
정확도 외에 이진분류모델을 평가하는 다른 지표들에는 정밀도, 재현율, Confusion Matrix, F1 Score 등이 있다. 그 중 Confusion Matrix, 정밀도, 그리고 재현율에 대해 알아보자.
Confusion Matrix
Confusion Matrix는 오차행렬, 혹은 혼동행렬이라고 번역되는데, 이진분류의 예측오류와 더불어 어떠한 유형의 예측오류가 얼마나 발생하는지 나타내는 지표이다.
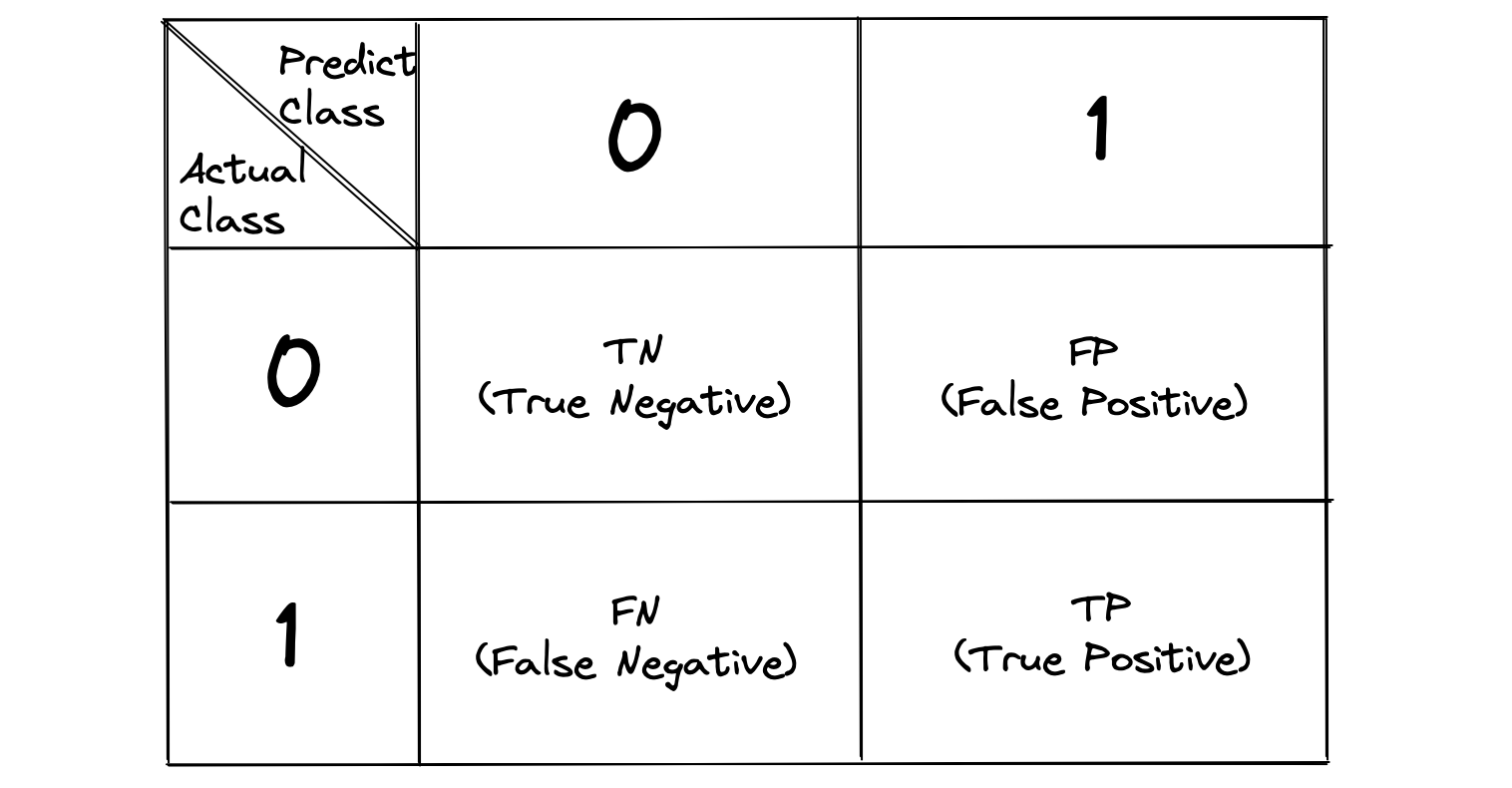
Confusion Matrix 각 성분은 모델의 예측값과 실제 값이 서로 같은지 다른지에 따라 나뉜다. 모델이 예측한 값이 1인 경우, 즉 우리가 관심이 있는 값으로 예측한 경우 Positive이고, 아닐 경우 Negative이다. 그리고 각각의 예측이 실제 값과 일치할 경우 True이고, 아닐 경우 False이다.
