2.3.3 선형모델
선형 모델을 약 100년 전에 개발되여 지금가지도 폭넓게 연구되며 쓰이고 있는 알고리즘이다. 선형모델은 입력 특성 즉, 독립변수(x)에 대해 선형함수를 만들어 예측을 수행한다.
🔎단순 회귀 선형(Simple linear regression)
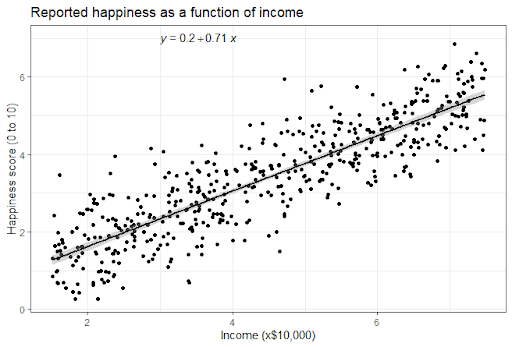
종속 변수(y)와 독립변수(x) 사이의 선형 관계를 파악하고 이를 예측에 활용하는 방법이다.
예를 들어, 기온(x)와 아이스크림 판매량(y) 사이의 관계식을 찾아내고자할 때 기온(x)과 아이스크림 판매량(y) 사이의 관계식을 모델(Model)이라고 한다. 현실 세계에서는 두 변수가 선형 관계에 있는 경우가 많아서 선형회귀 분석이 유용하다.
💡 단순 선형 회귀식 y = Wx + b
⚡두 변수가 선형 관계에 있는지 알아보는 방법: 산점도, 상관계수
🔎복합 회귀 선형(Multiple linear regression)
독립변수(설명변수) - x가 두 개 이상인 경우를 말한다.
💡 복합 선형 회귀식 y = w[0]x[0] + w[1]x[1] + .....+ w[p]*x[p] + b
이 식에서 x[0]부터 x[p]까지는 하나의 데이터 포인트에 대한 특성을 나타내며(특성의 개수는 p + 1) w와 b는 학습할 파라미터이다. 그리고 y는 모델이 만들어낸 예측값이다.
즉, 특성이 많아지면 w는 각 특성에 해당하는 기울기를 가진다. 다시말해, 예측값은 입력 특성에 각 가중치를 곱해서 더한 가중치의 합이라고 할 수 있다.
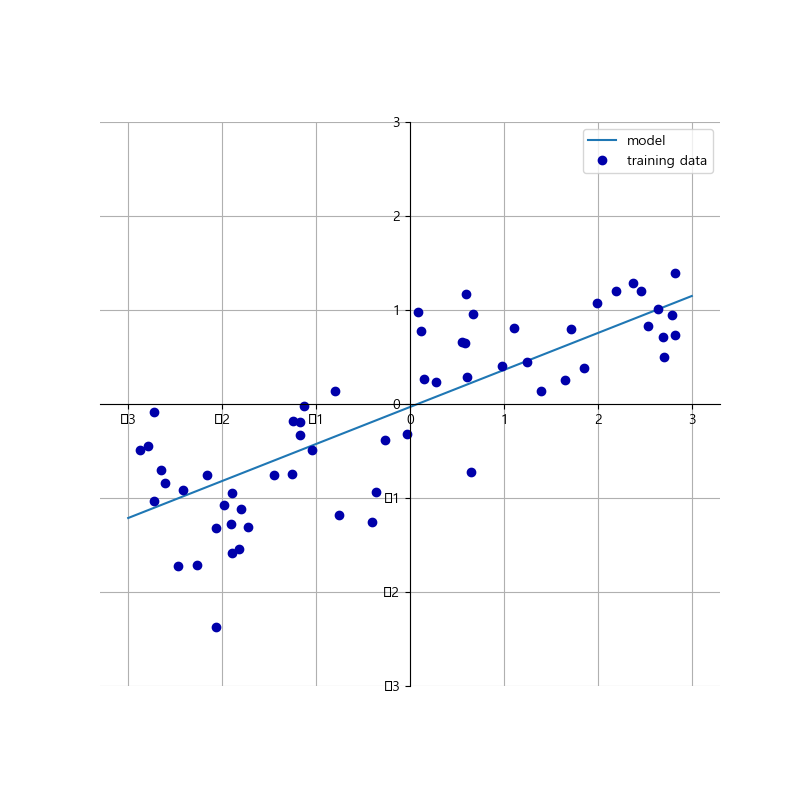
다음은 wave 데이터셋에 대한 simple linear regression 모델을 생성하고 이를 그래프로 그린 것이다.
