[논문리뷰] A Style-Based Generator Architecture for Generative Adversarial Networks (StyleGAN1)
[논문리뷰] GAN
Intro
- 2014년 Ian Goodfellow가 GAN이라는 적대적 학습 기반의 새로운 생성 모델 프레임워크를 제안한 뒤로, GAN은 생성모델 분야에 새로운 패러다임을 가져왔고 GAN에 대한 연구가 활발히 진행되어 왔지만, 지금까지는 GAN이 만들어내는 이미지를 쉽게 조작할 수 없었다.
- Style Transfer에서 아이디어를 얻어 GAN의 architecture을 수정하고, 기존의 space 상에서의 sampling이 아닌 space라는 새로운 vector space로부터 sampling하여 이미지를 합성하는 새로운 접근으로 GAN의 controllability를 높인 'StyleGAN' 시리즈의 시초인 StyleGAN1 (CVPR 2019, Tero et al.)논문을 리뷰한다.
- 이 논문도 상당히 오래되었지만, 후술할 StyleGAN2, ADA, 3 시리즈까지 논문이 굉장히 체계화되어있으며 잘 쓰여져 있고, space로부터 latent를 가져와 sampling하는 아이디어, GAN Inversion 등에 요즘에도 활용되고 있다는 점에서 StyleGAN 1부터 꼭꼭 씹어먹으며 정리해보려 한다. 상당히 긴 여정이 될 수 있겠다.
Abstract & Introduction
-
Style Transfer 논문으로부터 아이디어를 빌려, 새로운 형태의 Generator architecture를 가진 GAN framework를 제안한다.
-
우리가 제안하는 모델은 high-level attributes (e.g. human face 상에서 pose나 identity와 같은 디테일함) 을 비지도적으로 구분하고, 생성되는 이미지의 확률적 다양성 (frickle, hair)을 자동적으로 학습하며, 이는 synthesis의 control을 가능하게 해준다.
-
traditional한 quality metric들에 대해 state-of-the-art를 달성하고, FFHQ dataset을 새롭게 소개한다.
-
latent space로부터 이미지를 생성하는데, 지금까지는 latent space에 대한 이해가 부족했고 제안된 latent space interpolation들은 generator 간에 비교할 수 있는 정량적인 방법을 제공하지 않았다.
-
Style Transfer에서 아이디어를 얻어, Generator의 구조를 다시 디자인하여 Image Synthesis process를 control할 수 있게 한다.
-
noisy latent 를 직접적으로 Generator에 넣기보다는, latent code에 대한 convolution 연산을 통해 image의 style을 조정한다.
-
한편 discriminator나 loss function은 전혀 구조를 바꾸지 않았다.
-
Generator는 input latent code를 'intermediate latent space'로 mapping하고, 이는 variation의 factore들이 network 내에서 어떻게 represent되는지 알 수 있는 효과가 있다.
-
기존의 접근에서는 input latent space가 training data의 probability density를 따라야 하고, 이는 피할 수 없는 disentanglement를 유발한다.
-
PPL과 linear separability라는 두 가지 metric을 제시한다. 이러한 metric을 통해 우리가 제시하는 generator architecture가 traditional approach보다 (different factors of variation에 대해) 더 linear, less entangle한 representation을 얻어낼 수 있음을 확인할 수 있었다.
2. Style-based Generator
- 전통적으로 latent code는 input layer(Feed-forward Network)을 통해 제공된다. 하지만 본 논문의 접근에서는 input layer을 제거하고, 학습된 constant (Linear Transform)로 이를 대체한다.
- 주어진 latent space 상에 존재하는 latent code 에 대해, non-linear mapping network 을 거쳐 을 만들어낸다. 이 때 8개의 FC Network로 mapping network를 구성했다.
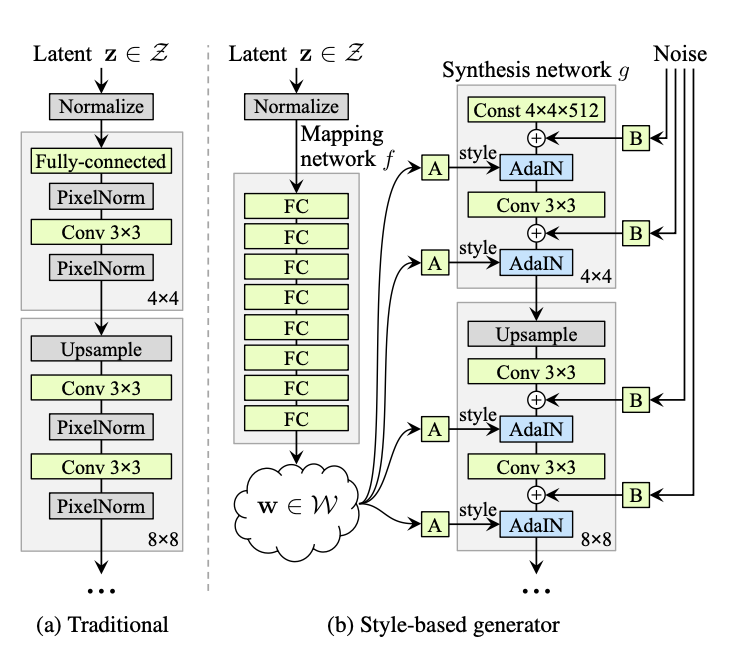
- mapping network를 통해 얻은 는 synthesis network 내에서 라고 표현하는 의 형태로 AdaIN operation에 사용된다. AdaIN operation은 다음과 같이 정의된다.
