Background
이름에서처럼, Xception은 Inception을 한번 더 개량한 것입니다.
그래서 Xception을 설명하기 앞서, Inception의 코어를 한번 되짚고 넘어가겠습니다.
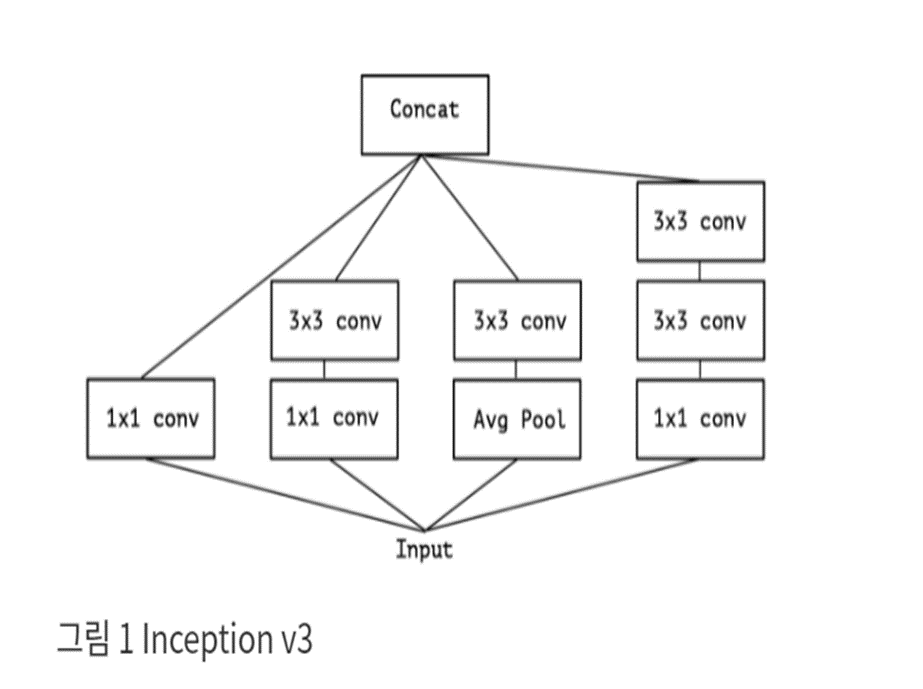
인셉션 모듈의 아이디어는 filter를 갖고 image와 같은 3D space를 모두 학습할 때, cross-channel correlation과 spatial correlation을 독립적으로 살펴볼 수 있게 함으로써 학습 프로세스를 좀더 쉽고 효율적으로 만든다는 것입니다.
즉, 일반적인 인셉션 모델은 먼저 1x1 convolution을 통해 cross-channel correlation을 살펴보고, 입력 데이터를 그림과 같이 원래의 공간보다 작은 3, 4개의 별도 공간에 mapping 한 다음, 이 작은 3D 공간의 모든 상관관계를 3x3, 5x5 convolution을 통해 mapping 합니다.
Single convolution kernel(filter) 하나가 하려는 것을 Spatial correlation(3x3, 5x5)을 분석해주면서 cross-channel correlation(1x1)으로 두 가지 역할을 잘 분산해주기 때문에 Xception 저자는 Inception이 좋은 모델이라고 생각합니다. 하지만 완벽하게 채널연산과 공간연산을 분리하지는 못했는데, Convolution 레이어에서 채널까지 조정하기 때문입니다.
Introduction
이제 저자는
cross-channel correlation과 spatial correlation의 mapping은 완전히 분리될 수 있다.
고 가설을 세웁니다.
이는 Inception Architecture의 기초가 되는 가설의 더 강력한 버전이기 때문에 "eXtreme Inception"을 의미하는 Xception이라고 부릅니다.
즉, Inception을 좀더 강하고 확실하게 해 보자는 것이 바로 Xception입니다.
Method
Xception의 핵심은 channel과 spatial의 correlation mapping이 완전하게 분리된 extreme version을 만드는 것입니다.
