본 포스팅에서는 대략적인 CNN이라고 불리는 Convolutional neural network의 역사에 대해 진행해보려구합니다.
최근 뉴스에서 인공지능이 하나의 주요 이슈로 부상하면서 우리는 머신러닝, 딥러닝이라는 말을 많이 들어보았을겁니다. 그럼 왜 인공지능이 주요이슈로 부상했을까요? 제가 생각하는 이유로는 인간이 생성하는 sequential data가 비로소 기계가 잘 처리할수 있게 되었기 떄문일거라 생각합니다.
📌 sequential data
여기서 sequential data는 데이터 집합 내의 객체들이 어떤 순서를 가진 데이터로 그 순서가 변경될시, 데이터의 고유 특성을 잃어버릴 수 있습니다. 예를 AAPL의 2022년 1월 31일 부터 2월 3일까지의 데이터를 확인해 보겠습니다.
import yfinance
df = yfinance.download('AAPL',start = '2022-01-31',
end = '2022-02-03')['Open']
print(df)
Out[01]:
Date Open
2022-01-31 170.160004
2022-02-01 174.009995
2022-02-02 174.750000
2022-02-03 174.479996
Name: Open, dtype: float64AAPL의 시가를 살펴보면 170.160004, 174.009995, 174.750000, 174.479996 로 이루어진것을 확인해 볼 수 있습니다. 만일 여기서, 시가가 174.479996, 174.750000, 174.009995, 170.160004의 inverse된 형태로 바뀐다면, 이는 앞선데이터와 같은 데이터 일까요?
둘은 완전히 다른 데이터 입니다. 즉, sequential data는 데이터의 값 뿐만 아니라 데이터의 위치까지 중요한 요소로 포함됩니다. 주식뿐만아니라, 이미지도 마찬가지입니다. 만일 너구리의 사진이 주어졌을때, 우리가 생각하는 너구리의 사진이 아닌 눈,코,입,팔,다리가 각 픽셀별로 뒤바껴있는 사진은 우리에게 온전한 너구리사진으로 인식되지 않을겁니다.
이처럼 sequential data는 값이 온전히 존재하냐 뿐만 아니라, 해당 값이 어느위치, 몇번째에 존자하는가도 중요한 데이터를 의미합니다. 그리고 본 포스팅에서 이루어질 CNN(Convolutional neural network)은 여러 sequentail data 중 이미지를 잘 처리하는 뉴럴넷 모델이라고 생각합니다.
📌 CNN의 배경
만일 아래과 같은 손글씨 데이터셋이 주어졌다고 합시다.

해당 손글씨 데이터를 구분하기위해, 뉴럴넷을 사용하지 않고 순수 코딩으로 프로그래밍을 한다고 가정하면, 우리는 IF문을 통해 pixel-pixel의 형태를 일일히 비교해가면서 주어진그림이 어떤숫자인지 classify 할 것입니다.
만약 각 숫자의 대한 변형이 5가지라면, 어찌저찌 IF문을 통해 classify 할 수있겠지만 숫자의 변형이 많아질 수록 코드를 짜는 시간은 기하급수적으로 늘어날 것 입니다.
하지만 이를 pixel-pixel 이 아닌 local feature로 비교하는건 어떨까요? 사람은 사진을 비교할때 각 pixel 별로 비교하지 않고 각 그림의 local feature를 찾아내고 local feature를 추출하고 각 local feature와 다른 local feature를 비교해서 두 사진이 같은지 다른지를 판단합니다.
그리고 이런식으로 프로그래밍을 한게 convolution이며 이를 뉴럴넷 형태로 발전 시킨것이 CNN(Convolution neural network) 라고 생각이 듭니다. CNN이 sequential data 중 이미지에 좋은 성능을 보이는 이유도 이미지를 비교할때 local feature를 찾아내고 그 local feature 끼리 비교하자라는 아이디어에서 시작된게 바로 CNN 이기 때문입니다.
보다 정확하게 CNN의 기원을 살펴 보자면 David Hubel과 Torseten Wiesel은 1958년과 59년에 진행된 시각 피질의 구조에 대한 결정적 통찰을 제공한 고양이 실험에서의 고수준의 뉴런이 저수준의 뉴런의 출력에 기반한다는 아이디어로 출발하게 되었다. 그리고 이러한 아이디어는 Backpropagation applied to handwritten zip code recognition이 나오면서 CNN의 처음 소개되는 계기가 됬으며, 1998년 Yann Lecn et al.의Gradient-based learning applied to document recognition의 LeNet이 나오면서 CNN의 본격적인 구조가 탄생되었습니다.
