알고리즘
1.탐욕 알고리즘의 이해

Greedy algorithm 또는 탐욕 알고리즘 이라고 불리움최적의 해에 가까운 값을 구하기 위해 사용됨여러 경우 중 하나를 결정해야할 때마다, 매순간 최적이라고 생각되는 경우를 선택하는 방식으로 진행해서, 최종적인 값을 구하는 방식지불해야 하는 값이 4720원 일
2.실전 - 동적 계획법
본 자료와 관련 영상 컨텐츠는 저작권법 제25조 2항에 의해 보호를 받습니다. 본 컨텐츠 및 컨텐츠 일부 문구 등을 외부에 공개하거나, 요약해서 게시하지 말아주세요.코딩 테스트 학습 팁알고리즘을 익힌 후, 해당 알고리즘과 관련된 문제만 연이어서 쭈욱 풀어보는 방식이 가
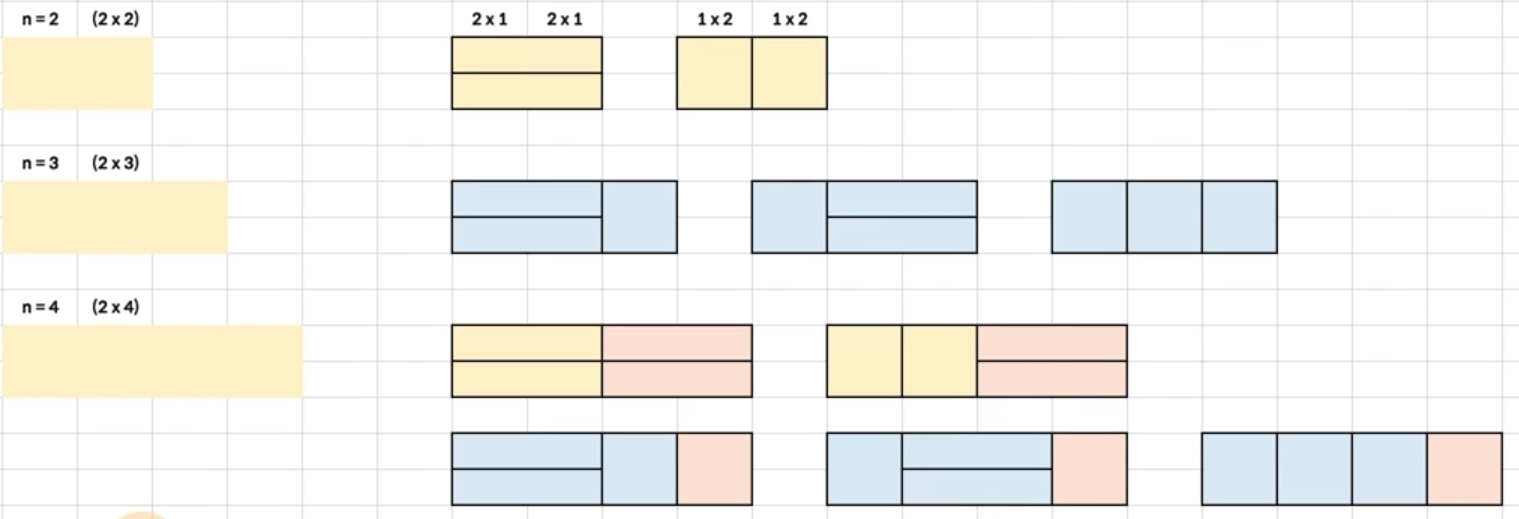
3.동적계획법과 분할정복
동적계획법 (DP 라고 많이 부름)입력 크기가 작은 부분 문제들을 해결한 후, 해당 부분 문제의 해를 활용해서, 보다 큰 크기의 부분 문제를 해결, 최종적으로 전체 문제를 해결하는 알고리즘상향식 접근법으로, 가장 최하위 해답을 구한 후, 이를 저장하고, 해당 결과값을
4.최소 신장 트리의 이해 (1)
Spanning Tree, 또는 신장 트리 라고 불리움 (Spanning Tree가 보다 자연스러워 보임)원래의 그래프의 모든 노드가 연결되어 있으면서 트리의 속성을 만족하는 그래프신장 트리의 조건본래의 그래프의 모든 노드를 포함해야 함모든 노드가 서로 연결트리의 속성
5.최소 신장 트리의 이해 (2)
대표적인 최소 신장 트리 알고리즘Kruskal’s algorithm (크루스칼 알고리즘), Prim’s algorithm (프림 알고리즘)프림 알고리즘시작 정점을 선택한 후, 정점에 인접한 간선중 최소 간선으로 연결된 정점을 선택하고, 해당 정점에서 다시 최소 간선으로
6.최단 경로 알고리즘의 이해
최단 경로 문제란 두 노드를 잇는 가장 짧은 경로를 찾는 문제임가중치 그래프 (Weighted Graph) 에서 간선 (Edge)의 가중치 합이 최소가 되도록 하는 경로를 찾는 것이 목적단일 출발 및 단일 도착 (single-source and single-destin
7.재귀 용법
고급 정렬 알고리즘엥서 재귀 용법을 사용하므로, 고급 정렬 알고리즘을 익히기 전에 재귀 용법을 먼저 익히기로 합니다.함수 안에서 동일한 함수를 호출하는 형태여러 알고리즘 작성시 사용되므로, 익숙해져야 함예제를 풀어보며, 재귀 용법을 이해해보기팩토리얼을 구하는 알고리즘을
8.이진 탐색
탐색할 자료를 둘로 나누어 해당 데이터가 있을만한 곳을 탐색하는 방법https://www.fun-coding.org/00_Images/binarysearch.pnghttps://www.mathwarehouse.com/programming/images/
9.실전 - 이진 탐색 알고리즘
본 자료와 관련 영상 컨텐츠는 저작권법 제25조 2항에 의해 보호를 받습니다. 본 컨텐츠 및 컨텐츠 일부 문구 등을 외부에 공개하거나, 요약해서 게시하지 말아주세요.본 문제는 각 자료구조/알고리즘을 보다 실전 문제와 연결하여 연습함으로써, 해당 자료구조/알고리즘 이해도
10.순차 탐색
탐색은 여러 데이터 중에서 원하는 데이터를 찾아내는 것을 의미데이터가 담겨있는 리스트를 앞에서부터 하나씩 비교해서 원하는 데이터를 찾는 방법프로그래밍 연습임의 리스트가 다음과 같이 rand_data_list로 있을 때, 원하는 데이터의 위치를 리턴하는 순차탐색 알고리즘
11.백트래킹
백트래킹 (backtracking) 또는 퇴각 검색 (backtrack)으로 부름제약 조건 만족 문제 (Constraint Satisfaction Problem) 에서 해를 찾기 위한 전략해를 찾기 위해, 후보군에 제약 조건을 점진적으로 체크하다가, 해당 후보군이 제약
