1. 자료구조
여러 개의 데이터가 묶여있는 자료형을 컨테이너 자료형이라고 하고, 이러한 컨테이너 자료형의 데이터 구조를 자료구조라고 한다. (묶어서 관리 함)
자료구조 종류

리스트는 안에 있는 데이터를 바꿀 수 있다.(박찬호를 박지성으로 바꿀 수 있음) but 튜플은 바꿀 수 없다. 셋트는 중복된 데이터를 쓰지 않는다.
2. 리스트
여러 개의 값을 담을 수 있는 순차적인 자료 구조
특징
- 여러 개의 요소(element)를 가지고 있다.
- 각 요소는 순서가 있으며, 인덱스(Index)를 가진다.
- 리스트의 첫 번째 요소의 인덱스는 0, 두 번째 요소의 인덱스는 1, 세 번째 요소의 인덱스는 2, ... 이러한 순서로 부여된다.
- 숫자, 문자(열), 논리형 등 모든 기본 데이터를 같이 저장할 수 있다.
- 리스트에 또 다른 컨테이너 자료형 데이터를 저장할 수도 있다.
students = ['박찬호', '홍길동', '이용규','박승철','김지은']
print(students[0])
print(students[1])
print(students[2])
print(students[3])
print(students[4])
#출력값
박찬호
홍길동
이용규
박승철
김지은리스트 선언
리스트는 대괄호([ ])를 이용하여 선언 할 수 있다. 각 요소는 쉼표(,)로 구분한다.
3. 리스트 길이
리스트에 저장된 아이템 개수를 뜻함
len()를 이용한 조회
myGames = ['롤','피파','롤체','mlb9이닝스','로스트아크']
for i in range(len(myGames)):
print(f'myGames:{myGames[i]}')
#출력값
myGames:롤
myGames:피파
myGames:롤체
myGames:mlb9이닝스
myGames:로스트아크len()함수를 이용해 리스트안의 아이템 개수를 세어 for문을 돌려 아이템을 조회하는 방법이다. 이 경우 리스트 안의 인덱스번호대로 0('롤')부터 5('로스트아크')까지 조회가 되는 것을 알 수 있다.
4. 리스트(LIST) 아이템 조회 방법(for문이용)
myGames = ['롤','피파','롤체','mlb9이닝스','로스트아크']
for i in range(len(myGames)):
print(myGames[i])
for game in myGames: #더 개선된 방법
print(game)
#출력값
롤
피파
롤체
mlb9이닝스
로스트아크
롤
피파
롤체
mlb9이닝스
로스트아크- 리스트 안에 리스트가 있을 때
studentsCnts = [[1, 19], [2, 20], [3, 22], [4, 18], [5,21]]
for i in range(len(studentsCnts)): #불편한 방법
print('{}학급 학생수: {}'.format(studentsCnts[i][0], studentsCnts[i][1]))
for classNo, cnt in studentsCnts: #쉬운 방법
print('{}학급 학생수: {}'.format(classNo, cnt))
#출력값
1학급 학생수: 19
2학급 학생수: 20
3학급 학생수: 22
4학급 학생수: 18
5학급 학생수: 21
1학급 학생수: 19
2학급 학생수: 20
3학급 학생수: 22
4학급 학생수: 18
5학급 학생수: 21- for 문과 if문을 이용해 과락 과목 출력
minScore = 60
scores = [['국어', 58],['영어', 77],['수학', 89],['과학', 99],['국사', 50]]
for item in scores: #첫번째 방법
if item[1] < minScore:
print('과락과목 : {}, 점수: {}'.format(item[0], item[1]))
for subject, score in scores: #두번째 방법
if score < minScore:
print('과락과목 : {}, 점수: {}'.format(subject, score))
for subject, score in scores: #세번째 방법
if score >= minScore: continue
print('과락과목 : {}, 점수: {}'.format(subject, score))
#출력값
과락과목 : 국어, 점수: 58
과락과목 : 국사, 점수: 505. 리스트(LIST) 아이템 조회 방법(while문이용)
- 인덱스, flag, 무한반복(while True)을 활용한 while 문을 이용하여 리스트 아이템을 조회한다.
