[논문리뷰 | CV] BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion Supplementary Material (2023) Summary
[논문리뷰]
목록 보기
32/42

Title
- BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion Supplementary Material

Abstract
기존 BEDLAM 논문에 주된 내용을 보충하기 위해 작성됨.
- 데이터셋 제작에 대한 자세한 정보
- 데이터셋 내용에 대한 추가적인 통계
- 데이터셋에서 추출한 예시 이미지
- 주된 내용에서 언급된 실험 결과
- 질적 결과의 시각적 표현
- BEDLAM-CLIFF와 BEDLAM-CLIFF-X는 3차원 인간 자세와 형태(3D Human Pose and Shape, HPS) 추정을 위해 개발된 두 가지 신경망 모델임.
- 이 두 모델은 BEDLAM 데이터셋에 대한 광범위한 실험을 통해 평가되었으며, 합성 데이터만을 이용하여 실제 이미지 데이터셋에 대한 SOTA 수준의 성능을 달성함으로써, 합성 데이터의 실제 적용 가능성을 입증하였음.
공통점
- BEDLAM 데이터셋을 이용하여 훈련되었으며, 3D Human Model을 생성하는 데 사용됨.
- 실제 환경에서의 3D 인간 자세 추정 알고리즘의 성능을 향상시키는 것을 목표로 함.
BEDLAM-CLIFF
- 실제 이미지 데이터를 사용하지 않고 오로지 합성 데이터만을 사용하여 훈련된 모델임.
- 이 모델은 신체의 위치 정보를 포함시켜 글로벌 회전을 예측할 수 있으며, 인간 감지에서 분리된 top-down 접근 방식을 채택
- BEDLAM-CLIFF 모델은 인간의 3D 자세를 추정할 때, 신체의 각 부위를 독립적으로 인식하고, 이를 통합하여 전체 신체의 3D 자세를 추정
BEDLAM-CLIFF-X
- BEDLAM-CLIFF의 확장 버전으로, SMPL-X 모델을 사용하여 손가락과 얼굴을 포함한 더욱 세부적인 신체 포즈를 추정
- 이 모델은 별도의 손 부위 네트워크를 훈련시키고, 이를 신체의 다른 부위 포즈와 결합하여 전체 신체 포즈를 생성
- 중요한 점은 BEDLAM-CLIFF와 손 부위 네트워크가 생성하는 손목 포즈가 다를 수 있기 때문에, 두 네트워크의 출력을 합치기 위해 추가적인 회귀기(regressor)를 훈련하여 사용.
- 이는 신체의 자연스럽지 않은 굽힘을 방지하고, 더 정확한 신체 포즈를 추정할 수 있게 도와줌.
1. Dataset creation
- BEDLAM은 다양한 신체 형태, 피부 톤, 모션을 포함하며, 이전 데이터셋과 달리 SMPL-X 몸체에 현실적인 의류와 머리카락이 물리적 시뮬레이션을 통해 애니메이션 처리됨.
- 이 데이터셋은 신체의 다양성을 보장하고, 실제 장면에서도 효과적으로 적용될 수 있는 정확한 3D 자세와 신체 형태 추정을 가능하게 함.

- 위의 그림은 BEDLAM 데이터셋의 신체 다양성과 관련된 부분을 설명
- BEDLAM에 사용된 271가지 서로 다른 신체 형태의 BMI 분포를 보여줌.
- 총 55,009개의 렌더링된 비디오에서 BMI 분포 제시
-> AGORA 데이터셋의 체형(파란색 바)와 CAESAR 데이터셋에서 고 BMI 체형(주황색 바)을 모두 사용하여 넓은 범위의 BMI를 커버함
- BEDLAM은 다양한 신체 유형을 포함하여 신체 다양성을 확보하기 위해 두 데이터셋의 체형을 통합하여 사용하고 있음.

