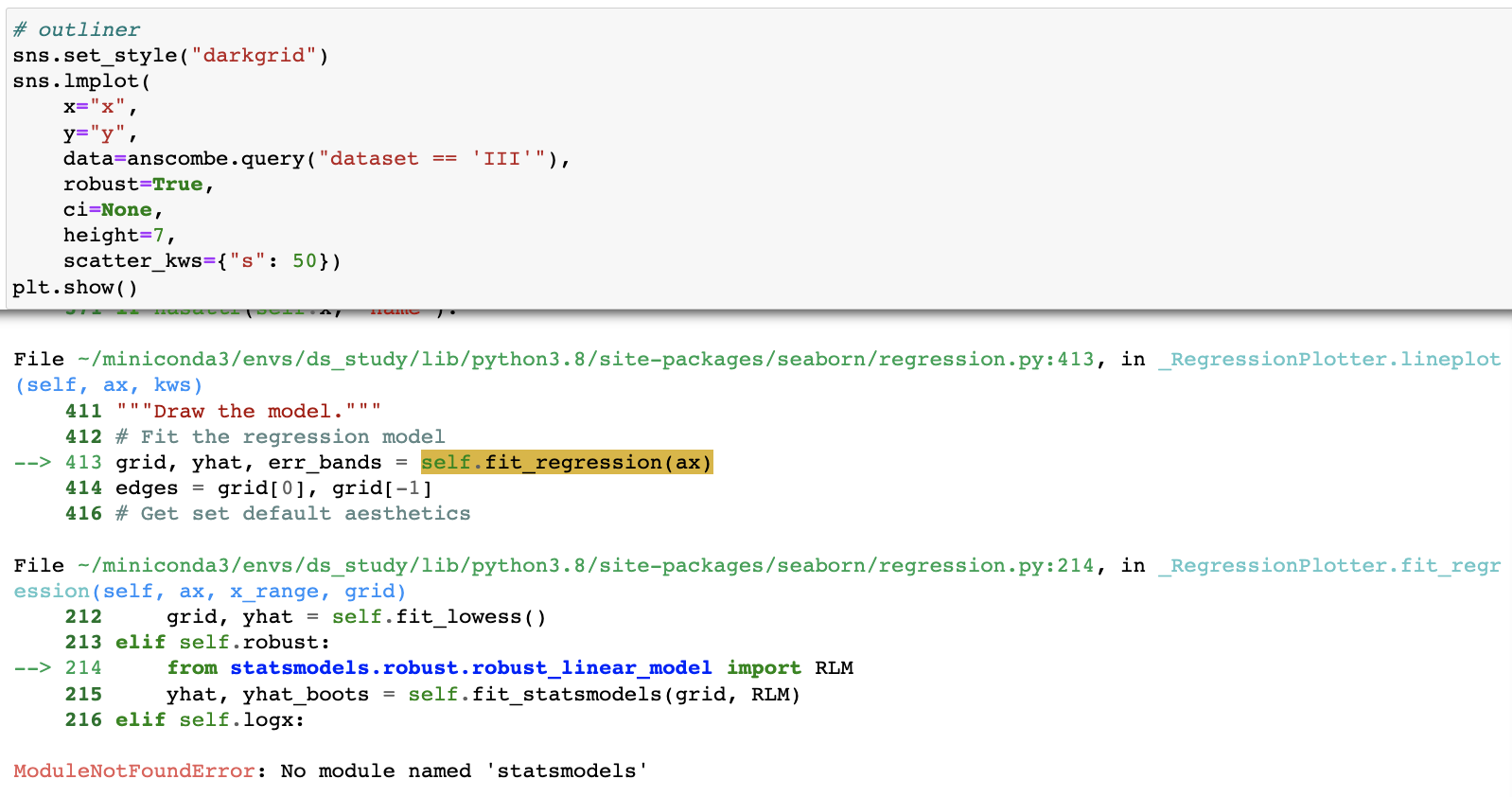
- outliner 현재 ("no module named statemodules")오류
9. 서울시 범죄현황 데이터 시각화
-
전 단계에서 정리된 표 불러오기
( import & 한글오류 작업 )
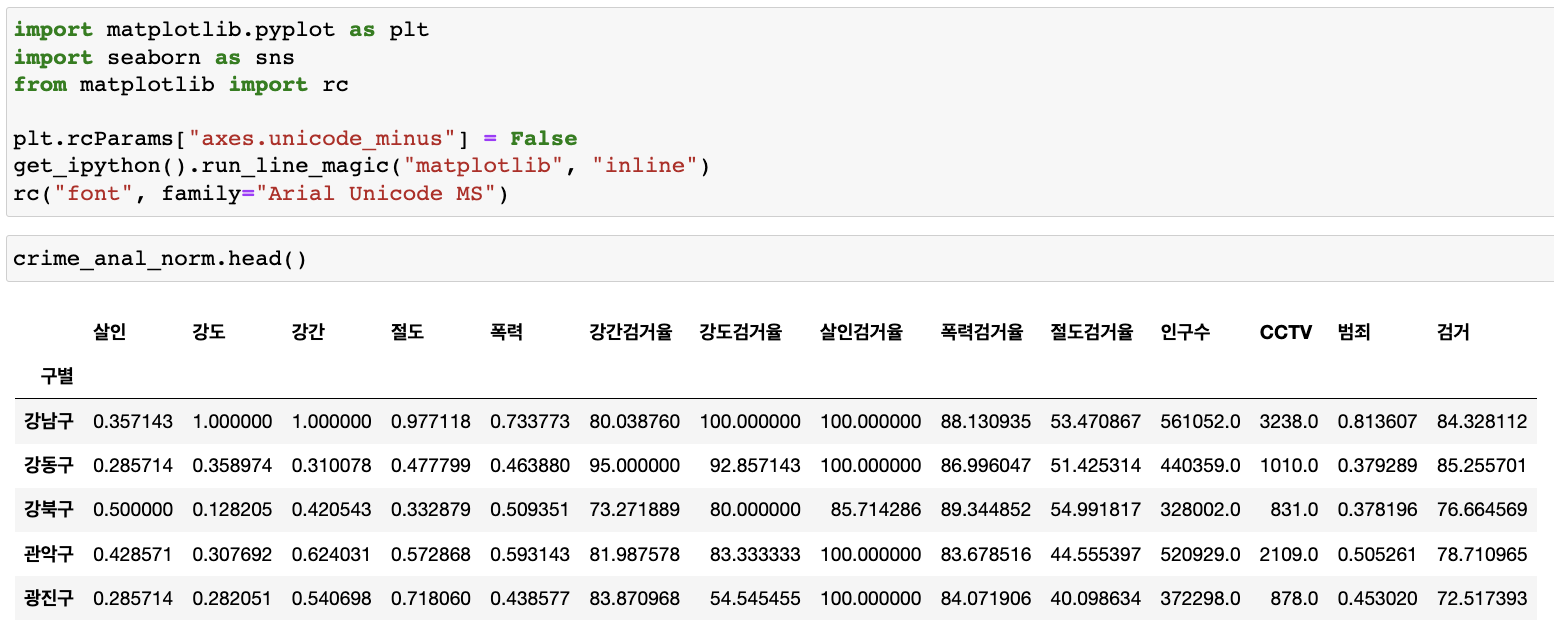