12.깊이 우선 탐색 (DFS)
대표적인 그래프 탐색 알고리즘너비 우선 탐색 (Breadth First Search): 정점들과 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식깊이 우선 탐색 (Depth First Search): 정점의 자식들을 먼저 탐색하는 방식BFS 방식: A -
13.넓이 우선 탐색 (BFS)
대표적인 그래프 탐색 알고리즘너비 우선 탐색 (Breadth First Search): 정점들과 같은 레벨에 있는 노드들 (형제 노드들)을 먼저 탐색하는 방식깊이 우선 탐색 (Depth First Search): 정점의 자식들을 먼저 탐색하는 방식BFS 방식: A -
14.기본정렬 - 선택정렬
다음과 같은 순서를 반복하며 정렬하는 알고리즘주어진 데이터 중, 최소값을 찾음해당 최소값을 데이터 맨 앞에 위치한 값과 교체함맨 앞의 위치를 뺀 나머지 데이터를 동일한 방법으로 반복함https://upload.wikimedia.org/wikipedia/comm
15.기본정렬 - 삽입정렬
삽입 정렬은 두 번째 인덱스부터 시작해당 인덱스(key 값) 앞에 있는 데이터(B)부터 비교해서 key 값이 더 작으면, B값을 뒤 인덱스로 복사이를 key 값이 더 큰 데이터를 만날때까지 반복, 그리고 큰 데이터를 만난 위치 바로 뒤에 key 값을 이동https&#x
16.기본정렬 - 버블정렬
알고리즘을 잘 작성하기 위해서는 잘 작성된 알고리즘을 이해하고, 스스로 만들어봐야 함모사! 그림을 잘 그리기 위해서는 잘 그린 그림을 모방하는 것부터 시작이번 챕터부터 알고리즘 시작입니다.!알고리즘 연습 방법연습장과 펜을 준비하자.알고리즘 문제를 읽고 분석한 후에,간단
17.그래프 이해
그래프는 실제 세계의 현상이나 사물을 정점(Vertex) 또는 노드(Node) 와 간선(Edge)로 표현하기 위해 사용https://www.fun-coding.org/00_Images/graph.png노드 (Node): 위치를 말함, 정점(Vertex)라고도
18.공간 복잡도
알고리즘 계산 복잡도는 다음 두 가지 척도로 표현될 수 있음시간 복잡도: 얼마나 빠르게 실행되는지공간 복잡도: 얼마나 많은 저장 공간이 필요한지좋은 알고리즘은 실행 시간도 짧고, 저장 공간도 적게 쓰는 알고리즘통상 둘 다를 만족시키기는 어려움시간과 공간은 반비례적 경향
19.고급정렬 - 퀵정렬
정렬 알고리즘의 꽃기준점(pivot 이라고 부름)을 정해서, 기준점보다 작은 데이터는 왼쪽(left), 큰 데이터는 오른쪽(right) 으로 모으는 함수를 작성함각 왼쪽(left), 오른쪽(right)은 재귀용법을 사용해서 다시 동일 함수를 호출하여 위 작업을 반복함함
20.고급정렬 - 병합정렬
재귀용법을 활용한 정렬 알고리즘리스트를 절반으로 잘라 비슷한 크기의 두 부분 리스트로 나눈다.각 부분 리스트를 재귀적으로 합병 정렬을 이용해 정렬한다.두 부분 리스트를 다시 하나의 정렬된 리스트로 합병한다.https://upload.wikimedia.org/w
21.실전 - 탐욕 알고리즘
본 자료와 관련 영상 컨텐츠는 저작권법 제25조 2항에 의해 보호를 받습니다. 본 컨텐츠 및 컨텐츠 일부 문구 등을 외부에 공개하거나, 요약해서 게시하지 말아주세요.본 문제는 각 자료구조/알고리즘을 보다 실전 문제와 연결하여 연습함으로써, 해당 자료구조/알고리즘 이해도
22.[Softeer] 징검다리
이것은 가장 긴 증가하는 부분 수열 알고리즘이다.옛날에 백준에서 풀었던 문제와 매우 흡사해서 빠르게 풀이했다.풀이 방법은 dp와 이분탐색이 있다.LIS(Longest Increasing Subsequence) 이라고 하는데, 굳이 작성하지 않겠다.내가 푼 풀이는 dp로