머신러닝, 딥러닝
1.1. [머신러닝] 개요 및 머신러닝의 분류

최근 개인적으로 많이 고민하고 느낀 부분은 앞으로 제 직업을 가지게 되는 분야가 생계를 위해서 혹은 대학교에서 공부하여 시간을 많이 투자했기 때문에 선택한 분야인지 아니면 제가 흥미를 갖게 되고 여기서 그칠 것이 아니라 해당 분야에 관한 노력과 투자를 통해 이 분야에
2.2. [머신러닝] Linear Regression
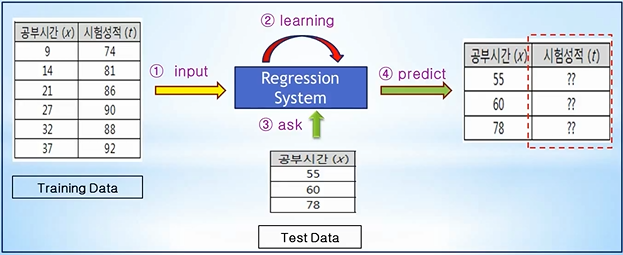
회귀 (Regression) Training Data를 이용하여 데이터의 특성과 상관관계 등을 파악하고, 그 결과를 바탕으로 Training Data에 없는 미지의 데이터가 주어졌을 경우에, 그 결과를 연속적인 (숫자) 값으로 예측하는 것 ex) 공부시간과 시험성적
3.3. [머신러닝] Linear Regression Code 구현

Training Data 입력https://blog.kakaocdn.net/dn/b2B8Ux/btqV35Z4gos/5Rf8aJeCnXpTaGMcju3vX1/img.png입력 데이터(x)와 출력 데이터(t)를 numpy를 이용하여 행렬 형태로 입력합니다.가중치