-
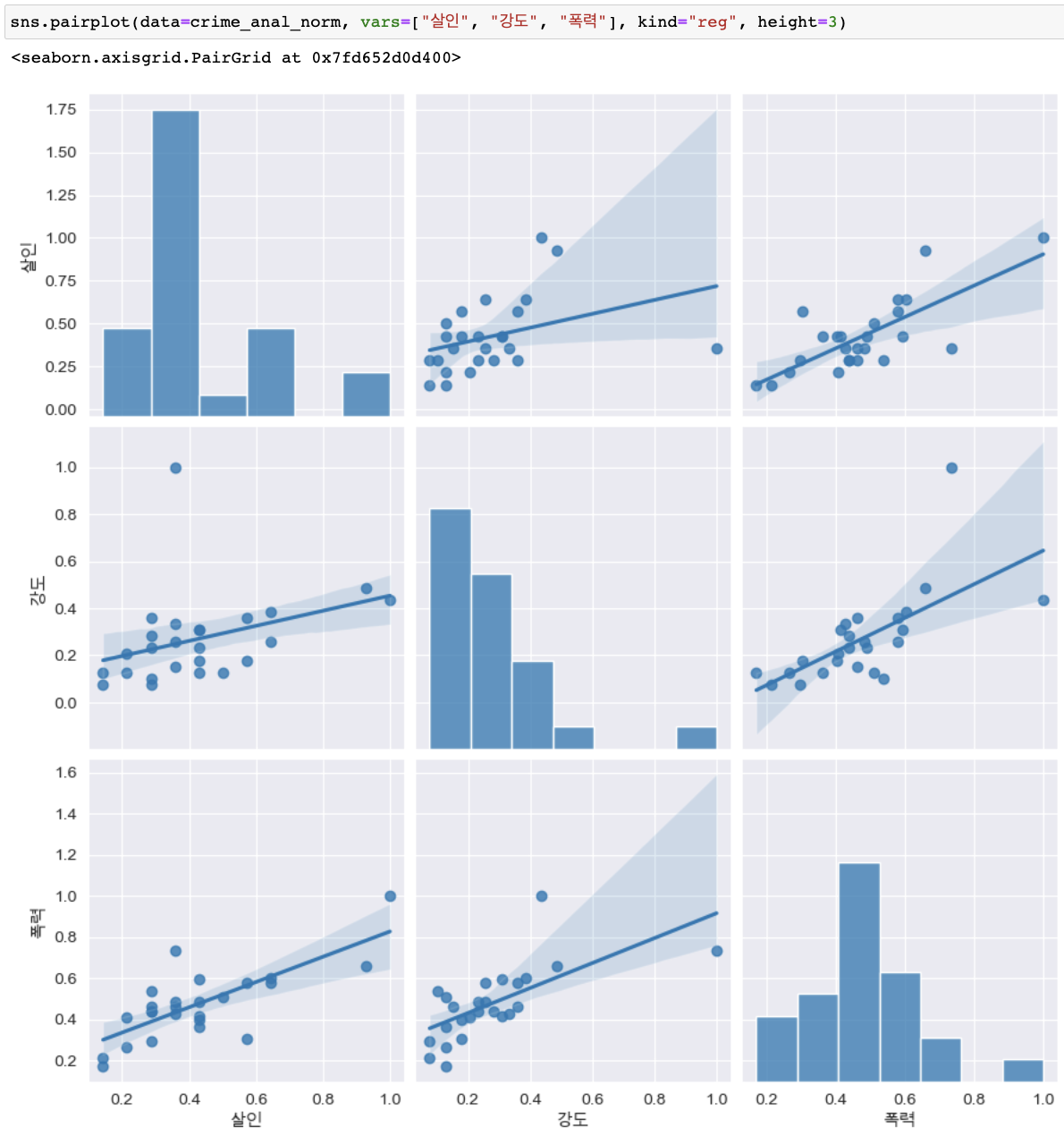
pairplot 자료의 상관관계 확인
(kind종류 : "scatter", "kde", "hist", "reg")
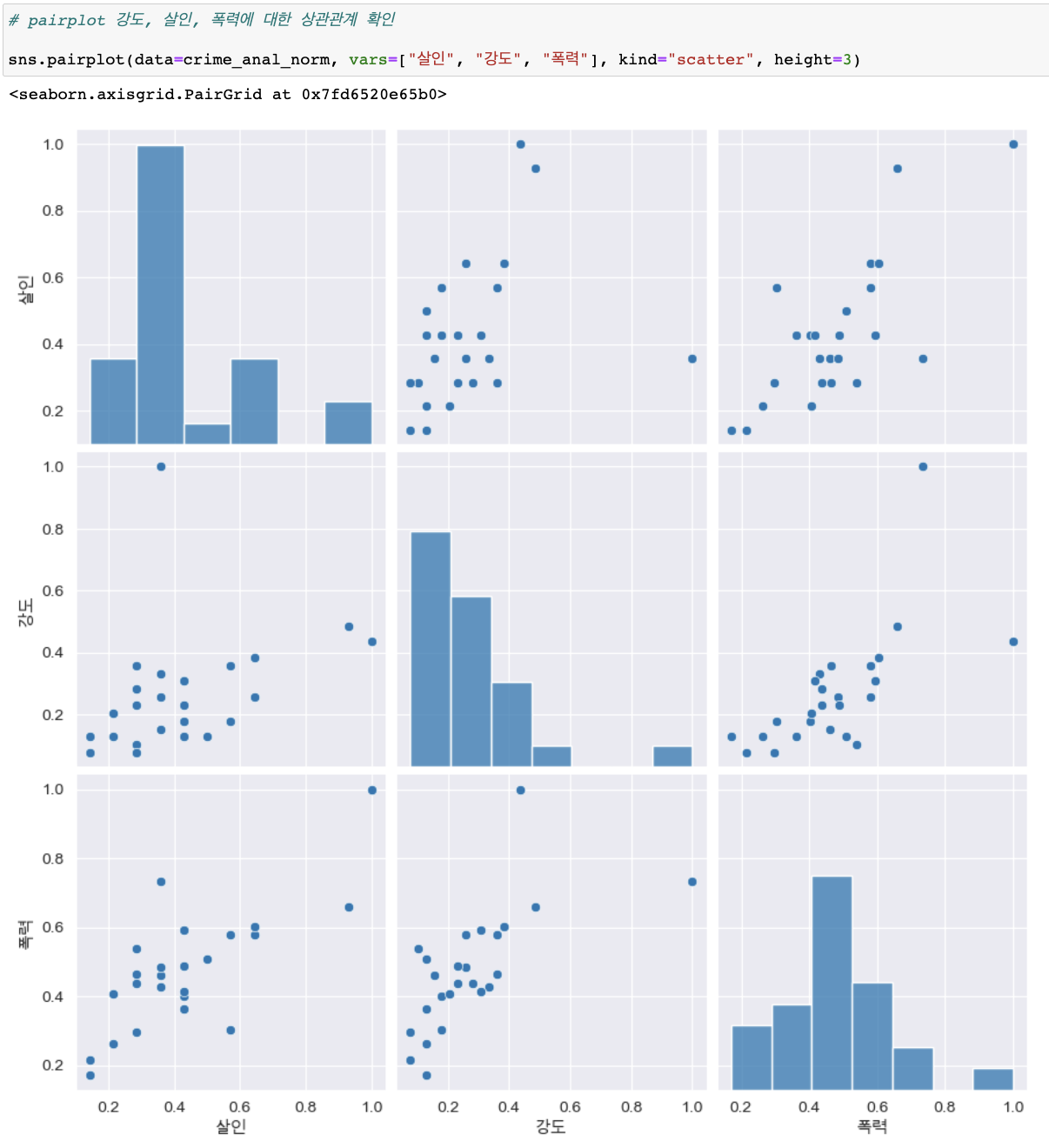