cars = ['그랜저','소나타','말리부','카니발','쏘렌토']
n = 0
while n < len(cars):
print(cars[n])
n+=1
n = 0
flag = True
while flag:
print(cars[n])
n+=1
if n == len(cars):
flag = False
n = 0
while True:
print(cars[n])
n+=1
if n == len(cars):
break
#실행결과
그랜저
소나타
말리부
카니발
쏘렌토- 아래 표와 리스트를 이용해서 학급별 학생 수와 전체 학생 수 그리고 평균 학생수를 출력해보자
studentCnts = [[1,18],[2,19],[3,23],[4,21],[5,20],[6,22],[7,17]]
sum = 0
avg = 0
n = 0
while n < len(studentCnts):
classNo = studentCnts[n][0]
studentNum = studentCnts[n][1]
print('{}학급 학생수 : {}명'.format(classNo, studentNum))
sum += studentNum
avg = sum / len(studentCnts)
n += 1 #무한 반복 빠지기 방지
print('전체 학생수: {}명'.format(sum))
print('평균 학생수: {}명'.format(avg))
#출력값
1학급 학생수 : 18명
2학급 학생수 : 19명
3학급 학생수 : 23명
4학급 학생수 : 21명
5학급 학생수 : 20명
6학급 학생수 : 22명
7학급 학생수 : 17명
전체 학생수: 140명
평균 학생수: 20.0명if minCnt == 0은 초기 설정을 위한 부분이고, minCnt > studentCnts[n][1]는 현재까지의 최소값(minCnt)보다 작은 학생 수를 가진 학급을 찾기 위한 부분이다. 최소값을 찾을 때는 초기화가 필요한 이유는 초기에 minCnt를 어떤 값으로든 설정해야 하며, 그 값보다 작은 값을 찾아야 하기 때문이다. 최대값은 초기화 없이도 어떤 값보다 큰 값을 찾아가면서 업데이트할 수 있다.
6. enumerate()함수
enumerate()함수를 이용하면 인덱스와 아이템을 한번에 조회할 수 있다.
students = ['학생1','학생2','학생3','학생4','학생5']
for idx, student in enumerate(students):
print('{} :{}'.format(idx,student))
#실행결과
0 :학생1
1 :학생2
2 :학생3
3 :학생4
4 :학생57. 리스트에 아이템 추가 방법
append()함수를 이용하여 마지막 인덱스에 아이템을 추가할 수 있다.
students = ['학생1','학생2','학생3','학생4','학생5']
students.append('학생6')
print(students)
print(len(students))
print(len(students)-1)
students = ['학생1','학생2','학생3','학생4','학생5']
#실행결과
['학생1', '학생2', '학생3', '학생4', '학생5', '학생6']
6 #리스트의 아이템 개수 출력
5 #리스트의 인덱스 길이 출력 - 다른 방법으로는 insert()함수를 이용하는 방법으로, 내가 원하는 위치(index)에 아이템을 추가하는 방법이 있다.
students = ['학생1','학생2','학생3','학생4','학생5']
students.insert(2,'학생6')
print(students)
print(len(students))
print(len(students)-1)
#실행결과
['학생1', '학생2', '학생6', '학생3', '학생4', '학생5']
6
58. 리스트에 아이템 삭제 방법
pop()함수를 이용하여 마지막 인덱스의 아이템을 삭제할 수 있다.
- pop() 함수안에 내용을 쓰지 않으면 기본적으로 맨 마지막 인덱스가 삭제된다
- pop() 함수안에 인덱스번호를 쓰면 해당 인덱스자리의 아이템이 삭제된다
- 삭제한 아이템을 변수에 넣어 별도로 출력이 가능하다(삭제된 아이템이 무엇인지 알고 싶을때 이용할 수 있다)
students = ['학생1','학생2','학생3','학생4','학생5']
students.pop()
print(students)
rValue = students.pop(0)
print(rValue)
#실행결과
['학생1', '학생2', '학생3', '학생4']
학생1- 또다른 방법으로 remove()함수를 이용하여 특정 아이템을 삭제할 수 있다. pop()함수와의 차이점은 pop()함수는 괄호안에 인덱스번호를 썼다면 remove()함수는 삭제하려는 아이템 값을 적는 것이다.
students = ['학생1','학생2','학생3','학생4','학생5']
students.remove('학생1')
print(students)
#실행결과
['학생2', '학생3', '학생4', '학생5']- remove()함수의 또다른 특징으로는 삭제하려는 값이 두개 이상일 경우 한개만 삭제가 된다. 만약 2개이상의 값을 삭제하려면 while문을 이용해야한다.