💭python
##################################회귀의 선형 모델##########################
#wave 데이터셋을 이용하여 linear_regression을 그리는 함수
import mglearn
import matplotlib.pyplot as plt
mglearn.plots.plot_linear_regression_wave()
plt.show()🗯결과
w[0]: 0.393906 b: -0.031804결과를 보면 기울기는 대략 0.4정도 되어야하며 이를 그림에서 그래프로 확인할 수 있다.
이 직선을 kNeighborsRegressor과 비교해보면 직선을 사용한 예측이 더 제약이 많게 느껴진다. 그러나 타깃 y가 특성들의 선형 조합이라는 것은 매우 과한 가정이다. 하지만 이는 1차원 데이터만 놓고 봐서 생긴 것으로 실제 특성이 많은 데이터셋이라면 선형 모델은 훌륭한 성능을 낼 수 있다.
회귀를 위한 선형모델은 특성이 하나일 때는 직선, 특성이 두 개일 때는 평면, 더 높은 차원에서는 초평면이 되는 특징을 가지고 있다.
🔎선형 회귀(최소제곱법)
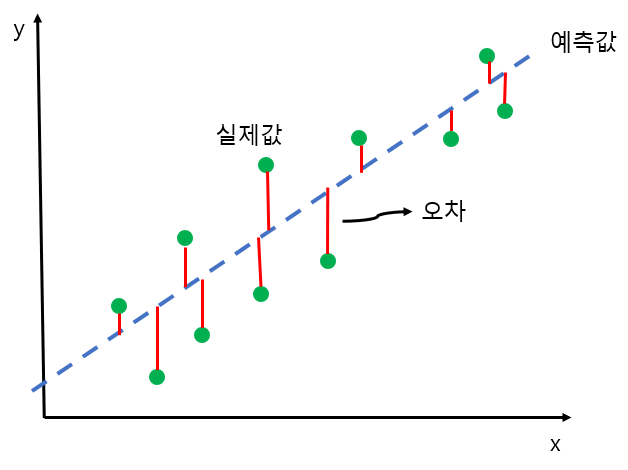
선형 회귀 또는 최소제곱법(OLS)은 가장 간단하고 오래된 회귀용 선형 알고리즘이다. 최소제곱법에서는 예측과 훈련 세트에 있는 타깃 y사이의 평균제곱오차를 최소화하는 파라미터 w와 b를 찾는다. 평균제곱오차는 예측값과 타깃 값의 차이를 제곱하여 더한 후에 샘플의 개수로 나눈 것이다. 선형 회귀는 매개변수가 없는 것이 특징이지만 모델의 복잡도를 제어할 방법 또한 없다.
💭python
##############wave 데이터셋을 이용한 선형모델###############
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
X, y = mglearn.datasets.make_wave(n_samples = 40)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state = 42)
lr = LinearRegression().fit(X_train, y_train)
#기울기 파라미터는 가중치 또는 계수라고 하며 객체의 coef_ 특성에 저장
#편향 또는 절편 파라미터(b)는 객체의 intercept_ 속성에 저장
print("lr의 가중치: ", lr.coef_)
print("lr의 절편: ", lr.intercept_)🗯결과
lr의 가중치: [0.47954524]
>>> print("lr의 절편: ", lr.intercept_)
lr의 절편: -0.09847983994403892coer속성은 intercept속성과 다르게 각 입력 특성에 하나씩 대응되는 Numpy 배열이다.