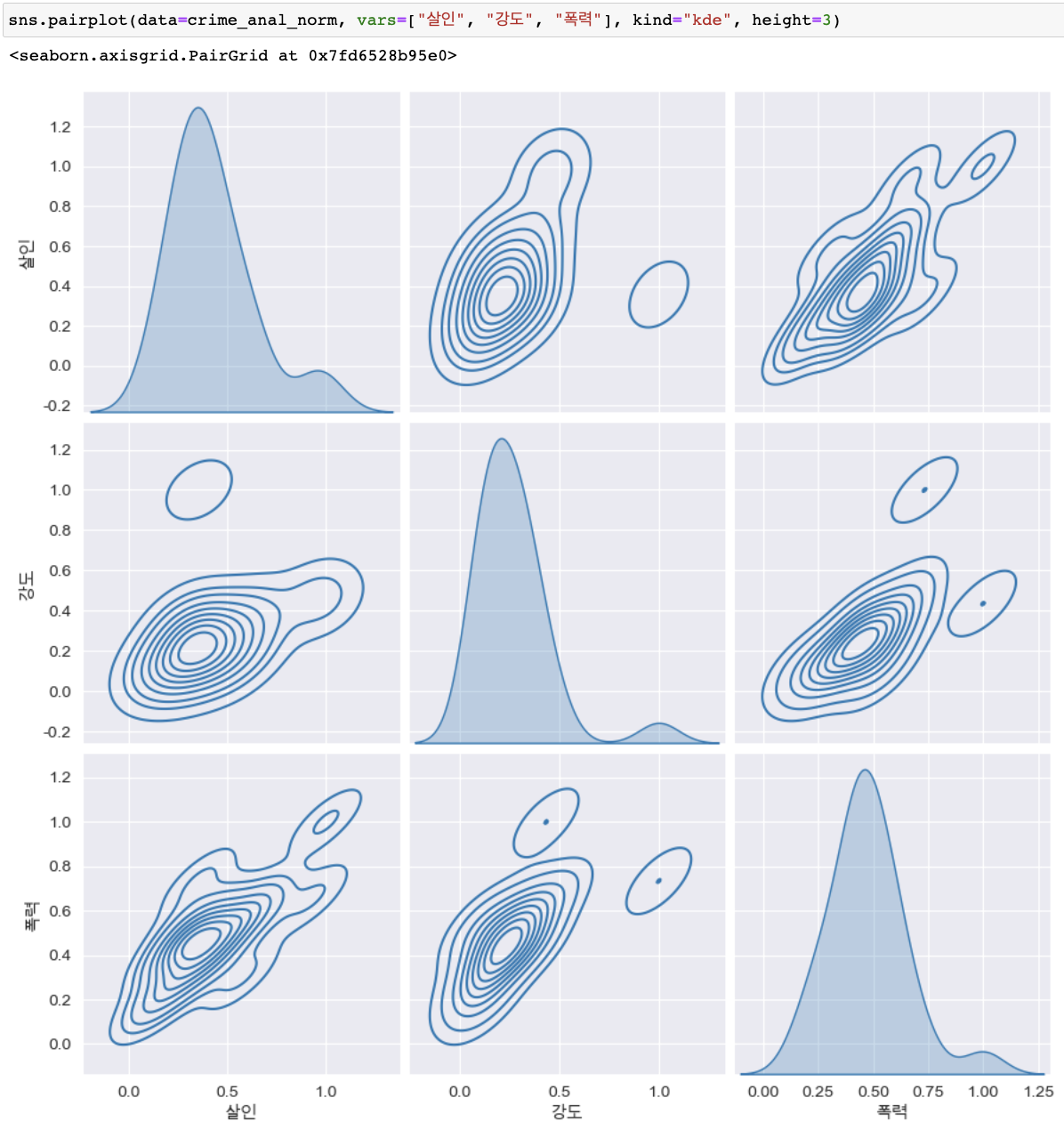
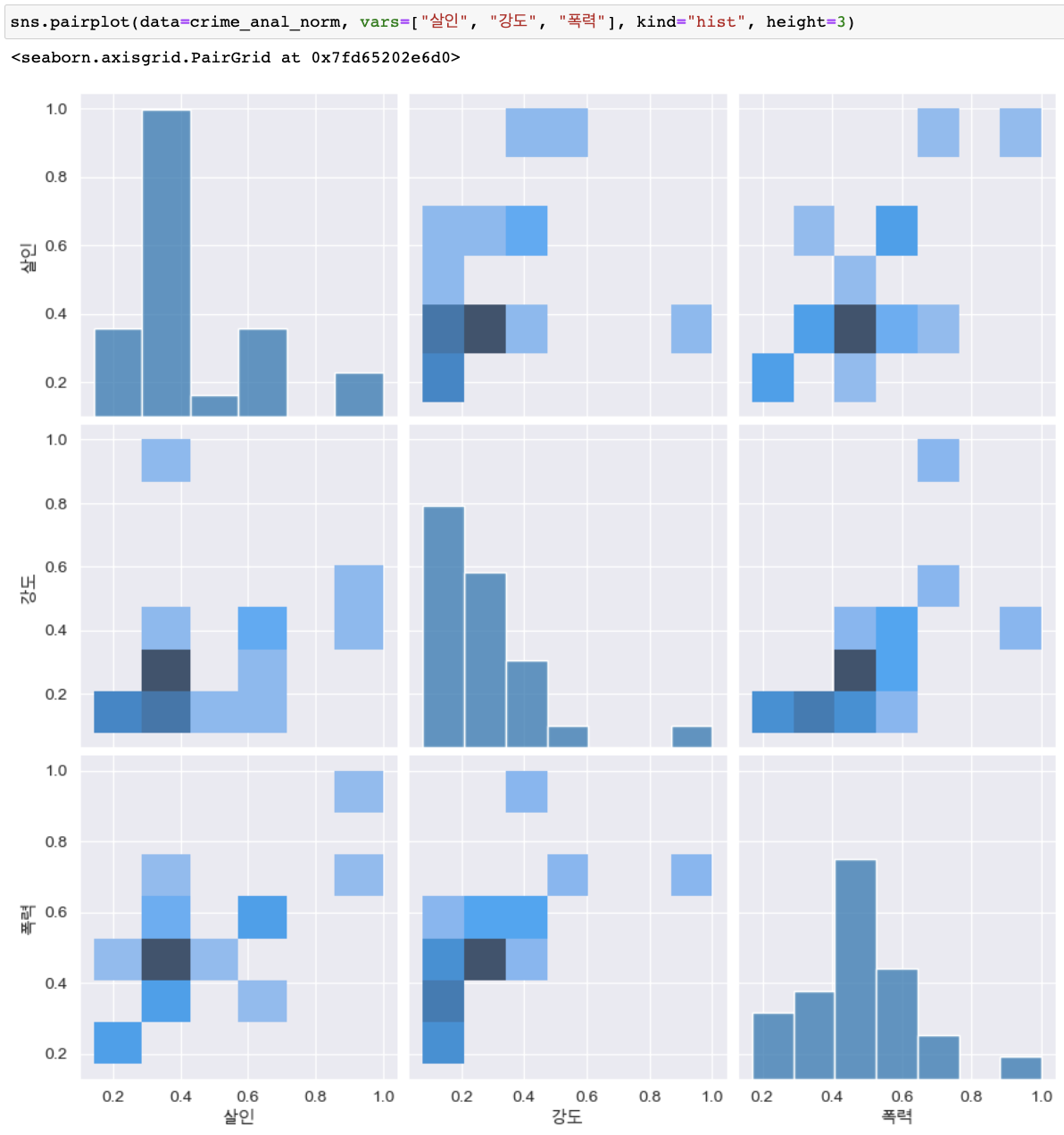
-
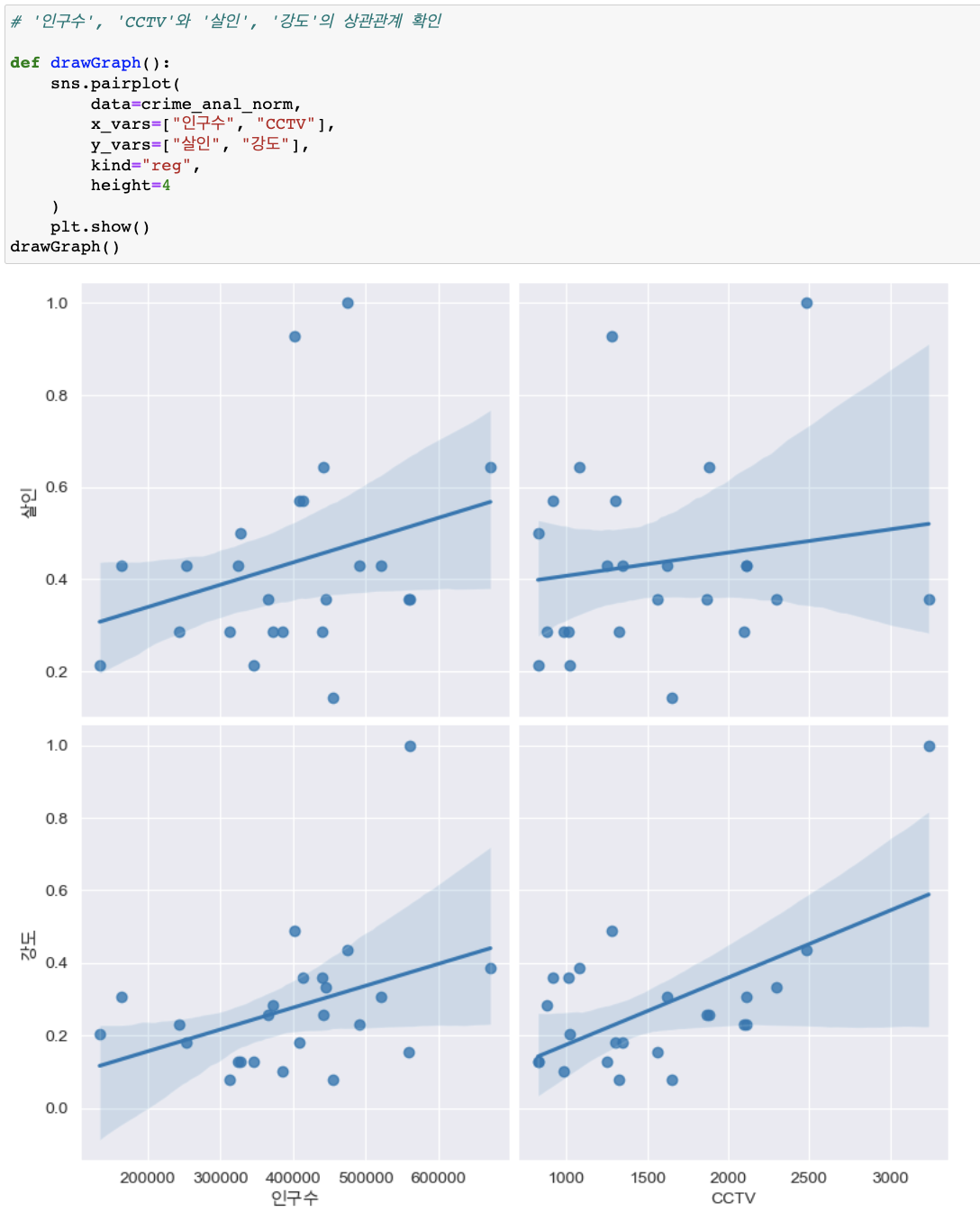
'인구수', 'CCTV'와 '살인', '강도'의 상관관계
-
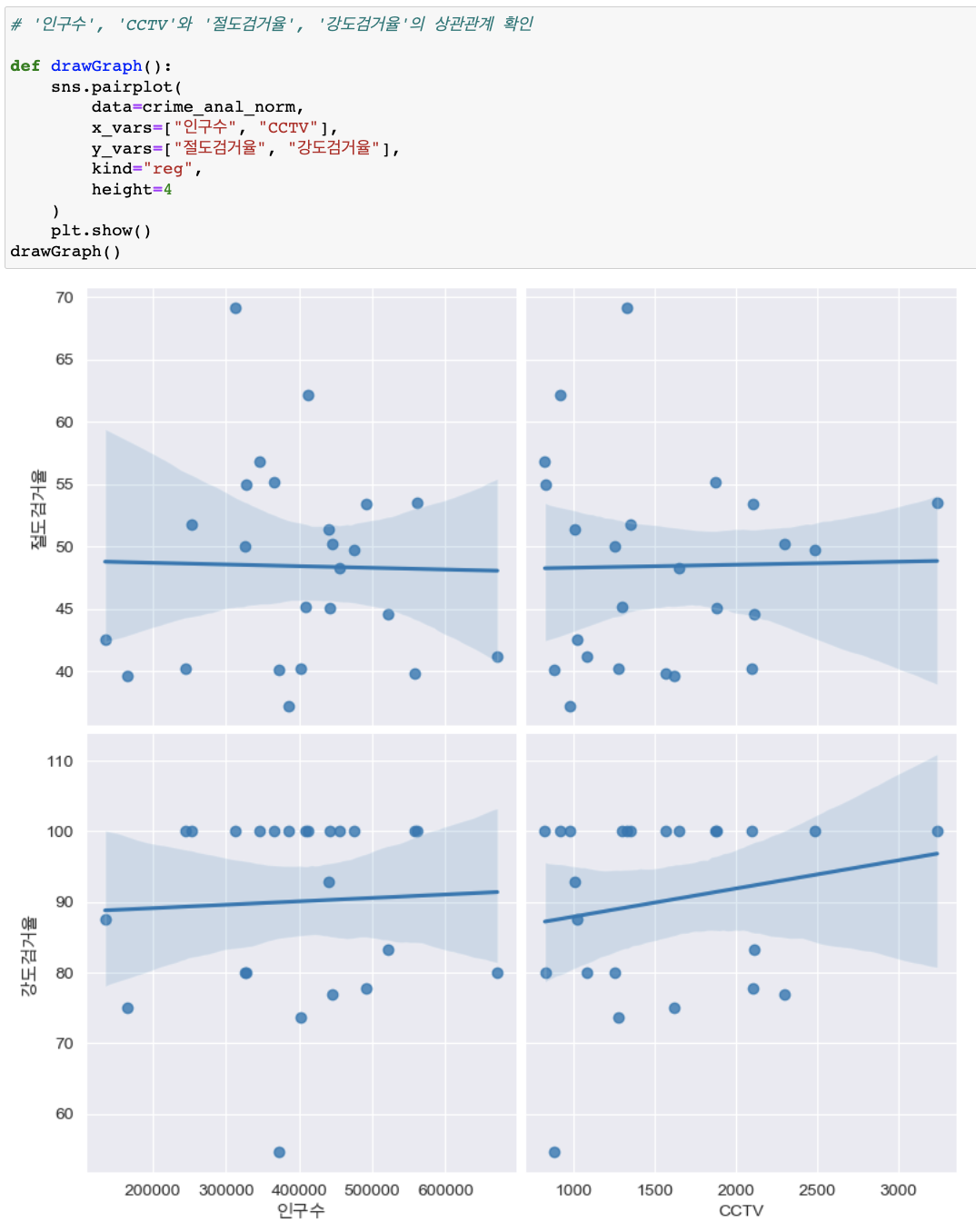