students = ['학생1','학생1','학생2','학생3','학생4','학생5']
students.remove('학생1')
print(students)
#실행결과
['학생1', '학생2', '학생3', '학생4', '학생5']
- 학생1이 두개 있었지만 한개만 삭제가 되었다.
students = ['학생1','학생1','학생2','학생3','학생4','학생5']
while '학생1' in students:
students.remove('학생1')
print(students)
#실행결과
['학생2', '학생3', '학생4', '학생5']9. 리스트 연결 방법
- 첫번째 방법: extend()함수를 이용하는 방법
aList = [1,2,3,4,5]
bList = [6,7,8,9,10]
aList.extend(bList)
print(aList)
#실행결과
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]- 두번째 방법: 덧셈기호를 이용하는 방법
aList = [1,2,3,4,5]
bList = [6,7,8,9,10]
cList = aList+bList
print(aList)
print(bList)
print(cList)
#실행결과
[1, 2, 3, 4, 5]
[6, 7, 8, 9, 10]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]- extend()는 단순히 리스트에 또 다른리스트를 연결하여 확장하는 개념이라면 덧셈기호를 써서 리스트를 연결하는 방법은 새로운 리스트가 만들어지는 개념이다.
10. 리스트 아이템 정렬
sort()함수를 이용하여 리스트안의 아이템을 정렬할 수 있다.
- 최저,최고 점수를 제외하고 평균, 합계를 구하자
playerScore = [9.5,8.9,9.8,9.2,8.8,9.0]
print('playerScore:{}'.format(playerScore))
playerScore.sort()
print('playerScore:{}'.format(playerScore))
playerScore.pop(0)
print('playerScore:{}'.format(playerScore))
playerScore.pop(len(playerScore)-1)
print('playerScore:{}'.format(playerScore))
avg=0
sum=0
for score in playerScore:
sum += score
avg = sum / len(playerScore)
print('총점:%.2f'%sum)
print('평균:%.2f'%avg)
#실행결과
playerScore:[9.5, 8.9, 9.8, 9.2, 8.8, 9.0]
playerScore:[8.8, 8.9, 9.0, 9.2, 9.5, 9.8]
playerScore:[8.9, 9.0, 9.2, 9.5, 9.8]
playerScore:[8.9, 9.0, 9.2, 9.5]
총점:36.60
평균:9.1511. 리스트 아이템 순서 뒤집기
reverse()함수를 이용하여 리스트 안의 아이템 순서를 뒤집을 수 있다.
- 다음 secret의 암호를 해독해보자(중세시대에서 많이 사용하는 해독방법)
secret = '27156231'
secretList = []
for char in secret:
secretList.append(int(char))
print('secretList:{}'.format(secretList))
secretList.reverse()
print('secretList:{}'.format(secretList))
val = secretList[0]*secretList[1]
secretList.insert(2,val)
val = secretList[3]*secretList[4]
secretList.insert(5,val)
val = secretList[6]*secretList[7]
secretList.insert(8,val)
val = secretList[9]*secretList[10]
secretList.insert(11,val)
print('secretList:{}'.format(secretList))
#실행결과
secretList:[2, 7, 1, 5, 6, 2, 3, 1]
secretList:[1, 3, 2, 6, 5, 1, 7, 2]
secretList:[1, 3, 3, 2, 6, 12, 5, 1, 5, 7, 2, 14]문자열을 숫자 리스트로 변환하고, 그 리스트를 역순으로 만든 다음, 일부 위치에 새로운 값을 삽입하는 간단한 예제이다.
12. 리스트 슬라이싱
슬라이싱: 문자열에서 일부분을 추출하는 것을 의미한다.
[n:m]을 이용하면 리스트에서 원하는 아이템을 뽑아 낼 수 있다.
ex) [1:3]은 1번째 요소(포함)부터 3번째 요소 전까지의 요소를 추출한다.
첫 번째 인덱스를 생략하면, 0부터 시작한다. 만약, 두 번째 인덱스를 생략하면, 리스트의 마지막 요소까지 추출한다.
