지도 학습 알고리즘
2.3.2 k-최근접 이웃
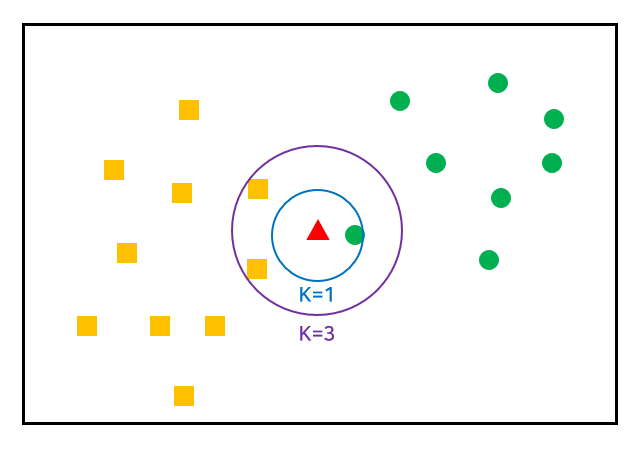
k-NN(k-nearest Neighbors) 알고리즘은 가장 간단한 머신러닝 알고리즘이다. 훈련 데이터셋을그냥 저장하는 것이 모델을 만드는 과정의 전부이기 때문이다. 새로운 데이터 포인트를 예측할 때는 훈련 데이터셋에서 가장 가까운 데이터 포인트, 즉 '최근접 이웃'을 찾는다.
k-NN 분류
가장 간단한 k-NN 알고리즘은 가장 가까운 훈련 데이터 포인트 하나를 최근접 이웃으로 찾아 예측에 사용하는 것이다. 단순히 이 훈련 데이터 포인트의 출력이 예측된다.
코드:
import mglearn
import matplotlib.pyplot as plt
#훈련 데이터셋을 저장하는 것이 모델을 만드는 전부
X, y = mglearn.datasets.make_forge()
#mglearn.plots에 있는 plot_knn_classfication 적용
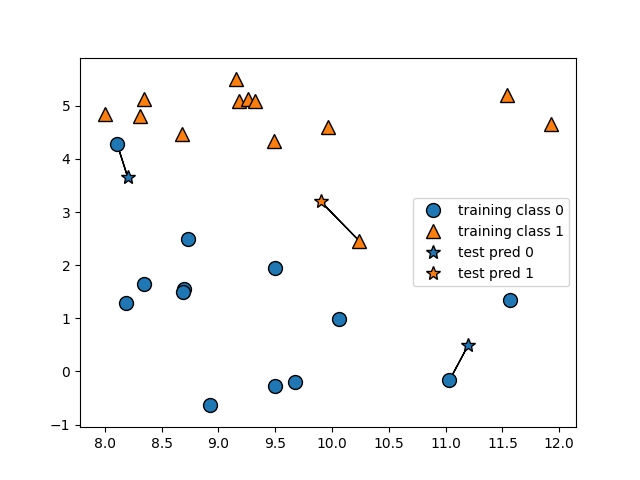
mglearn.plots.plot_knn_classification(n_neighbors=1)
plt.show()++) Q : 왜 세 데이터 포인트에 관해서만 예측을 진행하였나?