- 위의 그림은 BEDLAM 데이터셋에서 사용된 의상의 복잡성을 의미함.
- 물리 기반 시뮬레이션으로 정확하게 모델링

- 위의 그림은 상단 시점에서 보는 골반 경로들의 예시를 보여주며, 이들은 서로 충돌하지 않도록 배치된 다양한 수의 인물들에 의해 생성됨.
1.1. Other body models
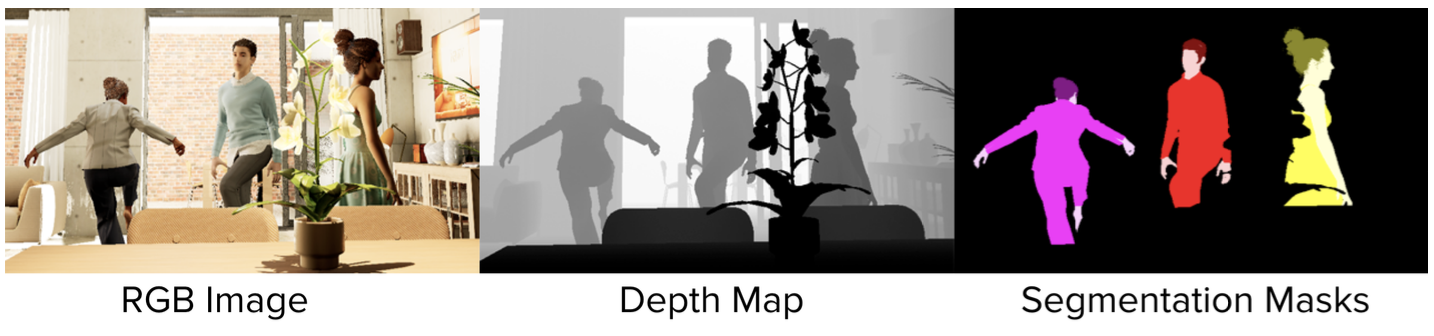
- BEDLAM 데이터셋이 SMPL-X 모델을 기반으로 설계됨.
- BEDLAM은 주로 SMPL-X 모델을 사용하지만, 많은 연구에서 SMPL 모델을 사용하기 때문에 SMPL 포맷의 Ground Truth도 제공할 예정임.
- BEDLAM은 Unreal Engine 5(UE5)로 렌더링되며, RGB 이미지 외에도 깊이 맵과 의미론적 분할 정보도 제공함. 이는 헤어, 의류, 피부 등에 대한 의미론적 라벨을 포함함.
- 이 추가 데이터를 통해 이미지에서 깊이를 추정하거나, RGB-D 데이터에 신체를 맞추는 방법, 의미론적 분할 등을 연구하는데 사용될 수 있음.
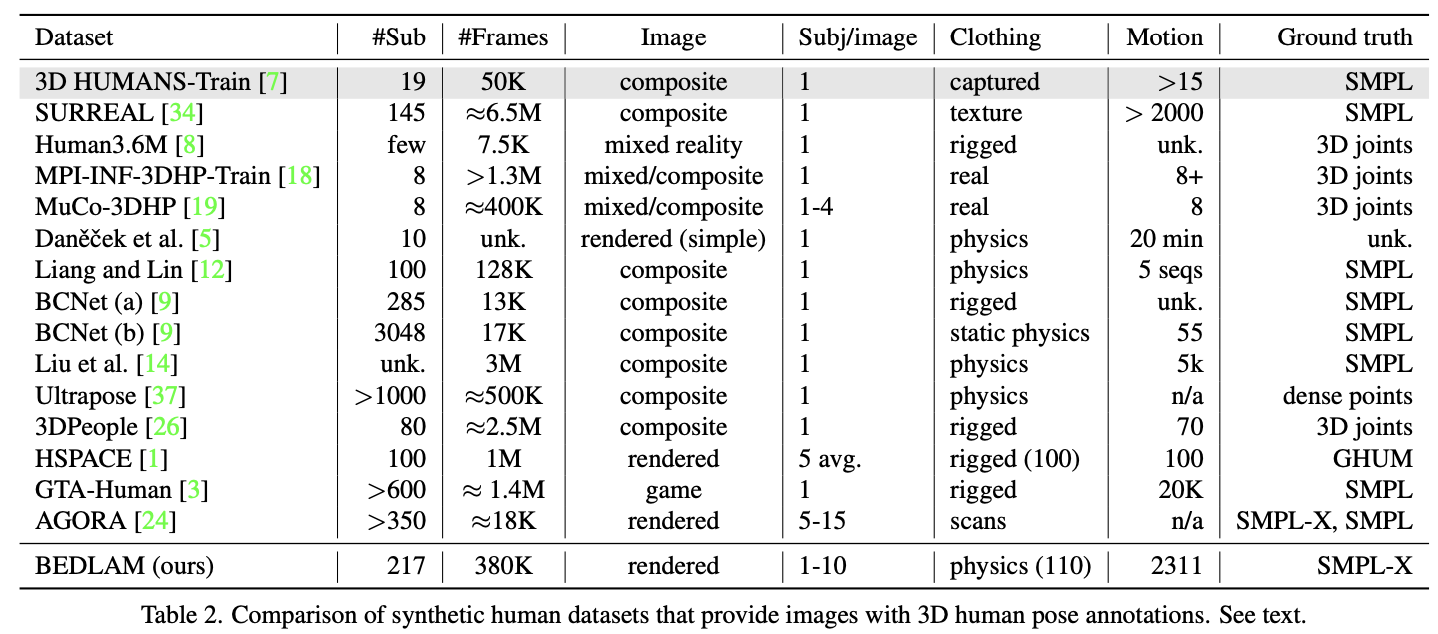
2. Comparison to other datasets
- 다양한 합성 데이터셋을 비교함.
3. Implementation Details
BEDLAM-CLIFF-X
- BEDLAM-CLIFF-X 네트워크는 주로 SMPL-X(3D 바디 메시 표현 표준) 바디 생성에 중점을 둠.
- BEDLAM에서의 손동작 데이터를 사용하여 BEDLAM-CLIFF-X라는 전신 네트워크를 훈련시킴.
- BEDLAM의 손 이미지 데이터를 기반으로 별도의 손 네트워크를 HMR(Human Mesh Recovery) 아키텍처로 훈련시키지만, SMPL 대신 SMPL-X와 호환되는
MANO모델로 대체함.
- 네트워크는 BEDLAM-CLIFF의
신체 포즈 출력()과 손 네트워크의손 포즈 출력()을 병합하여 관절이 있는 전신 포즈를 생성함. ()
