#1 분류와 회귀
지도학습에는 분류와 회귀가 있다
분류는 어떠한 변수에 영향을 받는 결과를 연속적이지 않은 값들로 나눌 때 사용한다. 분류는 여성/남성과 같이 두 개의 클래스로 분류하는 이진 분류와 A/B/C/D/F와 같이 셋 이상의 클래스로 분류하는 다중 분류로 나뉜다.
회귀는 연속적인 숫자, 또는 프로그래밍 용어로 말한다면 부동소수점수를 예측하는 것이다. 예를 들어 시험 공부에 투자한 시간(변수)에 따라 예상되는 기말고사 점수(연속적인 실수)를 추측하는 모델이 있다.
분류와 회귀를 구분하는 방법에는 출력 값에 연속성이 있는지 질문해보면 알 수 있다. 예상 출력값에 연속성이 있다면 회귀 문제이다.
#2 일반화, 과대적합, 과소적합
지도학습에서는 Test data로 학습한 모델이 Test 데이터와 특성이 같다면 처음 보는 새로운 데이터가 주어져도 정확히 예측할 거라 기대한다. 모델이 처음 보는 데이터에 대해 정확하게 예측할 수 있다면 이를 훈련 데이터에서 테스트 데이터로 일반화되었다고 한다. 직관적으로, 수학적으로도 간단한 모델이 새로운 데이터에 대해 더 잘 더 잘 일반화할 것이라고 예상할 수 있다. 이와 반대로 너무 많은 정보를 사용해서 복잡한 모델을 만드는 것을 과대적합, 데이터의 면면과 다양성을 잡아내지 못하고 간단한 모델이 선택되는 것을 과소적합이라고 한다.
모델을 복잡하게 할수록 훈련 데이터에 대해서는 더 정확하게 예측할 수 있다. 그러나 너무 복잡해지면 훈련 세트의 각 데이터 포인터에 민감해져 새로운 데이터에 잘 일반화되지 못한다.
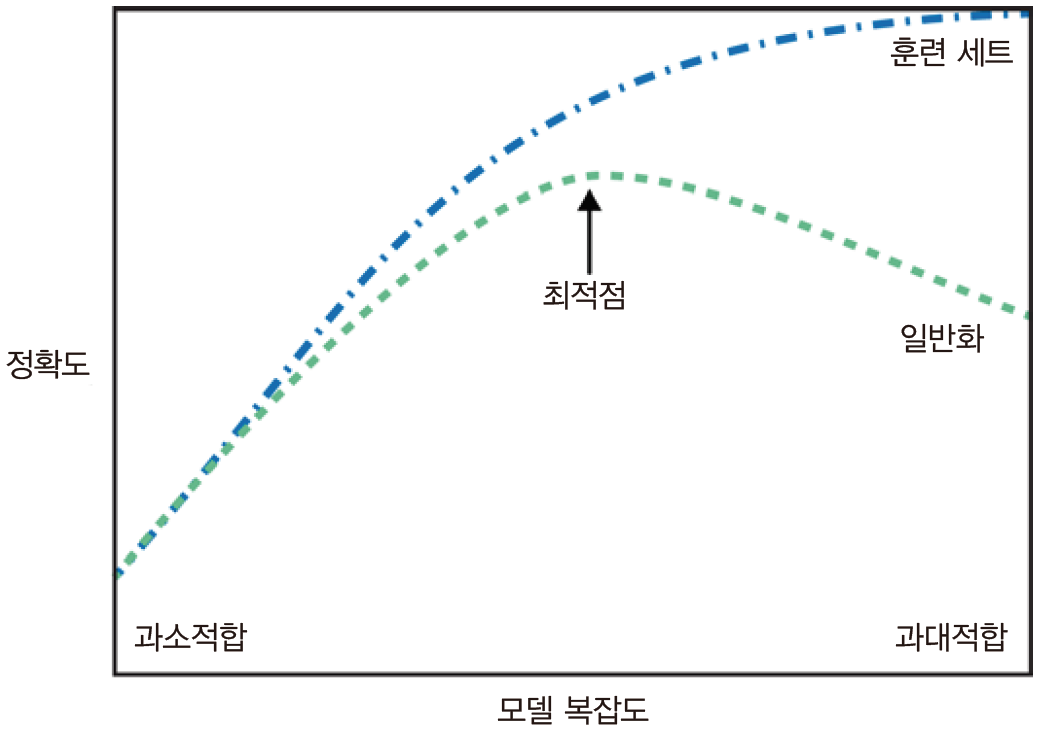
우리가 찾으려는 모델은 일반화 성능이 최대가 되는 최적점에 있는 모델이다.