📌 CNN의 발전과정
LeNet - Gradient-based learning applied to document recognition(1998)
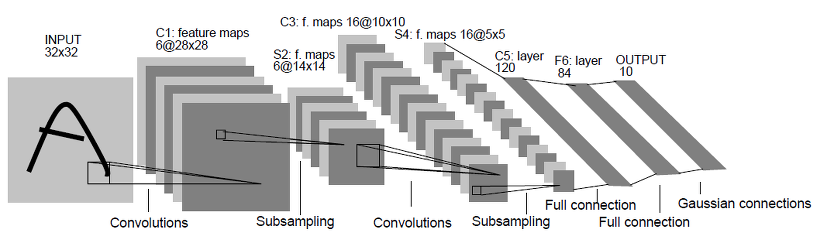
LeNet은 CNN의 기반을 구성했으며 input layer, convolution layer, subsampling layer, fully connected layer, output layer로 구성되는 것을 확인 할 수 있습니다. LeNet은 LeNet1을 시작으로 input의 크기 및 convolution kernal의 크기 LeNet5까지 발표되었으며, CNN 이전의 fully connected neural network의 topology 나 noise에 대한 이슈에 잘 대응하는것으로 확인되었습니다.
AlexNet - ImageNet Classification with Deep Convolutional Neural Networks(2012)
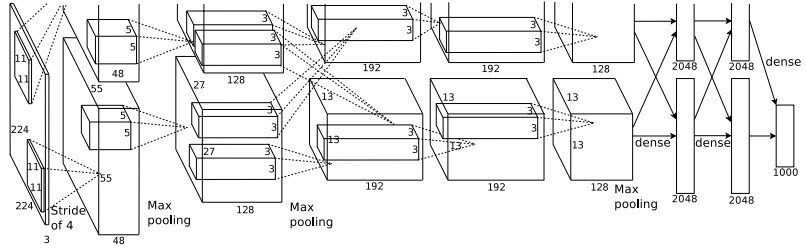
AlexNet은 CNN의 구조를 담고있는 뉴럴넷으로 LeNet-5와 유사하지만 병렬적인 구조로 설계되었습니다. 실제 위의 그림에서 확인 할 수 있듯이 AlexNet은 병렬적 구조를 제외하고는 LeNet-5와 유사한 형태로 나타납니다. AlexNet은 총 8개의 layer로 구성되었으며 8개의 layer는 5개의 convolution layer와 3개의 fully connected layer로 구성되었습니다.
그리고 마지막 fully connected layer의 경우 category 분류를 위해 softmax 함수로 설계된것을 확인 할 수 있습니다. AlexNet의 경우 성능 향상을 위해 2개의 GPU 사용을위한 병렬구조, activation function 으로 Relu를 사용하였으며, polling의 경우 현재도 많이 사용되는 max pooling을 사용하였습니다. 또한 ML 혹은 DL 모델 개발시 발생되는 오버피팅 문제를 해결하기위해 dropout 기법을 사용하였습니다.
ZFNet - Adaptive Deconvolutional Network for Mid and High-level Feature Learning
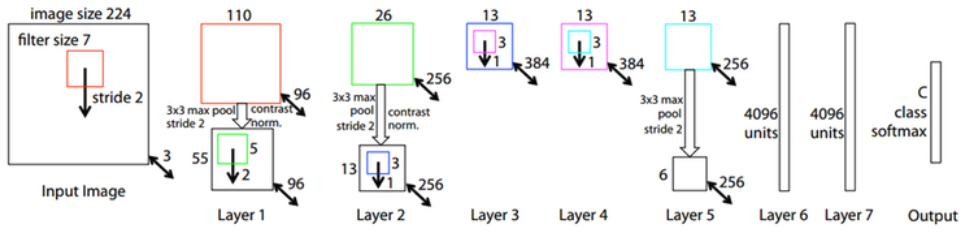
Layer가 많이 생길수록(=deep neural network) 하이퍼파라미터 튜닝은 중요한 문제입니다. ZFNet은 새로운 CNN의 모델구조를 제시했다기 보단 visualizing 기법을 통해 이러한 문제를 해결하려고 시도하였습니다.