- 얼굴 매개변수(, , ) (턱, 왼쪽 눈, 오른쪽 눈)는 중립으로 유지됨.
-> 즉, 감정이 변하지 않거나 표현되지 않음.
- 두 개의 출력(BEDLAM-CLIFF & 핸드 네트워크)은 서로 다른 손목 포즈를 제공하므로 직접 결합할 수 없음.
-> 따라서 작은 회귀분석기()는 이러한 두 가지 정보 소스를 효과적으로 병합하도록 훈련됨.
- 신체 포즈 ()와 손 포즈()는 BEDLAM-CLIFF-X 프레임 워크에 대해 정의됨.
📌
신체 포즈
( = {^, , }
📌
손 포즈
( = {, }
- 신체 포즈 ()는 SMPL-X의 처음 20개 포즈 매개변수로 구성되는 반면, 손 포즈()는 손목과 손가락의 포즈 매개변수로 구성됨.
- 이 회귀분석기()는 두 네트워크에서 golbal average pooled된 기능을 가져와 몸과 손 자세를 모두 포함하는 결합된 출력을 생성.
📌
회귀분석기 Output
( = {^, + , + })
- 기본적으로, 는 신체 네트워크와 손 네트워크로부터 얻은 정보를 사용하여 팔꿈치와 손목 포즈에 대한 업데이트를 학습함.
- 신체 네트워크에서 생성된 손목 포즈에 대한 업데이트만을 학습하기 때문에, 손목의 부자연스러운 구부러짐을 방지함.
- BEDLAM-CLIFF와 마찬가지로 BEDLAM-CLIFF-X를 훈련하기 위해, 모델 파라미터에 대한
MSE Loss,projected keypoints,3D joints,3D vertices에 대한 L1 Loss의 조합을 사용함.
4. Supplemental experiments
4.1. SMPL-X experiments on BEDLAM
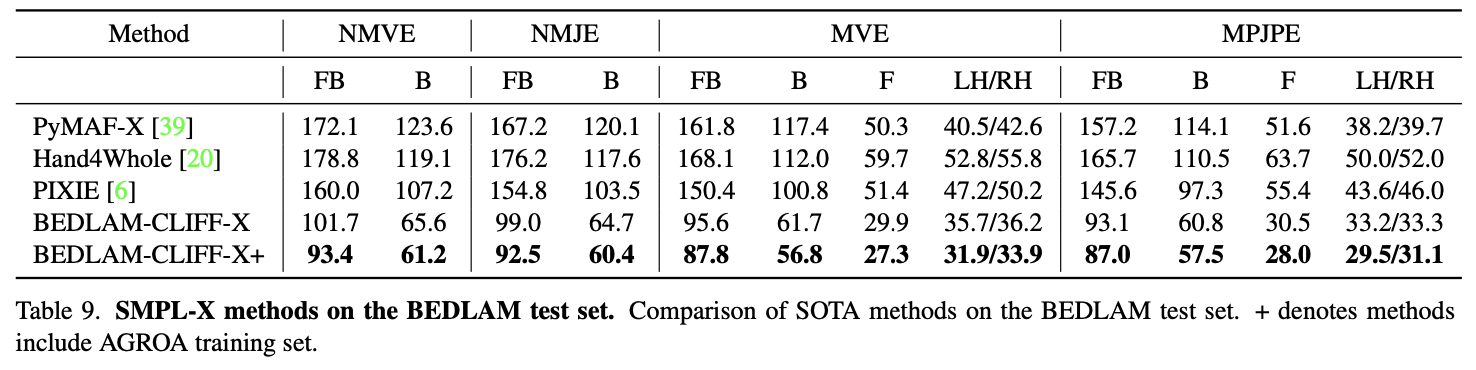
- 위의 표는 BEDLAM-CLIFF-X가 BEDLAM 테스트 세트에서 SMPL-X를 추정하는 최신 SOTA 방법보다 더 나은 성능을 보임을 보여줌.
5. Qualitative Comparison