- TP(True Positive): 모델의 예측이 우리가 관심이 있는 값이고(Positive), 실제 답도 우리가 관심이 있는 값으로 모델이 잘 맞췄다(True).
- FP(False Positive): 모델의 예측이 우리가 관심이 있는 값이고(Positive), 실제 답은 우리가 관심이 없는 값으로 모델이 못 맞췄다(False).
- TN(True Negative): 모델의 예측이 우리가 관심 없는 값이고(Negative), 실제 답도 우리가 관심이 없는 값으로 모델이 잘 맞췄다(True).
- FN(False Negative): 모델의 예측이 우리가 관심이 있는 값이고(Negative), 실제 답은 우리가 관심이 있는 값으로 모델이 못 맞췄다(False).
예를 들어, 어떠한 파일이 악성코드에 감염이 되었는지 안 되었는지 판단한다고 해보자. 감염되었을 때가 관심 있으니 1로 볼 수 있다. 그러면 4가지 성분은 다음과 같은 의미를 갖는다.
- TP: 모델이 악성코드에 감염됐다고 판단했는데, 실제로 악성코드가 있는 파일일 경우.
- FP: 모델이 악성코드에 감염됐다고 판단했는데, 실제로 악성코드는 없는 파일.
- TN: 모델이 악성코드 없는 파일이라고 판단했는데, 실제로 악성코드 없는 파일일 경우.
- FN: 모델이 악성코드 없는 파일이라고 판단했는데, 실제로는 악성코드 있는 파일.
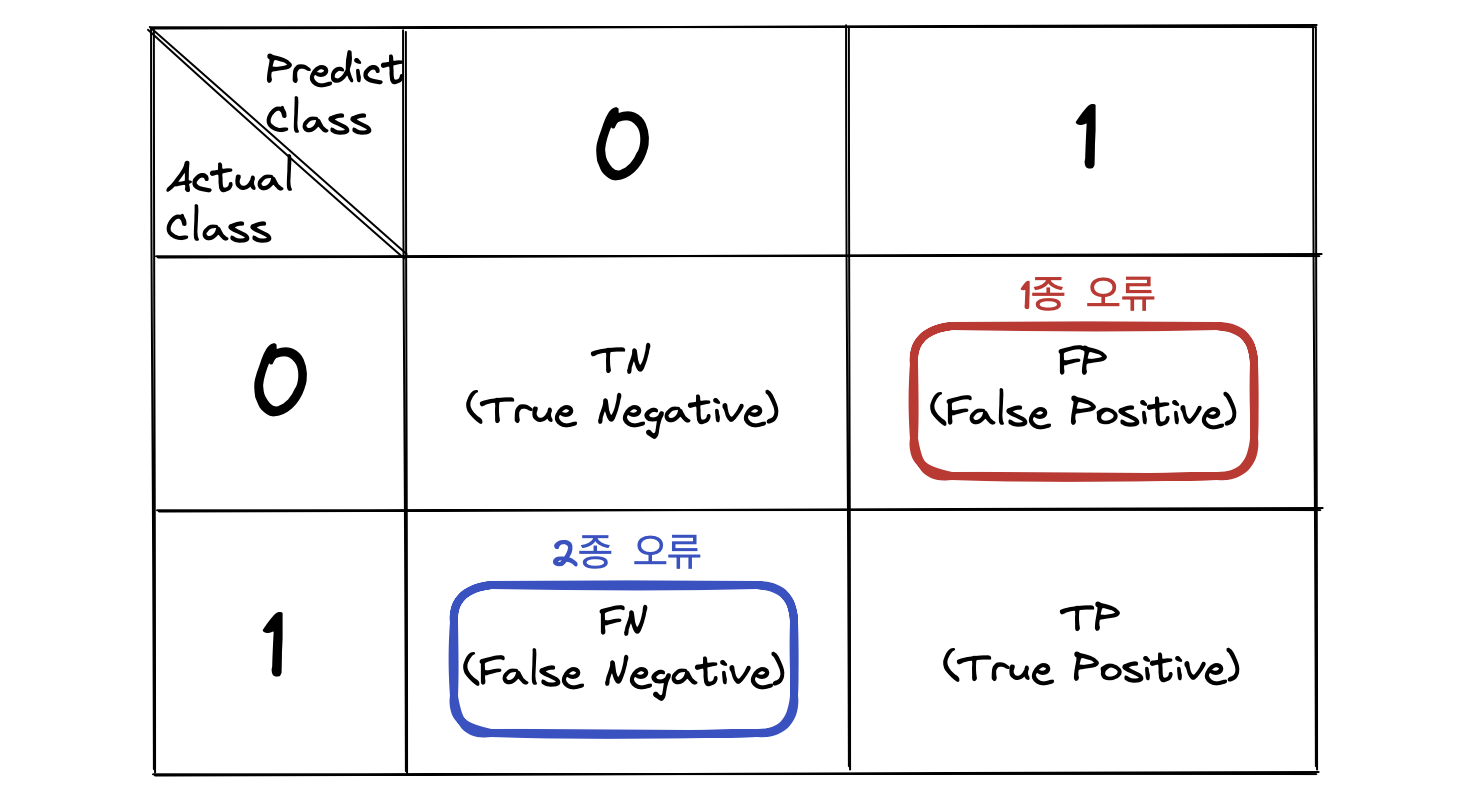
Confusion Matrix에서 FP와 FN은 각각 예측 오류 유형 중 1종 오류와 2종 오류를 의미한다. 1종 오류란 가설검정이론에서 가설이 맞을거라고 했지만 실제는 아닌 상황. 그리고 2종 오류란 반대로 가설이 틀릴거라고 했지만 실제는 맞는 상황을 뜻한다. 쉽게 말해 1종오류는 잘못 맞춘 경우고, 2종 오류는 잘못 틀린 경우다.
정밀도 (Precision)
정밀도는 모델이 관심있는 값이라고 예측한 경우에 대해 실제와 일치하는 비율을 말하는 지표이다. 예를 들어, 악성코드 파일을 찾는 모델이 있다고 해보자. 악성코드 있다고 예측한 파일 중 실제로 악성코드가 있는 파일이 얼마나 있는지에 해당하는 비율을 말한다.
- 정밀도(Precision) = TP / (TP+FP)
정밀도는 Confusion Matrix에서 모델이 1이라고 예측한 값들의 모임 TP+FP 중에서 TP가 몇 건인지의 비율로 계산한다.
