
Multi-Variable Logistic Regression
- Training Data 입력

앞서 Regression에서는 Simple-Variable으로 진행하였지만 이번에는 Multi-Variable로 입력 데이터에 9x2 행렬, 출력 데이터에 9x1 행렬을 입력합니다.
- 가중치 W, 바이어스 b 초기

Training Data의 입력(x)과 출력(t)의 특성을 나타내기 위한 가중치 W와 바이어스 b를 0과 1사이의 값으로 random 메서드를 이용하여 초기화합니다.
x_data가 9x2 행렬이므로 가중치 W는 2x1 행렬로 초기화하여 진행합니다.
- sigmoid , loss function

Linear Regression과 Classification(분류)에서 0과 1의 출력 값을 가지기 때문에, 출력으로 0 ~ 1 사이 값을 가지게하는 sigmoid 함수와 앞 장에서 설명한 croos-entropy를 구하는 loss_fuc을 정의합니다.
- numerical_derivative(), error_val(), predict()


앞서 Linear Regression처럼 numerical_derivative(), error_val(), predict() 함수들의 정의입니다.
- 학습률 초기화 및 손실함수가 최소가 될 때까지 W, b 업데이트


Training Data를 이용하여 약 80000번의 Train을 진행 후 predict 함수를 이용하여 결과값을 살펴보았습니다.
입력 데이터는 예습과 복습에 대한 성적의 상관관계를 나타내었는데, (0 = 시험탈락, 1 = 시험붙음)
결과값을 살펴보니 예습에 투자한 시간이 복습보다 시험에 붙을 확률에 더 큰 영향을 줄 것이라 예상하였고
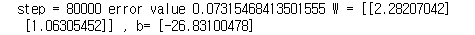
Training 후의 W1, W2 값을 살펴보니 W1 = 2.28 > W2 = 1.06으로 예습 data에 대한 가중치가 더 높음을 알 수 있었습니다.
또한, 초기값이나 Training 횟수, Learing Rate를 바꿔가며 Training을 진행해 보았는데 분포가 복잡한 데이터에 대해 Training을 진행하게되면 데이터의 분포나 상관관계에 따라 세가지 변수도 적절하게 조정해야할 것 같다는 생각이 들었습니다.
또한 Learning Rate는 Training 중에 고정값으로 진행되게 되는데, 이를 error value의 변화율이나 크기등을 기반으로 한 알고리즘을 통해서 가변적으로 실행된다면 Training 시간을 감소시킬 수 있지 않을까란 생각도 들었습니다.
