
정밀도는 예측모델이 Positive라고 예측한 것 중 실제와 일치하는 경우를 비율로 나타낸 값이고, TP/(TP+FP) 로 계산된다. 예를 들어, 예측모델이 100개의 메일을 스팸메일이라고 예측했는데 그 중 실제로 80개의 메일이 스팸메일이었다면, 이 모델은 80%의 정밀도를 갖는다. 정밀도는 예측모델의 관점에서 얼마나 잘 맞추었는지를 반영한다.
재현율은 실제로 Positive인 사례 중 모델이 옳게 예측해 낸 비율을 나타내며, TP/(TP+FN) 으로 계산된다. 예를 들어, 테스트 데이터에 100개의 스팸메일이 숨어있는데, 이 중 예측모델이 90개의 스팸메일을 스팸메일이라 판단해냈다면, 이 모델은 90%의 재현율을 갖는다. 재현율은 실제 데이터의 관점에서 얼마나 잘 맞추었는지를 반영한다.
정밀도, 재현율은 Trade-off 관계
정밀도와 재현율은 이진분류모델의 하이퍼파라미터, 임계값(Threshold)이 어떻게 설정되느냐에 따라 높아지고 낮아진다.
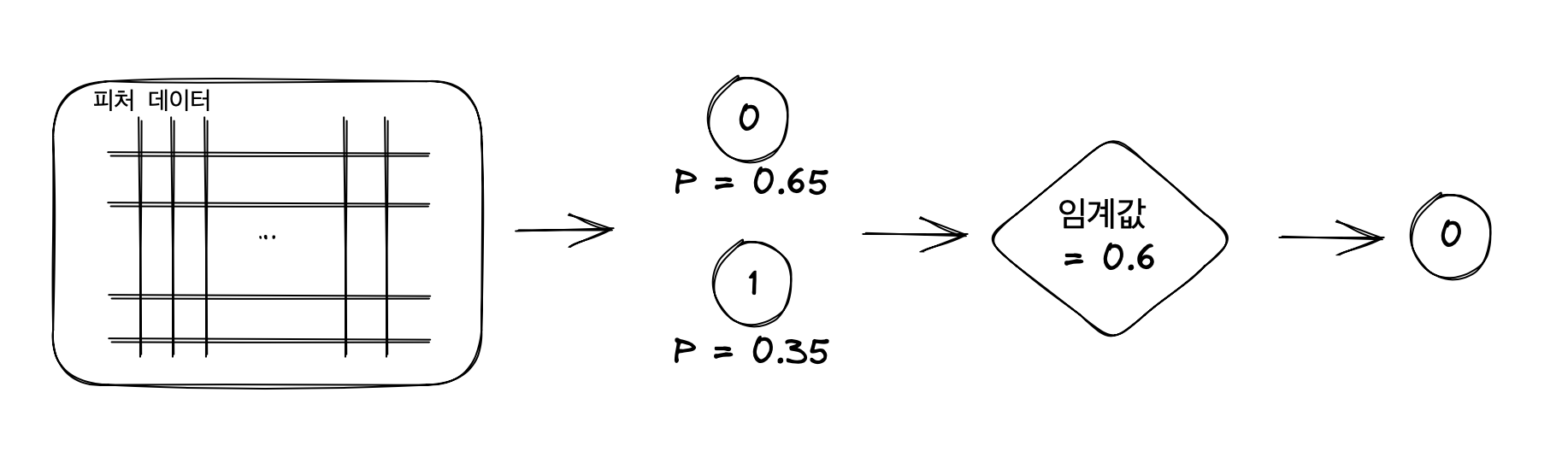
이진분류모델은 그 결과를 반환할 때 0일 확률, 1일 확률을 같이 반환해준다. 만약 어떤 피처데이터를 보고 결과를 냈을 때, 0일 확률이 0.65, 1일 확률이 0.35라고 해보자. 만약 임계값이 0.6이라면 이 예측모델은 1일 확률이 0.6을 넘지 못하기 때문에 0이라고 분류할 것이다. 다시 말해 예측모델은 더욱 깐깐해지고 1(Positive) 케이스가 적어진다. Positive 케이스 자체가 적어지므로 자연스럽게 FP 케이스도 적어지게 되며, 반대로 0(Negative) 케이스는 많아지고 FN도 같이 많아지게 된다. 따라서 임계값이 너무 높으면, 모델이 깐깐해져서 정밀도는 높아지고 재현율은 떨어지는 현상이 나타난다.