코드:
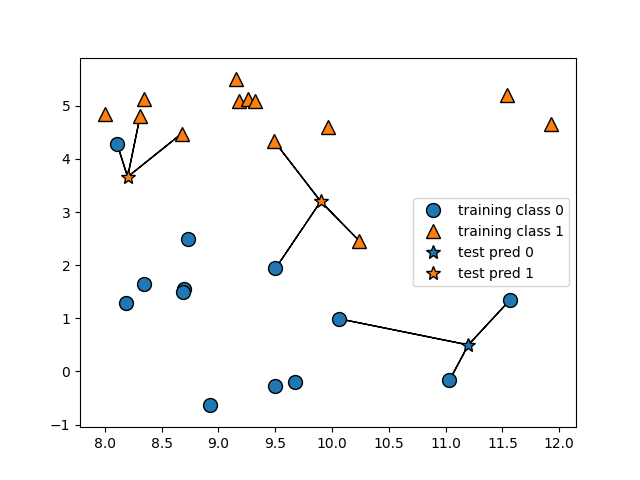
mglearn.plots.plot_knn_classification(n_neighbors=3)
plt.show()이 코드에서는 데이터 포인트를 3개 추가했는데, 추가한 각 데이터 포인트에서 가장 가까운 훈련 데이터 포인트를 연결했다. 둘 이상의 이웃을 선택할 때는 레이블을 정하기 위해 투표를 진행하는데 테스트 포인트 하나에 대해 클래스 0에 속한 이웃이 몇 개인지, 그리고 클래스 1에 속한 이웃이 몇 개인지를 세어 이웃이 더 많은 클래스를 레이블로 지정한다.
즉, k-최근접 이웃 중 다수의 클래스가 레이블이 된다.
이제, scikit-learn을 사용하여 k-NN 알고리즘을 실제 어떻게 적용하는지 살펴보겠다.
코드:
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_forge()
#train, test set으로 나누기
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.neighbors import KNeighborsClassifier
clf = KNeighborsClassifier(n_neighbors= 3)
clf.fit(X_train, y_train)
print("테스트 세트 예측: ", clf.predict(X_test))
#모델이 얼마나 잘 일반화되었는지 평가
print("테스트 세트 정확도: {:.2f}" .format(clf.score(X_test, y_test)))kNeighborsClassifier에서의 학습은 예측할 때 이웃을 찾을 수 있도록 데이터를 저장하는 것이다.
predict()함수를 통해 예측하고, score함수를 통해 예측 값을 평가한다.
이 모델의 정확도는 86%가 나왔다.
k-NN 프로세스의 가장 중요한 점은 k를 선택하는 것인데 k를 선택하는 방법은 가능한 k의 값을 모두 테스트해봐서 가장 성능이 좋은 수치를 선택하는 것이 가장 정확하다
KNeighborsClassifier 분석
2차원 데이터셋이므로 가능한 모든 테스트 포인트의 예측을 xy 평면에 그릴 수 있다. 그리고 각 데이터 포인트가 속한 클래스에 따라 평면에 색을 칠한다. 이렇게 하면 클래스 0과 클래스 1로 지정한 영역으로 나뉘는 결정경계를 볼 수 있다.

코드:
##fig = figure 데이터가 담기는 프레임(크기 모양을 변형할 수는 있지만 실제로 프레임위에 글씨를 쓸수는 없음),
##axes = axes 실제 데이터가 그려지는 캔버스
fig, axes = plt.subplots(1, 3, figsize=(10, 3))
for n_neighbors, ax in zip ([1, 3, 9], axes):
#fit 메소드는 self 오브젝트를 리턴한다
#그래서 객체생성과 fit 메소드를 한 줄에 쓸 수 있다.
clf = KNeighborsClassifier(n_neighbors=n_neighbors).fit(X, y)
#결정경계를 표시한다
#model 객체를 넣고, train 데이터, 평면 칠하기, 캔버스 설정, 투명도 설정을 해줄 수 있다
mglearn.plots.plot_2d_classification(clf, X, fill = True, eps = 0.5, ax = ax, alpha=.4)
#산점도 그리기
mglearn.discrete_scatter(X[:, 0], X[:, 1], y, ax=ax)
ax.set_title("{} 이웃" .format(n_neighbors))
ax.set_xlabel("특성 0")
ax.set_ylabel("특성 1")
axes[0].legend(loc = 3)
plt.rc('font', family = 'Malgun Gothic')
plt.show()그림을 보면 이웃이 늘어날 수록 결정 경계가 부드러워지는 것을 확인할 수 있다. 부드러운 경계라는 것은 더 단순한 모델을 의미한다. 다시 말해 이웃이 너무 적으면 모델의 복잡도가 높아져서 과대적합이 발생할 수 있고, 이웃이 너무 많으면 모델의 복잡도가 낮아져서 과소적합이 발생할 수 있다는 것이다. 극단적으로 이웃의 수를 모든 훈련 데이터 전체 개수로 지정할 경우 모든 데이터 포인트가 같은 값을 가지게 된다. 즉, 훈련 세트에서 가장 많은 데이터 포인트를 가진 클래스가 예측값이 된다.