2.1 모델 복잡도와 데이터셋 크기의 관계
모델의 복잡도는 훈련 데이터셋에 담긴 입력 데이터의 다양성과 관련이 깊다. 데이터가 다양할수록 과대적합 없이 더 복잡한 모델을 만들 수 있다. 보통은 많은 데이터셋이 다양성을 키워주므로 큰 데이터셋을 더 복잡한 모델을 만들 수 있게 해준다. 그러나 같은 데이터 포인트를 중복하거나 비슷한 데이터를 모으는 것은 도움이 되지 않는다.
2.3 지도 학습 알고리즘
2.3.1 예제에 사용할 데이터셋
어떤 데이터셋은 알고리즘의 특징을 부각하기 위해 작고, 인위적으로 만든 것도 존재하고 실제 샘플로 만든 큰 데이터셋도 존재한다
다음 코드는 이진 분류 데이터셋인 forge 데이터셋을 산점도로 그린 것이다. x축은 첫 번째 특성, y축은 두 번째 특성을 나타낸다.
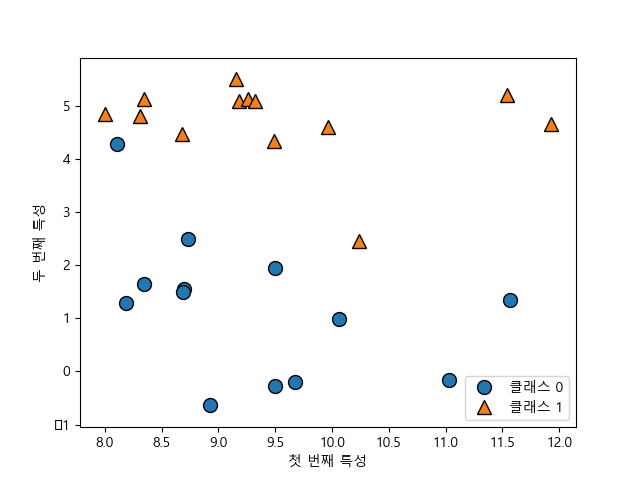
코드:
###Machine Learning - book: Introduction to Machine Learning with Python
import mglearn
import matplotlib.pyplot as plt
#make datasets, mglearn이라는 모듈에서 forge라는 데이터셋을 불러온다는 의미
X, y = mglearn.datasets.make_forge()
#x의 형태와 y의 형태를 확인한다
print(X, '\n', type(X), '\n', X.shape)
print(y, '\n', type(y), '\n', y.shape)
#산점도를 그린다. x[:, 0], x[: 1]이 각각 x축, y축이 되고 (x, x')쌍마다 y에 있는 정답값이 1:1로 할당된다
mglearn.discrete_scatter(X[:, 0], X[:, 1], y)
#한국어가 깨지는 것을 막기 위한 폰트 설정
plt.rc('font', family = 'Malgun Gothic')
#legend 함수의 loc 파라미터를 이용해서 범례가 표시될 위치를 설정
plt.legend(["클래스 0", "클래스 1"], loc = 4)
plt.xlabel("첫 번째 특성")
plt.ylabel("두 번째 특성")
plt.show()다음은 인위적으로 만든 wave 데이터셋을 표현한 코드이다. 회귀 알고리즘 설명에 사용된다.