'인구수', 'CCTV'와 '절도검거율', '강도검거율'의 상관관계
-
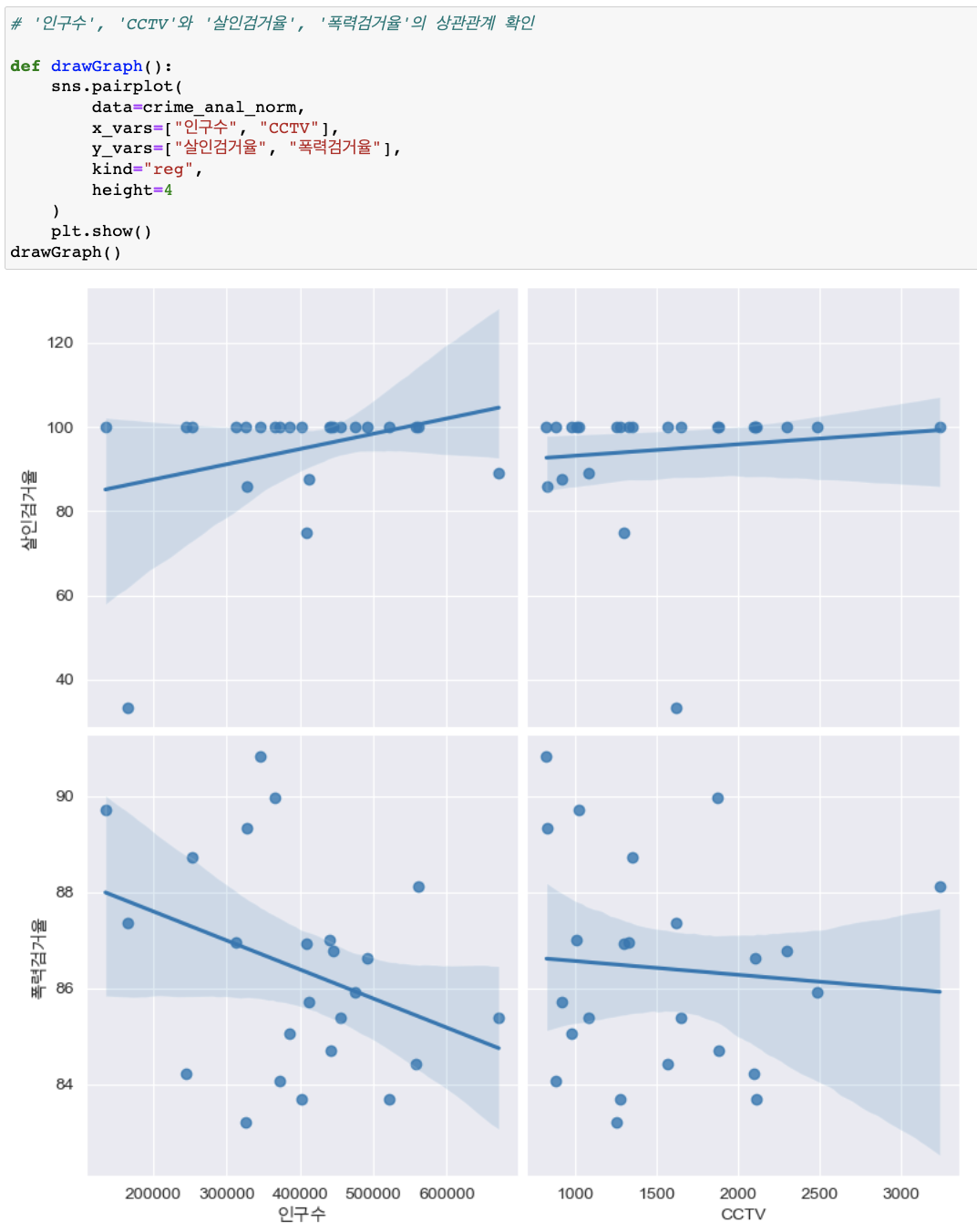
'인구수', 'CCTV'와 '살인검거율', '폭력검거율'의 상관관계
-
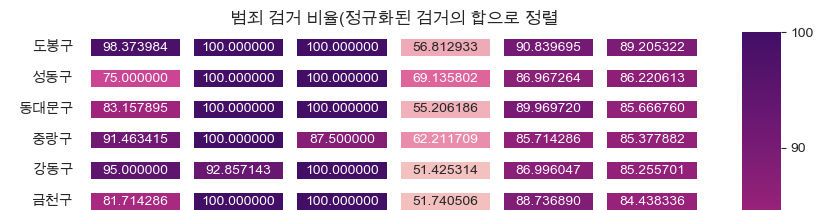