다음은 유방암 데이터셋을 이용하여 모델의 복잡도와 일반화 사이의 관계에 대해서 얘기해보겠다.
**여기서 중요한 점은 train_test_split()함수 중에서 stratify라는 매개변수이다. 공식문서를 찾아봤을 때, default는 0으로 설정되어 있고 배열 형식으로 설정했을 때 해당 배열을 클래스 레이블로 사용하여 stratified fashion으로 데이터를 분할한다고 적혀있다. 즉, 훈련데이터를 나눌 때 무작위로 샘플링하되, original dataset의 클래스 비율이 train, test set에서도 동일하게 유지되도록 보장한다는 것이다. 이것이 random sampling과는 다른 점이다.

코드:
############모델의 복잡도와 일반화 사이의 관계
from sklearn.datasets import load_breast_cancer
cancer = load_breast_cancer()
#stratify는 기존 데이터를 나눌 뿐만 아니라 클래스 분포 비율까지 맞춰준다
X_train, X_test, y_train, y_test = train_test_split(
cancer.data, cancer.target, stratify=cancer.target, random_state = 66
)
train_accurancy = []
test_accurancy = []
#1에서 10까지 이웃의 수를 결정
neighbors_settings = range(1, 11)
for n_neighbors in neighbors_settings:
#모델 생성
clf = KNeighborsClassifier(n_neighbors=n_neighbors)
clf.fit(X_train, y_train)
#훈련 세트 정확도 예측
train_accurancy.append(clf.score(X_train, y_train))
#일반화 정확도 저장
test_accurancy.append(clf.score(X_test, y_test))
plt.plot(neighbors_settings, train_accurancy, label="훈련 정확도")
plt.plot(neighbors_settings, test_accurancy, label="테스트 정확도")
plt.ylabel("정확도")
plt.xlabel("n_neighbors")
#그래프 범례 표시
plt.legend()
plt.show()실제로 이런 식으로 매끈하게 나오지는 않지만, 여기서도 과대적합과 과소적합의 특징을 볼 수 있다. 최근접 이웃의 수가 하나일 때는 훈련 데이터셋에 대한 예측이 정확하다.(과대적합) 그러나 이웃의 수가 늘어나면서 모델이 단순해지고 정확도가 떨어지게 된다. 테스트 세트를 확인해보면 이웃이 1개일 때 모델이 너무 복잡해지게 되고, 이웃이 10개일 때 모델이 너무 단순해져 정확도가 떨어지게 된다. 정확도가 가장 좋은 경우는 과대적합과 과소적합의 사이인 6-knn의 경우이다.
k-최근접 이웃 회귀
k-NN 알고리즘은 회귀 분석에도 사용된다. 다음은 wave 데이터셋을 이용하여 k-NN 알고리즘 그래프를 그린 것이다.
여기서 사용하는 plot_knn_regression 그래프는 wave 데이터셋을 이용해서 자동적으로 그래프를 그려준다.
코드:
###########k-최근접 이웃 회귀
#plot_knn_regression은 mgleran에 있는 wave 데이터셋을 이용하여
#k-NN 회귀 그래프를 그려준다.
