
정확도
모델이 분류, 그 중에서도 맞냐, 아니냐를 정하는 이진분류(Binaray Classfication)를 수행할 때 사용되는 대표적인 평가지표는
- 정확도(Accuracy)
- 정밀도(Precision)
- 재현율(Recall)
- 오차행렬(Confusion Matrix)
- F1 Score
- ROC, AUC
가 있는데, 정확도에 대해서 먼저 알아보자.
정확도는 모델의 예측이 얼마나 잘 맞는지 평가할 수 있는 가장 직관적인 데이터이자, 가장 쉽게 떠올릴 수 있는 지표이다. 전체 예측 데이터 건수 중 예측이 실제와 동일한 건수에 해당하는 값으로 다음과 같이 계산할 수 있다.

예를 들어 병원에서 의료 진단 모델로 100명의 환자에게 질병의 유무를 예측한다고 상상해보자. 실제로 질병이 있는 사람이 30명, 없는 사람이 70명이고 의료 진단 모델이 질병이 있는사람 30명 중 28명을 정확히 진단해냈고, 질병이 없는 70명 중 65명을 정확히 진단해냈다면 이 의료 진단 모델의 정확도는 (28+65)/100 = 93% 로 계산된다.
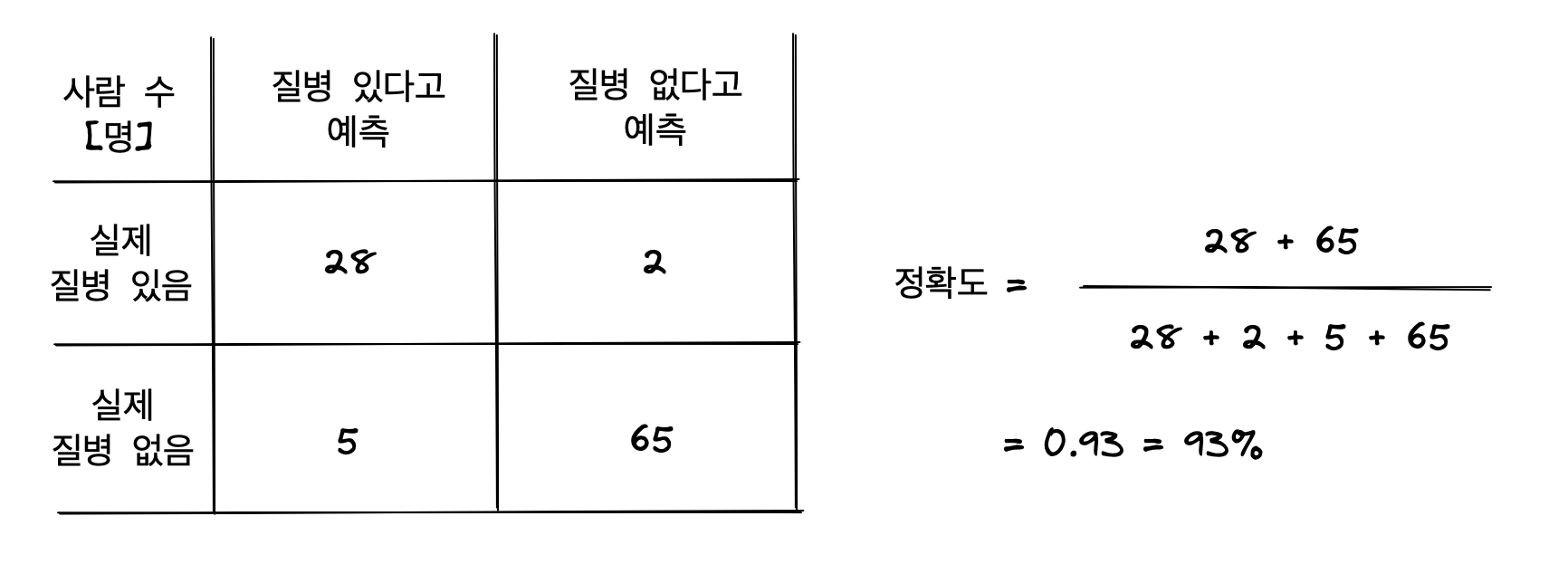
정확도를 이용하면 이진분류모델의 성능이 쓸만한지 아닌지 가장 쉽게 파악할 수 있다.