그 첫번째는 Inception 모듈의 단순화입니다. 먼저 하나의 크기의 Convolution만 사용하고 average pooling을 포함하지 않는 단순화된 Inception module을 만듭니다.
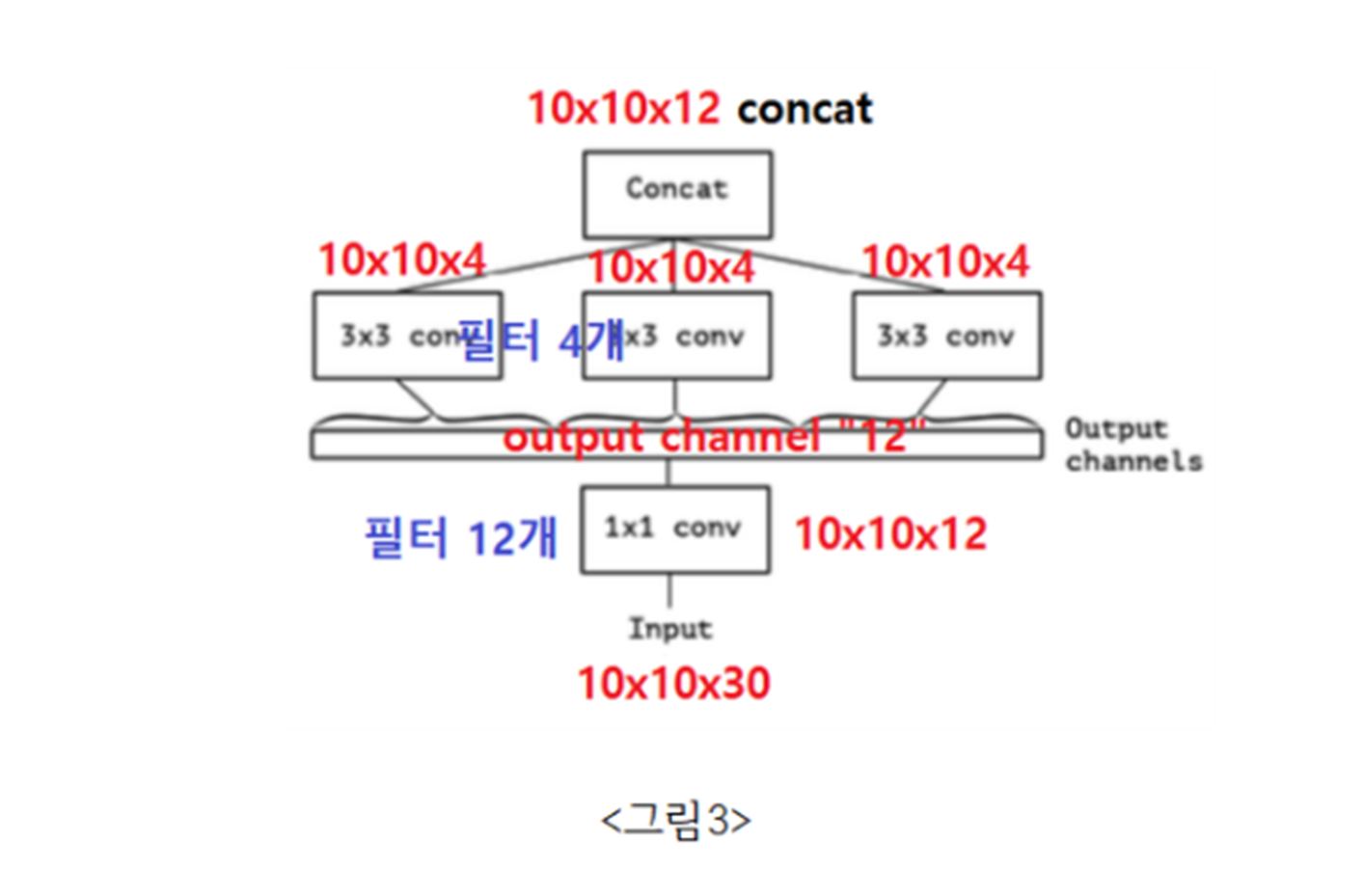
구체적인 예시와 함께 분석해보겠습니다. Input data를 30채널의 10x10 image라고 하겠습니다. 채널을 12개로 줄인다고 하면 12개의 filter를 가진 1x1 Conv layer를 통과해야 합니다.
