Introduction
MobileNet의 특징을 두 문장으로 정리하면, 다음과 같습니다.
- Not performance, but efficiency
- Simple hyperparameter tuning
대다수의 딥러닝은 고성능의 GPU환경과 고용량 메모리가 뒷받침되어야 합니다. 그에 따라 전력소모량도 엄청나겠죠. 그러나 소형 전자기기와 같이 성능이 제한되거나 배터리 퍼포먼스가 중요한 곳에서 사용되려면 성능도 중요하지만, 모델의 가벼움, 즉 효율성도 중요합니다. 그런 취지에서 MobileNet이 탄생하게 되었습니다.
MobileNet은 기존에 있던 방법과 아주 간단한 hyperparameter 조작만이 들어가 있습니다. 그러나 연산량과 parameter수를 크게 줄인 덕분에 소형 전자 기기안에서도 적당한 성능을 가지고 동작할 만한, 효율 좋은 모델이 될 수 있었습니다.
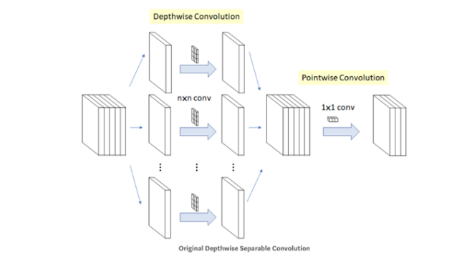
Xception처럼, mobileNet도 Depthwise Separable Convolution(DSC)을 사용합니다. 이 과정은 Xception글을 보면 설명이 되어있습니다.
여기서는 파라미터의 수를 중점으로 살펴보겠습니다.
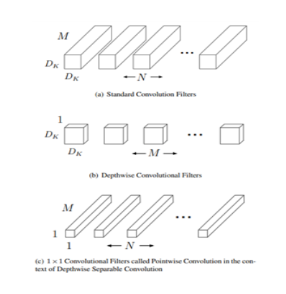
feature map의 가로, 세로값을 Df, 채널 수를 M, conv 필터의 가로, 세로값을 DK, conv 필터 수를 N이라고 하면 기존 CNN에서 output을 뽑기 위한 연산량은 아래 수식과 같습니다. 여기서 N은 output feature map이 가지는 채널 수 와도 같습니다.
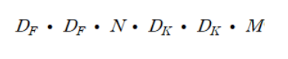
한편 DSC를 적용했을 때는, 이와 같은 수식이 연산량이 됩니다.
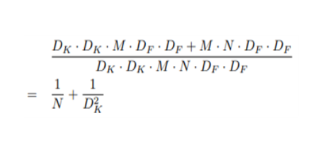
DSC를 적용했을 때의 효율은 아래 수식과 같으며 이는 8~9배의 속도 향상이라고 합니다.
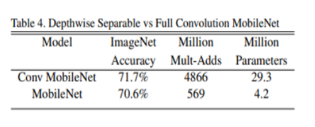
Table4에서는, 정확도가 1%정도밖에 차이 나지 않지만, DSC를 썼을 때 연산량과 파라미터수가 엄청나게 줄어드는 것을 볼 수 있습니다.
이처럼 이미 MobileNet은 충분히 작고 효율좋은 모델이지만 더욱 작고 효율이 좋은 모델이 필요할 때가 있습니다. 그럴 때 shrinking hyper parameter를 씁니다.
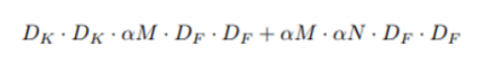
shrinking hyper parameter에는 두 가지가 있습니다.
첫 번째로 Width Multiplier (α) 입니다. α는 input과 output channel을 조절해주는 파라미터입니다. 전체적인 채널 수를 조절함으로써 더 thin한 모델을 만들 수 있습니다. alpha는 1보다 작은 값이며, default값은 1입니다. 논문에서는 1, 0.75, 0.5, 0.25로 실험했습니다.
적용한 수식은 위와 같습니다.
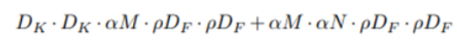
두 번째는 Resolution Multiplier (የ)입니다. የ는 input feature map의 크기를 조절합니다. የ는 1보다 작은 값이며, default값은 1입니다. 논문에선 기본 input resolution인 224가 የ가 적용되었을 때 224, 즉 የ=1인 경우, 192, 160, 128을 갖도록 하는 값으로 실험했습니다.
적용한 수식은 위와 같습니다.
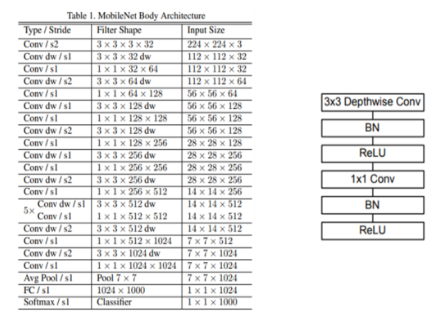
위 개념들을 적용한 MobileNet의 구조입니다. 오른쪽 도식화된 그림과 같이, Conv dw 부분, 즉 Depthwise conv필터 뒤에는 꼭 Batch Normalization과 ReLU함수가 들어갑니다. 물론 기본 convolution에도 BN과 ReLU는 들어갑니다.
다음은 실험 결과입니다.
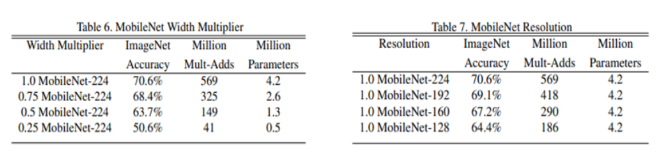
Table 6과 Table 7은 각각 Width Multiplier (α)만 적용했을 때와 Resolution Multiplier (የ)만 적용했을때의 정확도, 연산량, parameter 수 비교입니다. α는 위에서부터 1, 0.75, 0.5, 0.25의 값을 가지며, የ는 input feature map 크기가 224, 192, 160, 128이 되도록 하는 값을 가집니다.
정확도는 두 Shrinking hyper parameter가 작아질수록 떨어지지만, 그만큼 연산량과 파라미터수가 적어지는 것을 볼 수 있습니다.
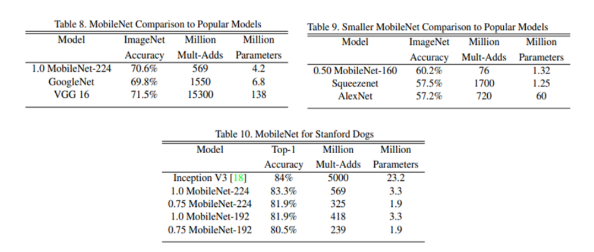
Table 8,9는 GoogleNet, VGG16, AlexNet, SqueezeNet과 비교했을때는 MoblieNet의 성능이 더 좋다는 것을 보여줍니다.
Table10은 Stanford dogs라는 데이터로 학습시켰을 때는 Mobile Net 이 Inception V3과 비슷한 성능이지만, 연산량과 파라미터 수가 월등히 작은 것을 보여줍니다.