그러나, 정확도를 사용할 때는 주의해야 할 점이 하나 있다. 바로 데이터 불균형이 심할 경우이다. 즉, 학습시키는 데이터의 분류가 지나치게 한 쪽에 몰려있을 경우에는 다수를 위주로 학습했기 때문에 소수에 해당하는 데이터를 잘 못 분류하게 된다.
정확도의 오류
예를 들어, 질병이 없는 사람 대비 질병이 있는 사람의 수는 적기 때문에 학습시킨 의료진단모델이 건강한 사람은 잘 찾아내지만 질병이 있는 사람을 못 찾아낸다고 해보자. 실제상황에서는 의미가 없는 모델이다. 예를 들어 990명의 건강한 사람과 10명의 질병을 가진 사람을 모델이 분류한다고 해보자. 이 모델은 990명의 건강한 사람은 모두 찾아냈지만 질병을 가진 사람은 10명중 1명만 찾아낼 수 있을 것이다.
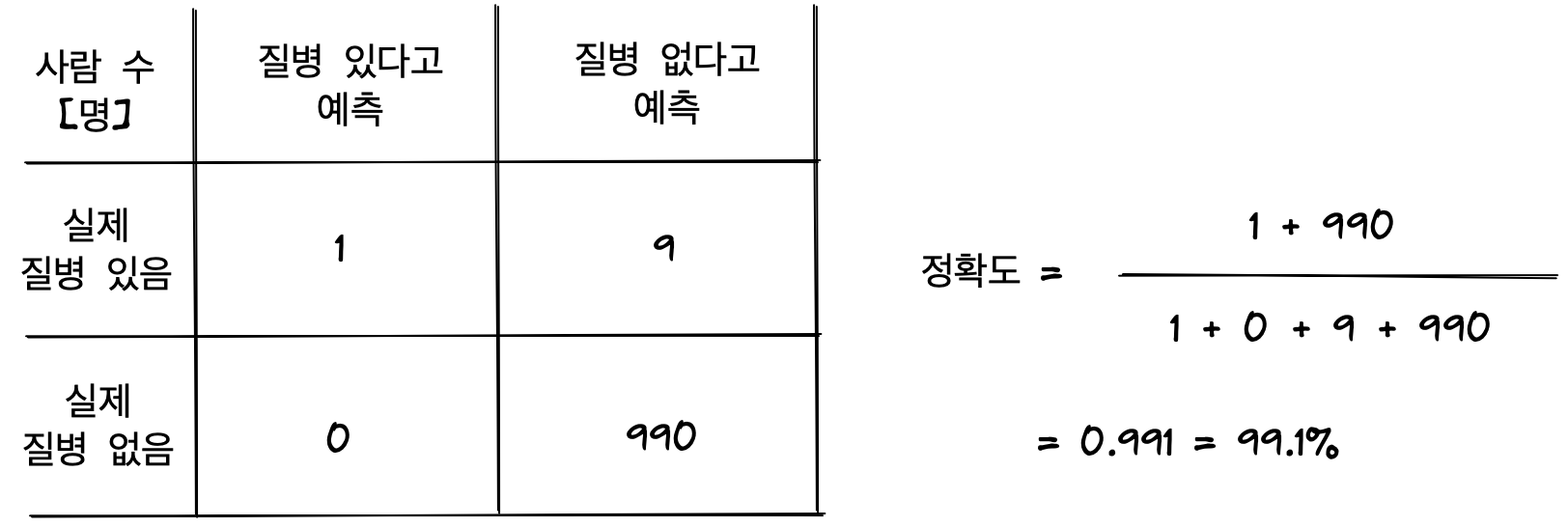
이 경우에 정확도를 계산해보면 무려 99.1%로 이 모델은 질병의 유무여부를 굉장히 잘 판단한다는 의미가 도출된다. 그러나 실제로는 아무리 질병이 없는 사람을 잘 찾아낸다고 해도, 질병이 있는 사람을 못 찾아내는 모델이기 때문에 도입해서 사용하게 되면 병원의 입장이 곤란해질 것이다.