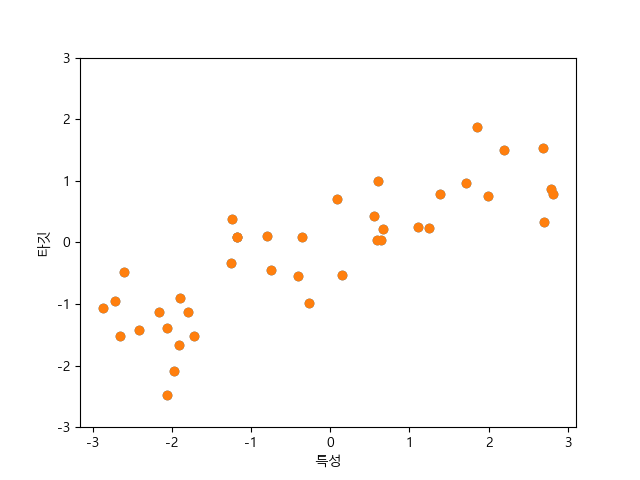
코드:
#인위적으로 만든 wave 데이터셋 사용, 표본은 40개
X, y = mglearn.datasets.make_wave(n_samples = 40)
#X, y 값 확인
print(X, '\n', type(X), '\n', X.shape)
print(y, '\n', type(y), '\n', y.shape)
#plot으로 데이터셋 그리기
plt.plot(X, y, 'o')
plt.rc('font', family = 'Malgun Gothic')
#마이너스 표현이 안될 떄 설정
plt.rcParams['axes.unicode_minus'] = False
plt.ylim(-3, 3)
plt.xlabel("특성")
plt.ylabel('타깃')
plt.show()실제 데이터셋인 위스콘신 유방암 데이터셋을 표현한 코드이다. 이 데이터셋은 유방암 종양의 임상 데이터를 기록해놓았다.
###############################위스콘신 유방암 데이터셋 표현#####################
from sklearn.datasets import load_breast_cancer
import numpy as np
cancer = load_breast_cancer()
#keys()는 딕셔너리에서 key값만 빼올 수 있는 함수
print('cancer.keys() : \n', cancer.keys())
print("유방암 데이터의 형태: ", cancer.data.shape)
print(cancer.target_names)
print(cancer.target)
#zip() 함수는 여러 개의 순회 가능한 객체를 인자로 받고, 각 객체를 튜플형태로 차례로 접근할 수 있는 반복자를 반환한다
#bincount는 0부터 객체의 최대값까지 각 원소의 빈도수를 계산한다
#212개는 악성, 357개는 양성
print("클래스별 샘플 개수: \n", {n: v for n, v in zip(cancer.target_names, np.bincount(cancer.target))})
print("특성 이름: \n", cancer.feature_names)
print("자세한 특성 설명: \n", cancer.DESCR)다음은 회귀 분석용 실제 데이터셋으로 보스턴 주택가격 데이터셋을 표현한 코드이다. 이 데이터셋으로는 범죄율, 찰스강 인접도, 고속도로 접근성 등의 정보를 이용해서 1970년대 보스턴 주변의 주택 평균 가격을 예측하는 것이다.(이 데이터셋은 ethical한 문제로 인해 1.2 버전에서는 삭제될 것이다.)
##########################보스턴 주택가격 데이터셋###############################
from sklearn.datasets import load_boston
boston = load_boston()
print("데이터의 형태: ", boston.data.shape)
#이때 13개의 입력 특성뿐만 아니라 특성끼리 곱하여(또는 상호작용이라 부름)
#의도적으로 확장하겠다. 이처럼 특성을 유도해내는 것을 특성 공학이라고 한다
X, y = mglearn.datasets.load_extended_boston()
print("X.shpae: ", X.shape)출처
https://www.androidhuman.com/2018-03-04-ml_for_everyone_basics_01
Intorduction to Machine Lenaring with Python - 안드레아스 뮐러, 세라 가이도
https://tensorflow.blog/%ED%8C%8C%EC%9D%B4%EC%8D%AC-%EB%A8%B8%EC%8B%A0%EB%9F%AC%EB%8B%9D/2-2-%EC%9D%BC%EB%B0%98%ED%99%94-%EA%B3%BC%EB%8C%80%EC%A0%81%ED%95%A9-%EA%B3%BC%EC%86%8C%EC%A0%81%ED%95%A9/

글 잘 봤습니다, 감사합니다.