1. Introduction
Object recognition의 performance를 올릴 수 있는 방법에는 더 강력한 모델로 학습을 하거나, 더 큰 데이터셋을 준비하거나, overfitting을 막을 수 있는 더 나은 기술을 사용하는 것이 있다. 하지만 dataset들중 labeling된 이미지들의 양은 상대적으로 적었다.
ImageNet이나 LabelMe와 같은 수백만장의 이미지의 수천개의 객체들을 recognition하기 위해서는 learning capacity가 큰 모델이 필요하고, 기존의 FFN(FeedForward neural Network)대신 CNN(Convolutional Neural Network)을 사용하면 파라미터는 더 적으면서 비슷한 성능에 도달할 수 있다.
그러나 CNN의 매력적인 특징이나 효율성에도 불구하고, high-resolution image들에 적용하기에는 여전히 비싸다. 다행히도 GPU를 이용하면 ImageNet과 같이 충분히 labeling된 sample을 가진 데이터셋에 대해서도 과적합 없이 학습을 할 수 있다.
모델의 contribution은 다음과 같다:
- ImageNet의 subset인 ILSVRC-2010, ILSVRC-2012 competition에서 사용된 데이터셋에 대해 CNN으로 학습하여 좋은 결과를 얻었다.
- 2D convolution의 highly-optimized GPU implementation을 제시한다.
- network의 성능을 향상시키고 학습 시간을 줄여주는 새로운 feature들을 제시한다.
- 네트워크의 방대한 크기에도 불구하고, overfitting을 방지하는 효과적인 techniques들을 서술한다.
- Final Network는 5개의 conv layer와 3개의 FC layer로 구성되어 있고, 이 구조를 변경하면 성능이 떨어지는것을 확인했다.
마지막으로, 현재 네트워크의 구조는 GPU의 메모리와 어느정도의 학습시간 내에서 동작하도록 제한되어있다. 이는 우리의 실험이 이후에 더 성능 좋은 GPU와 더 큰 데이터셋이 나오면 향상된 결과를 내놓을 수 있을것이라 기대한다.
2. The Dataset
ImageNet은 대략 22,000 카테고리에 속하는 high-resolution image 1500만장으로 이루어져 있다. ImageNet Large-Scale Visual Recognition Challenge(ILSVRC)는 ImageNet데이터셋중 1000개의 카테고리에 대하여 각 카테고리당 약 1000장의 이미지를 추출한 subset을 사용하며 120만장의 training image, 5만장의 validation image, 15만장의 testing image가 존재한다.
ImageNet에서는 top-1과 top-5 error rate를 사용하는데, top-5 error rate는 모델의 출력중 상위 5개의 확률에 해당하는 라벨에 정답라벨이 속하지 않을 비율이다.
ImageNet의 image들은 다양한 resolution을 가지고 있어, 직사각형이미지가 들어오면 짧은 쪽의 길이가 256이 되도록 rescale한 다음 256x256크기로 center crop하여 input dimensionality가 constant하도록 했다. 그리고 각각의 image pixel에 대해 train set의 평균 RGB값을 빼주는 전처리과정을 거쳤다.
3. The Architecture
모델의 아키텍쳐를 설명하는 섹션으로, section 3.1-3.4는 중요도 순으로 feature들을 설명한다.
3.1 ReLU Nonlinearity
neuron's output f를 입력x의 함수로 모델링하는 표준 방법은 또는 이다. Gradient descent를 사용할때 학습 시간의 관점에서, 앞의 두 함수와 같은 saturating nonlinearities들은 non-saturating nonlinearity 보다 느리다.
이러한 nonlinearity를 가진 neuron을 Rectified Linear Units(ReLUs)라고 하며, ReLU를 활성함수로 사용하는 Deep-CNN(DCNN)은 tanh를 활성함수로 사용하는 DCNN보다 몇배 이상 빠르다.
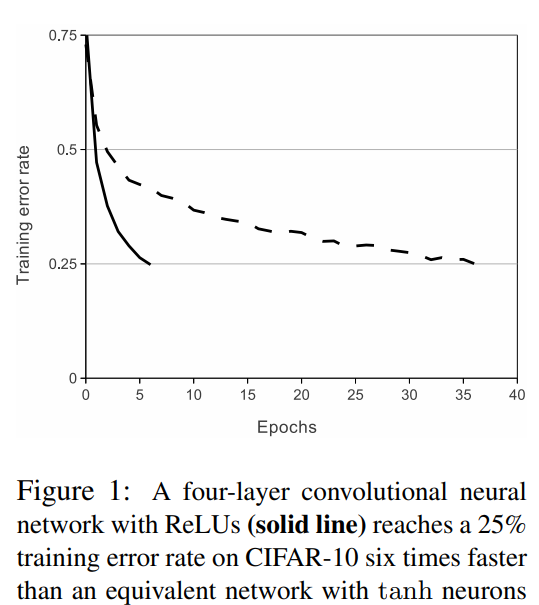
Figure1이 그것을 보여주는 실험으로, 네트워크 구조에 따라 정도는 다르지만, ReLU를 사용하는 Network가 일관적으로 Tanh를 사용하는 Network보다 몇 배 이상 빠르다.