예시
my_list = [1, 2, 3, 4, 5] print(my_list[1:3]) [2, 3] print(my_list[:3]) [1, 2, 3] print(my_list[2:]) [3, 4, 5] print(my_list[0:4:2]) [1, 3]
#리스트 슬라이싱
sliceList = ['가','나','다','라','마','바','사']
print(sliceList[1:4])
print(sliceList[:4])
print(sliceList[2:])
#문자열 슬라이싱
sliceList2 = '가나다라마바사'
print(sliceList2[1:4])
print(sliceList2[:4])
print(sliceList2[2:])
#slice()함수를 이용한 슬라이싱
sliceList3 = ['가','나','다','라','마','바','사']
print(sliceList3[slice(1,4)])
print(sliceList3[slice(4)])
print(sliceList3[slice(2,len(sliceList3))])13. 리스트의 나머지 기능들
리스트를 곱셈 연산하면 아이템이 반복된다.
korList = ['가','나','다','라']
mulKorList = korList * 2
print(mulKorList)
#실행결과
['가', '나', '다', '라', '가', '나', '다', '라']- index(item)함수를 이용하면 item의 인덱스를 알아낼 수 있다. 단 중복된 item이 있을 경우 제일 앞쪽의 item의 인덱스를 뽑아낸다.
korList = ['가','나','다','라','가','나','다','라']
indexKor = korList.index('가')
print(indexKor)
#실행결과
0 위의 경우처럼 맨 앞쪽의 인덱스 번호가 추출되었다. 중간의 '가'의 인덱스를 추출하고 싶다면 index()함수에서 범위를 지정하면 된다.
korList = ['가','나','다','라','가','나','다','라']
indexKor = korList.index('가',2,6)
print(indexKor)
#실행결과
414. 리스트의 나머지 기능들 2
count()함수를 이용하면 리스트안의 특정 아이템 갯수를 셀 수 있다.
- 오늘 헌혈한 혈액형의 총 갯수를 뽑아내보자
import random
types = ['A','B','AB','O']
todayData = []
for a in range(100):
type = types[random.randrange(len(types))]
todayData.append(type)
print(todayData)
print(len(todayData))
for type in types:
print('{}형\t : {}개'.format(type,todayData.count(type)))
#실행결과
['O', 'A', 'B', 'AB', 'A', 'A', 'B', 'A', 'AB', 'AB', 'B', 'AB', 'O', 'AB', 'AB', 'B', 'AB', 'B', 'B', 'B', 'B', 'A', 'B', 'A', 'B', 'B', 'O', 'A', 'AB', 'AB', 'O', 'A', 'AB', 'O', 'B', 'A', 'AB', 'B', 'O', 'AB', 'A', 'AB', 'B', 'B', 'O', 'A', 'B', 'O', 'B', 'O', 'O', 'AB', 'B', 'A', 'B', 'A', 'AB', 'A', 'A', 'O', 'O', 'AB', 'A', 'AB', 'B', 'AB', 'O', 'O', 'O', 'AB', 'B', 'AB', 'AB', 'B', 'AB', 'O', 'A', 'O', 'A', 'AB', 'A', 'O', 'A', 'B', 'O', 'O', 'B', 'A', 'AB', 'A', 'O', 'AB', 'AB', 'O', 'O', 'A', 'O', 'O', 'A', 'AB']
100
A형 : 24개
B형 : 24개
AB형 : 27개
O형 : 25개- randrange(): types 리스트의 인덱스 중 하나를 무작위로 선택하고, 선택한 인덱스를 사용하여 혈액형을 선택한다.
즉, 무작위로 생성된 혈액형 데이터를 생성하고, 각 혈액형의 개수를 출력하여 혈액형 데이터를 분석하는 예제이다.
15. 튜플이란
튜플이란 리스트와 비슷하지만 아이템 변경이 불가능 하다.
튜플 선언은 () 소괄호로 선언한다.
family = ('아빠','엄마','동생','할머니')
print('family Type:{}'.format(type(family)))
family[3] = '오빠'
#실행결과
family Type:<class 'tuple'>
TypeError: 'tuple' object does not support item assignment위 처럼 튜플을 선언해주고 인덱스 3번에 '오빠'를 삽입하려고 하는데 에러가 뜬다. 튜플은 아이템 삭제, 추가, 수정이 불가하다.