로직 기반 모델과 정확도
또한 모델의 학습이 의미없어질 수도 있다. 로직기반으로 판단하는 것과 별 차이가 없기 때문이다. 가짜 모델을 만들어 로직 기반으로 단순히 모든 사람의 질병이 없다고 예측한다고 해보자. 그러면 질병이 있다고 예측하여 맞춘 경우는 없지만 질병이 없다고 예측하여 맞춘 경우는 990건이므로
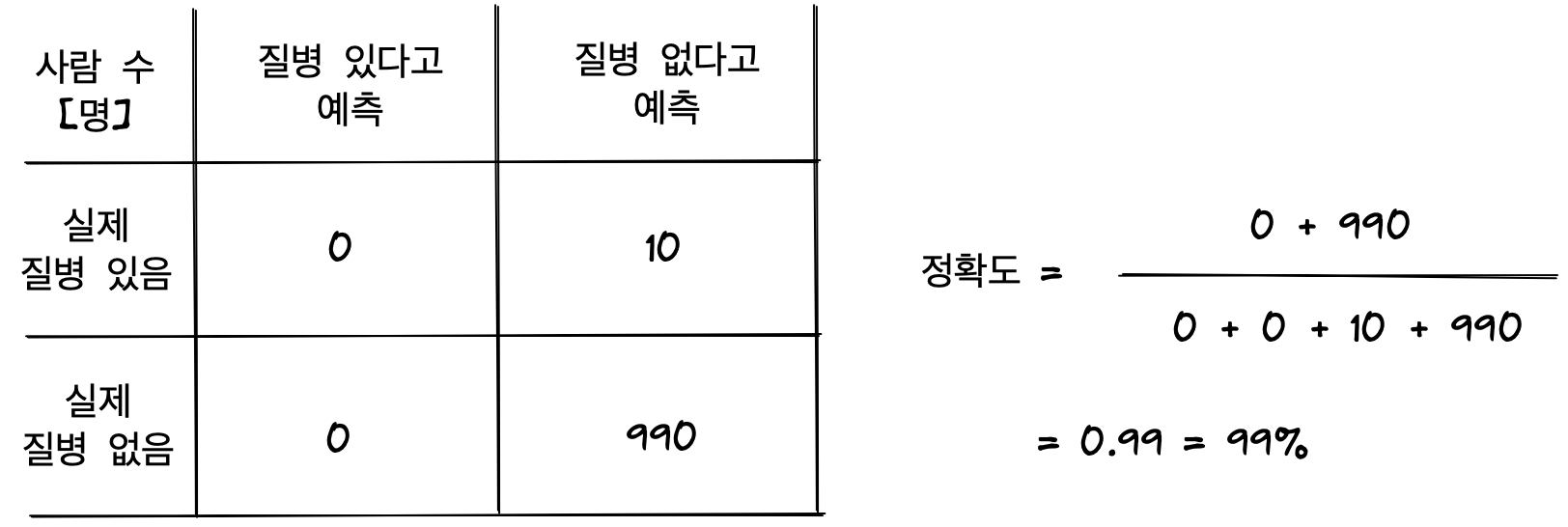
무려 99% 정확도를 보여준다. 정확도가 99%이지만 질병이 있는 환자를 한 명도 찾지 못한다.