이때 1x1 conv를 통과하고 나온 12채널을, 그림처럼 3x3 conv 레이어가 3개의 branch로 연결되어 있다면 각각 필터를 4개씩 쪼개서 갖게 하고, stride와 padding을 다르게 하여 가로세로(=공간)를 변경하게 한 후 concat시켜준다면 1x1 Conv레이어는 채널만을 변형하고 3x3 conv레이어는 공간만을 변형하게 됩니다.
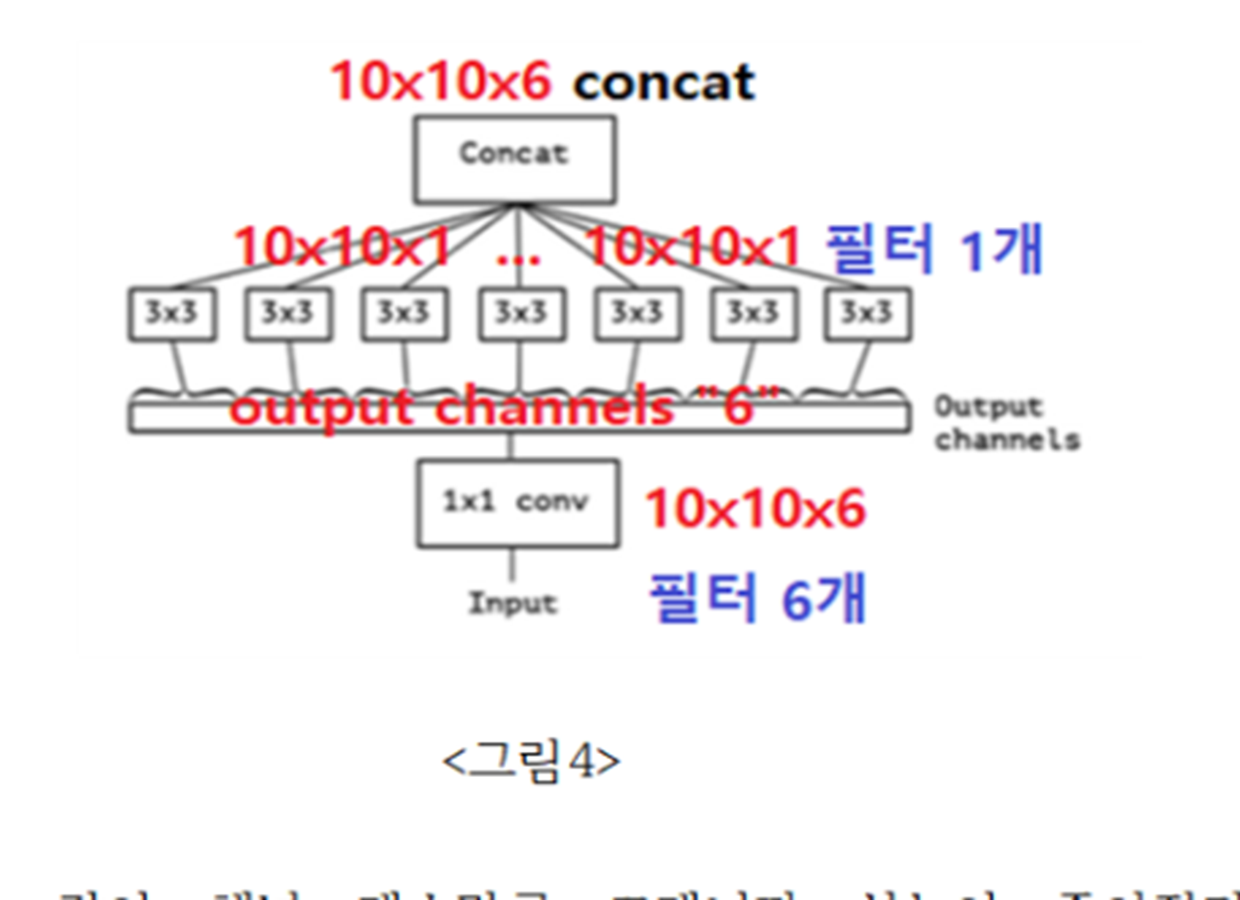
그러면 아예 채널개수만큼, 즉 12개의 채널을 1개의 채널 12개로 쪼개면 어떨까 라는 의문을 갖게 됩니다. output으로 출력될 채널만큼 1개의 채널씩 쪼개니까 성능이 좋아졌다고 하며, 이를 extreme version of Inception module이라고 부릅니다.