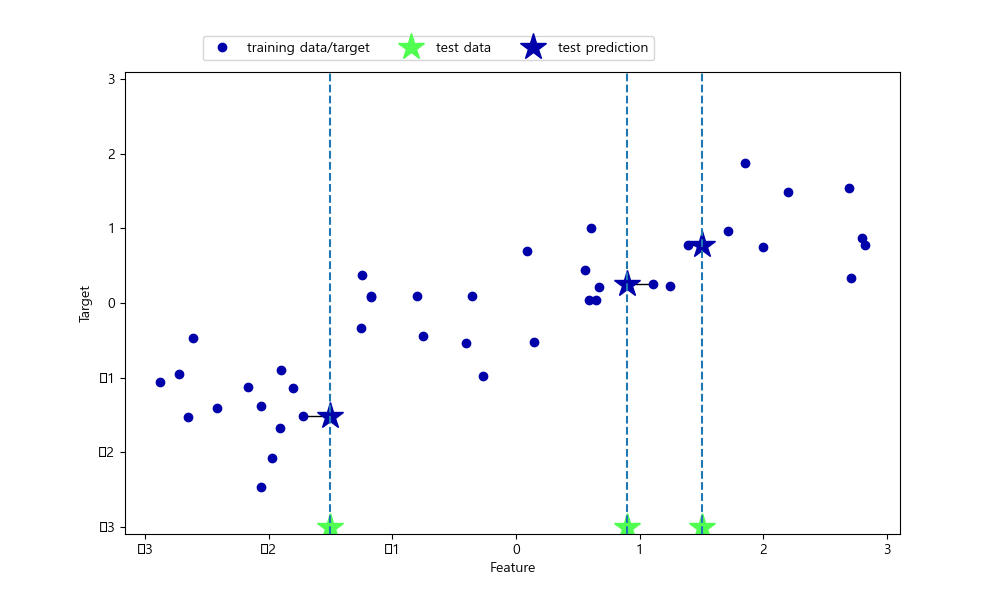
mglearn.plots.plot_knn_regression(n_neighbors = 1)
plt.show()여기서도 이웃을 n개 사용하여 회귀 분석을 진행할 수 있다. 여러 개의 최근접 이웃을 사용할 땐 이웃 간의 평균이 예측된다. 이때 평균은 weight의 매개변수가 uniform(기본값)인지 distance인지에 따라 np.mean을 이용한 단순 평균이나 거리를 고려한 가중치 평균을 구한다.
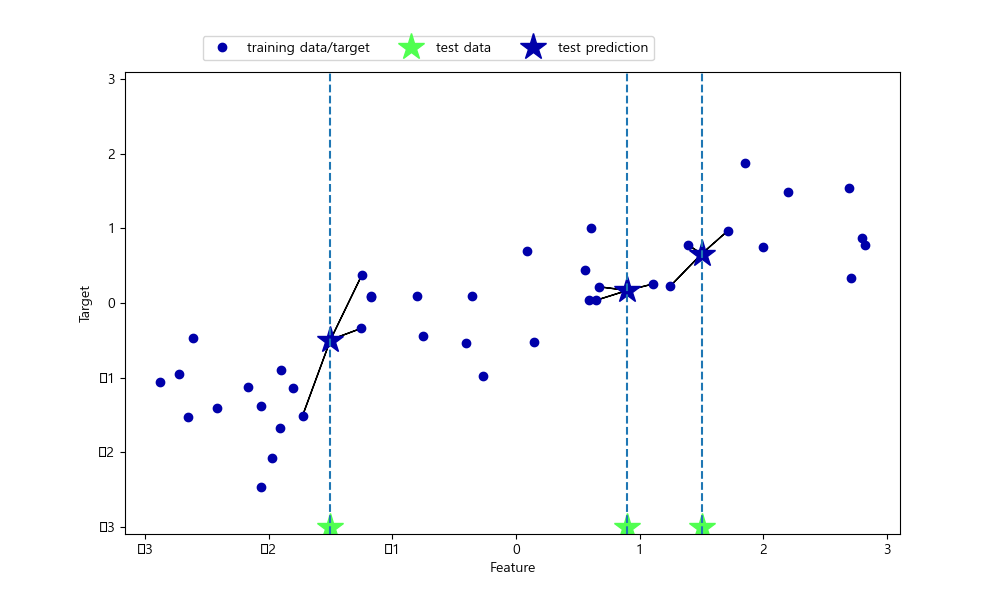
#n-NN 최근접 이웃 평균
mglearn.plots.plot_knn_regression(n_neighbors=3)
plt.show()scikit-learn에서 회귀를 위한 k-최근접 이웃 알고리즘은 kNeighborsRegressor에 구현되어 있다.
