Seeing Implicit Neural Representations as Fourier Series는 highly detailed signal이 periodic activation function 또는 input에 fourier mapping을 적용함으로써 표현할 수 있고, 논문에서 제안하는 Fourier mapped perceptron이 SIREN의 히든 레이어 한층과 동일하다는 것이 핵심 내용입니다.
Introduction
INR은 spatial resolution에 결합되지 않고 무한한 resolution을 가지기 때문에 고차원 신호나 메모리를 많이 필요로 하는 application에 적합하다는 장점이 있습니다.
하지만, SIREN이전 architecture들은 high frequency의 detail들을 잘 표현하지 못했습니다. RELU는 부분적으로 선형이고, 2차 미분은 0이 되는것이 주된 이유였습니다.
그래서 SIREN은 sinusoid function을 적용하여 signal의 고차 도함수에 포함된 신호들까지 잘 모델링할 수 있었습니다.
그러다 최근들어 positional encoding이 나오면서 ReLU를 이용하더라도 high frequency information을 학습할 수 있게 되었습니다.
후속 연구에서는 general한 Fourier mapping을 탐색했는데, 해당 연구에서서 low standard deviation으로 random Fourier mapping(rFM)을 수행하면 signal의 low frequency만을, high std로 rFM을 진행하면 signal의 high frequency만을 학습할 수 있다는 것을 보여주었습니다.
또한 fourier mapping의 parameter를 늘릴수록 performance가 계속 증가한다는 것도 보여주었습니다.
여기서 저자는 몇가지 의문점을 갖게 됩니다.
- We wonder what the difference between SIRENs and Fourier mapping is?
- Will the performance be saturated when we continue to increase the mapping parameters?
- Is there a way to avoid over-fitting when training networks using Fourier mapping?
SIREN과 Fourier mapping의 차이는 무엇인가?
mapping parameter를 계속 증가시키면 performance가 포화상태가 되지는 않을까?
fourier mapping을 진행할 때 overfitting을 피할 방법이 있을까?
이에 대한 대답으로, 저자는 아래와 같은 contribution을 제시합니다.
- We introduce an integer Fourier mapping and prove that a perceptron with this mapping is equivalent to a Fourier series.
- We explore the mathematical connection between Fourier mappings and SIRENs and show that a Fourier mapped perceptron is structurally like a one hidden layer SIREN.
- We modify the progressive training strategy and show that it improves the generalization of the interpolation task.
- We compare the different mappings on the image regression and verify the previous findings that the main contributor to the mapping performance is the number of elements and standard deviation.
Method - Integer lattice mapping
Method section에서는 앞서 말했던 contribution들을 각 섹션마다 하나씩 나누어 설명하고 있습니다.
첫번째로 Integer lattice mapping입니다. 들어가기에 앞서, INR의 input signal에 대해 생각해봅시다. input domain은 예를 들어 이미지의 높이, 너비와 같이 제한된 input domain을 갖고 있으며 그들의 값 또한 유한한 집합내에 정의되어 있기 때문에 우리는 input을 input bound를 넘어 연속적이고, 주기적인 신호로 볼 수 있습니다. 그리고 이것은 푸리에 급수로 표현하기 위한 조건들을 모두 만족합니다.
푸리에 급수는 또한 input에 integer lattice mapping을 적용한 single perceptron과 동일합니다.
여기서는 fourier mapped perceptron과 fourier series의 general equation이 동일함을 보이고 있습니다.
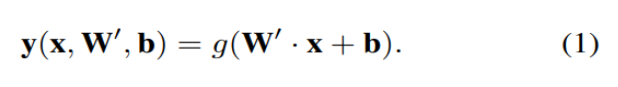
뉴럴네트워크의 기초적인 블록인 perceptron은 (1)과 같이 정의할 수 있습니다.
여기서 g는 activation function입니다.