30채널의 10x10 image를 6채널로 바꿀 때는, 1x1 conv이후 3x3 conv layer branch 6개를 만들어 각각에서 하나의 output 채널 씩을 생성합니다.
여기에 Depthwise Separable Convolution을 참고하여 수정한 모델을 Xception이라고 부릅니다.
Depthwise Sparable Convolution (DSC)
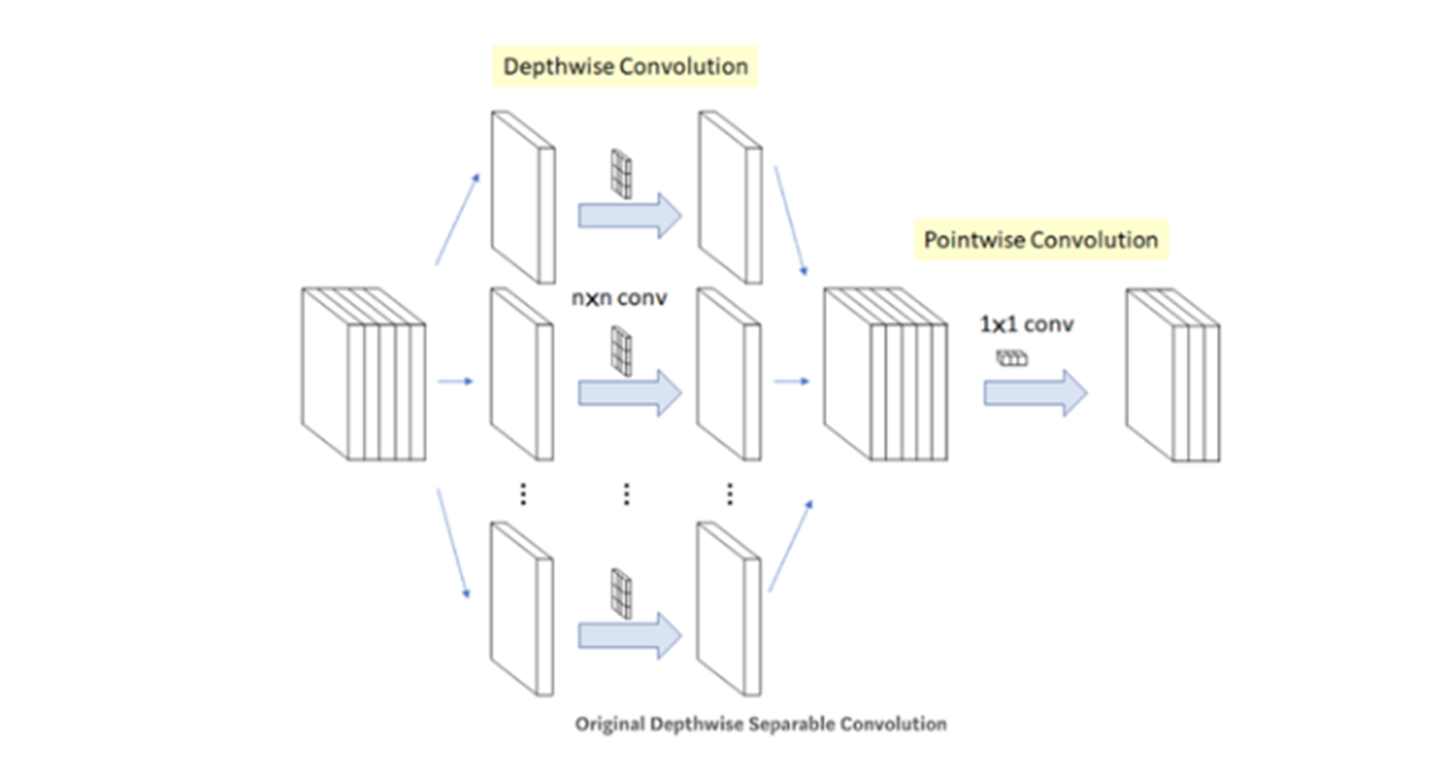
Depthwise Separable Convolution의 개념은 말 그대로
- Depthwise, 깊이 또는 채널 별로
- Separable, 나누어서
- Convolution, 컨볼루션 연산을 하는 것이라고 이해할 수 있습니다.
이 그림처럼, 5개의 채널을 가진 data가 인풋으로 들어올 때 5개의 채널로 분리하여 n x n convolution 필터를 통과시킵니다. 이때 stride와 padding을 조정해줌에 따라 spatial(공간)이 변하게 됩니다.
그 과정을 거친 채널들이 다시 채널에 대해 concat됩니다.
그 후 이루어지는 Pointwise Convolution과정은 그냥 1x1 conv layer를 통과하게 해 줌으로써 채널의 수를 줄이는 것입니다.
Xception VS DSC
Xception과 DSC는 두 가지 차이가 있습니다.
첫 번째로, 둘은 채널 및 공간 연산의 진행 순서가 다릅니다. Xception은 채널 수를 먼저 줄이고, 공간을 조정하지만 DSC는 공간을 먼저 조정하고 채널 수를 줄입니다.
두 번째로, 기존의 Inception에서는 공간연산을 한 이후 , 즉 3x3, 5x5 conv레이어를 지나간 후 비선형성을 주기위해 activation function 을 RELU로 주었지만, DSC에서는 activation function을 주지 않습니다. 이는 실험을 해보니 주지 않는게 더 성능이 좋은 것을 확인했다고 합니다. 또한 Residual Connection을 포함했더니 성능이 더욱 좋아졌다고 합니다.