16. 튜플 결합
튜플결합은 리스트결합과 마찬가지로 덧셈연산자(+)를 이용하여 결합할 수 있다. 하지만 extend()함수는 튜플에서는 사용할 수 없다.
myNumbers = (1,3,5,6,7)
friendNumbers = (2,3,5,8,10)
for number in friendNumbers:
if number not in myNumbers:
myNumbers = myNumbers + (number, )
print('myNumbers: {}'.format(myNumbers))
#실행결과
myNumbers: (1, 3, 5, 6, 7, 2, 8, 10)myNumbers 와 for문으로 돌린 number값을 결합할때는 number값을 튜플로 변환해주어야한다(number값은 int로 되어있어 튜플과 이상태로는 결합이 되지 않는다.)
이때 튜플로 변환해주는 방법은 (number, ) 이렇게 소괄호와 쉼표를 이용하면 된다.
17. 튜플 슬라이싱
튜플도 리스트와 마찬가지로 슬라이싱을 하여 원하는 아이템을 추출할 수는 있다. 하지만 튜플에서는 슬라이싱을 이용하여 아이템을 변경할 수 는 없다.
korList = ('가','나','다','라','마','바','사')
print(korList[1:4])
print(korList[:4])
print(korList[:2])
korList[:2] = ('가1','나1')
#실행결과
TypeError: 'tuple' object does not support item assignment
('나', '다', '라')
('가', '나', '다', '라')
('가', '나')18. 리스트와 튜플 비교(차이점)
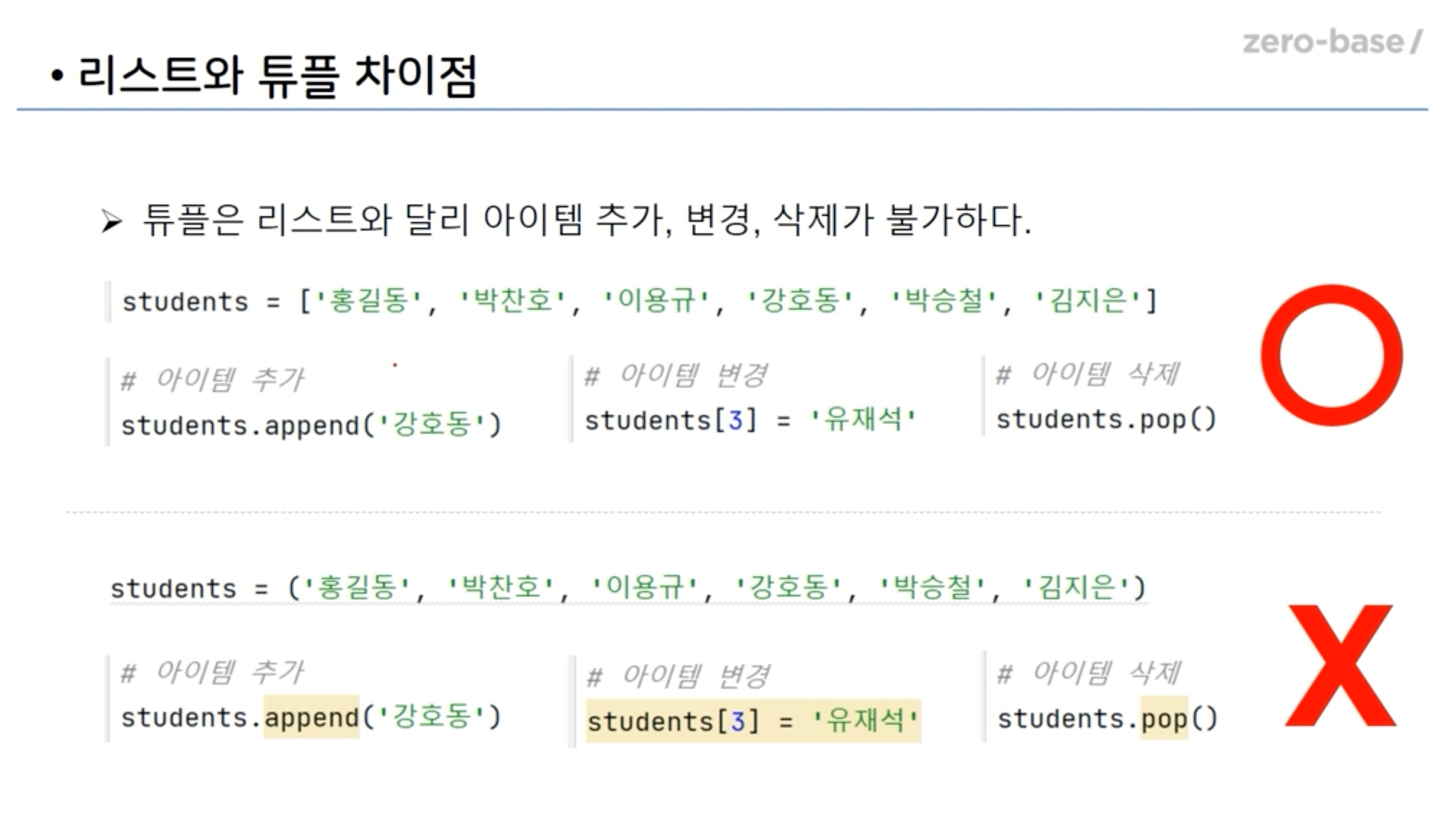
- 튜플은 선언시 괄호 생략이 가능하다(리스트는 생략x)
korList = '가','나','다','라','마','바','사'
print(type(korList))
#실행결과
<class 'tuple'>- 리스트와 튜플은 자료형 변환이 가능하다.