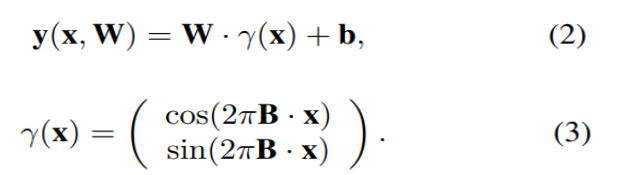
이제 g가 identity function이고, input에 fourier mapping γ(x)를 적용하면 식을 (2)와 같이 쓸 수 있습니다. 식 (2)가 fourier mapping을 input에 적용한 single perceptron을 수식으로 표현한 것입니다.
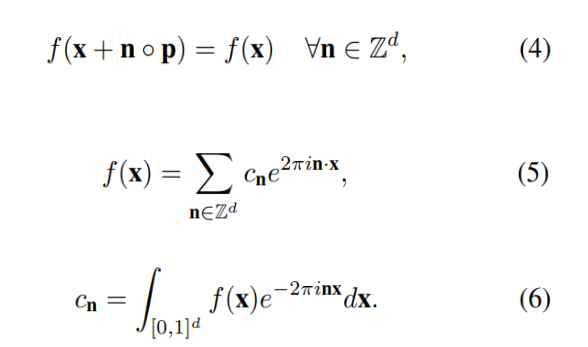
d_in차원에서 d_out차원으로 mapping하는 function f는 (4)와 같이 주기가 p인 주기함수로 볼 수 있으며 푸리에 급수로 표현하면 5번식이 됩니다.
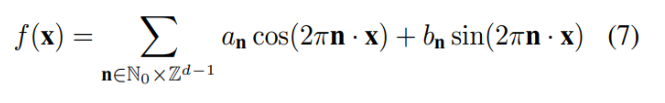
이것을 오일러 공식을 이용하면 (7)처럼 삼각함수의 합으로 표현할 수 있으며
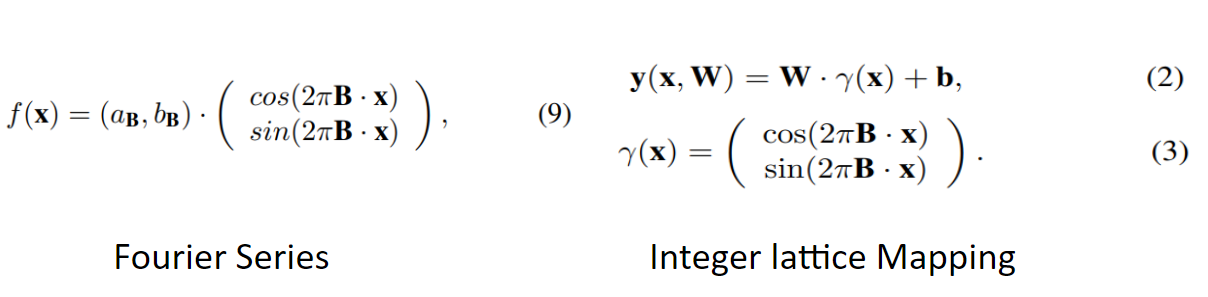
vector form으로 나타내면 (9)와 같습니다. 이제 perceptron을 나타내는 (2), (3) 과 푸리에 급수를 나타내는 9를 비교하면 W가 (a, b), b가 0일때 동일한 것을 볼 수 있는데 이로서 fourier mapping이 적용된 single perceptron이 fourier series이 동일한 것을 알 수 있습니다.
Method - SIRENs and Fourier mapping comparison

이 섹션에서는 fourier mapped perceptron이 하나의 hidden layer를 가지는 SIREN과 동일함을 보여줍니다.
이전의 식 (2) 에 (3)을 대입하고, sin과 consine을 합치면 (12)와 같이 쓸 수 있습니다.
이 식에서 C가 weight matrix로, pi가 bias vector로, sin함수가 activation function 역할을 수행한다고 볼 수 있는데, SIREN의 구조와 동일한 것을 알수 있습니다.