from sklearn.neighbors import KNeighborsRegressor
X, y = mglearn.datasets.make_wave(n_samples = 40)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 0)
#이웃의 개수를 3으로 하여 모델의 객체를 만든다.
reg = KNeighborsRegressor(n_neighbors=3)
#훈련데이터를 이용하여 모델을 학습시킨다
reg.fit(X_train, y_train)
print("테스트 세트 예측: \n", reg.predict(X_test))
print("테스트 세트 R^2: {:.2f}" .format(reg.score(X_test, y_test)))KNeighborsRegressor에서도 score 메소드를 활용하여 모델을 평가할 수 있는데, 이 메소드는 회귀일 때 R^2 값을 반환한다. 결정 계수라고 불리는 R^2값은 회귀 모델에서 예측의 적합도를 측정한 것으로 보통 0-1사이의 값이 된다. 1로 갈 수록 예측이 완벽한 것이고, 0은 훈련 세트의 출력값인 y_train의 평균으로만 예측하는 모델의 경우이다. R^2이 음수가 될 때도 있는데 이는 예측과 타깃이 상반된 경향을 가지는 경우이다.
kNeighborsRegressor 분석
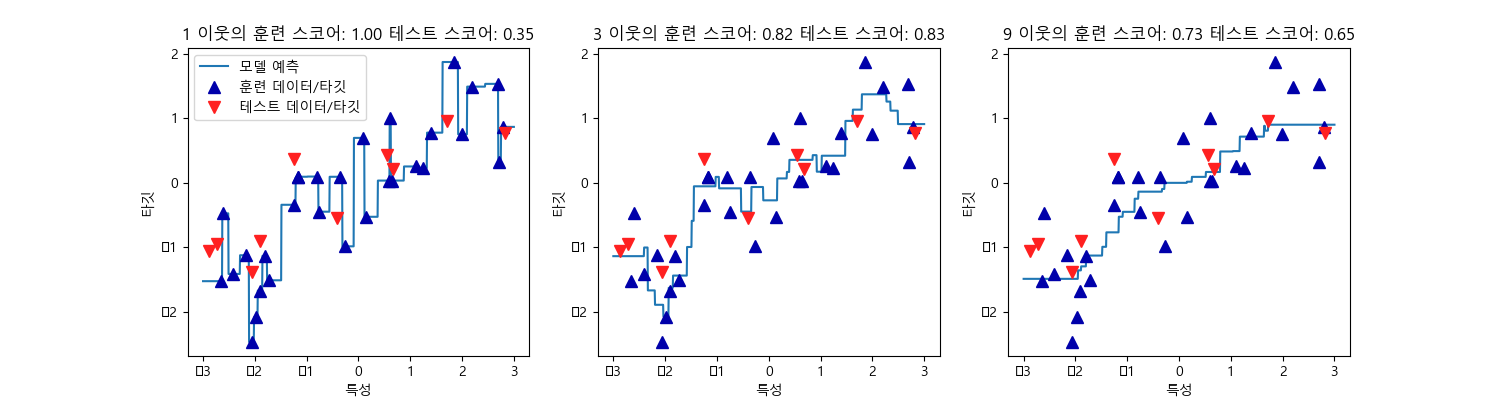 코드:
코드:
########kNeighborRegressor 분석################
fig, axes = plt.subplots(1, 3, figsize = (15, 4))
#-3과 3 사이에 1000개의 데이터 포인트를 만들고 이를 예측해보도록 하기
#linsapce에서 처음 값은 시작값, 중간 값은 end값, 마지막값은 값 사이에 나눌 개수를 의미한다
#선형간격값을 출력해준다.
