
Kaggle에 있는 타이타닉데이터를 이용하여 지금까지 배운 내용을 가지고 데이터 분석을 하고 각 모델이 생존자 예측을 잘 하는지 비교해보자.
데이터 전처리
- Null 값 처리
- 불필요한 속성 제거
- 인코딩
모델 학습 및 검증 / 예측 / 평가
- 결정트리, 랜덤포레스트, 로지스틱 회귀 각각 비교.
- K Fold 교차검증
- cross_val_score(), GridSearchCV 실습.
1. Raw data 확인
다운받은 데이터를 불러와 우선 raw data 를 살펴보자.
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
titanic_df = pd.read_csv('titanic_train.csv')
display(titanic_df.head(3))
각 컬럼은 다음과 같은 의미를 가지고 있다.
PassengerId: 승객의 고유 아이디Survived: 생존 여부. 0은 사망, 1은 생존Pclass: 티켓의 클래스. 1은 1등석, 2는 2등석, 3은 3등석Name: 승객의 이름Sex: 승객의 성별Age: 승객의 나이SibSp: 함께 탑승한 형제자매 또는 배우자의 수Parch: 함께 탑승한 부모 또는 자녀의 수Ticket: 티켓 번호Fare: 승객이 지불한 요금Cabin: 승객이 머무른 객실 번호Embarked: 승객이 탑승한 항구. C는 Cherbourg, Q는 Queenstown, S는 Southampton을 의미.
여기서 생존했는지 여부를 알기 위함이니, 타겟은 Survived 가 될 것이다. pandas DataFrame의 메소드들을 활용하여 좀 더 자세히 살펴보자.
-
df.info()를 이용하면 각 컬럼별로 Null 값이 몇개인지, 데이터 타입이 어떻게 되는지 알 수 있다.print(titanic_df.info())<class 'pandas.core.frame.DataFrame'> RangeIndex: 891 entries, 0 to 890 Data columns (total 12 columns): # Column Non-Null Count Dtype --- ------ -------------- ----- 0 PassengerId 891 non-null int64 1 Survived 891 non-null int64 2 Pclass 891 non-null int64 3 Name 891 non-null object 4 Sex 891 non-null object 5 Age 714 non-null float64 6 SibSp 891 non-null int64 7 Parch 891 non-null int64 8 Ticket 891 non-null object 9 Fare 891 non-null float64 10 Cabin 204 non-null object 11 Embarked 889 non-null object dtypes: float64(2), int64(5), object(5) memory usage: 83.7+ KB None -
혹은
df.isnull().sum()이용하면 각 컬럼별로 Null 값이 몇개인지만 직접적으로 확인할 수 있다.PassengerId 0 Survived 0 Pclass 0 Name 0 Sex 0 Age 177 SibSp 0 Parch 0 Ticket 0 Fare 0 Cabin 687 Embarked 2 dtype: int64Age와 Cabin의 Null 값이 좀 많으므로 나중에 이에 대한 처리를 해주어야 함을 예상해볼 수 있다.
-
df.describe()이용하면 데이터타입이 숫자인 컬럼들에 대해서 Null 아닌 데이터 갯수, 평균, 표준편차, 최소, 25%, 50%, 75%, 최대까지 4분위 값들을 알 수 있다.titanic_df.describe()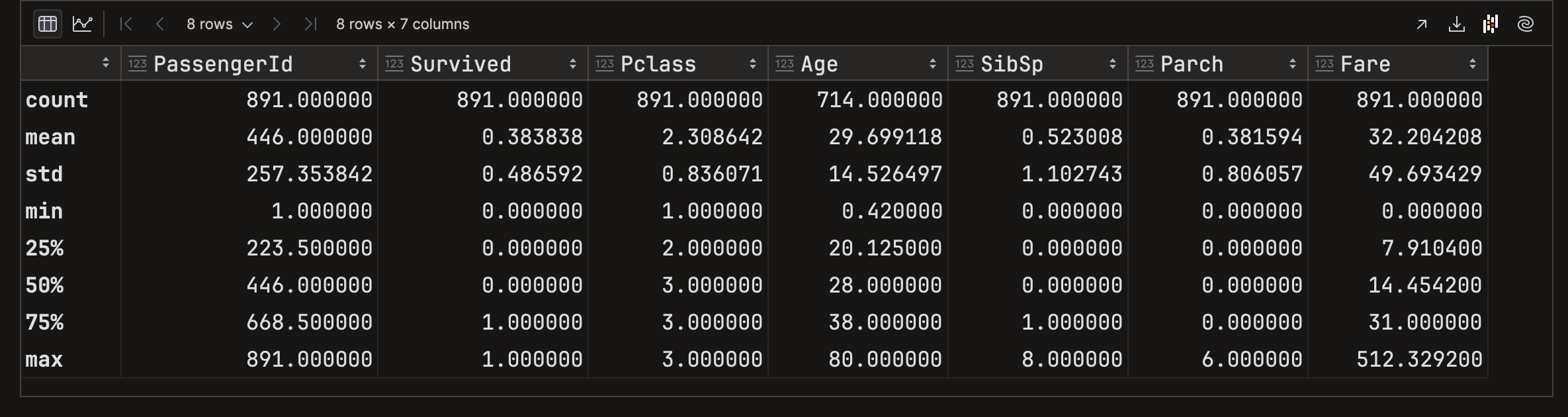
2. Exploratory Data Analysis (EDA)
모델에 학습시키기 전에 먼저 데이터를 살펴보면서 전반적으로 어떤 경향이 있는지 사람의 눈으로 분석해보자. 타이타닉 당시에는 여성과 아이, 그리고 노인을 먼저 살린다는 사회적 분위기가 있었다. 이를 바탕으로 생존율을 성별, 나이대에 따라 나누어 살펴보자.