4.4. [머신러닝] Logistic Regression - Classification
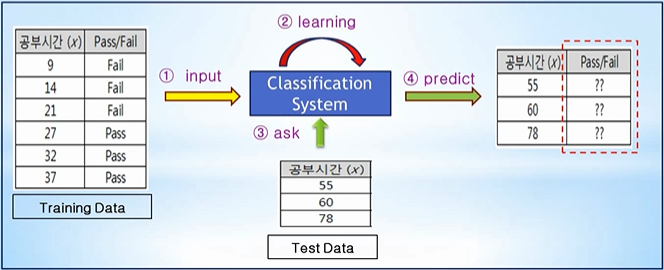
Training Data 특성과 관계 등을 파악한 후에,미지의 입력 데이터에 대해서 결과가 어떤 종류의 값으로 분류될 수 있는지를 예측https://blog.kakaocdn.net/dn/XUekH/btqV19WkTMf/50kvY21UY6gKvuHgPe5aC0/
5.5. [머신러닝] Logistic Regression - Classification Code 구현

Training Data 입력https://blog.kakaocdn.net/dn/cQG71P/btqWxg0aB0B/jWaswblt81wR0Qaopg23D0/img.png앞서 Regression에서는 Simple-Variable으로 진행하였지만 이번에는 Mult
6.6. [머신러닝] AND, OR, NAND, XOR Code 구현