타이타닉 생존자 예측 예시
타이타닉의 생존자 예측으로도 로직 기반 모델과 기계학습모델의 정확도를 비교해보자.
로직 기반으로 판단하는 모델은 성별 피처를 보고 남성이면 0, 여성이면 1로 생존여부를 판단한다.
- 테스트를 위한 로직 기반 가짜모델을 생성한다.
import numpy as np
import pandas as pd
import sklearn
# 가짜 더미 모델을 생성.
class MyDummyClassifier(sklearn.base.BaseEstimator):
# fit(): 아무것도 학습 X. 그냥 pass.
def fit(self):
pass
# predict(): 해당 피처의 값이 1이면 0, 0이면 1.
def predict(self, x_test:pd.Series):
# 변수를 Series로 받아온다.
pred = np.zeros((x_test.shape[0], 1)) # 예측값을 0으로 채운 배열 생성.
for i in range(x_test.shape[0]):
if x_test.iloc[i] == 0:
pred[i] = 1
elif x_test.iloc[i] == 1:
pred[i] = 0
return pred- 모델에 입력할 수 있는 데이터형식이 되도록 전처리 과정을 정의한다.
# 데이터 전처리를 위한 함수선언
# Null 처리
def fillna_features(df:pd.DataFrame, inplace=False)-> pd.DataFrame:
df.fillna(value={'Age':df['Age'].mean,
'Cabin':'N',
'Embarked':'N',
'Fare':0}, inplace=inplace)
return df
# 머신러닝에 불필요한 Feature 제거
def drop_features(df:pd.DataFrame,axis=1, inplace=False)-> pd.DataFrame:
df.drop(['PassengerId', 'Name', 'Ticket'], axis=axis, inplace=inplace)
return df
# 레이블 인코딩 수행
def format_features(df:pd.DataFrame)->pd.DataFrame:
df['Cabin']=df['Cabin'].str[:1]
features=['Cabin','Sex','Embarked']
for feature in features:
le = sklearn.preprocessing.LabelEncoder()
le= le.fit(df[feature])
df[feature]=le.transform(df[feature])
return df
# Data Processing 호출
def transform_features(df:pd.DataFrame)-> pd.DataFrame:
temp_df = fillna_features(df,inplace=True)
temp_df = drop_features(temp_df, inplace=True)
temp_df = format_features(temp_df)
return temp_df- 데이터를 불러와 전처리 과정을 적용하고 로직 기반 가짜모델로 예측한다.
# 데이터를 불러오고 전처리 적용.
titanic_df = pd.read_csv('titanic_train.csv') # 데이터를 불러온다.
y_titanic_df = titanic_df['Survived'] # target 데이터는 'Survived'이다.
X_titanic_df = titanic_df.drop('Survived', axis=1) # 나머지를 feature 데이터로 쓰려고 'Survived' 컬럼을 drop한다.
X_titanic_df = transform_features(X_titanic_df) # 데이터 전처리를 수행한다.
# 학습/테스트 데이터 분리
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.2,
random_state=0) # 20퍼센트가 테스트데이터 되도록 분리한다.
# 가짜 모델
myclf = MyDummyClassifier() # 가짜 모델 객체 생성.
myclf.fit(X_train, y_train) # 가짜 모델로 학습. 사실상 하는 거 없음.
mypredictions = myclf.predict(X_test) # 가짜 모델로 예측.
print(f"Dummy Classifier의 정확도는: {accuracy_score(y_test, mypredictions):.4f}")
로직 기반으로 만들어진 가짜모델의 정확도가 78%로 꽤 높게 나오기 때문에 정확도만 봐서는 학습이 잘 된 것인지 아닌지 판단하기 어렵다. 이처럼 정확도 하나만으로는 모델의 성능을 오판하게 되므로 정밀도, 재현율, F1 Score 등 다른 지표로 크로스체크가 필요하다.