3.2 Training on Multiple GPUs
논문에서 실험할 당시 GPU는 3GB 메모리의 GTX 580이었다. ILSVRC대회의 120만장의 학습데이터는 네트워크를 학습시키기엔 충분했으나, GPU에는 너무나 방대한 크기였다. 그래서 저자는 두 개의 GPU에 걸쳐 네트워크를 확장했다. 논문에서 채택한 parallelization
scheme은 각각의 GPU에 kernel(또는 neuron)의 절반씩 넣되, 이러한 GPU communicate는 특정 layer에서만 발생하도록 하는 방법이다.
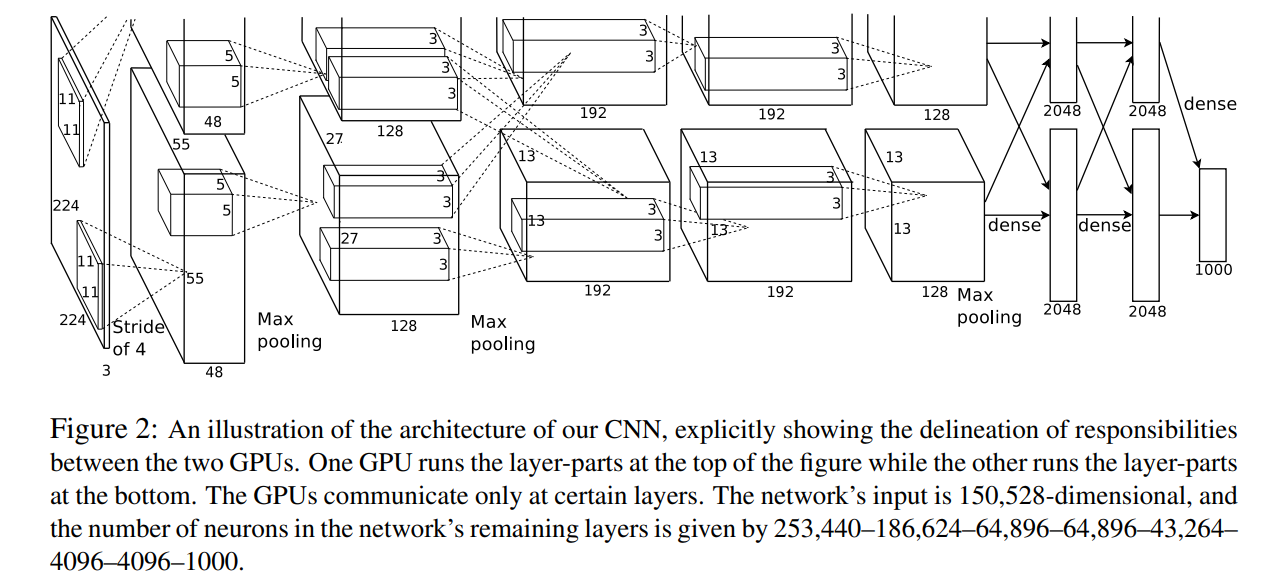
Figure 2는, 두개의 GPU중 하나는 위쪽을, 하나는 아래쪽 kernel을 맡아 동작하고 중간중간 communicate하며 parallelization을 구현한 것을 보여준다.
이러한 scheme는 단일 GPU로 network를 학습시켰을 때보다 top-1에러와 top-5에러를 각각 1.7%, 1.2%가량 줄일 수 있었다. 또한 학습 시간도 단일 GPU일때보다 약간 줄였다.
3.3 Local Response Normalization (LRN)
ReLU는 saturation 현상을 막기위한 Normalization이 필요없다는 속성을 갖고 있다. 하지만 아래와 같은 normalization이 일반화성능을 향상시킨다는 것을 발견했다.
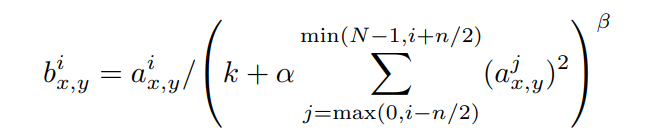
는 i번째 kernel을(x,y)좌표에 적용하고 ReLU nonlinearity를 적용한 것을 나타낸다.
은 동일한 spatial position에서 인접한 n개의 kernel을, 은 한 layer안에 있는 kernel의 총 개수이다.
는 validation set에서 사용하는 hyperparameter이다.