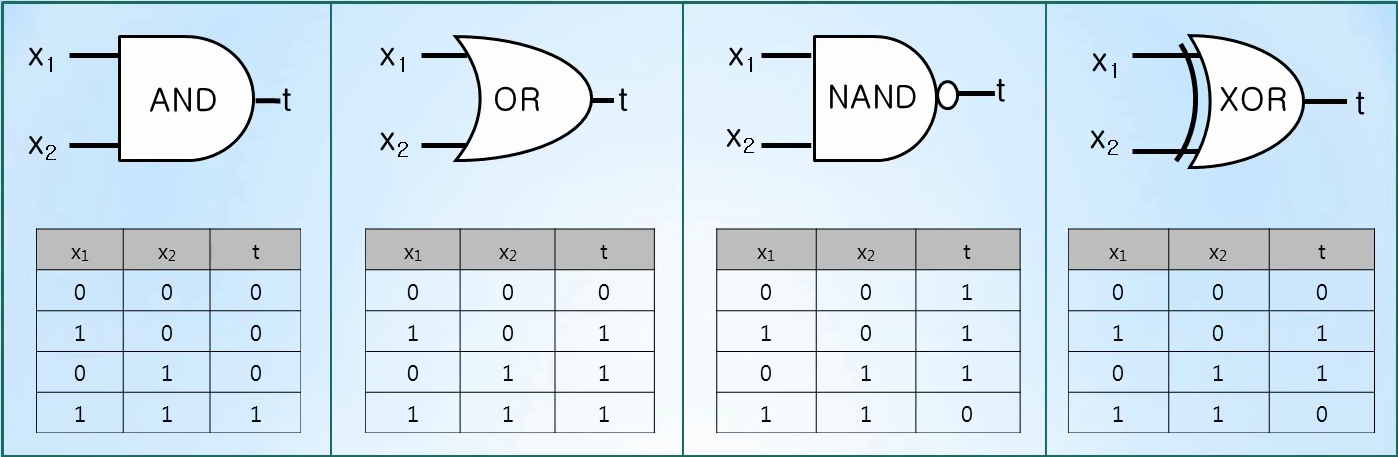
https://blog.kakaocdn.net/dn/MYujV/btqWc8vwKUm/xzwqfrNFnr4aQj2OooSKnK/img.pngAND, OR, NAND, XOR 논리테이블(Logical Table)은 입력 데이터(x1, x2), 정답 데이터 t(0
7.8. [딥러닝] Back-propagation(오차역전파)
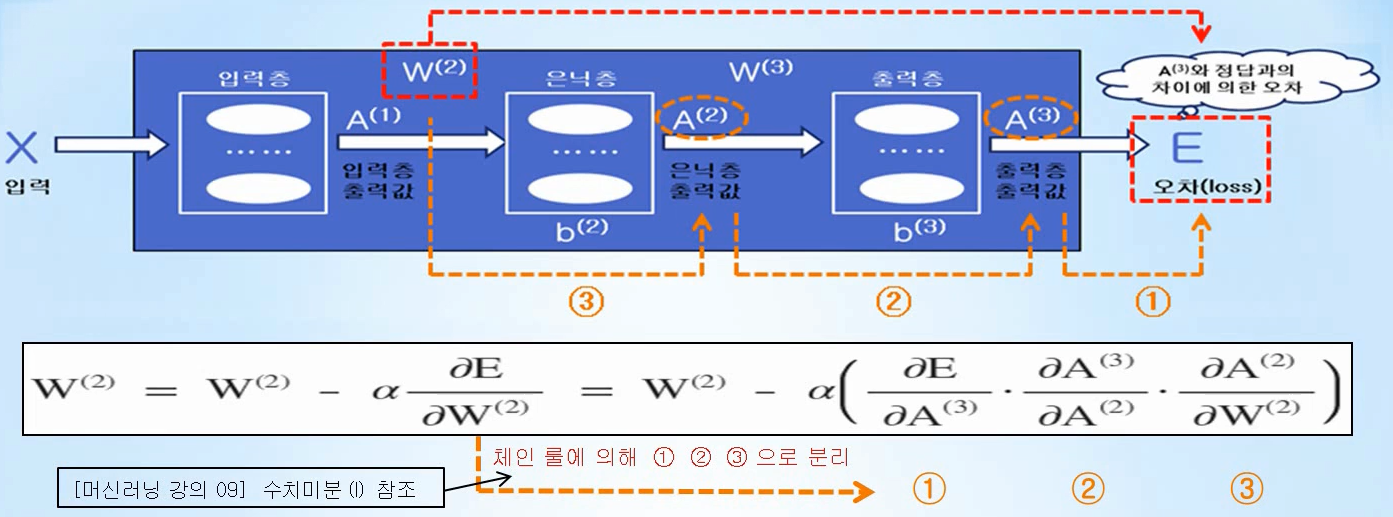
딥러닝의 꽃이라고 불리는 Back-propagation에 대해 알아보도록 하겠습니다.앞서 784x100x10 딥러닝 아키택쳐에서 60,000개의 MNIST를 학습을 진행해보니 시간이 제 컴퓨터 기준 반나절정도 소요되었습니다. 이유는 수치미분을 통하여 가중치/바이어스 업
8.9. [딥러닝] Back-Propagation을 이용한 MNIST Code 구현
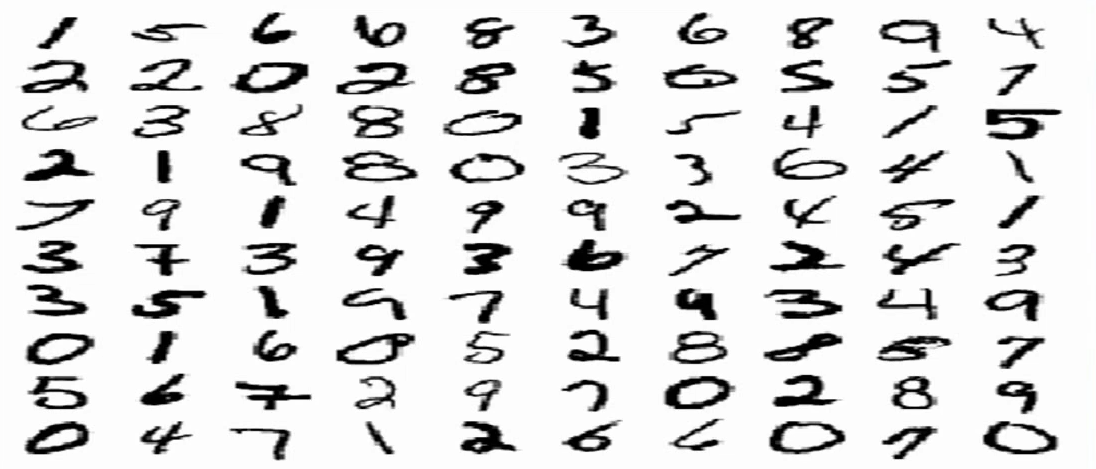
