[논문리뷰] Learning Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks (DCGAN)
0
[논문리뷰] GAN
목록 보기
2/3
Intro
- 2014년 Ian Goodfellow가 GAN이라는 적대적 학습 기반의 새로운 생성 모델 프레임워크를 제안했지만, 이 방법은 representation을 비지도적으로 학습하는 Generator와 Discriminator가 간단한 형태의 MLP였다.
- GAN의 architecture을 일반적으로 Image Recognition에서 많이 사용하는 CNN으로 바꾸어 성능을 개선한 연구인 'Learning Unsupervised Representation Learning with Deep Convolutional Generative Adversarial Networks(Alec & Luke et al. Arxiv) 논문을 소개한다.
Abstract & Introduction
- CNN을 이용한 supervised learning은 computer vision 분야에서 널리 사용되어왔다.
- 그에 비해 CNN을 이용한 unsupervised learning은 상대적으로 덜 주목받아왔다.
- 이 연구에서 Deep Convolutional Generative Adversarial Networks (DCGAN)을 소개하고, unsupervised learning에 널리 활용될 수 있음을 주장한다.
- DCGAN이 deep convolutional 구조에 의해, Generator와 Discriminator에 대해 모두 hierarchial하게 representation을 학습할 수 있음을 보인다.
- 더해서 novel한 task에 학습된 feature을 사용해봄으로써 representation의 applicability를 보인다.
- unlabeled dataset에 대해 reusableg한 feature representation을 학습하는 것은 활발히 연구되어 왔다.
- GAN은 maximum likelihood를 통한 unsupervised learning으로 이미지 생성을 학습하며, generator와 discriminator을 supervised task에 feature extractor로 활용하는 후속 연구가 있었다.
- 그러나 GAN은 학습이 불안정하고, 종종 nonsensical한 output을 낸다는 문제가 있다고 알려져왔다.
- 해당 연구에서는 다음과 같은 contribution을 갖는다.
- Convolutional GAN의 구조를 architectural topology 측면에서 contstarint한다. 이를 Deep Convolutional GAN이라고 명명한다.
- 학습된 discriminator를 image classification task에 대해 학습해서, 다른 unsupervised algorithm과 competitive한 성능을 보이게 한다.
- GAN에 의해 학습된 filter들을 시각화한다.
- Generator가 vector arithmetic property를 가지고, 이를 통해 generated sample의 semantic quality를 쉽게 manipulation할 수 있음을 보인다.
2. Related Work
2.1 Representation Learning from Unlabeled Data
2.2 Generating Natural Images
2.3 Visualizing The Internals of CNNs
- 고전적인 논문이므로 Related Work는 생략. 배경 지식이 없어도 GAN과 CNN에 대한 이해만 있다면 쉽게 이해할 수 있다.
3. Approach and Model Architecture
- 지금까지 CNN을 사용해서 GAN을 scale up하려는 시도는 있었으나, 성공적이지 못했다.
- 여러 시도를 통해 stable한 학습과, 더 깊은 generative model, higher resolution에 대한 Image Synthesis를 가능하게 하는 model architecture을 찾는 데 성공했다.
- 성공의 핵심 요인은 총 3가지이다.
- 첫 번째로, deterministic spatial pooling function (e.g. maxpooling)을 strided convolution으로 대체하여, network가 고유한 spatial downsampling을 학습할 수 있게 한다.
- 이를 통해 generator를 strided downsampling을, discriminator는 spatial upsampling을 학습할 수 있도록 했다.
- 두 번째로, convolutional feature의 맨 끝에 대해 원래는 fully connected layer을 많이 사용했지만, 이를 제거하는 것이 trend가 되었다.
- 이를 Global Average Pooling으로 대체하여 성공했던 시도가 있었지만, GAP를 사용하는 것이 stability는 높이는 반면 convergence speed를 해친다는 것을 발견했다.
- GAN의 첫 layer에서는 noise distribution 를 입력으로 받아 matrix multiplication (FC) 하지만, 결과는 4-dimensional tensor로 reshape된 뒤 convolution layer의 첫 입력으로 들어간다.
- Discriminator의 마지막 output을 flatten 연산한 뒤 sigmoid를 거쳐 output으로 나온다.
- 세 번째로, Batch Normalization을 적용했다.
- Input을 batch 단위로 normalize하여 각 unit이 zero mean, unit variance를 갖도록 함으로써 poor initialization로 인해 생기는 training problem을 해결해준다.