#reshape(정수, 정수)는 reshape(정수 행, 정수 열)의 2차원 배열로 값을 변형해준다.
#reshape애서 행의 값이 -1로 되어있다는 것은 열의 값은 특정 정수로 지정되어 있을 떄,
#남은 배열의 길이와 남은 차원으로부터 추정해서 알아서 지정하라는 뜻이다.
line = np.linspace(-3, 3, 1000).reshape(-1, 1)
for n_neighbors, ax in zip([1, 3, 9], axes):
#반복을 통해 이웃의 수를 바꿔가며 예측을 진행한다
reg = KNeighborsRegressor(n_neighbors=n_neighbors)
reg.fit(X_train, y_train)
#이웃의 수를 바꿔가며 -3~3까지의 데이터 포인트의 예측값을 정하여라
ax.plot(line, reg.predict(line))
#mglearn.cm2()는 이진 분류를 위한 컬러맵을 반환한다. 첫번쨰 클래스는 파란색, 두번째는 빨간색이다
ax.plot(X_train, y_train, '^', c=mglearn.cm2(0), markersize=8)
ax.plot(X_test, y_test, 'v', c=mglearn.cm2(1), markersize = 8)
ax.set_title("{} 이웃의 훈련 스코어: {:.2f} 테스트 스코어: {:.2f}" .format(
n_neighbors, reg.score(X_train, y_train),
reg.score(X_test, y_test)))
ax.set_xlabel("특성")
ax.set_ylabel("타깃")
axes[0].legend(["모델 예측", "훈련 데이터/타깃", "테스트 데이터/타깃"], loc="best")
plt.show()
이 그림에서 볼 수 있듯이 1-NN인 경우 훈련 데이터셋이 미치는 영향이 커서 예측값이 모두 훈련 데이터 포인트를 지난간다. 이는 매우 불안정한 예측을 만들어낸다. 이웃을 많이 사용하면 훈련 데이터에는 잘 안맞을 수 있지만 더 안정된 예측을 얻게 된다.
장단점과 매개변수
일반적으로 kNeightbors 알고리즘에서 중요한 매개변수는 데이터 포인트 사이의 거리를 재는 방법과 이웃의 수이다. 실제로 이웃의 수는 3-5일 때 잘 작용하지만 데이터에 따라 달라질 수 있기 때문에 적당한 이웃의 수를 설정하는 것이 중요하다. 또한 거리 재는 문제는 다루지 않았지만 기본적으로 유클리디안 거리 방식을 사용한다.
k-NN의 장점은 이해하기 매우 쉬운 모델이고, 매개변수를 다루기도 쉬우며 많이 조정하지 않아도 자주 좋은 성능을 발휘한다는 점이다. 따라서 복잡한 알고리즘을 수행하기 전에 다뤄보면 좋은 알고리즘이다. 그러나 train set가 매우 커지게 되면 예측이 느려지기 때문에 데이터를 전처리하는 것이 중요하다. 또한 (수백 개 이상의) 많은 feature를 가지고 있거나 특성 값이 대부분 0인 데이터셋에서는 잘 작동하지 않는다.
k-NN 알고리즘은 이해하기 쉽지만 예측이 느리고 많은 특성을 처리하는 능력이 부족하기 때문에 현업에서는 잘 사용되지 않는다.
출처
Introduction to Machine Learning with Python - 안드레아스 뮐러, 세라 가이도 지음, 박해선 옮김 https://hyjykelly.tistory.com/44

너무 잘 읽었습니다, 많은 것을 배웠습니다.