-
AdaIN 연산을 통해 각 feature map 는 normalize 후 style scalar 에 의해 scaling, biasing된다.
-
Style Transfer와 StyleGAN을 비교해보면, StyleGAN에서는 example image를 계산하는 대신, spatially invariant한 style 을 계산한다.
-
마지막으로, 우리는 noise input을 Generator의 중간 입력에 noisy input을 명시적으로 넣어줌에 따라, generator가 stochastic detail을 잡도록 했다. noise가 넣어지는 위치는 AdaIN 또는 Upsample 연산을 거친 뒤 3x3 convolution을 거친 이후이다.
-
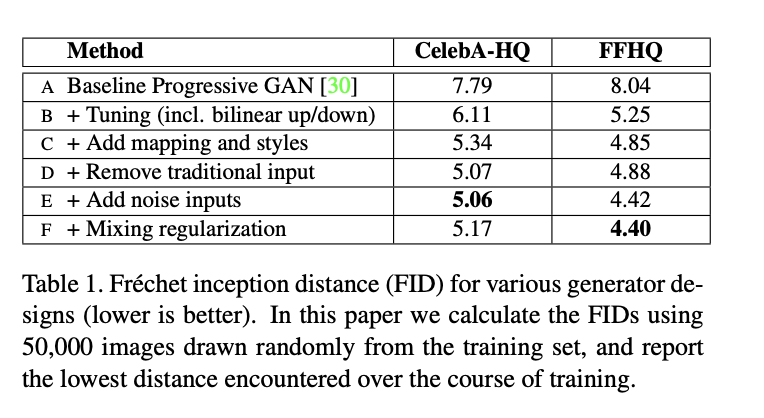
Progressive GAN의 Generator을 base로 하여 method를 추가했다. 각 method에 대한 설명은 다음과 같다.
- (B): bilinear upsampling, downsampling operation 적용, 더 많은 학습 시간, hyperparameter tuning
- (C): mapping network를 추가하고, AdaIN operation 적용
- (D): traditional input layer을 제거하고, learned 4x4x512 tensor로부터 sampling 과정 시작
- (E) noisy input을 Generator 중간중간에 추가
- (F) mixing regularization (3에서 자세히 다룸.)
-
FFHQ dataset에 대해 FID를 비교
-
추가적으로, 지금까지의 GAN을 개선하려는 접근들은 discriminator을 개선하는 방식이었음. (multiple discriminator, multiresolution discrimination, self-attention 등..)
-
genearator을 개선하려는 접근은 latent space이 정확한 distribution을 갖도록 하거나, Gaussian mixture model로 latent space를 shaping하거나, clustering, convexity를 개선하는 등의 접근이었음.
-
우리는 intermediate latent space라는 새로운, latent의 특성을 더 잘 설명할 수 있고 유용한 space를 설명하며 input noise를 learnable netwokr로 embedding한다는 점에서 novelty가 있음.
3. Properties of the style-based generator
-
StyleGAN을 통해 style에 대한 scale-specific modification을 통해 image synthesis를 control할 수 있게 되었음.
-
mapping network를 learned distribution으로부터 sample을 그리는 방법으로 해석할 수 있음.
-
Synthesis network는 style collection들을 base로 하여 novel한 image를 만들어내는 방법으로 해석할 수 있움.
3.1. Style Mixing
-
이러한 localization이 가능한 것은, AdaIN operation 때문이라고 생각할 수 있는데, AdaIN operation은 각 채널들을 zero mean, unit variance로 normalize한 뒤 style에 근거하여 각 채널들을 scaling하고 biasing하는 방식으로 feature들의 relative importance를 수정함.
-
Style localize를 더 개선하기 위해서, "mixing regularization"이라는 방법을 제시하는데, training 과정 동안 한 latent vector로부터 sampling하는 것이 아니라 2개의 random latent code로부터 generate하는 것이다.
-
이를 더 구체적으로 말하면, synthesis network 상에서 noisy input을 넣어주는 부분에 을 넣어주던 것의 일부를 를 넣는 것으로 대체하는 것이다. 그리고, 대응되는 는 어떤 crossover point를 지정하고 이전 지점까지는 를 넣어주고 그 이후로는 를 넣어주는 것이다. 이런 접근은 adjacent style (인접한 스타일)들이 correlate되어있다고 가정하는 것을 막아준다. 즉, style 간의 seperation을 돕는다.
3.2. Stochastic Variation
- human portrait에는 확률적으로 간주될 수 있는 많은 관점들이 있다. 예를 들어, 머리카락, 뭉툭함, 주근깨 또는 피부 모공의 정확한 위치와 같은 특성들처럼.
- Traditional Generator에서는, input layer의 입력으로 input만 들어가고, 이것이 network를 거치며 이미지가 만들어지는데, 이런 확률적인 다양성을 만들어내기 위해서는 network가 다양한 pseudorandom number들을 만들어내는 능려글 학습해야 한다.
- 이 과정에서 네트워크 capacity가 커져야 하고, 생성된 이미지에서 흔히 볼 수 있는 반복 패턴에서 알 수 있듯이 항상 성공적인 것은 아니다.
- 이를 네트워크가 학습해야 하는 것이 아니라 Convolution 직후에 per-pixel noise를 넣어주는 방식으로 접근하여 생성되는 이미지의 확률적 다양성을 증가시켰다. (E)
4. Disentanglement studies