- Deep Generator가 학습을 시작하는 데 중요한 (긍정적인) 영향을 끼치고, 학습이 collapse(붕괴)되는 걸 방지해준다.
- 한편, 모든 layer에 batchnorm을 적용하는 것은 학습을 불안정하게 하고 sample oscillation을 일으킨다는 문제가 있었다. 일부 layer (Generator output, Discriminator Input layer)에서 batch normalization을 제거함으로써 해결할 수 있었다.
- 이를 다음과 같이 정리하고, 'Architecture Guidelines for stable Deep Convolutional GANs'로 제안했다.
- 모든 pooling layer을 strided convolution(D), fractional-strided convolution(G)으로 대체
- generator와 discriminator에 batch normalization 적용
- Deeper architecture을 위해 fully connected hidden layer 제거
- generator에서 마지막 layer에 tanh를 적용하는 것을 제외하고 ReLU activation 사용
- discriminator에서는 LeakyReLU 적용
4. Details of Adversarial Training
- Image를 tanh로 [-1, 1]로 scaling하는 것 이외에는 preprocessing X
- B = 128, minibatch SGD
- 로 weight initialization
- Adam optimizer, lr = 0.0002 (0.001로 설정했던 이전의 접근은 lr이 너무 크다고 판단)
- (0.9로 설정했던 이전의 접근은 training oscillation, instability 유발, 0.5로 하면 안정적으로 학습 가능)
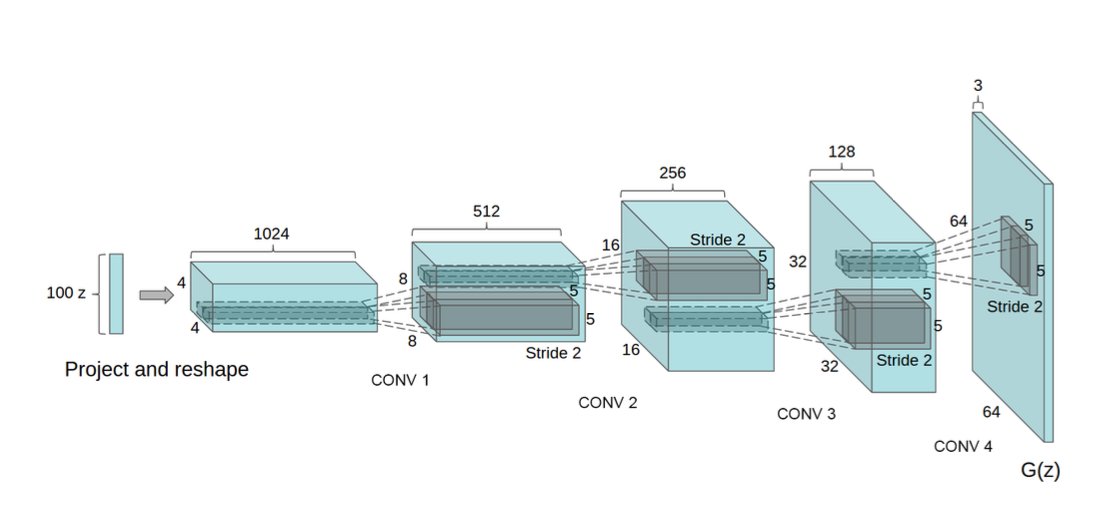
- 100 dimension의 noisy latent 를 Convolution-Upsampling ... 을 반복하여 64x64 pixel image 로 만든다.

- ImageNet-1k, LSUN Bed에 대해 실험
5. Empirical Validation of DCGANs Capabilities
- 당시에는 Unsupervised representation learning에 CNN을 사용하는 것이 익숙하지는 않았던 시기라서, learned representation의 활용의 다양성을 제안했다.
- Generator을 feature extractor로 활용하여 Image classification에 적용해보는 실험 (결과 생략)
6. Investigating and Visualizing the Internals of the Networks
6.1 Walking in the Latent Space
6.2 Visualizing the Discriminator Features
6.3 Forgetting to Draw Certian Objects
- Deep Convolution 기반의 network의 내부를 들여다보는 다양한 접근을 다루는 섹션인데, 아주 고전적인 논문이다 보니... 간단하게 vector arithmetic에 대한 설명만 하고 넘어가려 한다.