VGGNet - Very Deep Convolutional Networks for Large-Scale Image Recognition (2014)
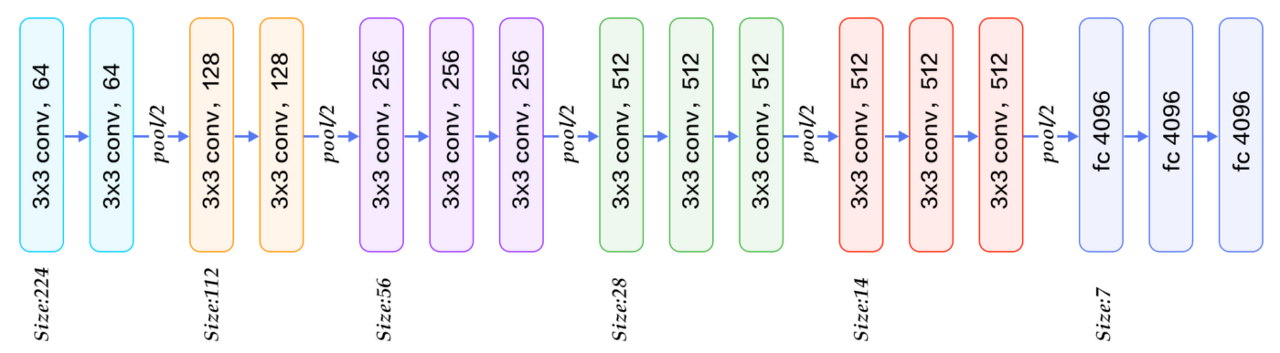
CNN기반인 AlexNet이 좋은 성과를 내면서 더욱 발전된 후속 모델들이 나왔습니다. VGGNet는 모델의 제목에서 유추할수 있듯이 모델의 lyaer를 많이 쌓을 수록 CNN 모델의 성능에 어떠한 영향을 미치는지에 대해 집중하여 ILSVRC에서 준우승을 차지한 모델입니다.
VGGNet은 모델의 깊이가 어떠한 영향을 끼치는지 알기위해 3x3크기의 layer를 겹쳐서 사용하였습니다. ILSVRC의 데이터의 경우 16개의 layer이후 부터는 성능에 별다른 소득을 주지 못한것을 확인 하였습니다. 또한, VGGNet은 3x3 convolution layer 2개와 5x5 convolution layer 1개의 성능 차이를 비교하였는데, 3x3 convolution layer 2개를 사용하는 편이 모델을 deep하게 만들고 파라미터 수 를 줄일 뿐만아니라 non-linearity activation function을 통해 feature추출 특성이 좋아짐을 확인 하였습니다.
GoogLeNet - (2014)
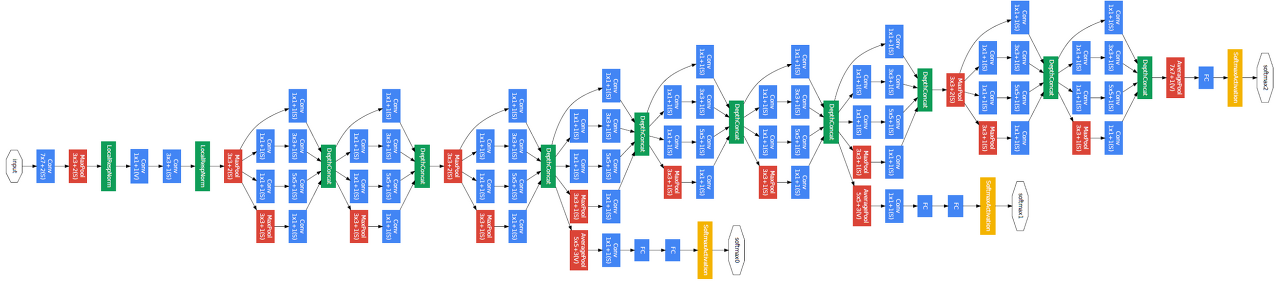
앞서 말한 VGGNet이 ILSVTC에서 준우승을 차지했다면, GoogLeNet의 경우 동일 대회에서 우승을 차지한 모델로써 VGGNet과 유사하게 22개의 layer를 쌓음으로써 CNN을 좀더 deep하게 만들었습니다.
GoogLeNet은 기계의 자원을 효율적으로 이용하면서 학습 능력을 극대화 할 수 있는 deep 한 CNN모델을 설계하는 것에 초점을 맞추었습니다. 이에GoogLeNet 에는 총 9 개의 Inception이라는 기본 모듈을 중첩시키는 구조를 사용하였습니다. 또한 local field에서 다양한 feature들을 추출하기 위해서 여러개의 convolution을 병렬적으로 확용하였습니다.
처음에는 1x1 convolution, 3x3 convolution, 3x3 max pooling로 구성하려고 했으나 3x3과 5x5의 convolution 연산량은 부담이 되어 망의 깊이와 넖이가 커질수록 GoogLeNet에 악영향을 끼칠수도 있었습니다. 이에 3x3과 5x5 convolution layer 앞에 1x1 convolution을 cascade 구조로 두면서 feature map의 차원을 줄이면서, 다양한 scale을 확보하면서 연산량의 균형을 맞출수 있게 되었습니다.