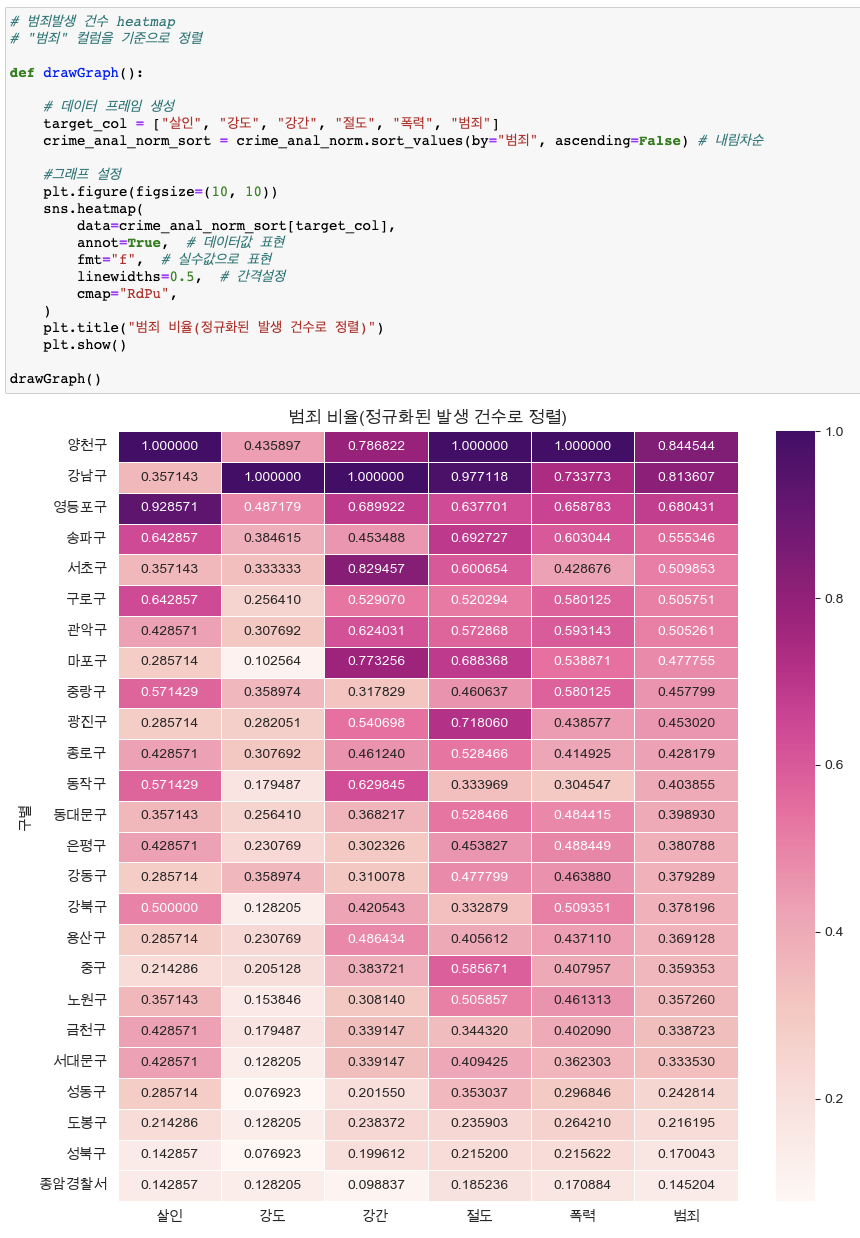
heatmap
-- '검거' 컬럼을 기준으로 '각 검거율' 비교
-- '검거' 컬럼을 기준으로 '각 범죄' 비교 -
'검거' 컬럼을 기준으로 '각 검거율' 비교
# 검거율 heatmap
# '검거' 컬럼을 기준으로 정렬
def drawGraph():
# 데이터 프레임 생성
target_col = ["강간검거율", "강도검거율", "살인검거율", "절도검거율", "폭력검거율", "검거"]
crime_anal_norm_sort = crime_anal_norm.sort_values(by="검거", ascending=False) # 내림차순
#그래퍼 설정
plt.figure(figsize=(10, 10))
sns.heatmap(
data=crime_anal_norm_sort[target_col],
annot=True, # 데이터값 표현
fmt="f", # d: 정수, f: 실수
linewidths=0.5, # 간격설정
cmap="RdPu",
)
plt.title("범죄 검거 비율(정규화된 검거의 합으로 정렬")
plt.show()
drawGraph()

-
linewidths=10 # 간격설정
-
'검거' 컬럼을 기준으로 '각 범죄' 비교
-
데이터 저장

오류 코드
- outliner 오류 ("no module named statemodules")
- 해결
- pip install statsmoduls 설치 후 작동