💭python
#train set와 test set의 성능 대비
print("훈련 세트 성능: {}" .format(lr.score(X_train, y_train)))
print("테스트 세트 성능: {}" .format(lr.score(X_test, y_test)))🗯결과
print("훈련 세트 성능: {}" .format(lr.score(X_train, y_train)))
훈련 세트 성능: 0.6883322630458479
print("테스트 세트 성능: {}" .format(lr.score(X_test, y_test)))
테스트 세트 성능: 0.626150295776388R^2이 0.62 정도라면 그리 좋은 결과는 아니다.
훈련 세트 성능과 테스트 세트 성능의 결과가 거의 비슷하다면 과대적합이 아니라 과소적합 상태이다.
1차원 데이터셋에 대해서는 모델이 매우 단순하기 때문에 과대적합될 확률이 낮지만 고차원 데이터셋일 경우 과대적합될 확률이 높다.
다음은 모델이 복잡한 보스턴 주택가격 데이터셋에 대해 선형회귀를 적용해보았다.
💭python
##############boston dataset을 이용한 선형모델##############
X,y = mglearn.datasets.load_extended_boston()
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state= 0)
lr = LinearRegression().fit(X_train, y_train)
print("훈련 세트 성능: {}" .format(lr.score(X_train, y_train)))
print("테스트 세트 성능: {}" .format(lr.score(X_test, y_test)))🗯결과
>>> print("훈련 세트 성능: {}" .format(lr.score(X_train, y_train)))
훈련 세트 성능: 0.9520519609032729
>>> print("테스트 세트 성능: {}" .format(lr.score(X_test, y_test)))
테스트 세트 성능: 0.607472195966591훈련 데이터 세트와 테스트 데이터 세트의 성능 차이는 모델이 과대적합되었다는 확실한 신호이므로 복잡도를 제어할 수 있는 모델을 사용해야 한다. 기본 선형 회귀 방식 대신 가장 널리 쓰이는 모델은 리지 회귀이다.
실제 데이터를 이용한 최소제곱법
💭python
##################car dataset을 이용한 linearRegressor###################
import pandas as pd
import numpy as np
from sklearn.linear_model import LinearRegression
from sklearn.model_selection import train_test_split
#RMSE 평가 지표: MSE값은 오류의 제곱을 구하므로 실제값보다 더 커지는 특성이 있어
#이에 루트를 씌운 값을 구한 것. 에러에 제곱을 하기 떄문에 에러가 크면 클수록 그에 따른 가중치가 높아진다.
#MSE는 실제 값과 예측값과의 차이를 제곱해 평균화한 것
#RSME는 sklearn의 mean_squared_error 함수를 이용해 구할 수 있음
#R2score은 결정계수를 구하는 함수: 독립변수가 종속변수를 얼마나 잘 평가하는지 알려줌
from sklearn.metrics import mean_squared_error, r2_score
raw_data = pd.read_csv("C:/Users/young/OneDrive/바탕 화면/cars.csv")
print(raw_data)
X = raw_data['speed']
y = raw_data['dist']
#X, y는 각각 np.array로 바꿔줘야 하는데, 하나의 속성(feature)에 대해 여러 값을 가질 떄
#reshape(-1, 1)을 적용하여 2차원 배열 혹은 행렬로 만들어줘야 한다
#그 이유는 최소제곱법에서 회귀선을 계산할 때 행렬로 계산하기 때문
X = np.array(X).reshape(-1, 1)
y = np.array(y).reshape(-1, 1)
train_X, test_X, train_y, test_y = train_test_split(X, y, test_size = 0.3, random_state= 3)
model = LinearRegression()
model.fit(train_X, train_y)
pred_y = model.predict(test_X)