https://blog.kakaocdn.net/dn/dh1tuR/btqWzsGXOM1/JZOPsIG9KgfsphZpuwcaS0/img.pngMNIST(Modified National Institute of Standards and Technology datab
9.10. [딥러닝] CNN (Convolution Neural Network)
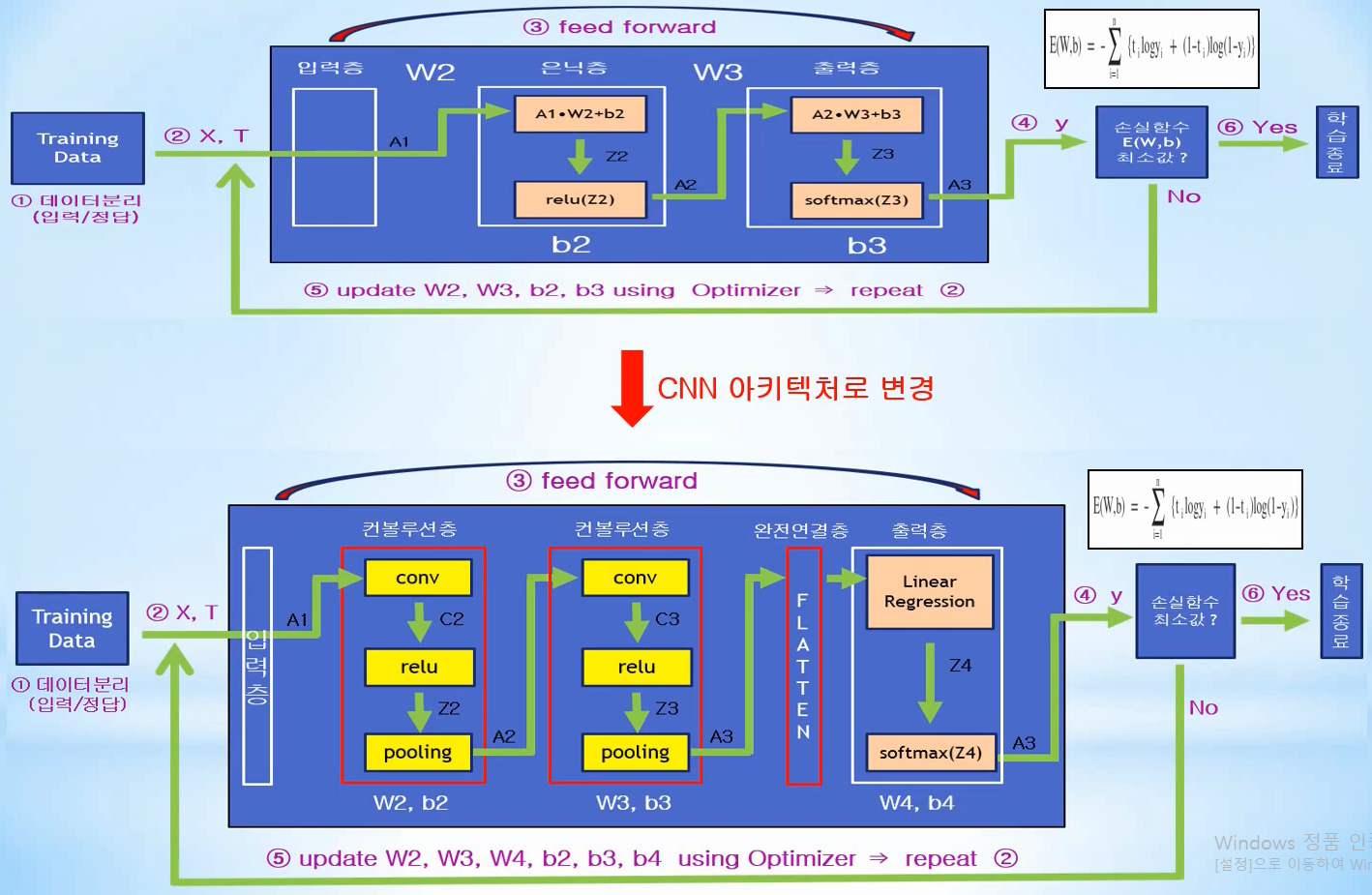
https://blog.kakaocdn.net/dn/cAAxzZ/btqWQ9nOtsa/NVH8jbMcLFS5omt8Pkhedk/img.png그림의 위쪽은 일반적인 신경망(Neural Network)으로 한개의 입력층과 여러개의 은닉층 그리고 최종 출력층으로 구
10.11. [딥러닝] RNN (Recurrent Neural Network)
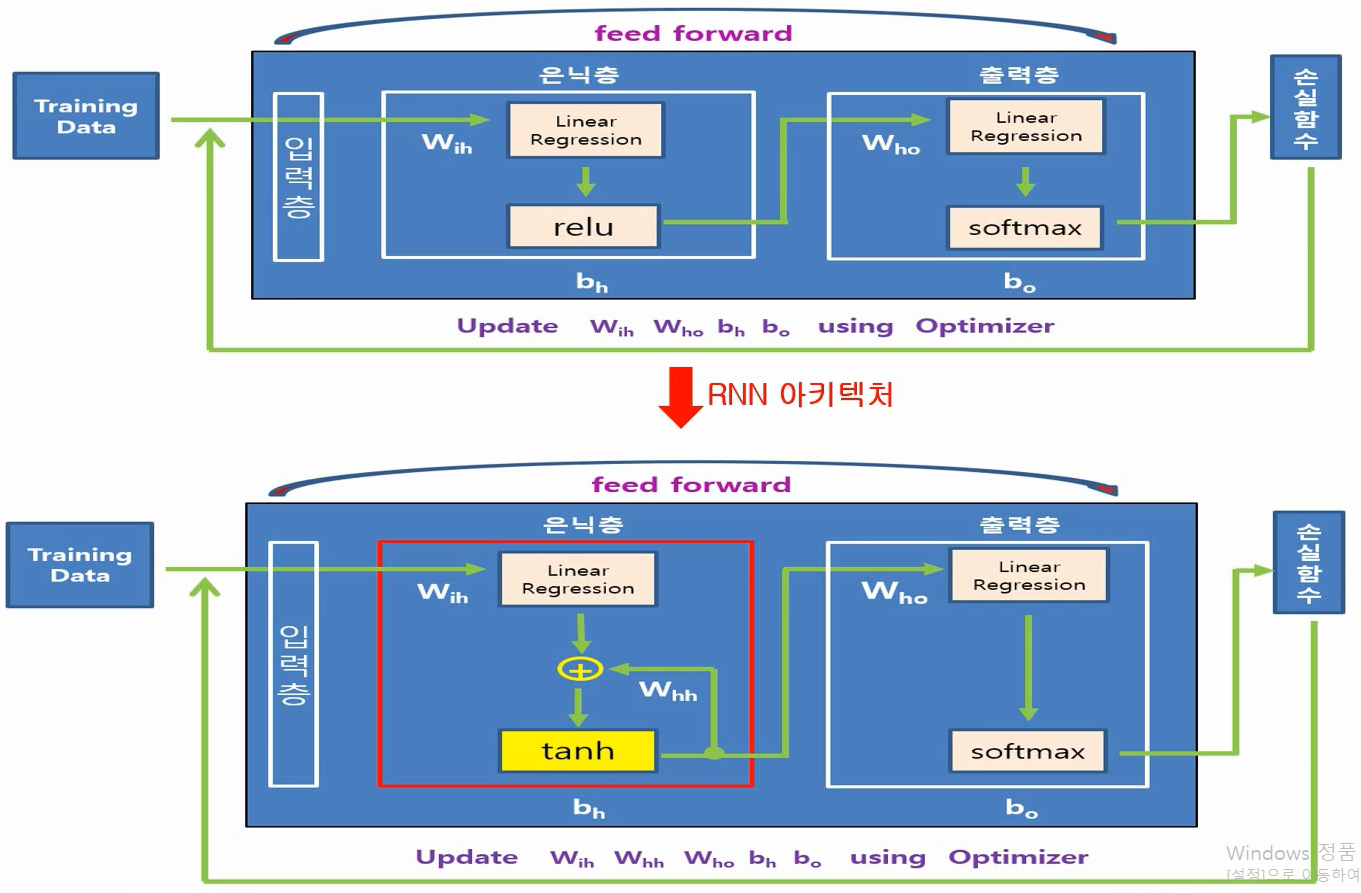
https://blog.kakaocdn.net/dn/LJQk5/btqWQ9abYhR/kWpUkwuhZd0EXa6PFDF0K1/img.pngRNN(Recurrent Neural Network) 또한 일반 신경망처럼 Training Data를 입력으로 Feed F