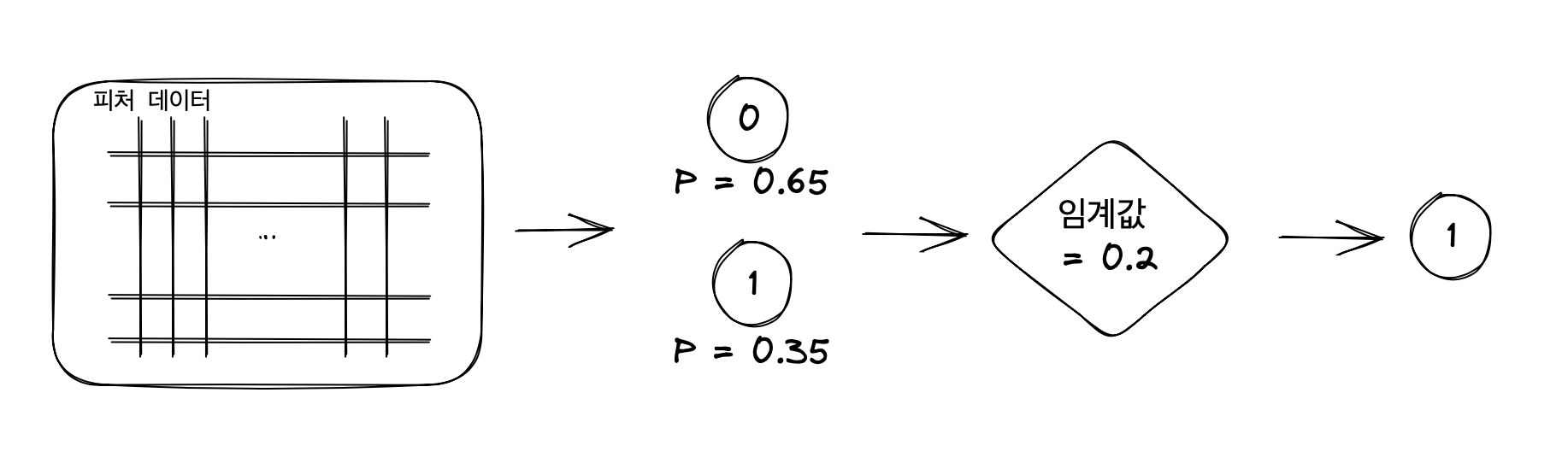
반대로 임계값이 너무 낮아 0.2라면, 1일 확률이 0.35라도 임계값을 넘어 모델은 해당 케이스를 1이라고 분류한다. 즉, 예측모델이 후해지고 1(Positive)인 결과가 많아지게 된다. 그러면 TP와 함께 FP 케이스가 많아지므로 정밀도는 떨어진다. 반대로 0(Negative) 결과는 적어서 FN도 같이 낮아지고 이는 재현율이 높아지는 결과를 가져온다. 다시 말해, 임계값이 너무 낮으면, 모델이 후해져서 정밀도는 낮아지고 재현율은 높아지는 현상이 나타난다.

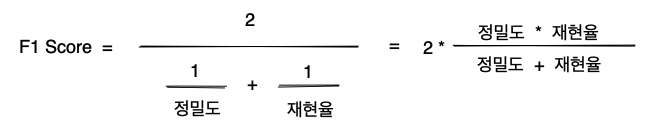
정밀도와 재현율이 서로 반비례하는 상관관계가 나타나는데, 정밀도가 중요한 상황이라고 해서 재현율을 완전히 버릴 수는 없다. 그 반대도 마찬가지로 재현율을 챙긴다고 정밀도를 완전히 버릴 수는 없다. 둘 다 어느 정도 균형있게 챙기는 것이 좋은데, 이를 위해 조화평균인 F1 Score라는 새로운 지표로 모델의 성능을 평가한다.
F1 Score
F1 Score는 정밀도와 재현율의 조화평균으로 다음과 같이 구할 수 있다.
정확도가 90% 로 매우 높은데 재현율이 10% 로 매우 낮은 모델의 F1 Score를 계산해보면 0.18 이 나온다. 반면에 정확도가 80% 로 전보다 살짝 낮지만, 재현율이 60% 로 높아진 경우의 F1 Score는 0.686 이다. 정확도와 재현율에 따라서 각각 F1 Score가 어떤 값으로 계산되는지 표와 그래프로는 다음과 같이 나타낼 수 있다.