즉 Fourier mapping이 SIREN으로 표현될 수 있음을 보입니다.
Method - Progressive training
세번째 progressive training 섹션입니다. 저자는 BARF라는 논문에서, NeRF의 입력으로 넣는 positional encoding의 HF성분을 학습초기에는 masking하고 학습이 진행될수록 점점 unmask하는 training strategy전략을 fourier mapping에 적용하였습니다.
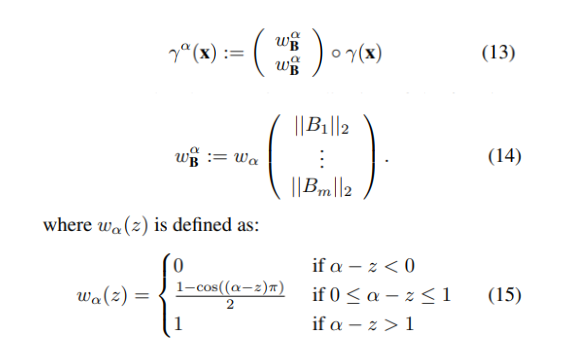
수식이 13, 14, 15와 같은데, 학습 후반부 HF성분이 들어왔을 때, 이미 network는 LF성분을 학습 초반에 학습완료했기 때문에 HF에 좀더 집중할 수 있게 되며, 이 strategy를 사용하면 overfitting을 줄일 수 있다고 합니다.
식(2)의 γ(x) 대신 위 γ_α(x)를 사용하면 progressive training이 됩니다.
Experiment
첫번째 실험은 integer mapping이 정말로 fourier series를 표현하는 것인지와 progressive training이 generalization에 도움이 되는지를 보여줍니다.
실험에는 3개의 fourier mapped perceptron을 사용했고, 각각의 perceptron이 image의 채널 각각에 대응합니다.
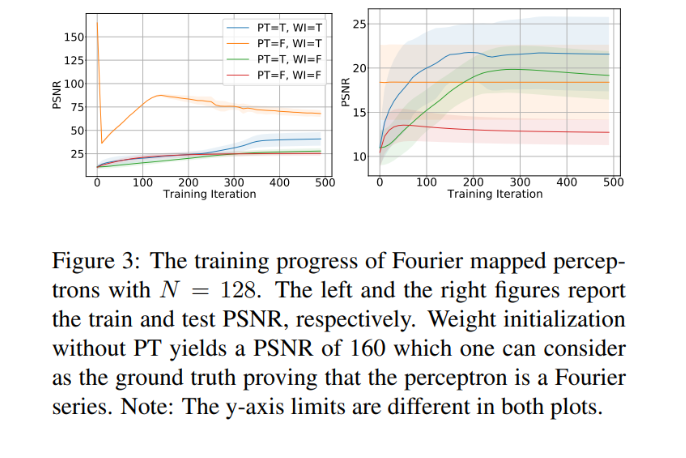
Figure 3을 먼저 보면, PT는 progressive training을 적용했는지의 여부, WI는 weight를 fourier coefficient로 초기화했는지의 여부를 나타냅니다. 왼쪽그래프에서 노란색은 weight initialization만 적용했을 때인데, PSNR이 150 이상인 것을 볼 수 있습니다. 이는 integer lattice mapping을 적용한 단일 perceptron이 fourier series라는 것을 증명하는 결과라고 합니다. 그런데 WI와 PT를 모두 적용한 파란색의 경우 PT가 HF성분을 학습 초기에 masking하기 때문에 초기 PSNR이 낮게 나오는 것입니다.
오른쪽 그래프에서는 PT를 적용한 것들이 test PSNR이 높게 나왔는데, 논문의 progressive training strategy가 generalization을 시켜준 것이라고 볼 수 있습니다.
마지막으로 PT와 WI가 모두 적용되지 않은 빨간색을 보면 training data에 overfitting된 것을 볼 수 있고, figure 2에서 격자선이 남아있는 것을 볼 수 있습니다.