print(pred_y)
#직접 숫자를 넣었을 때 에측
print(model.predict([[13]]))
print(model.predict([[20]]))
print('기울기: {:.2f}, 젊편: {:.2f}' .format(model.coef_[0][0], model.intercept_[0]))
print('Mean squared error: {:.2f}' .format(mean_squared_error(test_y, pred_y)))
print('coefficient of determination : %.2f}' %r2_score(test_y, pred_y))
print('train test: {:.2f}, test score: {:.2f}' \
.format(model.score(train_X, train_y), model.score(test_X, test_y)))
plt.scatter(test_X, test_y, color = 'black')
plt.plot(test_X, pred_y, color='blue', linewidth=3)
plt.xlabel('speed')
plt.ylabel('dist')
plt.show()🗯result
>>print('기울기: {:.2f}, 젊편: {:.2f}' .format(model.coef_[0][0], model.intercept_[0]))
기울기: 3.52, 젊편: -10.66
>>> print('Mean squared error: {:.2f}' .format(mean_squared_error(test_y, pred_y)))
Mean squared error: 285.03
>>> print('coefficient of determination : %.2f}' %r2_score(test_y, pred_y))
coefficient of determination : 0.68}
>>> print('train test: {:.2f}, test score: {:.2f}' \
... .format(model.score(train_X, train_y), model.score(test_X, test_y)))
train test: 0.62, test score: 0.68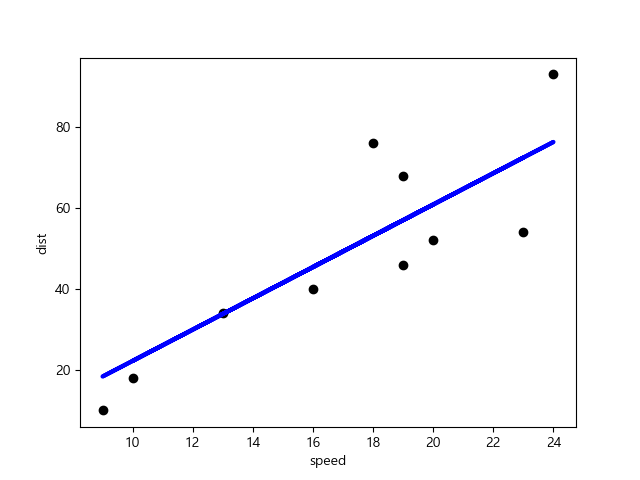
🔎리지 회귀
리지(ridge)도 회귀를 위한 선형 모델이므로 최소적합법에서 사용한 것과 같은 예측 함수를 사용한다.하지만 리지 회귀에서 가중치(w)는 선택은 훈련 데이터를 잘 예측하기 위해서 뿐만 아니라 추가적인 제약 조건을 만족시키기 위한 목적도 있다. 리지 회귀에서는 가중치를 최대한 0에 가깝게 만들어서 모든 특성이 출력에 주는 영향력을 최소한으로 줄인다. 이러한 제약을 규제(regularization)이라고 하는데 이러한 규제는 과대적합이되지 않도록 모델을 강제로 제한한다. 이러한 규제방식을 L2 규젤고 한다.
리지 회귀 모델을 실제 데이터인 보스턴 주택각격 데이터셋에 어떻게 적용되는지 알아보겠다.
💭python
##############Ridge regression##############
from sklearn.linear_model import Ridge
from mglearn.datasets import load_extended_boston
X, y = load_extended_boston()
train_X, test_X, train_y, test_y = train_test_split(X, y, random_state=0)
ridge_model = Ridge()
ridge_model.fit(train_X, train_y)
print("훈련 세트 점수: {:.2f}, 테스트 세트 점수: {:.2f}" \
.format(ridge_model.score(train_X, train_y), ridge_model.score(test_X, test_y)))🗯result
훈련 세트 점수: 0.89, 테스트 세트 점수: 0.75훈련 세트 점수는 LinearRegression보다 낮지만 테스트 세트에 대한 점수는 훨씬 더 높다. 즉, 선형 회귀는 이 데이터셋에 대해 과대적합될 확률이 크지만 Ridge는 덜 자유롭기 때문에 과대적합 될 확률이 낮아지기 때문이다. Ridge는 과대적합 확률을 낮춰주지만 훈련 세트에 대한 성능 또한 낮아지기 때문에 사용자는 alpha 매개변수로 훈련 세트와 성능 대비 모델을 얼마나 단순화할지 정할 수 있다. 최적의 alpha 값은 데이터셋에 따라 달라지기 때문에 잘 조절해야 한다.
