
스케일링(Scaling)
스케일링은 머신러닝 모델을 학습시킬 때 더 효율적으로 할 수 있도록 하는 전처리 과정 중 하나이다. 학습을 위한 피처데이터에는 여러 종류의 데이터들이 있을 텐데, 각각의 피처데이터들은 서로 단위도 다르고, 스케일도 다르다. 그런데 이를 하나로 통일된, 즉 표준화 되고 정규화된 크기로 맞춰주지 않으면 머신러닝 모델 입장에서 어떤 데이터가 더 비중이 높은지 판단할 때 혼란스러울 수 있다.
예를 들어, 고객 데이터 분석에서는 고객의 나이, 소득, 구매 빈도, 웹사이트에서의 활동 시간 등 다양한 특성을 사용한다. 나이는 대체로 0에서 100 사이, 구매 빈도는 몇 번에서 수백 번까지, 활동 시간은 몇 분에서 수십 시간까지 그 범위가 다양하게 나타날 수 있다. 이처럼 범위가 다른 데이터를 학습에 적용하기 전에 스케일링을 통해 일관된 범위로 조정하지 않으면 모델의 성능이 최적화되지 않고 학습이 잘 되지 않을 수 있다.
scikit-learn에서는 다양한 스케일링 기법을 지원하는데, 가장 대표적인 두 가지 방법은 다음과 같다.
- StandardScaler
- MinMaxScaler
StandardScaler
StandardScaler를 사용하면 해당 피처의 데이터를 평균이 0, 표준편차가 1인 데이터로 표준화하여 가우시안 분포를 따르게끔 만들 수 있다. StandardSclaer는 대표적으로 서포트 벡터 머신(SVM), 선형 회귀, 로지스틱 회귀에서 쓰이는데, 왜냐하면 이러한 모델들은 데이터가 표준화된 가우시안 분포를 가지고 있다고 가정하기 때문이다.
StandardScaler는 Z Score 변환이라고도 불린다.
scikit-learn 예제 데이터셋 중 iris 데이터셋을 이용하여 연습해보자.
- 전
from sklearn.datasets import load_iris
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 붓꽃 데이터 세트를 로딩하고 DataFrame으로 변환
iris = load_iris()
iris_data = iris.data
iris_df = pd.DataFrame(data=iris_data, columns=iris.feature_names)
print('feature 들의 평균 값')
print(iris_df.mean())
print('\nfeature 들의 분산 값')
print(iris_df.var())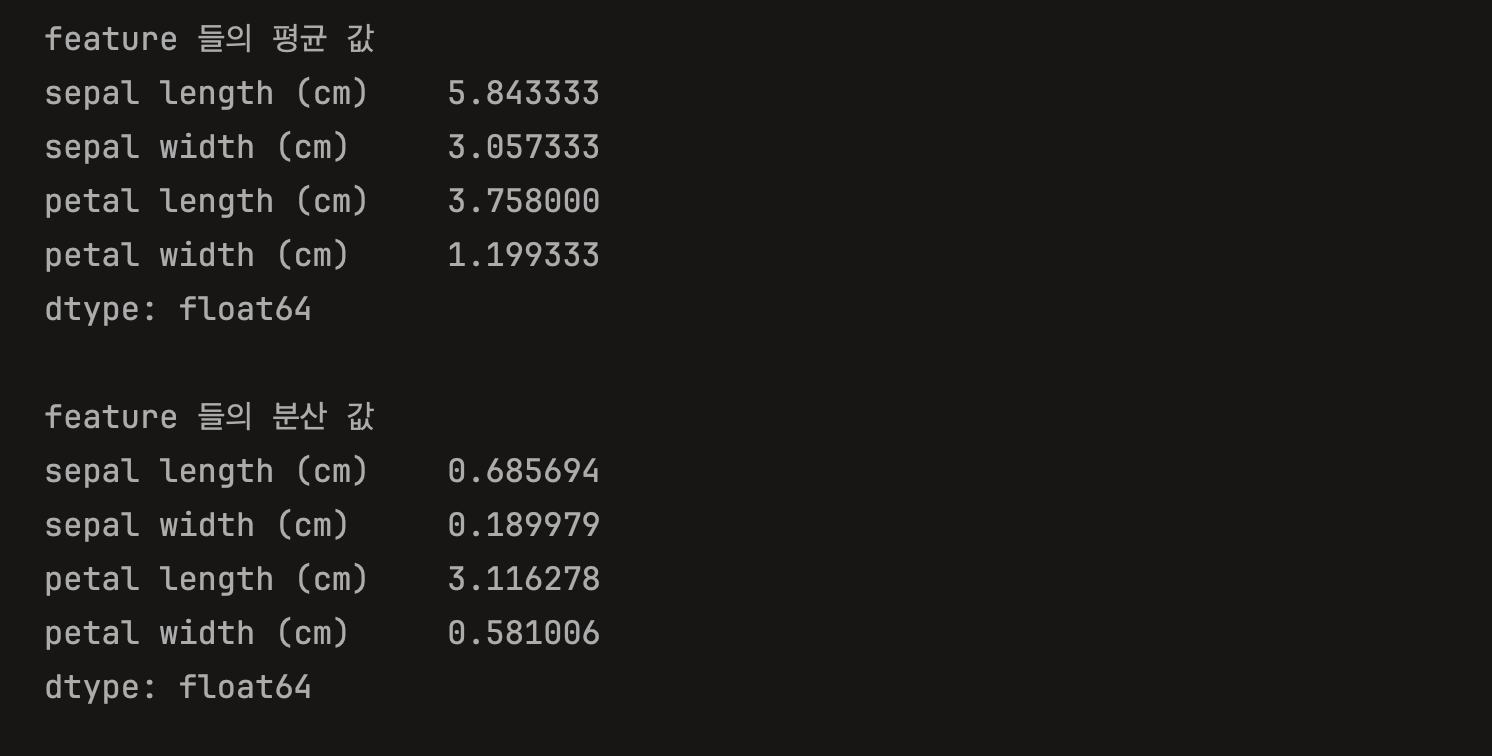
StandardScaler를 적용하기 전에는 sepal length, sepal width, petal length, petal width 모두 평균과 분산이 제각각인 것을 알 수 있다.