- 위의 그림은 PARE, CLIFF, BEDLAM-CLIFF 사이의 질적 비교를 제공함.
-
RICH (왼쪽 두 개)와 3DPW (오른쪽 두 개)에서의 결과를 보여줌.
-> 예측된 몸체를 이미지 위에 겹쳐서 그리고 옆면에서 봤을 때를 렌더링 -
옆면 뷰는 BEDLAM-CLIFF (맨 아래 줄)가 카메라, 카메라 각도, 프레임 가리기 변화에도 불구하고 3D에서 실제 몸체와 더 잘 정렬된 몸체 자세를 예측함.
- 또한, 가려진 경우 다른 방법들에 비해 BEDLAM-CLIFF가 더 자연스러운 다리 자세를 생성한다는 것을 위의 그림의 1, 3, 4열에서 볼 수 있음.

- 위의 그림은 3DPW와 RICH 데이터셋에 대한 BEDLAM-CLIFF-X의 질적 결과를 제공함.
- 이 경우, 우리는 SMPL-X 손 자세도 추정함.
🎯 Summary
- 저자가 뭘 해내고 싶어 했는가?
- BEDLAM-CLIFF와 BEDLAM-CLIFF-X라는 두 가지 신경망 모델을 개발하여, 합성 데이터만으로 훈련된 모델이 실제 촬영된 이미지에서의 3D 인간 포즈와 형태 추정에서 얼마나 잘 일반화되는지를 측정하고자 함.
- 이 연구의 접근 방식에서 중요한 요소는 무엇인가?
- 합성 데이터의 현실성과 다양성
- 이를 활용한 신경망 모델의 훈련 방법론
- 참고하고 싶은 다른 레퍼런스에는 어떤 것이 있는가?
- SMPL-X
- BEDLAM: A Synthetic Dataset of Bodies Exhibiting Detailed Lifelike Animated Motion
- 느낀점은?
- BEDLAM 코드를 뜯어보는 도중, BEDLAM-CLIFF와 BEDLAM-CLIFF-X 모델을 알게 되었고, 이를 구체적으로 공부하고자 논문을 읽음.
- 이는 BEDLAM이라는 합성 데이터셋만으로 사용하여 훈련된 모델들이었고, 이제는 정확한 차이를 알 수 있었음. Good!!
📚 References
논문

AI 전문가가 되기 위해 [a-zA-Z]까지 정리하는 거나입니다 😊