Ridge 값을 높이면 계수가 거의 0에 가까워지게 때문에 일반화는 잘 되지만 훈련 세트의 성능이 떨어지게 된다.
💭python
#alpha값 조절 -- alpha = 10
ridge_model10 = Ridge(alpha=10).fit(train_X, train_y)
print("훈련 세트: {:.2f}, 테스트 세트: {:.2f}" \
.format(ridge_model10.score(train_X, train_y), ridge_model10.score(test_X, test_y)))🗯result
훈련 세트: 0.79, 테스트 세트: 0.64alpha 값을 매우 줄이면(alpha = 0.0000001) 계수를 거의 조절하지 않기 때문에 LinearRegression으로 만든 모델과 거의 비슷해진다.
💭python
#alpha값 조절 -- alpha = 0.1
ridge_model01 = Ridge(alpha=0.1).fit(train_X, train_y)
print("훈련 세트: {:.2f}, 테스트 세트: {:.2f}" \
.format(ridge_model01.score(train_X, train_y), ridge_model01.score(test_X, test_y)))🗯result
훈련 세트: 0.93, 테스트 세트: 0.77이 코드에서는 alpha = 0.1인데 꽤 좋은 성능을 낼 수 있었다. 따라서 테스트 세트에 대한 성능이 높아질 때까지 alpha 값을 줄일 수 있을 것이다
💭python
#alpha 값에 따라 coef_속성이 어떻게 달라지는지 조사
#alpha 값이 커지면 coef_가 작아짐
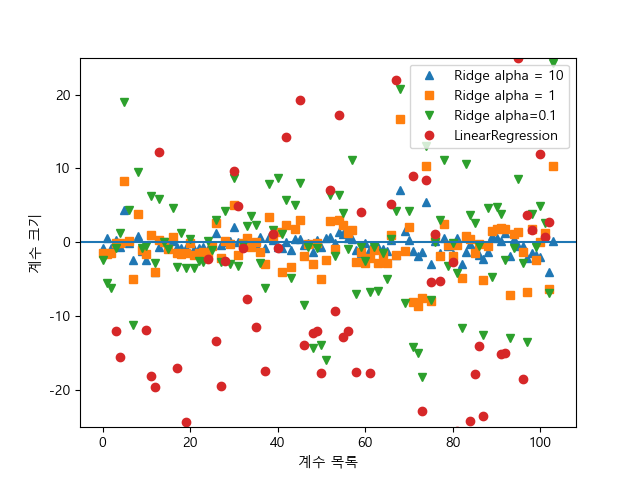
plt.plot(ridge_model10.coef_, '^', label='Ridge alpha = 10')
plt.plot(ridge_model.coef_, 's', label = 'Ridge alpha = 1')
plt.plot(ridge_model01.coef_, 'v', label = 'Ridge alpha=0.1')
plt.plot(lr.coef_, 'o', label = 'LinearRegression')
plt.xlabel('계수 목록')