성별에 따른 생존율
dataframe의 groupby를 이용하면 성별과 생존율 두 컬럼의 관계를 알아볼 수 있다.
# 성별에 따른 생존여부.
# groupby()로 묶어서 count() 해보기.
print(f"{titanic_df.groupby(['Sex','Survived'])['Survived'].count()}")
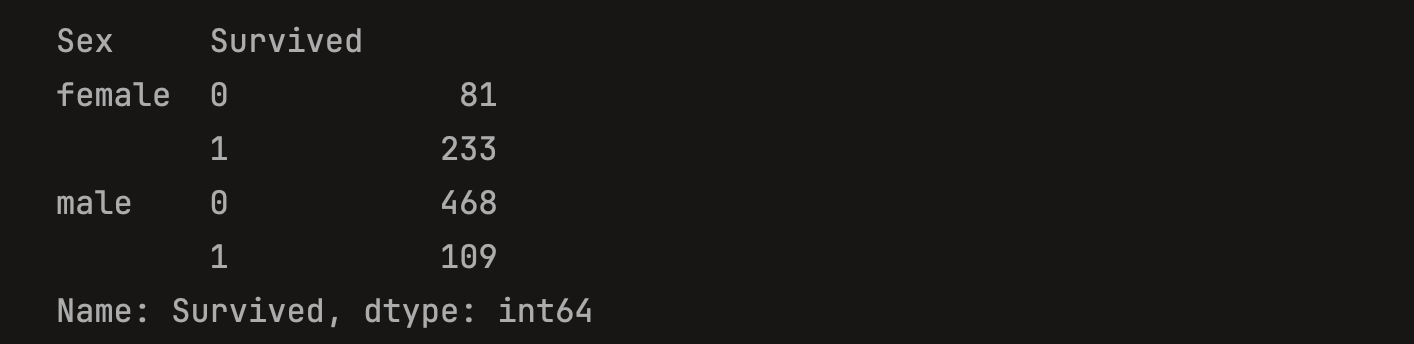
df.groupby() 로 두 컬럼을 묶고, 원하는 컬럼을 대괄호를 이용해 선택하여 count() 메소드를 실행한다. 그러면 성별의 각 값에 따른 생존여부의 수가 얼마나 되는지 볼 수 있다. groupby() 는 DataFrameGroupBy 타입으로 반환받고, 여기에서 알고자 하는 컬럼을 선택하면 SeriesGroupBy 타입으로 반환받는다.
결과값을 봤을 때는 여성의 사망은 81명, 생존은 233명. 그리고 남성의 사망은 468명, 생존은 109명으로 확실히 남성의 생존율이 더 낮아보인다. 이를 좀 더 시각적으로 잘 표현하기 위해서 Seaborn의 barplot으로 각 값의 평균값을 확인해보자.
