이번 포스팅에서는 tree 구조의 앙상블 학습방법인 랜덤포레스트(Random Forest) 에 대해 써보겠습니다. 랜덤포레스트는 기계학습의 일종으로, 분류, 회귀 분석 등 의 문제에 활용되며 훈련 과정에서 구성한 다수의 결정 트리로부터 분류 또는 평균 예측등에 주로 사용됩니다.
📌 Decision Tree(의사결정나무)
먼저, 랜덤 포레스트를 이해하기 위해서는 랜덤 포레스트를 구성하는 decision tree에 대한 사전 지식이 요구됩니다. Decision tree는 의사 결정에 필요한 경로와 결과를 나무 구조로 시각화하여 분류와 예측을 수행하는 분석방법 입니다. Decision tree의 핵심은 노드(node) 로, 각 노드가 yes or no를 선택하는 하나의 분기점이라고 볼 수 있습니다. 이 개념은 분류(classfication) 혹은 예측을 나무 형태로 visualizing 된 추론 규칙에 따라 표현할 수 있기 때문에, 다른 방법들과 비교했을 때 그 과정을 쉽게 이해할 수 있습니다.
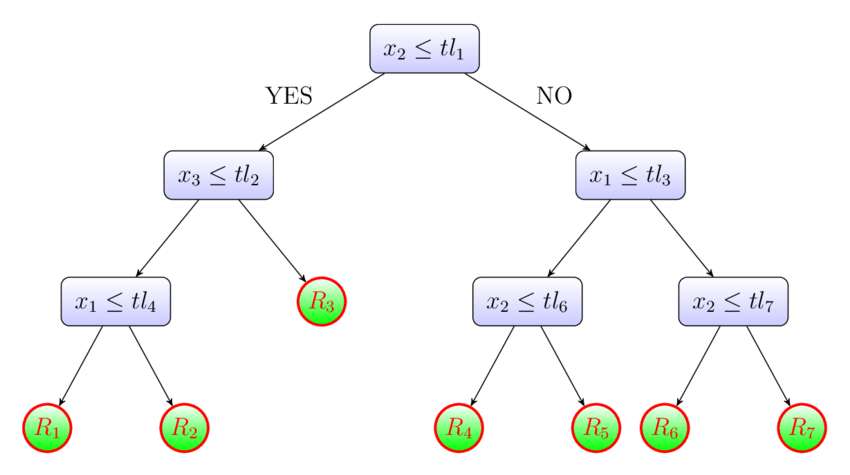
위의 그림에서 제일 처음 시작되는 질문인 뿌리 노드(root node) 가 있고 제일 끝에 형성되는 끝노드(terminal node) 가 있으며 그사이에 중간 노드(intermediate) 들이 있습니다. 뿌리 노드에서 그 아래 노드로 갈수록 데이터의 개수는 점점 줄어들게 되고 끝노드에 속하는 데이터의 개수를 합하면 뿌리 노드의 데이터 수와 일치하 게 된다. 즉, 끝노드 간의 교집합이 없으며 끝노드의 개수가 분리된 데이터의 수 만큼 나타나게 된다. 위의 그림 상황에 적용해보면, 끝마디가 7개라면 전체 데이터가 7개의 부분집합으로 나누어진 것으로 볼 수 있습니다.