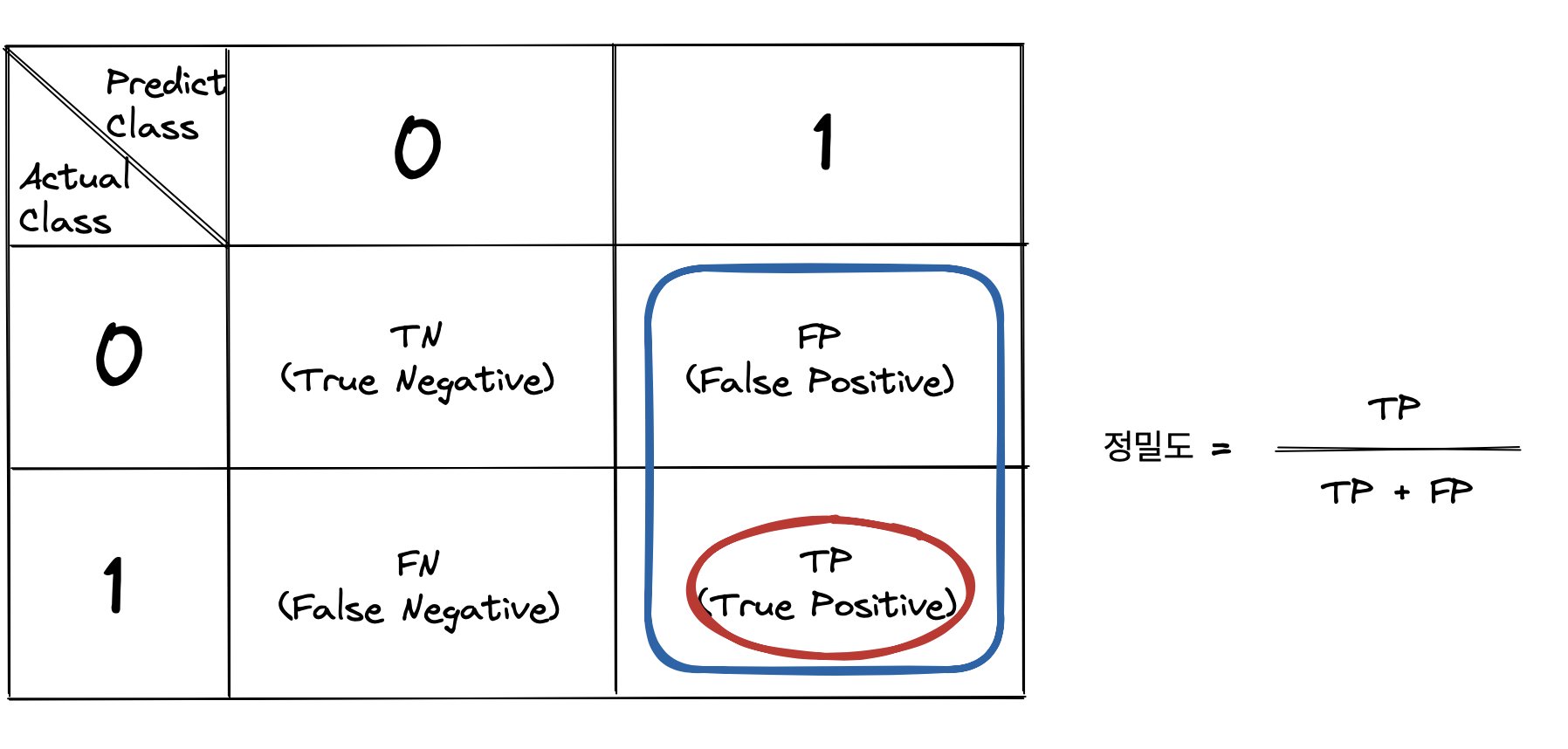
TP가 충분히 보장되었다고 할 때, 정밀도가 높으려면 FP 케이스가 적어지도록 만들어줘야 한다. FP 케이스를 줄인다는 건, 맞다고 판단했는데 실제로 아닌 경우를 줄인다는 뜻이다. 반대로 정밀도가 낮으면 FP 케이스가 많다는 뜻이고 이는 모델이 잘못 맞다고 판단한 경우가 많음을 뜻한다.
정밀도가 중요한 지표로 사용될 때는 FP가 불러오는 손해가 큰 경우이다.
-
스팸메일 필터링을 하는 모델이 있다고 해보자. 고객에게 오는 스팸메일 뿐 아니라(TP) 거의 모든 메일을 스팸메일이라고 판단해서 안 보여준다면(FP>TP), 고객은 일반 은행이나 병원에서 온 메일도 확인하지 못하고 중요한 메일을 놓쳐 오히려 스팸메일보다 더 큰 손해를 입을 것이다.
-
은행 및 카드사에서 사기 거래를 잡아내기 위한 모델이 가짜거래 뿐 아니라(TP) 진짜거래도 모두 사기라고 판단해서 거래정지 시켜버린다면 (FP>TP), 고객이 편의점에서 물건을 사도 거래정지가 되어 가짜거래로 인한 피해보다 더 큰 비용을 지불하게 될 것이다.
-
주변차량 인식모델이 진짜 차량도 잡아내지만(TP), 차량이 아닌 것도 과하게 차량이라고 잡아내어 사고날 것 같다고 차를 멈춰버린다면(FP>TP), 오히려 기업은 주변차량을 못 잡아낼 때보다 고객으로부터 더 큰 항의를 받을 수도 있다.