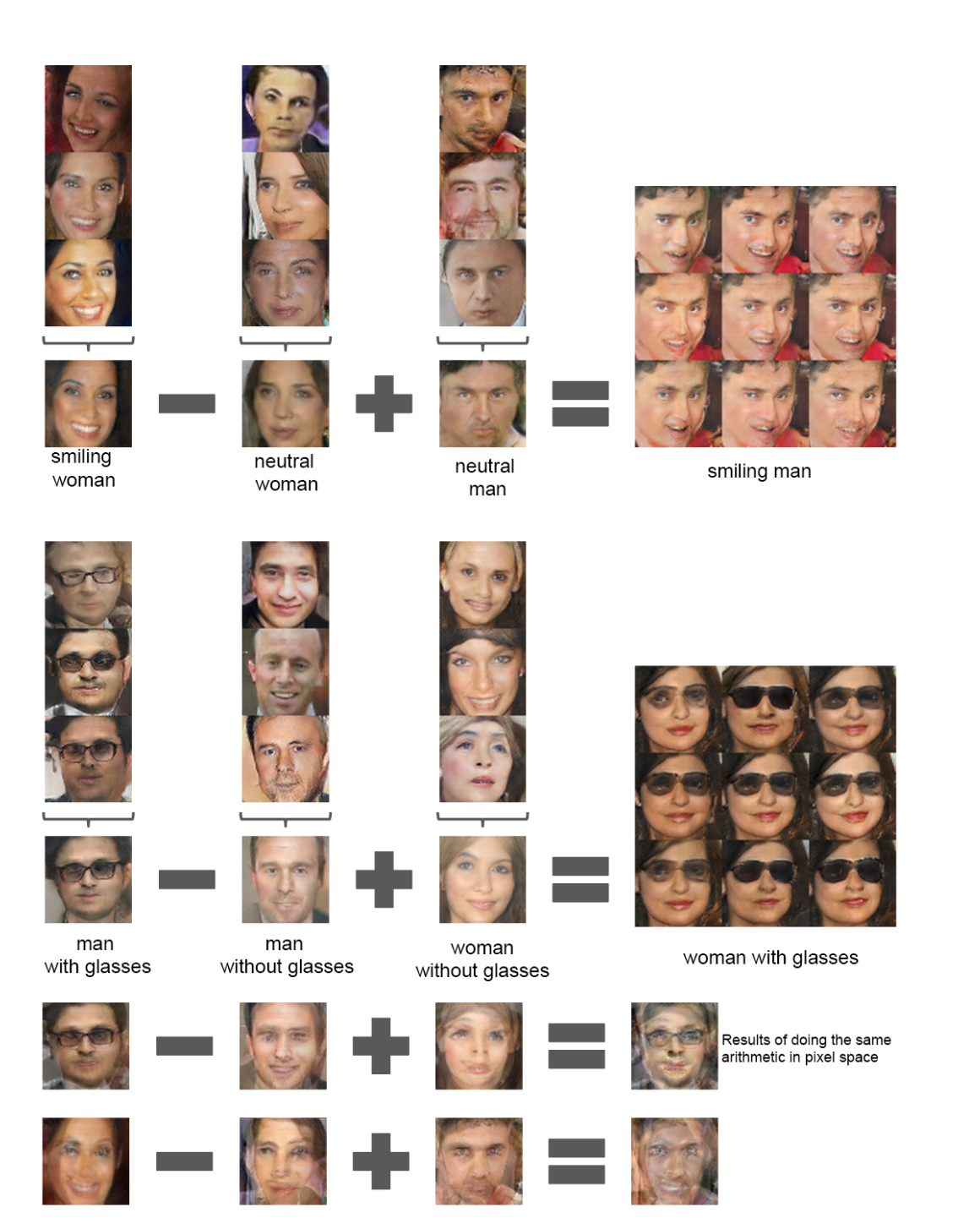
6.3.2 Vector Arithmetic On Face samples
- Word2Vec (NeuRIPS 2013)에서는 word의 learned representation에 대한 simple arithmetic operation을 통해 representation space의 rich한 linear structure을 소개했다.
- 예를 들어, vector("King") - vector("Man") + vector("Woman") 연산을 한 벡터에 NN을 취하면 vector("Queen")이 되는 것처럼
- 이를 latent vector 가 속해 있는 latent space 에 대해서도 비슷하게 적용할 수 있음을 확인했다.
- latent vector 간의 arithmetic 연산으로, 생성되는 이미지 간의 linear interpolation이 가능함을 논한다.
- 이후에도 StyleGAN 등에서 비슷한 개념이 많이 등장한다.


Master Student @ KAIST CS / Generative Modeling