타이타닉 데이터셋을 통한 Decision Tree 설명
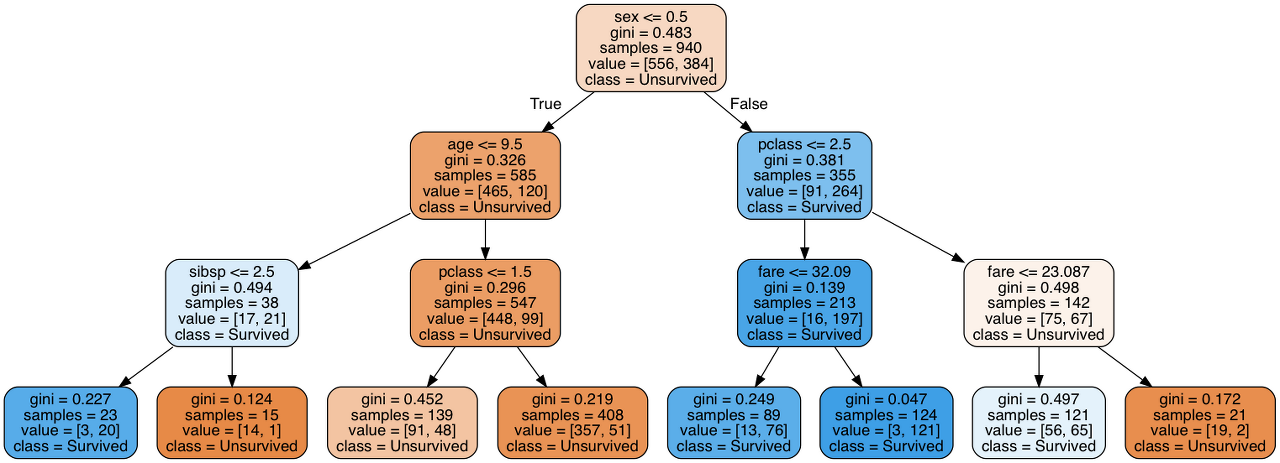
위의 그림은 Kaggle의 머신러닝 입문 데이터셋중 하나인 타이타닉 생존자를 찾는 것에 대한 decision tree입니다. 각 노드당 질문을 보면 조건들이 있고 뿌리 노드를 시작으로 질 문에 질문이 꼬리에 꼬리를 무는 형식이다. 뿌리 노드를 보면 ‘성별 <= 0.5’ 라고 되어 있는 데 이것은 남자인가? 여자인가? 라고 질문하는 것과 같고, 결과적으로 전체 승객에 대한 분류를 통해 생존 확률을 예측할 수 있습니다.
이처럼, 숫자형 결과 가 나오는 것을 회귀나무(regression tree) 라 하고, 범주형 결과가 나오는 것을 분류나무(classification tree) 라고 합니다. 의사 결정 나무를 만들기 위해서는 우선 어떤 질문을 어떤 순서로 할 것인지를 결정해야 한다. 질문을 고르는 가장 좋은 방법은 예측하려는 대상에 대한 가장 많 은 정보를 담고 있는 질문을 고르는 것이 좋습니다. 이렇듯 ‘정보를 얼마나 담고 있는가’의 정도를 엔트로피(entropy) 라고 표현이 됩니다. 이러한 엔트로피는 데이터의 불확실성 정도 를 나타내고 엔트로피가 클수록 데이터의 분포 정도가 커지기 때문에 엔트로피가 높은 값을 좋은 지표로 볼 수 있습니다.
Decision tree는 이해하기 쉽고 해석이 용이하다는 장점이 있으며 숫자형 및 범주형 데이터를 둘 다 처리할 수 있습니다. 하지만 decision tree는 overfitting될 위험이 높다라는 치명적인 단점이 존재합니다. Overfitting 이란 이전의 학습한 데이터에 대해서는 예측을 잘하지만, 새로운 데이터에 대해서는 예측 성능이 떨어지는 경우를 말하는데 이러한 과적합의 문제를 해결하기 위해 랜덤포레스트(Random Forest)가 등장한 계기가 됩니다.