두 번째 실험은 single perceptron에서 mapping freq를 다르게 했을 때 모델의 성능을 비교합니다. input에 gaussina mapping, integer mapping, position encoding, SIREN 4개를 비교한 결과가 figure 4, 5에 나타나 있습니다.
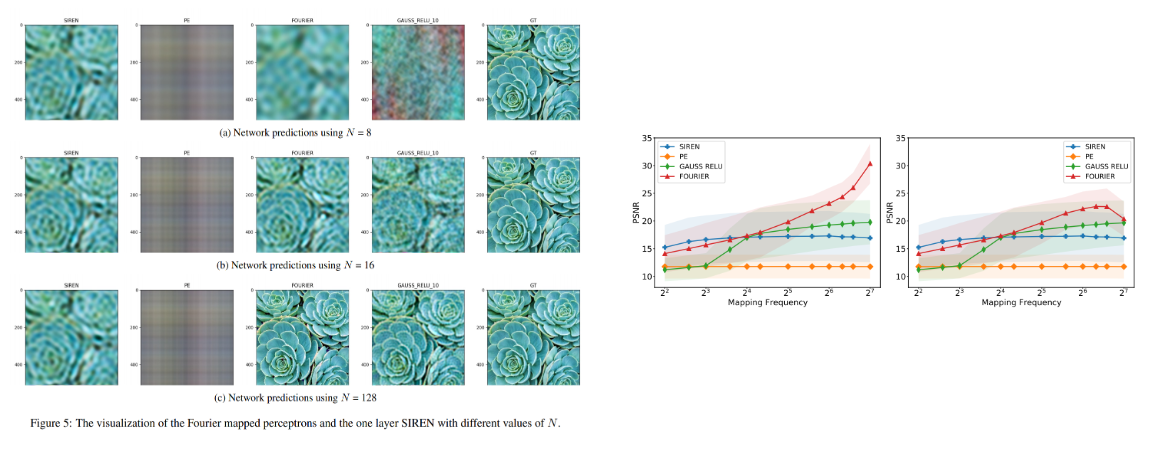
Figure 5a의 상황, N=8일때, 즉 mapping frequency가 작을 때를 보면 gaussian이 제대로 동작하지 않는 것을 볼 수 있습니다. sampling된 frequency 개수가 작기 때문에 image의 중요한 부분을 담고 있는 frequency를 sampling할 확률이 작기 때문에 발생한 현상입니다.
Fourier라고 써있는 이미지, 즉 integer mapped perceptron은 blur한 이미지가 output으로 나오는데, 이는 low frequency만을 학습했기 때문입니다. SIREN은 sampling에 상대적으로 영향을 덜 받기 때문에 상대적으로 잘 동작하는 것이라고 논문에서는 추정합니다.
N이 증가함에 따라 SIREN, Gaussian, Integer mapping의 performance가 증가하고 N=16에서 비슷한 성능을 보이는데, N이 더 증가하면 SIREN과 Gaussian은 포화상태에 도달하지만 논문에서 제시한 integer mapping이 outperform을 보인다고 합니다.
Conclusion
- we identified a relationship between the Fourier mapping and the general d-dimensional Fourier series, which led to the integer lattice mapping.
- From experiments, we showed that one perceptron with frequencies equal to the Nyquist rate of the signal is enough to reconstruct it.
- Furthermore, we showed that the progressive training strategy improves the generalization of the interpolation task.
논문에서는 Fourier mapping과 Fourier series(=integer lattice mapping)간의 연관성을 확인했으며,실험에서 하나의 퍼셉트론이 signal의 Nyquist rate이상의 주파수를 가지면, 입력 signal을 표현하는데 충분하다는 것을 보여주었습니다.
그리고 progressive training strategy가 interpolation task에서 일반화 성능을 향상시키는 것 또한 확인했습니다.