plt.ylabel('계수 크기')
plt.rc('font', family = 'Malgun Gothic')
plt.rcParams['axes.unicode_minus'] = False
xlims = plt.xlim()
#수평선 그리기(y, x최소값, x최대값), x값 처음부터 마지막까지 라인을 그리기
plt.hlines(0, xlims[0], xlims[1])
plt.xlim(xlims)
plt.ylim(-25, 25)
plt.legend()
plt.show()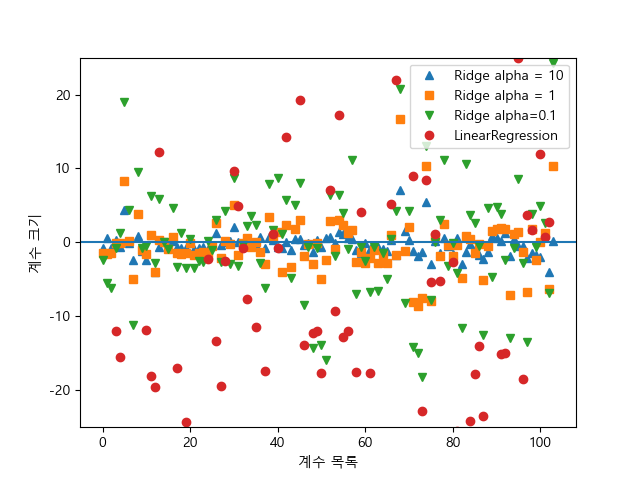
x값은 coef_의 원소를 위치대로 표현한 것이고 y축은 계수의 크기를 보여준다. 그림을 보면 확실히 ridge alpha의 값이 커질수록 규제가 커져 계수크기가 0에 가까워지는 것을 확인할 수 있다.
규제의 효과를 이해하는 또 다른 방법은 alpha의 값을 고정하고 훈련 데이터의 크기를 변화시켜 보는 것이다. 이때 데이터셋의 크기에 따른 모델의 성능 변화를 나타낸 그래프를 학습 곡선(learning curve)라고 한다.
💭python
#학습 곡선 그려보기
mglearn.plots.plot_ridge_n_samples()
plt.show()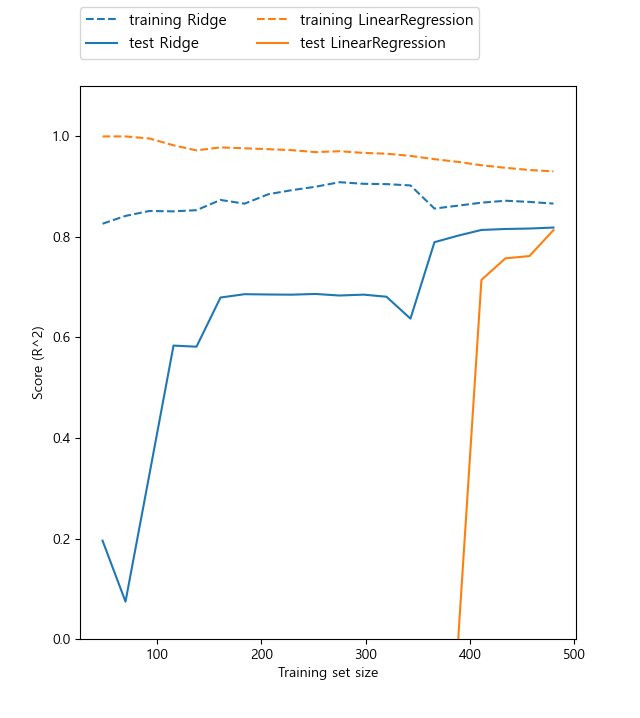
그래프를 보면 알 수 있듯이 Ridge는 규제를 받기 때문에 train set의 성능이 LinearRegression보다 떨어진 것을 확인할 수 있다. 또한테스트 세트의 경우 Ridge의 성능이 LinearRegression보다 더 좋고, ridge와 LinearRegression 모두 training set의 크기가 커질수록 성능이 더 좋아진다. 그러나 training set size가 커질수록 LinearRegression의 성능이 Ridge의 성능을 따라잡게 되는데 이는 training set size의 크기가 커질수록 규제의 영향 덜해진다는 사실을 알 수 있다. 또한 선형회귀의 훈련데이터 성능이 점점 더 떨어지는데 이는 데이터 사이즈가 커질수록 과대적합되기가 어렵기 떄문이다.
출처
https://www.scribbr.com/statistics/simple-linear-regression/