📌 Random Forest(랜덤 포레스트)
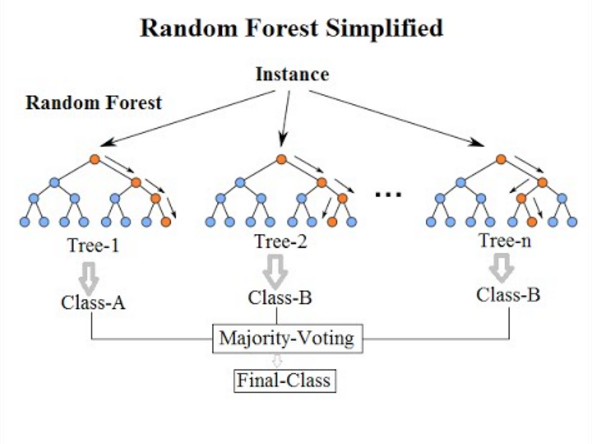
랜덤 포레스트는 위에서 설명한 의사 결정 나무를 이용해 만든 알고리즘으로, 분류와 회귀 분석 등에서 자주 활용되는 앙상블학습 기법 중 하나입니다. 랜덤 포레스트에서의 랜덤(random)은 임의성을 뜻하며, 포레스트 (Forest)는 문자 그대로 숲을 의미하며 숲은 decision tree의 트리(Tree)가 모여 형성된것으로 이해할 수 있습니다.
Decision tree의 단점으로 주어진 데이터에만 학습이 잘되고, 새로운 데이터에 대해서는 학습 성능이 떨어지는 overfitting의 위험도가 높다는게 있는데, 이는 주어진 데이터에 대해서만 최적화되어 있어 normalize가 어렵다는 것을 의미합니다. 따라서 이러한 문제점을 해결하기 위해 랜덤포레스트는 임의대로 tree를 여러개 만들어 overfitting의 문제를 해결할려고 합니다. 임의대로 tree를 만들면 기존 decision tree에서 주어진 학습 데이터에 따라서 의사 결정 트리가 달라져서 일반화하여 사용하기 어렵다는 단점을 극복할 수 있기 때문입니다.
그리고 이렇게 임의대로 데이터를 중복을 허용하여 선택하는 방식을 부트스트랩(bootstrap) 이라고 합니다. 또한 임의로 선택하여 여러 개의 의사 결정 트리를 만들어 다수의 예측 결과를 활용하는 방식을 앙상블(ensemble) 기법이라고 합니다. 부트스트랩을 이용해 무작위성을 가진 의사 결정 트리의 집합인 랜덤 포레스트를 구성하고, 다양한 의사 결정 트리에 앙상블 기법을 적용하여 다수의 예측 결과를 내놓고, 이를 최종 하나로 합치는 것을 배깅(bagging) 이라고 합니다. 배깅은 부트스트랩(bootstrap)과 어그리게이팅(aggregating)을 합친 단어인데, 여러 개의 데이터를 임의로 선택해서 결과들을 모으고 다시 합치는 것을 의미한다.
예를 들어, 고려해야할 요소(Feature)들이 20개 있다고 합시다. 20개의 요 소를 기반으로 하나의 결정 트리를 만들 때, 트리의 가짓수가 많아지게 될 것이고, 이는 overfitting의 문제를 야기하게 될 것입니다. 그러나 20개의 요소들 중에서 임의로 5개의 요소만 선택해서 하나의 결정트리를 만들고, 또 20개 중 임의로 5개의 요소를 선택해서 또 다른 결정 트리를 만들고(이때 선택할 5개의 요소들은 중복을 허락하여 뽑는다.) 이렇게 수차례 반복해서 여러개의 decision tree를 만들 수 있게 됩니다. 각 결정 트리에서 예측 값을 내놓게 되고, 이러한 여러 예측 값들 중에서 가장 많이 나온 값을 최종 값으로 정하게 됩니다 이렇듯 하나의 크고 가짓수가 많은 결정 트리를 만드는 것이 아닌 여러 개의 작은 결정 트리를 이용해 값을 분류하는 방식인 것입니다.
📌 마무리
실상활의 예를들어 쉽게 decision tree와 랜덤포레스트를 설명해보면, decision tree는 내가 회식메뉴를 고르는 과정이라고 설명할 수 있을꺼 같습니다. 반면, 랜덤포레스트의 경우는 나 뿐만 아니라 내팀 혹은 부서원들이 각자 회식 메뉴를 골라서 투표를 통해 과반수 이상의 투표를 받은 메뉴가 회식 메뉴로 정해지는 의사결정하는 방법이라 할 수 있을 꺼 같습니다.