LRN은 특정 layer에서 ReLU를 적용한 다음 적용했다.
LRN을 적용하여 top-1에러와 top-5에러를 1.4%, 1.2%가량 줄였고, CIFAR-10 dataset에 대해서는 four-layer CNN이 LRN이 없을때 13%, 있을때 11%의 에러를 달성했다.
3.4 Overlapping Pooling
CNN에서 pooling은 동일한 kernel map에서 뉴런의 이웃한 그룹에 있는 output을 요약한다. pooling을 진행할 때, kernel size보다 stride를 작게 하면 overlapping pooling을 할 수 있으며 논문에서는 kernel size = 3x3, stride=2로 진행하였다.
이렇게 하여 top-1, top-5에러를 각각 0.4%, 0.3% 줄였다.
3.5 Overall Architecture
마지막 FC layer는 1000개의 class label의 분포를 생성하는 1000-way softmax로 이루어져 있다.
Figure 2에서, 2,4,5번째 conv(convolutional) layer는 동일한 GPU의 kernel map만을 받아온다. 3번째 conv layer의 kernel은 두번째 layer의 모든 kernel map과 연결되어있다(parallelization). LRN은 1,2번째 conv layer에 적용되어있다. Section 3.4에서 설명한 Overlapping Max-pooling layer는 1,2,5번째 conv layer에 적용되었다. ReLU활성화 함수는 모든 conv, FC layer의 output에 적용되어있다.
Layer 별 구체적인 kernel의 개수는 논문의 Section 3.5 마지막 문단에 자세히 서술되어 있다.
4. Reducing Overfitting
이 섹션에서는 overfitting을 줄이는 주요한 두 방법을 소개한다.
4.1 Data Augmentation
image data의 과적합을 줄이는 쉽고 일반적인 방법은 label-preserving transformation을 사용해 데이터셋을 늘리는 것이다. 논문에서 제시하는 augmentation연산은 CPU에서 이뤄지고 계산량이 매우 적어 augmentated data를 별도의 저장장치에 저장할 필요가 없다.
첫번째 augmentation은 256x256 이미지에서 random하게 224x224크기로 crop하는것이다. 이것은 training set을 2048배 늘리는 것과 동일하며 augmentation의 결과 이미지들은 여전히 inter-dependent하다.
테스트시에는 하나의 이미지에 대해 4개의 모서리부분과 center 부분에서 224x224크기로 crop하고 여기에 horizontal flip을 적용해 총 10개의 이미지에 대해 예측을 하고, 이 예측결과를 softmax계층에서 averaging하여 모델의 출력으로 한다.
두번째는 training image의 RGB 채널 intensity를 바꾸는 것이다. 구체적으로, ImageNet training set전체에 걸쳐 RGB pixel값에 대해 PCA를 수행한다. 즉 각각의 RGB image pixel 에 다음과 같은 quantity를 추가한다:
이때 와 는 각각 RGB pixel의 3x3 공분산 행렬의 번째 고유벡터와 고윳값이고, ~ 인 random variable이다.
이 scheme는 자연 이미지의 중요한 속성을 대략적으로 포착하는데,즉, object identity는 조명의 강도와 색상의 변화에 불변한다는 것이다. 이 scheme를 통해 top-1 error가 1%줄었다.
4.2 Dropout
Ensemble과 같이, 서로 다른 모델의 prediction을 통합하는 것은 test error를 줄이는 매우 성공적인 방법이다. 그러나, AlexNet과 같이 train에만 수 일이 걸리는 거대 네트워크에는 비용이 많이 들어 적용하기 어렵다.
AlexNet이 나올 당시에 제시되었던 새로운 기법, 'dropout'을 이용하면 적은 비용으로도 ensemble의 효과를 노릴 수 있다.
Dropout에 의해 특정 hidden neuron이 0으로 setting되면, 해당 neuron은 forward pass, back propagation에 참여하지 않게 된다. 이는 input이 들어올 때마다 모델이 새로운 architecture를 갖게 되는 것을 의미한다.
논문에서는 dropout을 Figure 2에서 1,2번째 FC layer에 적용했다.
5. Details of learning
AlexNet의 train은 stochastic gradient descent (SGD)를 128 bacth size, 0.9 momentum, 0.0005 weight decay로 진행된다.
weight 의 update rule은 아래와 같은데,
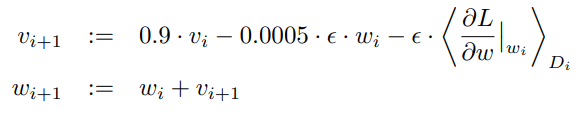
: iteration index
: momentum variable,
: learning rate
: 에서 계산되는 에 대한 목적 함수 미분값의 i번째 배치 의 평균
각 layer의 가중치 초기화는 $N(0, 0.01)을 따르는 random값으로 초기화했다.