# 그래프로 확인
sns.barplot(data=titanic_df,x='Sex',y='Survived')
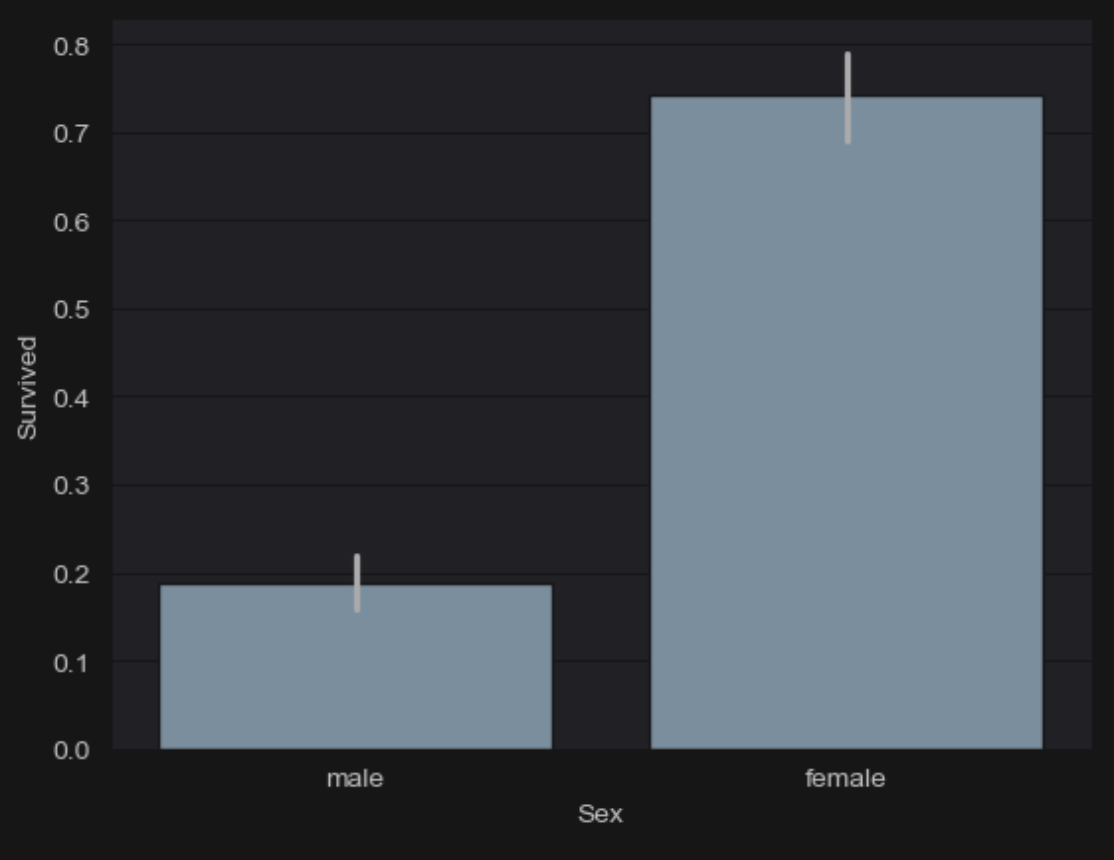
그래프로 확인해보아도 남성에 비해 여성의 생존율이 명백히 높다.
나이에 따른 생존율
df.info() 에서 나이 데이터를 보면 약 200개가 Null 값이다. 그리고 float64 타입으로 컬럼의 고유한 값이 엄청 많기 때문에 각 값에 대해서 barplot을 나타내면 그 의미를 알기 힘들다. 나이 한살 한살에 대한 생존여부를 판단하는 것은 의미가 없다. 따라서 각 데이터를 나이대 별로 분류하는 전처리 과정이 필요하다.
# 나이대에 따른 생존율
# 나이는 1씩 증가하는 값이라 각 값을 모두 x축에 나타낸다면 의미를 찾기 힘듦.
def get_age_category(age)-> str:
if np.isnan(age) :
return 'Unknown'
elif age <=5:
return 'Baby'
elif age <=12:
return 'Child'
elif age <=18:
return 'Teenager'
elif age <=25:
return 'Student'
elif age <=35:
return 'Young Adult'
elif age <=60:
return 'Adult'
else:
return 'Elderly'
# 새로운 컬럼을 만들어서 나이대 정보를 담기.
titanic_df['Age_category']=titanic_df['Age'].apply(lambda age: get_age_category(age))
print(f"{titanic_df['Age_category']}")데이터를 처리하면 각각의 나이대에 맞게 분류되어 dataframe에 새로운 컬럼으로 만들어진다. 이를 seaborn barplot 이용해 시각화해보자. 그냥 하면 x축 데이터 순서가 뒤죽박죽이니까 order 인자 통해서 순서를 정해준다.