playerScore = (9.5,8.9,9.8,9.2,8.8,9.0)
playerScore = list(playerScore)
print('playerScore:{}'.format(playerScore))
playerScore.sort()
print('playerScore:{}'.format(playerScore))
playerScore.pop(0)
print('playerScore:{}'.format(playerScore))
playerScore.pop(len(playerScore)-1)
print('playerScore:{}'.format(playerScore))
avg=0
sum=0
for score in playerScore:
sum += score
avg = sum / len(playerScore)
print('총점:%.2f'%sum)
print('평균:%.2f'%avg)
#실행결과
playerScore:[9.5, 8.9, 9.8, 9.2, 8.8, 9.0]
playerScore:[8.8, 8.9, 9.0, 9.2, 9.5, 9.8]
playerScore:[8.9, 9.0, 9.2, 9.5, 9.8]
playerScore:[8.9, 9.0, 9.2, 9.5]
총점:36.60
평균:9.15playerScore 튜플형을 sort()함수를 이용하여 값을 추출할 수 없으니 리스트로 변환 후 풀었다.
19. 튜플 아이템 정렬
튜플은 수정이 불가하기 때문에 리스트로 변환 후 정렬한다.
playerScore = (9.5,8.9,9.8,9.2,8.8,9.0)
#튜플을 리스트로 변환
playerSocre = list(playerScore)
#아이템 정렬 실행
playerSocre.sort()
print('playerSocre:{}'.format(playerSocre))
#리스트를 튜플로 변환
tuplePlayerScore = tuple(playerSocre)
print(type(tuplePlayerScore))
#실행결과
playerSocre:[8.8, 8.9, 9.0, 9.2, 9.5, 9.8]
<class 'tuple'>sorted()함수를 이용하면 튜플도 정렬할 수 있다.
(단, 반환되는 값은 리스트 자료형으로 반환된다)
playerScore = (9.5,8.9,9.8,9.2,8.8,9.0)
sortedPlayerScore = sorted(playerScore)
print('sortedPlayerScore:{}'.format(sortedPlayerScore))
print(type(sortedPlayerScore))
#실행결과
sortedPlayerScore:[8.8, 8.9, 9.0, 9.2, 9.5, 9.8]
<class 'list'>20. for문을 이용한 튜플 조회
- 과목점수를 입력하여 과락 과목과 과락 점수를 추출해보자
minScore = 60
korScore = int(input('국어 점수:'))
engScore = int(input('영어 점수:'))
matScore = int(input('수학 점수:'))
sciScore = int(input('과학 점수:'))
artScore = int(input('미술 점수:'))
scores = (
('국어',korScore),
('영어',engScore),
('수학',matScore),
('과학',sciScore),
('미술',artScore),
)
for score in scores:
if score[1] < minScore:
print('과락 과목: {}과목 , {}점'.format(score[0],score[1]))
#실행결과
국어 점수:50
영어 점수:60
수학 점수:70
과학 점수:80
미술 점수:90
과락 과목: 국어과목 , 50점21. 딕셔너리란

딕셔너리: 키와 값의 쌍으로 구성된 자료 구조이다. 키는 유일해야 하며, 값은 중복이 허용한다.