| Precision\Recall | 0.1 | 0.2 | 0.3 | 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | 0.9 | 1.0 |
|---|---|---|---|---|---|---|---|---|---|---|
| 0.1 | 0.100 | 0.133 | 0.150 | 0.160 | 0.167 | 0.171 | 0.175 | 0.178 | 0.180 | 0.182 |
| 0.2 | 0.133 | 0.200 | 0.240 | 0.267 | 0.286 | 0.300 | 0.311 | 0.320 | 0.327 | 0.333 |
| 0.3 | 0.150 | 0.240 | 0.300 | 0.343 | 0.375 | 0.400 | 0.420 | 0.436 | 0.450 | 0.462 |
| 0.4 | 0.160 | 0.267 | 0.343 | 0.400 | 0.444 | 0.480 | 0.509 | 0.533 | 0.554 | 0.571 |
| 0.5 | 0.167 | 0.286 | 0.375 | 0.444 | 0.500 | 0.545 | 0.583 | 0.615 | 0.643 | 0.667 |
| 0.6 | 0.171 | 0.300 | 0.400 | 0.480 | 0.545 | 0.600 | 0.646 | 0.686 | 0.720 | 0.750 |
| 0.7 | 0.175 | 0.311 | 0.420 | 0.509 | 0.583 | 0.646 | 0.700 | 0.747 | 0.788 | 0.824 |
| 0.8 | 0.178 | 0.320 | 0.436 | 0.533 | 0.615 | 0.686 | 0.747 | 0.800 | 0.847 | 0.889 |
| 0.9 | 0.180 | 0.327 | 0.450 | 0.554 | 0.643 | 0.720 | 0.788 | 0.847 | 0.900 | 0.947 |
| 1.0 | 0.182 | 0.333 | 0.462 | 0.571 | 0.667 | 0.750 | 0.824 | 0.889 | 0.947 | 1.000 |
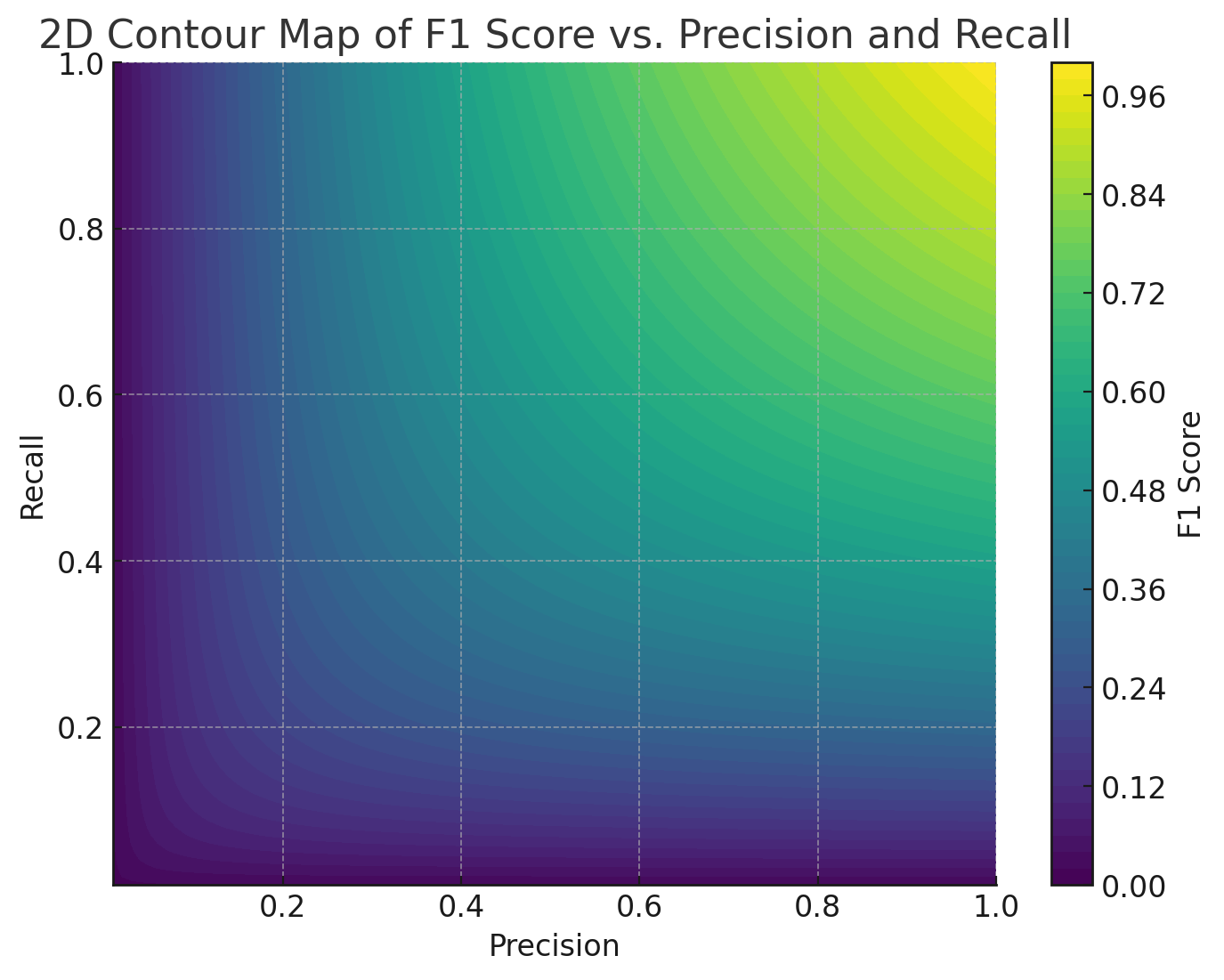
F1 Score는 정밀도와 재현율이 균형있게 중요한 상황에서 모델을 평가하는 지표로 사용된다. 예를 들어, 스팸메일 예측모델을 평가할 때는 스팸이 아닌 메일을 스팸으로 잘못 분류하는 것(정밀도에 영향)과 스팸 메일을 모두 감지해 내는 것(재현율에 영향) 둘 다 중요하기 때문에 정밀도, 재현율과 더불어 F1 Score도 같이 고려하는 것이 좋다.