# 그림으로 그리기. 이 때, 순서를 원하는 순서로 맞춰주기.
print(f"{titanic_df['Age_category'].value_counts()}")
age_order=['Unknown', 'Baby', 'Child', 'Teenager', 'Student', 'Young Adult', 'Adult', 'Elderly']
sns.barplot(data=titanic_df,x='Age_category',y='Survived', order=age_order, hue='Sex')
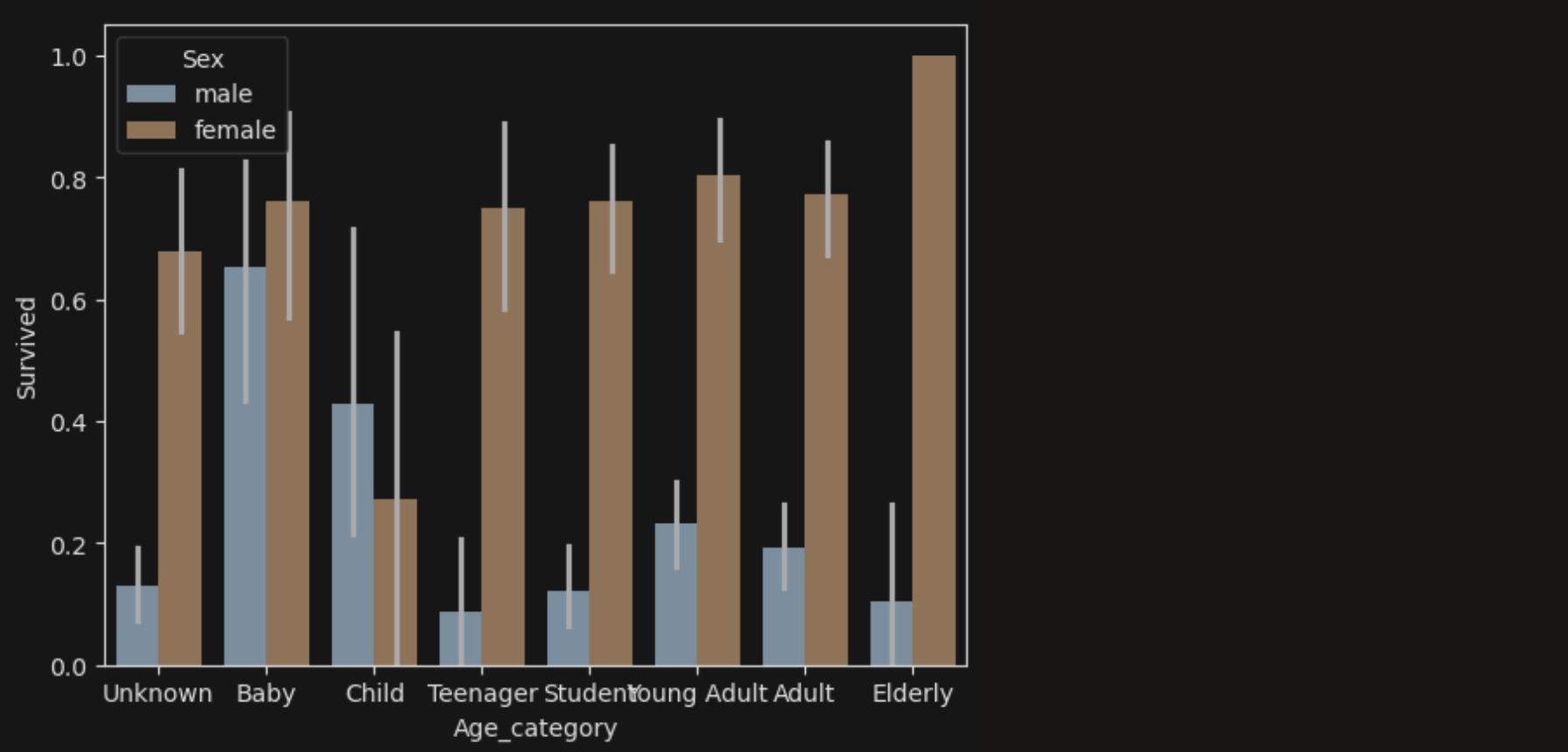
그래프를 봤을 때 Unknown을 제외하고 Baby와 Child는 남녀 구분 없이 생존율이 높지만, Teenager 부터는 남녀 생존율 차이가 극명하게 나는걸 볼 수 있다.
다음에는 scikit-learn 제공 모델을 여러 개 학습시켜 생존여부를 예측하고 모델마다 결과값이 어떻게 다른지 비교해보자.