- 딕셔너리는 중괄호({})를 사용하여 표현하며, 키와 값은 콜론(:)으로 구분한다.
- 딕셔너리는 리스트와는 다르게 순서가 없다. 또한 튜플과 다르게 변경이 가능하다.
22. 딕셔너리 조회
key값을 이용해서 value(값)을 조회할 수 있다.
"딕셔너리 이름[key]"
예시
>>> person = {'name': 'John Doe', 'age': 30, 'city': 'Seoul'}
>>> print(person['name'])
'John Doe'예제
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박세리'}
print('students[\'s1\']:{}'.format(students['s1']))
print('students[\'s2\']:{}'.format(students['s2']))
print('students[\'s3\']:{}'.format(students['s3']))
print('students[\'s4\']:{}'.format(students['s4']))
#실행결과
students['s1']:홍길동
students['s2']:박찬호
students['s3']:이용규
students['s4']:박세리- get()함수를 이용해서 value(값)을 조회할 수도 있다.
get()함수로 존재하지 않는 key값을 찾으면 none을 반환한다.
(기존의 key값으로 value값을 조회하면 에러가 뜬다)
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박세리'}
print('students[\'s4\']:{}'.format(students.get('s4')))
print('students[\'s5\']:{}'.format(students['s5']))
print('students[\'s5\']:{}'.format(students.get('s5')))
#출력값
students['s4']:박세리
KeyError: 's5'
students['s5']:None23. 딕셔너리 추가
key값 = value값 형태로 딕셔너리를 추가한다.
"딕셔너리 이름[key] = value"
예시
>>> person = {'name': 'John Doe', 'age': 30, 'city': 'Seoul'}
>>> person['gender'] = 'Male'
>>> print(person)
{'name': 'John Doe', 'age': 30, 'city': 'Seoul', 'gender': 'Male'}예제
students = {}
students['이름'] = input('이름 입력:')
students['학년'] = input('학년 입력:')
students['전공'] = input('전공 입력:')
students['메일'] = input('메일 입력:')
students['주소'] = input('주소 입력:')
print('students info: {}'.format(students))
#실행결과
이름 입력:윤세아
학년 입력:3
전공 입력:경영
메일 입력:xxx
주소 입력:korea
students info: {'이름': '윤세아 ', '학년': '3', '전공': '경영', '메일': 'xxx', '주소': 'korea'}24. 딕셔너리 조회(여러 함수를 이용)
keys()함수 : key 값 조회
values()함수 : value 값 조회
items()함수 : (key:value) 값 조회, 튜플형태로 조회됨
>>> person = {'name': 'John Doe', 'age': 30, 'city': 'Seoul'}
>>> print(person.keys())
dict_keys(['name', 'age', 'city'])
>>> person = {'name': 'John Doe', 'age': 30, 'city': 'Seoul'}
>>> print(person.values())
dict_values(['John Doe', 30, 'Seoul'])딕셔너리에는 리스트나 튜플처럼 인덱스가 존재하지 않기때문에 key값이 매우 중요하다. key값으로 value값을 조회하거나 수정할 수 있기 때문이다.
25. 딕셔너리 아이템 삭제
del, pop()함수를 이용하여 딕셔너리의 아이템을 삭제 할 수 있다.
pop()은 함수 이기 때문에 del과 달리 삭제된 값을 반환해준다.
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박세리'}
del students['s1']
print(students)
result = students.pop('s2')
print(students)
print('s2:{}'.format(result))
#실행결과
{'s2': '박찬호', 's3': '이용규', 's4': '박세리'}
{'s3': '이용규', 's4': '박세리'}
s2:박찬호26. 딕셔너리 유용한 기능
in, not in : 키(key)의 존재 유/무를 판단한다
len(): 딕셔너리(길이) 즉 아이템 개수를 알 수 있다.
clear(): 딕셔너리안의 모든 아이템을 전부 삭제 한다.
students = {'s1':'홍길동', 's2':'박찬호', 's3':'이용규', 's4':'박세리'}
# in
print('s1' in students)
print('s2' in students)
print('s3' in students)
print('s4' in students)
print('s5' in students)
# len()함수
print(len(students))
# clear()함수
students.clear()
print(students)
#실행결과
True
True
True
True
False
4
{}