정밀도를 이용하면 모델이 예측한 관심있는 케이스가 얼마나 실제와 잘 일치하는지 파악할 수 있으므로, 모델의 성능을 평가하는 데에 중요한 지표로 쓰인다.
재현율 (Recall)
재현율은 모델이 실제로 관심있는 값을 얼마나 잘 찾아내는지를 나타내는 지표이다. 예를 들면, 실제 악성코드가 있는 파일 중 악성코드가 있다고 맞게 예측한 파일이 얼마나 되는지가 재현율에 해당한다.
- 재현율(Recall) = TP / (TP+FN)
재현율은 Confusion Matrix에서 실제 1이라고 판정된 사례들(TP+FN) 중 TP가 몇 건인지 비율로 나타낼 수 있다. 이는 실제로 중요한 값을 놓치지 않는 정도를 측정한다.
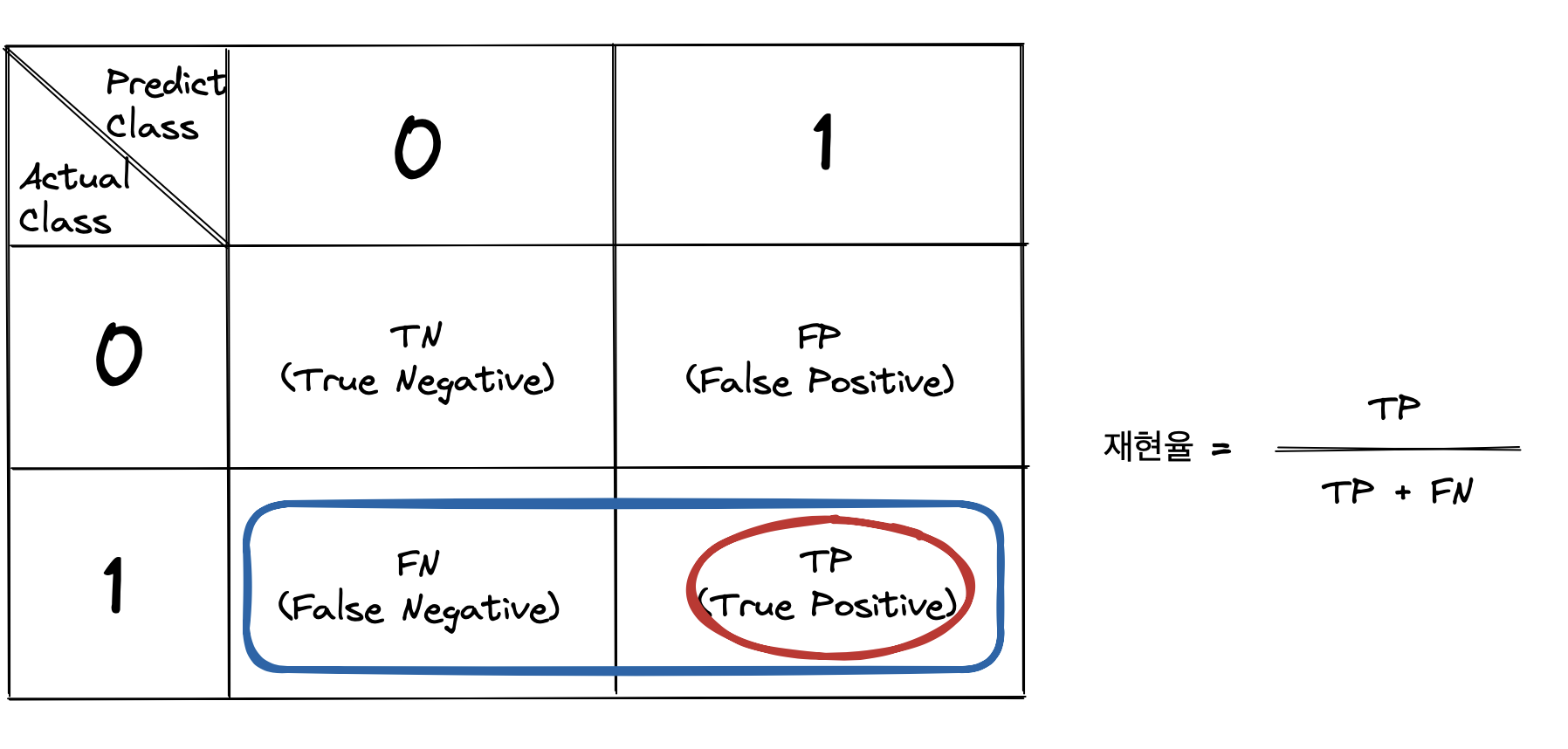
TP를 충분히 확보했다고 할 때, 재현율이 높으려면 FN 케이스가 적어지도록 만들어줘야 한다. FN을 줄인다는 것은 실제로 관심있는 값들 중 모델이 잘못 예측한 경우를 줄인다는 뜻이다. 반대로 재현율이 낮으면 FN 케이스가 많다는 것을 의미하며, 이는 모델이 실제 중요한 경우를 많이 놓쳤음을 나타낸다.