StandardScaler는 scaler = StandardScaler()으로 객체를 생성해준 뒤,scaler.fit(iris_df) 으로 데이터를 학습하고 scaler.transform(iris_df) 으로 스케일링을 진행한다.
- 후
# StandardScaler 객체 생성
scaler = StandardScaler()
# StandardScaler로 데이터 세트 변환. fit()과 transform() 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform() 시 스케일 변환된 데이터 세트가 NumPy ndarray로 반환돼 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('스케일 된 feature 들의 평균 값')
print(iris_df_scaled.mean())
print('\n스케일 된 feature 들의 분산 값')
print(iris_df_scaled.var())
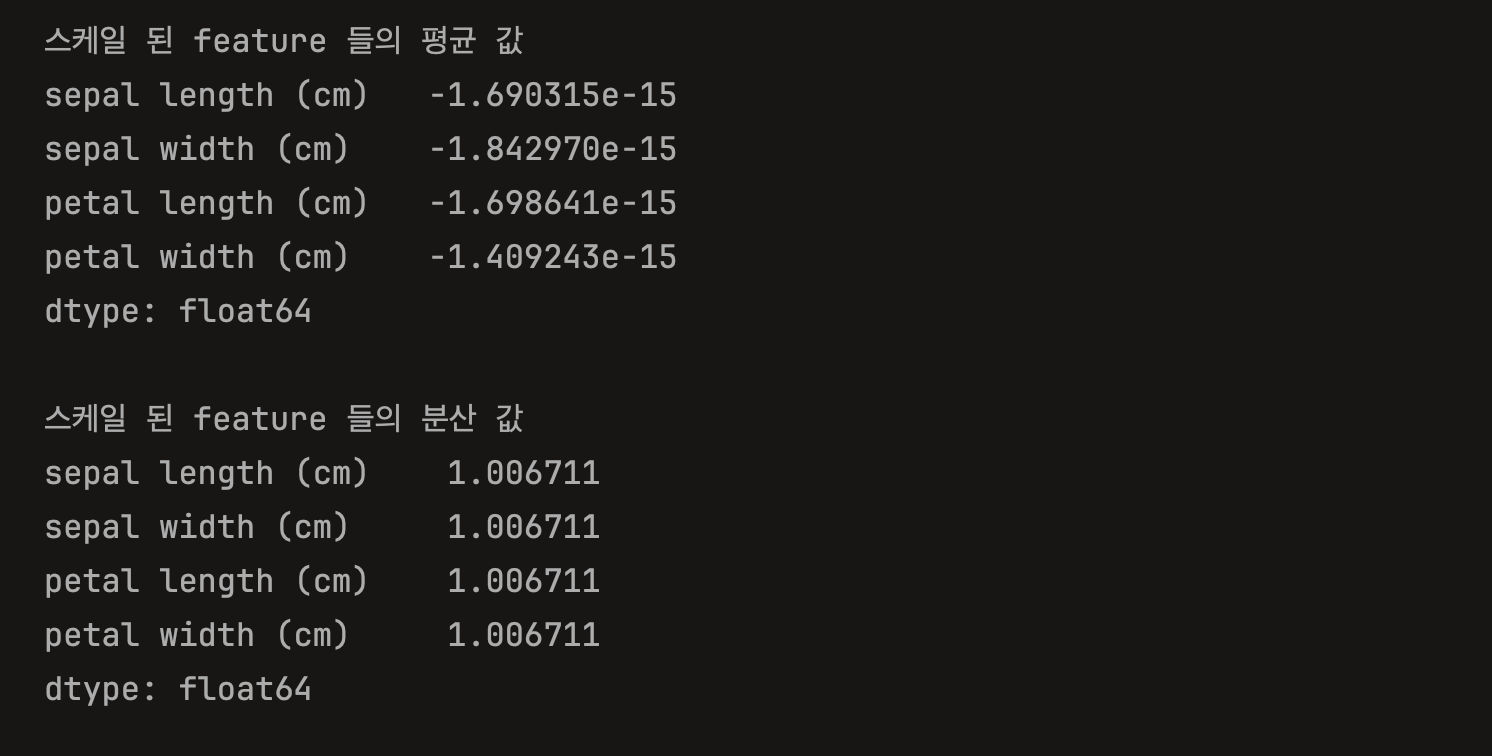
StandardScaler를 적용하면 각 피처의 평균이 0, 표준편차가 1에 매우 가까운 값으로 나타나는 걸 확인할 수 있다.