2,4,5 conv layer와 FC layer 전체의 bias는 1로 초기화했다. 이렇게 1로 초기화함으로써, ReLU에 학습 초기에 positive input을 주게 되고 이것이 초기 학습을 가속한다.
모든 layer에는 동일한 learning rate(lr)을 사용했으며, heuristic하게 validation error가 향상되지 않을때 직접 10으로 나누어 주었다.
6. Results
Table 1에 ILSVRC-2010에서 AlexNet(CNN)의 결과가 나와있다.
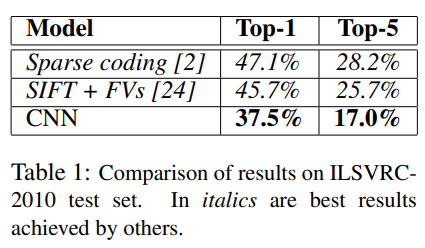
Table 2는 ILSVRC-2012에서의 결과다.
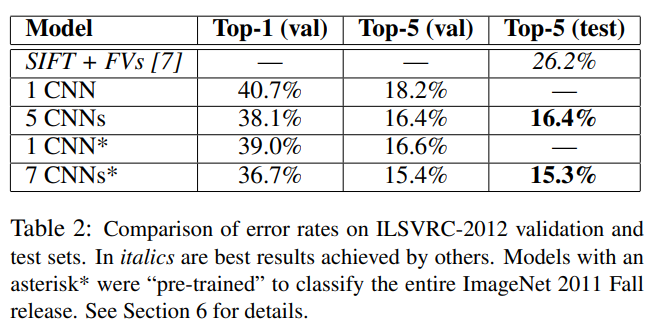
표에서 빈 칸은 test set label이 공식적으로 이용가능하지 않아서 측정할 수 없었다.
아래 내용부터는 val error와 test error가 0.1%이상 차이나지 않아 혼용하여 사용한다.
논문에 서술된 구조로 학습한 1 CNN은 18.2%의 top-5 error rate를 보였다.
5개의 유사한 CNN의 prediction을 평균한 5 CNNS는 16.4%의 성능을 보였다.
하나의 CNN을 학습했지만, 마지막 pooling layer 이후에 6개의 conv layer를 추가하고, ImageNet Fall 2011데이터셋으로 학습한 모델을 ILSVRC-2012에 'fine-tunning'한 1 CNN은 16.6%의 성능을 보였다.
ImageNet Fall 2011로 pre-train한 두 개의 CNN의 예측 과, 전술한 5 CNNs의 예측을 평균한 7 CNNs가 15.3%로 가장 성능이 좋았다.
6.1 Qualitive Evaluations

Figure 3은 network의 two data-connected layers(GPU2개로 학습하는 layer)의 conv kernel 94개이다.
GPU1의 kernel(top 48 kernel)들은 색상이 거의 없지만, GPU2의 kernel(bottom 48 kernel)들은 색상이 뚜렷하다.
이러한 specialization은 매 실행마다 일어나고 가중치초기화와는 독립적으로 일어난다.

Figure 4의 좌상단 mite를 보면, 객체가 이미지 중앙에 있지 않더라도 network가 식별하는것을 볼 수 있다.
leopard의 경우, top-5 label들이 모두 고양이의 다른 종인데, 이것들은 leopard의 'pla;usible label이다.
네트워크의 visual knowledge를 입증하는 또다른 방법은 마지막 4096차원 hidden layer에서 이미지에 의해 유도된 feature activation을 고려하는것이다. 만약 두 이미지가 적은 euclidean separation만으로 feature activation vector를 만들어낸다면, neural networ의 higher level에서는 그것들이 유사하다고 간주한다고 말할 수 있다.
7. Discussion
우리의 결과는 large DCNN이 순수 지도 학습을 사용하여 매우 어려운 데이터 세트에서 기록을 깨는 결과를 달성할 수 있음을 보여준다. 단일 conv layer가 제거되면, 우리의 network(AlexNet)의 성능이 감소한다는 것도 주목할 만한 결과이다.
실험을 단순화하기 위해, 논문에서는 unsupervised pre-training을 쓰지 않았다. 지금까지 우리의 결과는 네트워크를 더 크게 만들고 더 오래 훈련함에 따라 개선되었지만 human visual system의 추론 시간 경로와 일치하기 위해서는 여전히 magnitude의 order가 필요하다.
Video sequence등에 존재하는 '시간 구조(temporal structure)'는 매우 유용한 정보를 제공해주는데, 이는 정적 이미지(static image)에서는 누락되거나 매우 적은 양 밖에 존재하지 않는다.. 궁극적으로, 우리는 DCNN을 video sequence에 사용하고자 한다.

좋은 글 감사합니다.