재현율이 중요한 지표로 사용될 때는 FN이 불러오는 손해가 큰 경우이다.
-
질병 진단 모델에서, 실제로 질병이 있는 환자를 건강하다고 판단하는 것(FN)은 그 환자가 제 때에 필요한 치료를 받지 못하게 하므로, 심각한 건강 문제나 사망으로도 이어질 수 있다.
-
금융 사기 감지모델에서, 사기 거래를 정상 거래로 잘못 판단하는 것(FN)은 사기 피해를 적발해내지 못한다는 걸 의미하고 이는 자칫 큰 자금이 사기꾼의 손에 넘어가는 등의 피해를 가져올 수 있다.
-
주변 차량 감지 모델이 실제로 부딪힐 가능성이 있는 차가 있음에도 그걸 감지해내지 못한다면(FN), 이는 사고로 이어지게 되고 감지모델을 제공한 기업에게 큰 손해를 끼칠 수 있다.
재현율을 이용하면 모델이 우리가 관심이 있는 사례를 실제로 얼마나 잘 포착하는지 판단할 수 있어 모델 성능평가에 중요한 지표로 쓰인다.
그런데 위에서 보면 정밀도와 재현율의 사례가 겹친다. 물론 둘 다 중요하다. 풀고자 하는 문제에서 중요도를 어디에 두느냐에 따라 정밀도를 중요하게 볼지, 재현율을 중요하게 볼 지 나뉘게 된다.
정밀도와 재현율은 상충하는 관계에 있어서 모델의 성능을 최적화할 때 이 둘의 균형을 맞추는 것이 필수적이다. 이를 보고 정밀도와 재현율이 '트레이드 오프' 관계에 있다고 이야기한다. 한 쪽을 높이면 다른 쪽이 낮아지는 경향이 보인다.
예를 들어, 악성코드 감지 모델에서 정밀도를 극대화하려고 하면 정상파일을 잘못 잡는 일을 줄이는 대신 실제 악성코드를 놓칠 가능성이 높아진다. 즉, FN이 증가하여 재현율이 떨어진다. 반대로 재현율을 극대화하려고 하면 가능한 모든 악성코드를 잡으려고 하므로 정상파일을 악성코드로 잘못 판단하는 일이 늘어난다. 즉, FP가 증가하여 정밀도가 떨어진다. 따라서 상황과 필요에 따라 두 지표의 균형을 잘 찾는 최적화 과정이 중요하다. 이를 동시에 관리하기 위해서 F1 Score라는 정밀도와 재현율의 조화평균을 이용할 수 있다.
Scikit-learn 으로 확인
사이킷런과 타이타닉 예시 데이터를 가지고 생존자예측모델의 오차행렬, 정확도, 재현율을 확인해보자. 예측모델은 사이킷런에서 제공하는 Logistic Regression 모델을 사용하며, 코드는 다음과 같은 로직을 따른다.
- 데이터를 불러온다.
- 모델 적용 위해, 전처리 과정을 거친다.
- Null 처리
- 불필요 피처 제거
- 데이터 인코딩
- 학습데이터, 테스트 데이터 분리
- 학습모델의 객체를 생성하고, 학습, 예측시킨다.