MinMaxScaler
MinMaxScaler는 크기의 단위가 다른 여러 피처들을 모두 0과 1사이의 값으로 바꾸는 역할을 한다. 데이터의 최솟값이 0, 최댓값이 1이 되게끔 스케일을 조정한다.
마찬가지로 iris 데이터를 가지고 연습해보자. StandardScaler 때와 마찬가지로 MinMaxScaler() 객체를 생성 후, scaler.fit(iris_df)로 데이터를 학습하고, scaler.transform(iris_df)로 데이터를 변환한다.
# MinMaxScaler
# 란, 데이터 값을 0과 1사이의 범위 값으로 변환. 만약 음수 값이 있다면 -1에서 1값으로 변환.
from sklearn.preprocessing import MinMaxScaler
# MinMaxScaler 객체 생성
scaler = MinMaxScaler()
# MinMaxScaler로 데이터 세트 변환. fit()과 transform() 호출.
scaler.fit(iris_df)
iris_scaled = scaler.transform(iris_df)
# transform() 시 스케일 변환된 데이터 세트가 NumPy ndarray로 반환돼 이를 DataFrame으로 변환
iris_df_scaled = pd.DataFrame(data=iris_scaled, columns=iris.feature_names)
print('스케일 된 feature 들의 최솟값')
print(iris_df_scaled.min())
print('\n스케일 된 feature 들의 최댓값')
print(iris_df_scaled.max())
스케일을 조정하고 나면 최솟값이 0, 최댓값이 1이 되는 결과가 나온다.
MinMaxScaler 사용 시 주의사항
MinMaxScaler를 사용할 때는 학습용 데이터의 최대,최소 범위와 테스트용 데이터의 최대, 최소 범위가 일치하도록 해주어야 한다.
예를 들어, [0,1,2,3,4,5,6,7,9,10] 으로 0 ~ 10 데이터를 가지고 fit() 이후 transform()을 진행해주면 [0., 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.] 이 된다.
그런데 테스트용 데이터가 [0,1,2,3,4,5] 인데 fit() 하고 transform()을 진행했을 때 예상하는 [0., 0.1, 0.2, 0.3, 0.4, 0.5]가 아니라 [0., 0.2, 0.4, 0.6, 0.8, 1.]라는 결과가 나오게 된다. 이는 fit()을 테스트용 데이터에도 적용했기 때문이다. 따라서 테스트용 데이터를 변환할 때는 fit() 없이 transform()을 사용하여 학습용 데이터에서 사용한 척도를 그대로 가져가야 한다.
# fit(), transform(), fit_transform() 사용할 때 유의사항.
# 학습 데이터와 테스트 데이터 구분 시 사용에 주의해야 한다.
# MinMaxScaler로 예시.
import numpy as np
from sklearn.preprocessing import MinMaxScaler
train_data=np.arange(0,11).reshape(-1,1) # 0~10 까지 값을 2차원 array로 생성
test_data=np.arange(0,6).reshape(-1,1) # 0~5 까지 값을 2차원 array로 생성
# MinMaxScaler 객체 생성
scaler = MinMaxScaler()
# fit()하게 되면 train_data의 최솟값이 0, 최댓값이 10으로 설정됨.
scaler.fit(train_data)
# transform()하게 되면 train_data의 최솟값이 0, 최댓값이 1로 변환됨.
train_scaled = scaler.transform(train_data)
print('원본 train_data 데이터:', np.round(train_data.reshape(-1), 2))
print('Scale된 train_data 데이터:', np.round(train_scaled.reshape(-1), 2))
# 주의⚠️
# 테스트하기 위해 테스트 데이터도 변환시켜줄 때, 테스트 데이터 넣어서 fit()을 사용하면 안된다.
# 왜냐하면 그렇게 할 시 모델의 학습데이터와 다르게 설정되기 때문. 여기서는최솟값이 0, 최댓값이 5로 바뀌게 됨.
# train data의 척도를 유지하면서 test_data 스케일링 하려면 그냥 transform()을 적용시켜주어야 한다.
test_scaled = scaler.transform(test_data)
print('원본 test_data 데이터:', np.round(test_data.reshape(-1), 2))
print('Scale된 test_data 데이터:', np.round(test_scaled.reshape(-1), 2))
#%%