Experiment
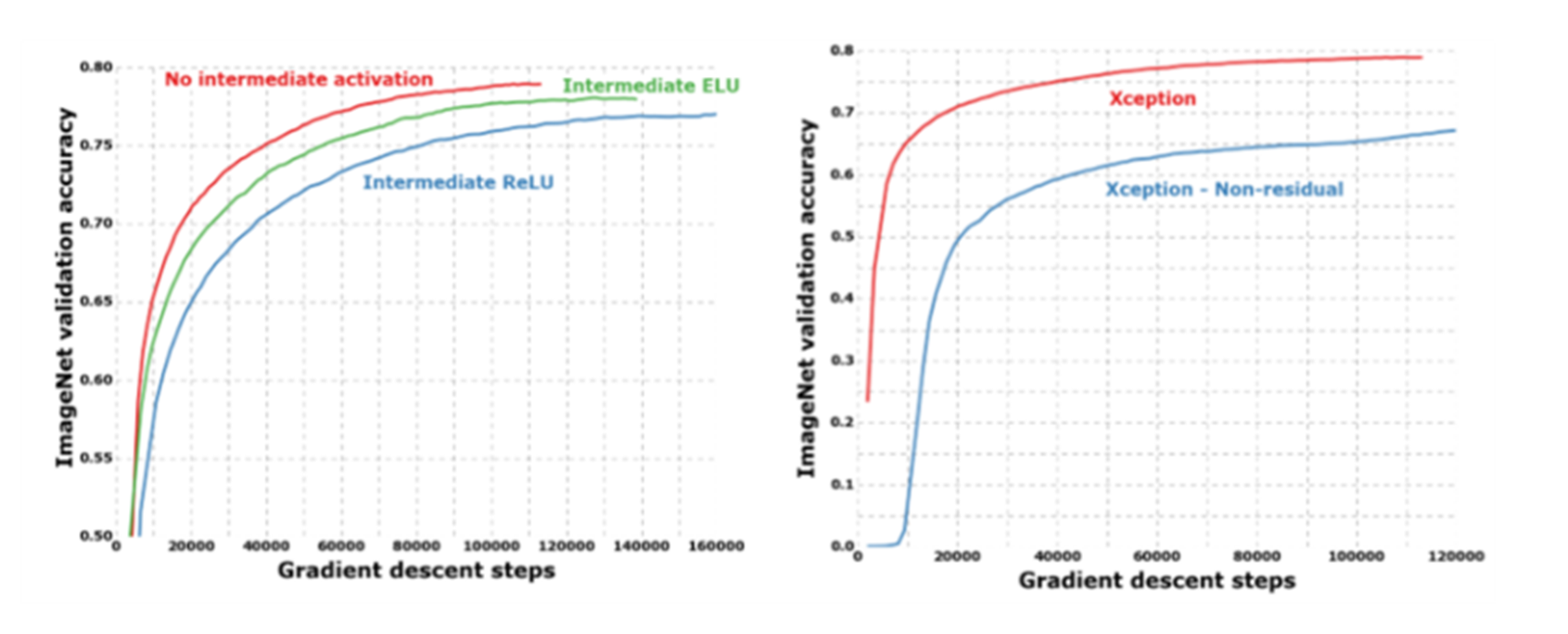
왼쪽 그래프는 activation function을 ReLU, ELU, 아무것도 주지 않았을 때의 결과인데, 붉은색으로 표시된, 활성 함수가 없을 때 제일 성능이 좋은 것을 확인할 수 있습니다.
오른쪽 그래프는 활성화 함수에 대해 비선형성을 주지 않았을 때 성능이 더 좋은 것을 확인할 수 있습니다.
Exception Structure
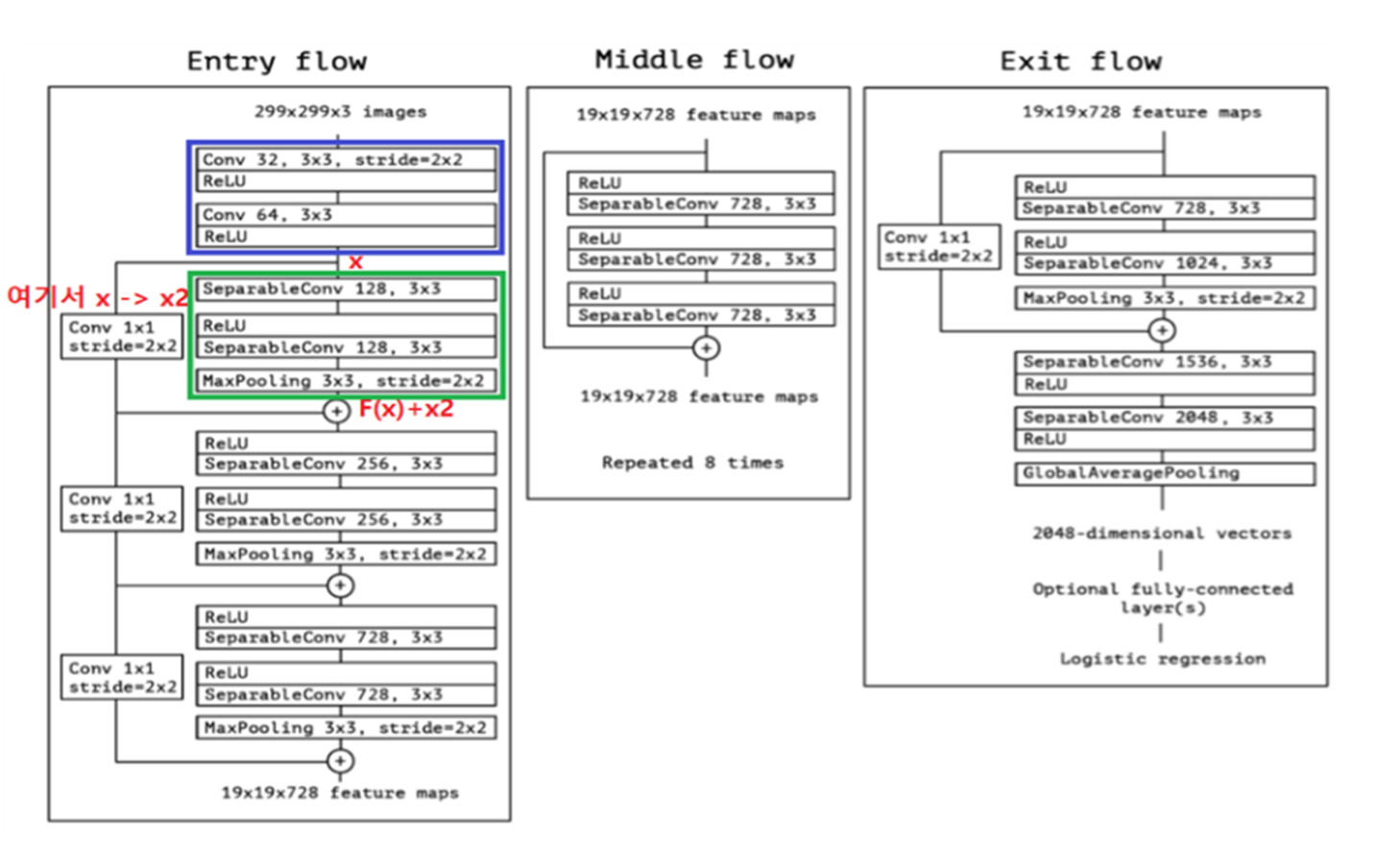
모델의 전체구조는 이와 같이 Entry flow, middle flow, exit flow로 구성되어 있습니다.
Entry flow에서 중간중간 +표시가 Residual block, skip connection입니다. Entry flow의 파란 박스를 지나고 난 결과가 x일 때, 이 x만 초록색 상자를 지나 F(x)가 됩니다. 하지만 x가 Conv레이어 하나를 더 통과해 x2가 되고, 그 x2r가 F(X)와 합쳐져 다음 상자로 넘어가게 됩니다.
SeparableConv 부분에서는 아까 보여드렸던, Depthwise separable convolution을 거치게 됩니다. 주어진 데이터의 채널을 측정해 그 개수만큼 데이터를 쪼개고 각각의 쪼개진 이미지에 대해 nxn conv 필터를 통과시키고 concat하여 1x1 conv필터를 통과시킵니다.
Middle flow에서는 사진의 과정을 8번 반복합니다.
Exit flow에서는 skip connection박스를 한번 더 진행하고, DSC모듈을 거치고 fully connected 레이어들을 거쳐 output을 만들어냅니다.
Conclusion
논문에서는 Xception을
Inception도 아니고 DSC도 아니지만, DSC의 개념을 따라가는, 그러나 DSC와 완전 똑같지는 않게 활성함수가 conv와 separableconv 뒤에 따라오는 모델





이라고 정리했습니다.