GoogLeNet은 이런식의 inception을 구축하고 NIN(Network In Network; CNN의 convolution layer의 local field에서 feature을 찾는 성능은 우수하지만 filter가 linear하기 때문에 non-linear한 feature를 찾는데 어려움이 존재하여, feature map의 수를 늘리는 형식으로 non-liner한 상황을 지원하는 filter를 설계하여 한계를 극복하며[= MLP convolutional layer], global average pooling을 사용) 구조로 사용된 모델입니다. 하지만 이러한 성능 및 구조에도 불구하고 ResNet의 단순성, 확장성 및 성능으로 후퇴하게 되었습니다.
ResNet (2015)
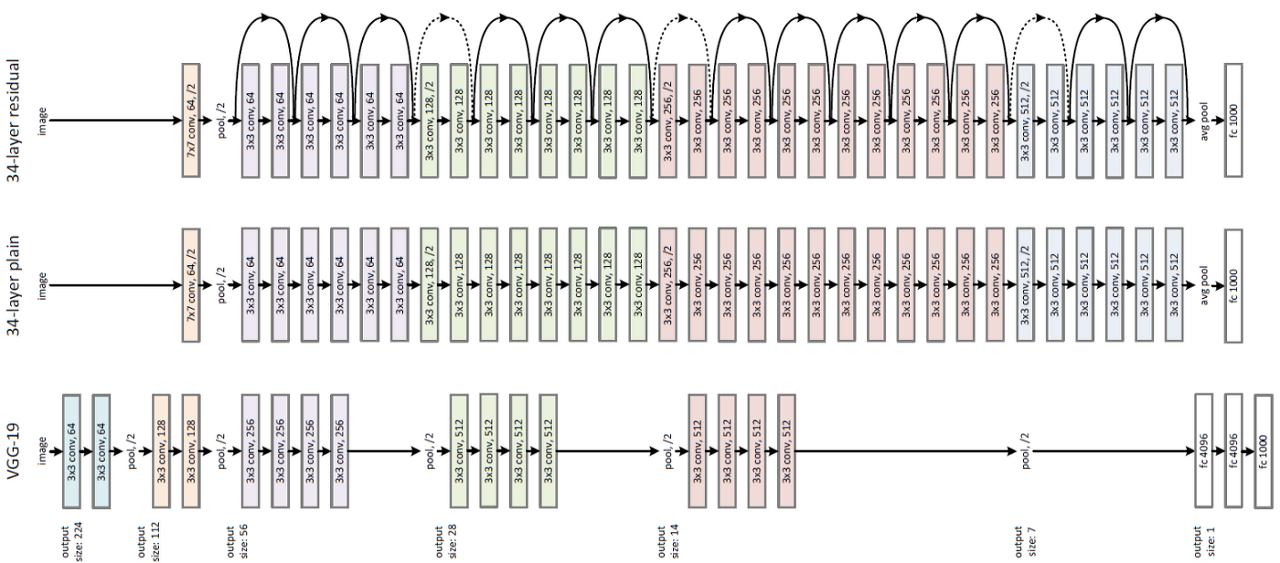
위에서 말한 내용처럼 2014년에는 CNN의 layer가 깊게 설계된 모델이 주목을 받았습니다. ResNet은 residual learning, shortcut, identity mapping 과 같이 이전의 CNN 구조에서 찾기 힘든 용어들이 사용되며, 152의 layer의 구조를 갖고있는 모델입니다.
VGGNet에서는 16개의 layer이후 추가적으로 layer를 생성해도 성능 향상을 이루기 힘듬을 보여주었으며, 추가적으로 ResNet의 실험팀에서 VGGNet의 20 layer와 56 layer에 대해 CIFAR-10의 학습데이터로 실험한 결과, 56 layer의 구조를 가진 CNN 모델이 20 layer의 구조를 가진 모델보다 성능이 낮아진것을 확인하였습니다. 이는 단순히 layer를 깊게 설계하는 것만으로 좋은 결과를 기대하기 어렵다고 해석할 수 있습니다. 이에 ResNet 실험팀은 layer를 deep하게 설계하면서 학습성능을 높을수 있는 방법을 고민한 결과 residual learning을 발표하게되었습니다.
ResNet의 경우 residual learning과 shortcut 연결을 통해 layer의 optimization을 잘 수행할수 있는 기초를 마련한 모델이라고 할 수 있습니다. 또한 ResNet에 나온 shortcut의 경우 현재의 CNN 구조에서 역시 흔하게 찾아볼수 있게 되었습니다. 또한 성능적 측면에서인간의 인지 능력을 웃도는 수준을 보여주며 후속 연구에서 새로운 CNN 구조를 연구 혹은 비교할때도 ResNet을 우선적으로 검토하게 되었습니다.