- 오차행렬, 정확도, 재현율로 평가한다.
import numpy as np
import pandas as pd
from sklearn.base import BaseEstimator
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression
from sklearn.metrics import precision_score, recall_score, confusion_matrix
# 데이터 전처리를 위한 함수선언
# Null 처리
def fillna_features(df: pd.DataFrame, inplace=False) -> pd.DataFrame:
df.fillna(value={'Age': 30,
'Cabin': 'N',
'Embarked': 'N',
'Fare': 0}, inplace=inplace)
return df
# 머신러닝에 불필요한 Feature 제거
def drop_features(df: pd.DataFrame, axis=1, inplace=False) -> pd.DataFrame:
df.drop(['PassengerId', 'Name', 'Ticket'], axis=axis, inplace=inplace)
return df
# 레이블 인코딩 수행
def format_features(df: pd.DataFrame) -> pd.DataFrame:
df['Cabin'] = df['Cabin'].str[:1]
features = ['Cabin', 'Sex', 'Embarked']
for feature in features:
le = LabelEncoder()
le = le.fit(df[feature])
df[feature] = le.transform(df[feature])
return df
# Data Processing 호출
def transform_features(df: pd.DataFrame) -> pd.DataFrame:
temp_df = fillna_features(df, inplace=True)
temp_df = drop_features(temp_df, inplace=True)
temp_df = format_features(temp_df)
return temp_df
# Step 1: load titanic example data
titanic_df = pd.read_csv('titanic_train.csv')
# Step 2: preprocess the data to fit with model.
y_titanic_df = titanic_df['Survived']
X_titanic_df = titanic_df.drop('Survived', axis=1)
X_titanic_df = transform_features(X_titanic_df)
# Split the data into training and test sets
X_train, X_test, y_train, y_test = train_test_split(X_titanic_df, y_titanic_df, test_size=0.2, random_state=0)
# Step 3: create model object from sklearn.
model = LogisticRegression()
# Step 4: train and test the model with the data.
model.fit(X_train, y_train)
predictions = model.predict(X_test)
# Step 5: evaluate by precision and recall values.
precision = precision_score(y_test, predictions)
recall = recall_score(y_test, predictions)
print(f"Confusion Matrix:\n {confusion_matrix(y_test, predictions)}")
print(f"Precision: {precision:.4f}")
print(f"Recall: {recall:.4f}")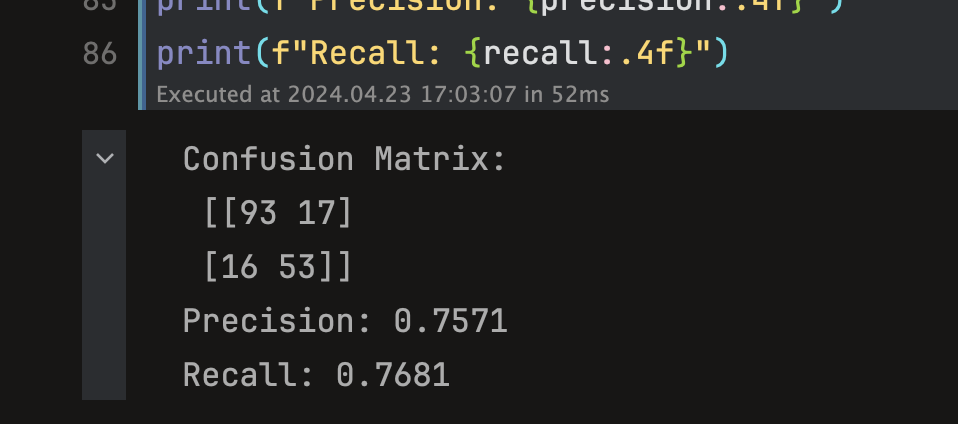
사이킷런의 confusion_matrix() 결과에서 행은 실제값, 열은 예측값을 뜻한다. 즉, 왼쪽 위부터 아래로 각각 TN, FN, FP, TP 의미를 갖는다. 그러면 이 모델의 생존여부 판단은 정확도 0.76, 재현율 0.78 정도를 갖는다고 평가할 수 있게 된다.
